
RT-1: ROBOTICS TRANSFORMER FOR REAL-WORLD CONTROL AT SCALE
👉🏻 RT-1 (Robotics Transformer) by Google
Full Summary
본 논문은 대규모의 다양한 데이터셋으로부터 지식을 효과적으로 흡수하고 일반화할 수 있는 로봇 제어 모델 RT-1 (Robotics Transformer)을 제안한다.
기존 로봇 학습은 특정 작업에 국한된 데이터를 사용하는 경우가 많아 새로운 작업이나 환경에 대한 일반화 능력이 부족했다. 이러한 한계를 극복하기 위해, 본 논문은 개방형, 작업에 구애받지 않는(task-agnostic) 학습 방식과 대용량 데이터를 처리할 수 있는 Transformer 기반의 고용량 아키텍처를 결합하는 것이 핵심이라고 주장한다.
RT-1은 이미지와 자연어 명령을 입력받아 로봇의 팔과 베이스 움직임을 출력하는 모델이다. 이 모델은 FiLM으로 조건화된 EfficientNet image encoder, TokenLearner, 그리고 Transformer를 결합한 효율적인 구조를 갖는다. 이 모델은 3500만 개의 파라미터를 가졌음에도 불구하고 실시간 제어에 필수적인 3Hz의 빠른 추론 속도를 달성한다.
13대의 로봇을 이용해 17개월간 수집한 13만 개 이상의 시연 데이터(700개 이상의 작업)로 학습한 결과, RT-1은 학습된 작업에서 97%의 높은 성공률을 보였다. 또한, 처음 보는 작업, 방해물, 배경에 대한 일반화 성능에서 기존 최고 성능의 모델(baseline)보다 각각 25%, 36%, 18% 더 뛰어난 성능을 입증했다.
나아가 시뮬레이션 데이터나 다른 종류의 로봇(예: Kuka)으로부터 수집된 이종 데이터를 성공적으로 학습하여 기존 성능 저하 없이 새로운 시나리오에 대한 일반화 능력을 향상시키는 '데이터 흡수(data absorption)' 능력도 보여주었다.
Section Summary
1. Introduction
-
문제 제기
: 컴퓨터 비전, NLP 등 다른 분야에서는 대규모 데이터로 사전 학습된 범용 모델이 성공을 거두었지만, 데이터 수집이 특히 어려운 로봇 공학 분야에서는 아직 이러한 접근법이 제대로 입증되지 않았다. -
핵심 과제
: 일반화 성능이 뛰어난 로봇 모델을 구축하기 위한 두 가지 핵심 과제는 (1) 규모와 다양성을 모두 갖춘 데이터셋을 구축하는 것과 (2) 대용량이면서도 실시간 제어가 가능한 효율적인 모델을 설계하는 것이다. -
솔루션 제시
: 본 논문은 이 두 과제를 해결하기 위해 13만 건의 시연으로 구성된 대규모 데이터셋과, 이를 효과적으로 학습할 수 있는 RT-1 아키텍처를 제안한다.RT-1은 뛰어난 일반화 및 강건성(robustness)을 보이며, SayCan 프레임워크와 결합하여 최대 50단계에 이르는 장기 과제(long-horizon task) 수행도 가능하다.

2. Related Work
- Transformer 기반 정책
: 최근 여러 연구에서 로봇 제어를 위해 Transformer를 사용했지만, RT-1은 언어와 시각 정보를 로봇 행동으로 매핑하는 전체 과정을 하나의 시퀀스 모델링 문제로 취급하여 Transformer를 더욱 적극적으로 활용한다.
- 실세계 로봇 조작
: Gato와 같은 기존 대규모 모델들은 실제 로봇으로 수행한 작업의 종류가 매우 제한적이었던 반면, RT-1은 700개가 넘는 다양한 실세계 작업에 대한 학습 및 일반화 성능을 평가한다.
- 다중 작업 및 언어 기반 학습
: RT-1은 로봇 공학의 오랜 연구 분야인 다중 작업 학습 및 언어 조건부 학습의 연장선에 있으며, 이전 연구들보다 훨씬 큰 규모의 데이터와 다양한 행동을 다루는 새로운 아키텍처를 제안함으로써 이 분야를 한 단계 발전시켰다.
3. Preliminaries
-
Robot learning
: 본 논문은 언어 지시사항과 시각 정보를 기반으로 로봇 정책을 학습하는 것을 목표로 한다.- policy : 언어 명령 와 일련의 이미지 관찰 가 주어졌을 때, 로봇의 행동 를 출력
- 학습의 목표 : 주어진 지시사항에 대한 성공 여부를 나타내는 이진 보상(binary reward)을 최대화하는 정책을 학습
-
Transformer
: RT-1은 정책()를 파라미터화하기 위해 Transformer를 사용한다.
Transformer는 입력 시퀀스를 출력 시퀀스로 매핑하는 시퀀스 모델이며, 본 연구에서는 이미지와 언어 지시사항 같은 입력 데이터를 토큰 시퀀스로 변환하고, 이를 다시 행동 토큰 시퀀스로 매핑하는 데 사용된다. -
Imitation Learning
: 전문가(여기서는 사람)의 성공적인 시연 데이터셋을 사용하여, 주어진 상황에서 전문가의 행동을 모방하도록 정책을 학습시키는 행동 복제(behavioral cloning) 방식을 사용한다.
학습 목표는 이미지와 언어 지시사항이 주어졌을 때, 시연 데이터에 기록된 행동의 로그 가능도(log-likelihood)를 최대화(음의 로그 가능도를 최소화)하는 것이다.
4. System Overview
-
하드웨어 및 환경
: Everyday Robots의 7축 팔을 가진 이동형 로봇을 사용하며, 대규모 데이터 수집을 위한 '로봇 교실'과 평가를 위한 실제 사무실 주방 2곳에서 실험을 진행했다. -
데이터
: 13만 개 이상의 인간 원격 조종 시연 데이터로 구성되며, 각 시연에는 "콜라 캔 집어"와 같은 텍스트 설명이 달려 있다.

- RT-1 아키텍처
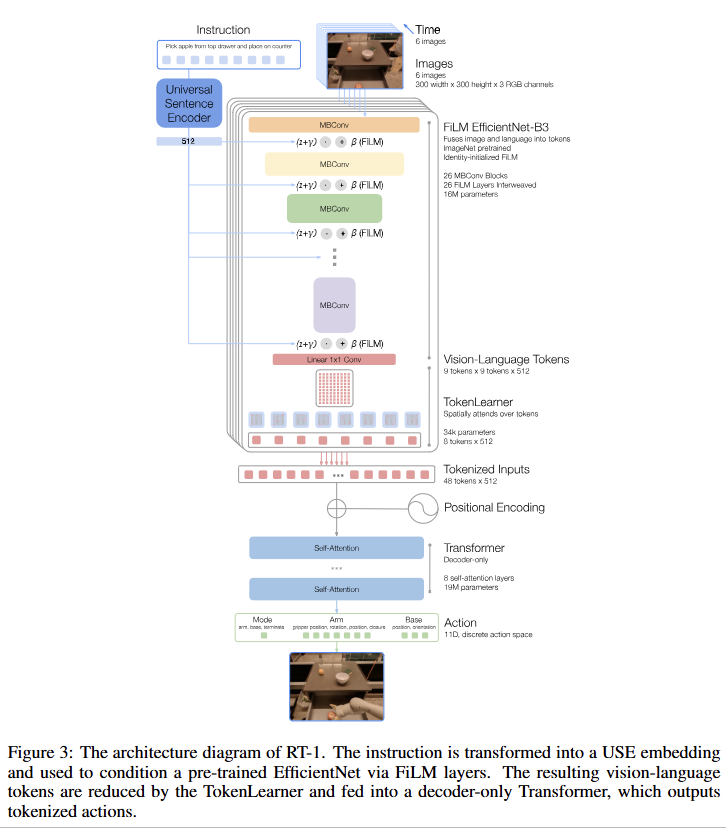
- 입력: 이미지 시퀀스와 자연어 명령을 입력받는다.
- 처리: ImageNet으로 사전 학습된 EfficientNet이 FiLM을 통해 언어 임베딩으로 조건화되어 이미지 특징을 추출한다.
- 압축: TokenLearner가 추출된 특징 토큰을 소수의 핵심 토큰으로 압축한다.
- 출력: Transformer가 압축된 토큰을 처리하여 이산화된(discretized) 로봇 행동을 출력한다.
- 실시간 제어: 전체 시스템은 3Hz의 빈도로 로봇 행동을 제어한다.
5. RT-1 : Robotics Transformer
Model
-
Instruction and image tokenization
: RT-1은 6개의 이미지 시퀀스와 자연어 지시사항을 입력받는다. 6개의 이미지는 FiLM으로 조건화된 EfficientNet을 통과하여 81개의 시각-언어 토큰으로 변환된다.언어 명령은 Universal Sentence Encoder (USE)로 임베딩되어 FiLM 레이어에 주입됨으로써, 초기 단계부터 작업과 관련된 특징을 추출하도록 돕는다.
-
TokenLearner
: 위 81개의 토큰을 다시 8개로 압축하여 Transformer의 연산 효율성을 높인다. -
Transformer
: 8개의 self-attention 레이어로 구성된 decoder-only Transformer가 최종적으로 행동 토큰을 출력한다.
-
Action tokenization
: 팔(7차원), 베이스(3차원), 제어 모드(1차원) 등 총 11차원의 행동 공간을 각각 256개의 구간(bin)으로 이산화하여 사용한다. 이는 복잡한 multi-modal 행동 분포를 효과적으로 표현할 수 있게 한다. -
Loss
: 모델 학습에는 standard categorical cross-entropy 손실을 사용하고, 이전 Transformer 기반 제어기들에서 활용되었던 casual masking을 적용하여 다음 행동을 예측한다. -
Inference speed
: 실시간 제어 요구사항(3Hz, 100ms 이내)을 만족시키기 위해 TokenLearner를 통한 토큰 수 감소와 이전 계산 결과를 재사용하는 기법을 적용한다.
Data
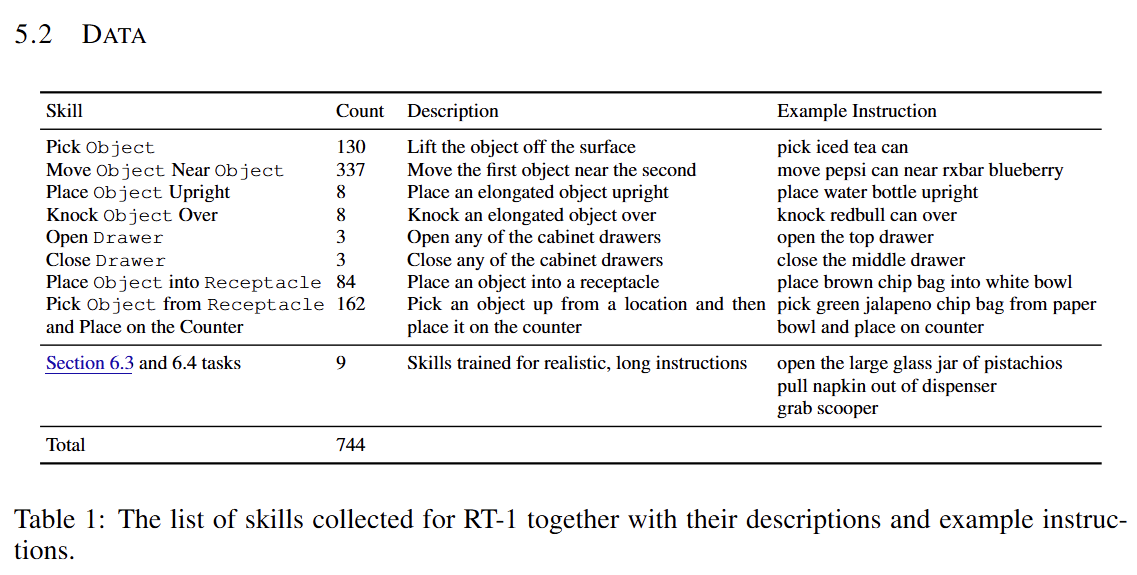
13대의 로봇으로 17개월에 걸쳐 13만 개의 시연 데이터를 수집했다.
데이터는 '물건 집기', '서랍 열기' 등과 같은 기술(skill) 그룹으로 분류되며, 총 744개의 구체적인 명령어로 구성된다 (Table 1 참조).
데이터 수집은 다양한 물체와 행동을 포함하도록 설계되어 모델의 일반화 능력을 극대화하고자 했다.
6. Experiments

6.1. Experimental Setup
-
하드웨어 및 환경
- 로봇: Everyday Robots의 mobile manipulator를 사용하여 실험을 수행
- 환경: 총 세 곳의 환경에서 평가 진행
- 학습 환경: 데이터 수집을 위해 제작된 모의 주방 환경
- 평가 환경 (실제 주방): 학습 환경과 유사한 조리대를 가졌으나, 조명, 배경, 전체적인 주방 구조(예: 찬장, 싱크대 유무 등)에서 차이가 있는 실제 사무실 주방 두 곳(Kitchen1, Kitchen2)에서 평가
-
평가 지표
: 모델의 성능, 일반화, 강건성을 측정하기 위해 다음과 같은 네 가지 지표를 사용했으며, 총 3,000회 이상의 실제 로봇 실험을 통해 평가됨-
학습된 작업 성능 (Seen task performance) : 학습 데이터셋에 포함된 명령어에 대한 수행 능력을 평가. 단, 물체의 위치나 로봇의 시작 위치 등은 매번 무작위로 변경되어, 현실적인 환경 변화에 대한 일반화 능력을 함께 측정. 물건 집기, 옮기기, 서랍 조작 등 총 200개 이상의 작업을 대상으로 테스트.
-
처음 보는 작업 일반화 (Unseen tasks generalization) : 학습 데이터에 포함되지 않은 21개의 새로운 명령어를 수행하는 능력을 평가. 명령어 자체는 새롭지만, 그 안에 포함된 개별 기술(skill)이나 객체는 학습 데이터에 다른 조합으로 등장한 적이 있음. 예를 들어, "사과 집기"가 평가 대상이라면 학습 데이터에는 "사과 옮기기"나 "콜라 캔 집기" 같은 관련 데이터가 포함됨
-
강건성 (Robustness) :
- 방해물(Distractor) 강건성: 장면에 방해물이 추가되었을 때의 성능 평가. 방해물의 수와 목표 객체의 가려짐 정도에 따라 쉬움(0-5개), 중간(9개), 어려움(9개, 가려짐) 난이도로 나누어 테스트
- 배경(Background) 강건성: 새로운 주방 환경이나 패턴이 있는 테이블보를 사용하는 등 시각적 배경이 바뀌었을 때의 성능 평가
-
장기 시나리오 (Long-horizon scenarios) : 여러 기술을 순차적으로 연결해야 하는 현실적인 장기 과제에 대한 일반화 성능을 평가."테이블 위 모든 물건 버리기"와 같은 상위 레벨의 지시사항을 SayCan 시스템을 이용해 자동으로 세부 단계로 나누어 수행하게 하고, 이를 통해 새로운 작업, 객체, 환경 등 여러 일반화 요소를 동시에 테스트
-
6.2 일반화 성능
CAN RT-1 LEARN TO PERFORM A LARGE NUMBER OF INSTRUCTIONS, AND TO GENERALIZE TO NEW TASKS, OBJECTS AND ENVIRONMENTS?
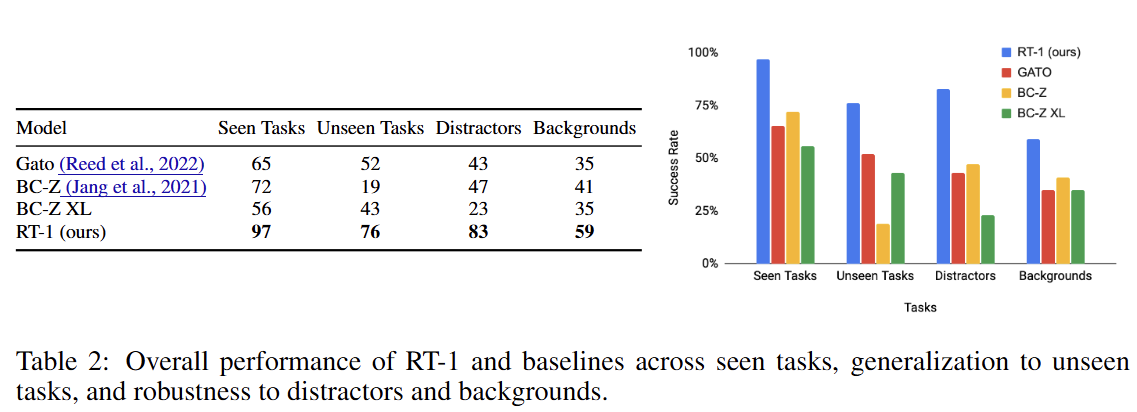
RT-1은 학습된 작업(Seen Tasks, 97%)뿐만 아니라, 처음 보는 작업(Unseen Tasks, 76%), 방해물이 있는 환경(Distractors, 83%), 새로운 배경(Backgrounds, 59%) 모두에서 Gato, BC-Z 등 비교 모델들을 큰 차이로 능가했다.

6.3 이종 데이터 흡수
CAN WE PUSH THE RESULTING MODEL FURTHER BY INCORPORATING HETEROGENEOUS DATA SOURCES SUCH AS SIMULATION OR DATA FROM DIFFERENT ROBOTS?
-
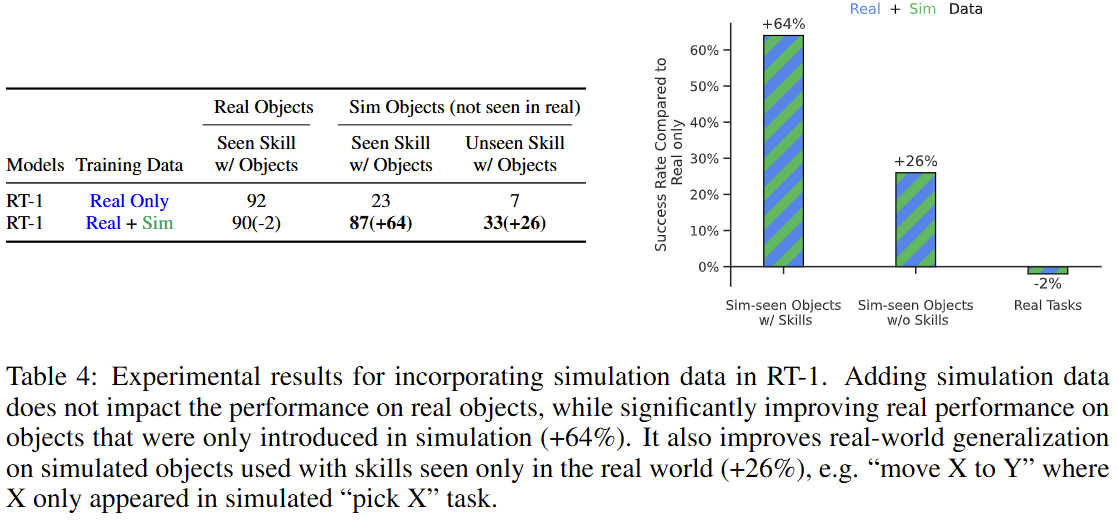
시뮬레이션 데이터: 실제 데이터에 시뮬레이션 데이터를 추가 학습했을 때, 실제 환경에서의 기존 작업 성능은 유지하면서(-2%) 시뮬레이션에서만 본 객체에 대한 실제 작업 성공률을 23%에서 87%로 크게 향상시켰다.
-
타 로봇 데이터: 다른 종류의 로봇(Kuka)이 수집한 데이터를 추가 학습했을 때도 기존 작업 성능 저하를 최소화하면서(-2%), Kuka 로봇의 작업 환경과 유사한 새로운 '상자 안 물건 집기' 작업의 성공률을 22%에서 39%로 약 2배 가까이 향상시켰다.
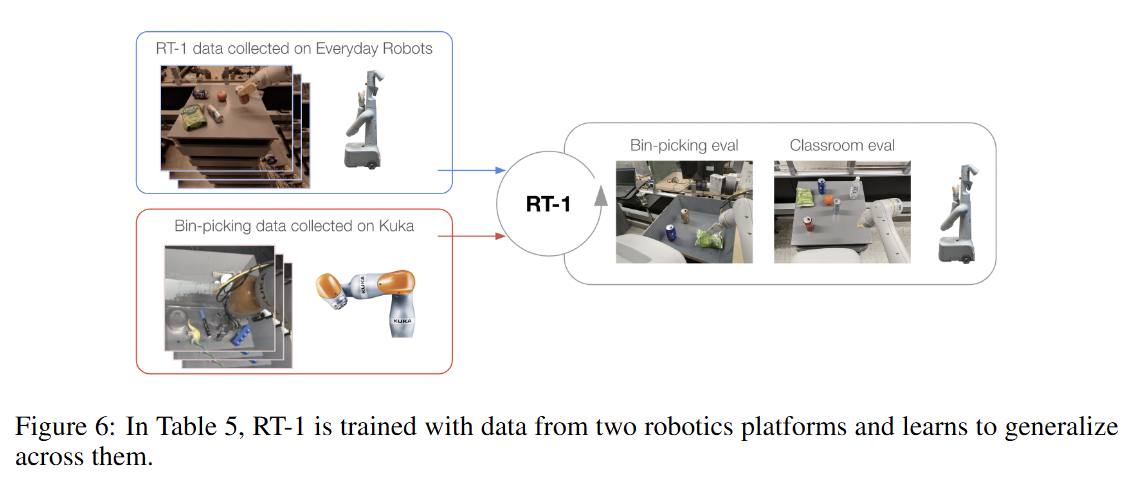
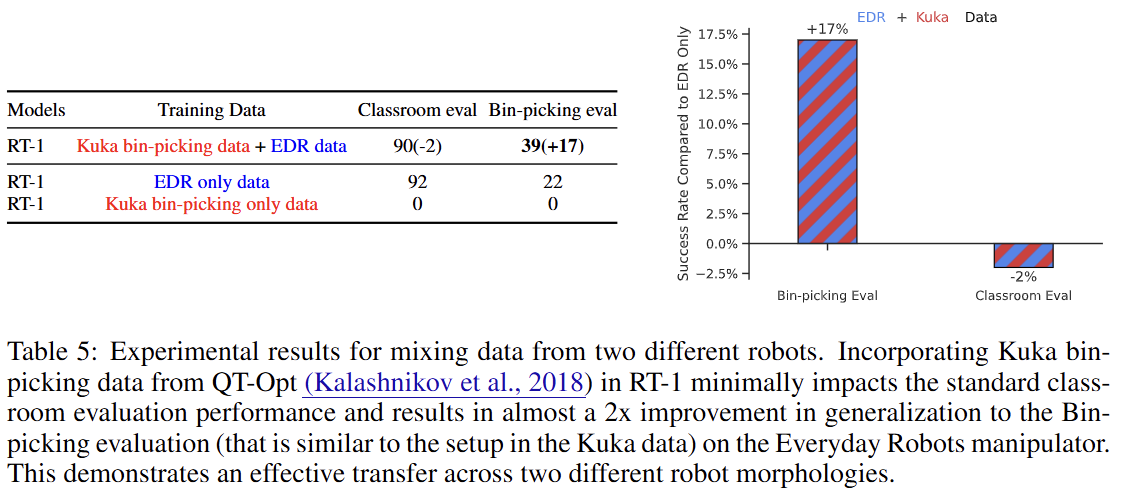
6.4. 장기 과제 수행
HOW DO VARIOUS METHODS GENERALIZE LONG-HORIZON ROBOTIC SCENARIOS?
SayCan 프레임워크와 결합하여 실제 주방 환경에서 장기 과제를 수행한 결과, RT-1은 67%의 성공률을 기록했다. 특히 학습 환경과 다른 두 번째 주방에서는 Gato가 0%, BC-Z가 13%의 성공률을 보인 반면, RT-1은 67%의 성능을 유지하며 뛰어난 환경 일반화 능력을 보였다.
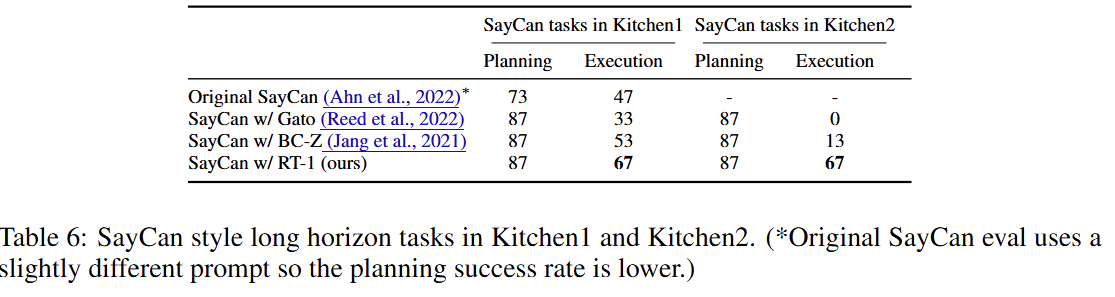
6.5 데이터 규모와 다양성
HOW DO GENERALIZATION METRICS CHANGE WITH VARYING AMOUNTS OF DATA QUANTITY AND DATA DIVERSITY?
데이터의 양(quantity)보다 다양성(diversity)이 일반화 성능에 더 큰 영향을 미쳤다. 작업의 25%를 제거하자(데이터 양은 97% 유지), 데이터 양을 49% 줄인 것과 비슷한 수준으로 일반화 성능이 하락했다.
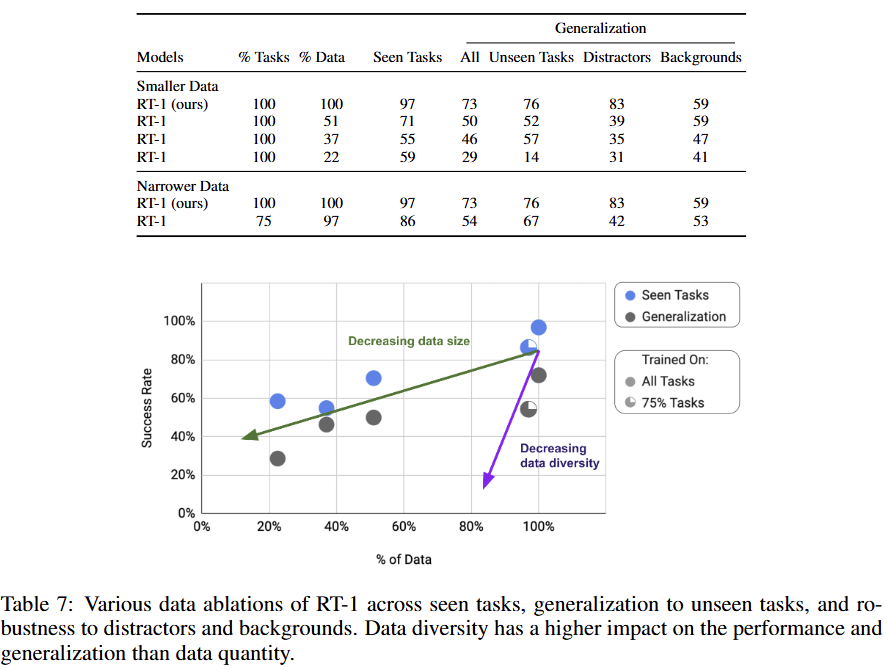
7. Conclusions, Limitations, and Future Work
-
결론: RT-1은 대규모의 다양한 데이터를 효과적으로 흡수하여 뛰어난 일반화 성능을 보이는 로봇 학습 방법임을 입증했다.
-
한계점:
- 시연자의 성능을 뛰어넘기 힘든 모방 학습의 근본적인 한계가 있다.
- 이전에 본 적 없는 완전히 새로운 동작을 생성하는 데는 한계가 있다.
- 다루는 작업이 고도의 정교함을 요구하지는 않는다.
- 향후 연구: 비전문가도 쉽게 데이터를 수집하고 모델을 학습시킬 수 있는 방법 개발, 환경 다양성 증대, 확장 가능한 어텐션 및 메모리 구조를 통한 반응 속도 개선 등을 향후 연구 방향으로 제시했다.
🔍 SayCan vs RT-1 비교
✨ 요약
SayCan과 RT-1은 로봇이 복잡한 작업을 수행하게 하는 서로 다른 계층의 문제를 해결하며, 함께 사용될 때 강력한 시너지를 내는 보완적인 관계에 있다. SayCan이 '무엇을 할지' 계획하는 고수준 두뇌 역할을 한다면, RT-1은 계획된 단계를 '어떻게 실행할지' 담당하는 강력한 저수준 실행기 역할을 한다.
| 구분 | SayCan (Do As I Can, Not As I Say) | RT-1 (Robotics Transformer 1) |
|---|---|---|
| 주요 목표 | 고수준 계획(High-Level Planning): "음료수를 쏟았어, 도와줘"와 같은 추상적이고 긴 지시사항을 이해하고, 로봇이 수행할 수 있는 구체적인 행동 순서로 변환하는 것을 목표로 한다. | 저수준 제어(Low-Level Control): "콜라 캔 집어"와 같은 구체적인 단일 명령을 정확하게 수행하는 범용 정책 모델을 만드는 것을 목표로 한다. |
| 역할 | 플래너 (Planner): 다음에 어떤 기술(skill)을 실행해야 가장 유용하고 성공 확률이 높은지 결정한다. 직접 로봇을 움직이지 않는다. | 실행기 (Executor/Policy): 플래너가 결정한 특정 기술을 수행하기 위해, 이미지 입력을 받아 실제 모터 명령을 생성한다. |
| 핵심 기술 | LLM과 가치 함수의 결합: 대규모 언어 모델(LLM)을 사용해 "어떤 기술이 지시사항에 유용한지(Say)"를 판단하고, 학습된 가치 함수(Value Function)를 통해 "로봇이 그 기술을 물리적으로 성공할 수 있는지(Can)"를 결합한다. | Transformer 기반 End-to-End 모델: 이미지와 언어 입력을 받아 이산화된(discretized) 로봇 행동을 직접 출력하는 단일 Transformer 모델이다. 대규모의 다양한 데이터 학습을 통해 높은 일반화 성능을 확보한다. |
| 관계 | RT-1과 같은 강력한 저수준 정책을 필요로 한다. RT-1이 제공하는 신뢰도 높은 기술 실행 능력이 있어야 SayCan의 계획이 의미를 가진다. | SayCan과 같은 고수준 플래너와 결합하여 장기 과제(long-horizon task)를 수행할 수 있다. RT-1 논문에서 SayCan을 활용해 50단계에 달하는 복잡한 작업을 수행하는 실험을 진행했다. |
✨ 비교 내용 정리
두 시스템의 핵심적인 차이와 관계는 다음과 같다.
1. 목표와 역할: 계획(Planning) vs. 실행(Execution)
-
SayCan은 '지시사항을 어떻게 나눌 것인가'에 집중한다. 예를 들어, "쏟은 음료수 치우는 것을 도와줘"라는 명령을 받으면, LLM의 지식을 활용해 "1. 스펀지 찾기, 2. 스펀지 집기, 3. 스펀지 가져오기" 와 같은 일련의 계획을 생성한다. 이때 로봇이 실제로 스펀지를 집을 수 있는 상태인지를 가치 함수(어포던스)로 확인하여 비현실적인 계획(예: 근처에 없는 진공청소기 사용)을 배제한다. -
RT-1은 SayCan이 생성한 계획의 각 단계, 즉 "스펀지 집기"와 같은 단일 명령을 실제로 수행하는 역할을 한다. RT-1은 13만 건이 넘는 방대한 실제 로봇 시연 데이터를 학습하여, 다양한 물체와 환경에서도 높은 성공률로 명령을 실행할 수 있는 강건함과 일반화 능력을 갖추었다.
2. 기술적 접근: 시스템 결합 vs. 단일 모델
-
SayCan은 두 개의 독립적인 시스템을 창의적으로 결합한 접근 방식이다.
Say (LLM): 웹의 방대한 텍스트로 학습된 의미론적 지식을 제공한다.
Can (Value Function): 로봇이 실제 환경에서 상호작용하며 학습한 물리적 실행 가능성(affordance) 정보를 제공한다. -
RT-1은 시각 정보와 언어 명령을 입력받아 직접 행동을 출력하는 잘 짜인 단일 End-to-End 모델이다. FiLM-EfficientNet, TokenLearner, Transformer를 결합한 효율적인 구조로 대규모 데이터를 효과적으로 흡수(absorb)하여 일반화 성능을 극대화하는 데 초점을 맞춘다.
3. 시너지 효과
RT-1 논문은 SayCan과 RT-1의 시너지를 명확하게 보여준다. 기존 SayCan은 BC-Z와 같은 비교적 간단한 정책을 실행기로 사용했지만, RT-1을 실행기로 사용함으로써 훨씬 더 복잡하고 어려운 장기 과제를 높은 성공률로 수행할 수 있게 되었다.
특히 RT-1의 뛰어난 일반화 덕분에 처음 보는 주방 환경(Kitchen2)에서도 성능 저하 없이 67%의 실행 성공률을 기록했으며, 이는 다른 모델들이 급격한 성능 저하를 보인 것과 대조된다.
결론적으로, SayCan은 로봇에게 추상적인 목표를 이해하고 논리적인 계획을 세우는 능력을 부여하고, RT-1은 그 계획의 각 단계를 현실 세계에서 신뢰도 높게 실행하는 신체 능력을 제공한다. 이 둘의 조합은 범용 로봇을 향한 중요한 진전을 보여준다.
