VGGNet
합성곱층의 파라미터 수를 줄이고 훈련 시간을 개선하기 위해 탄생했다. 즉, 네트워크 깊이가 성능에 어떤 영향을 끼치는지 확인하고자 개발된 모델이다. VGG는 깊이의 영향을 확인하기 위해 합성곱층에서 사용하는 필터와 커널의 크기를 가장 작은 3X3으로 고정했다.
네트워크 계층 총 개수에 따라 VGG16 ,VGG19 등으로 나뉘며, VGG16의 네트워크 구조는 다음과 같다.
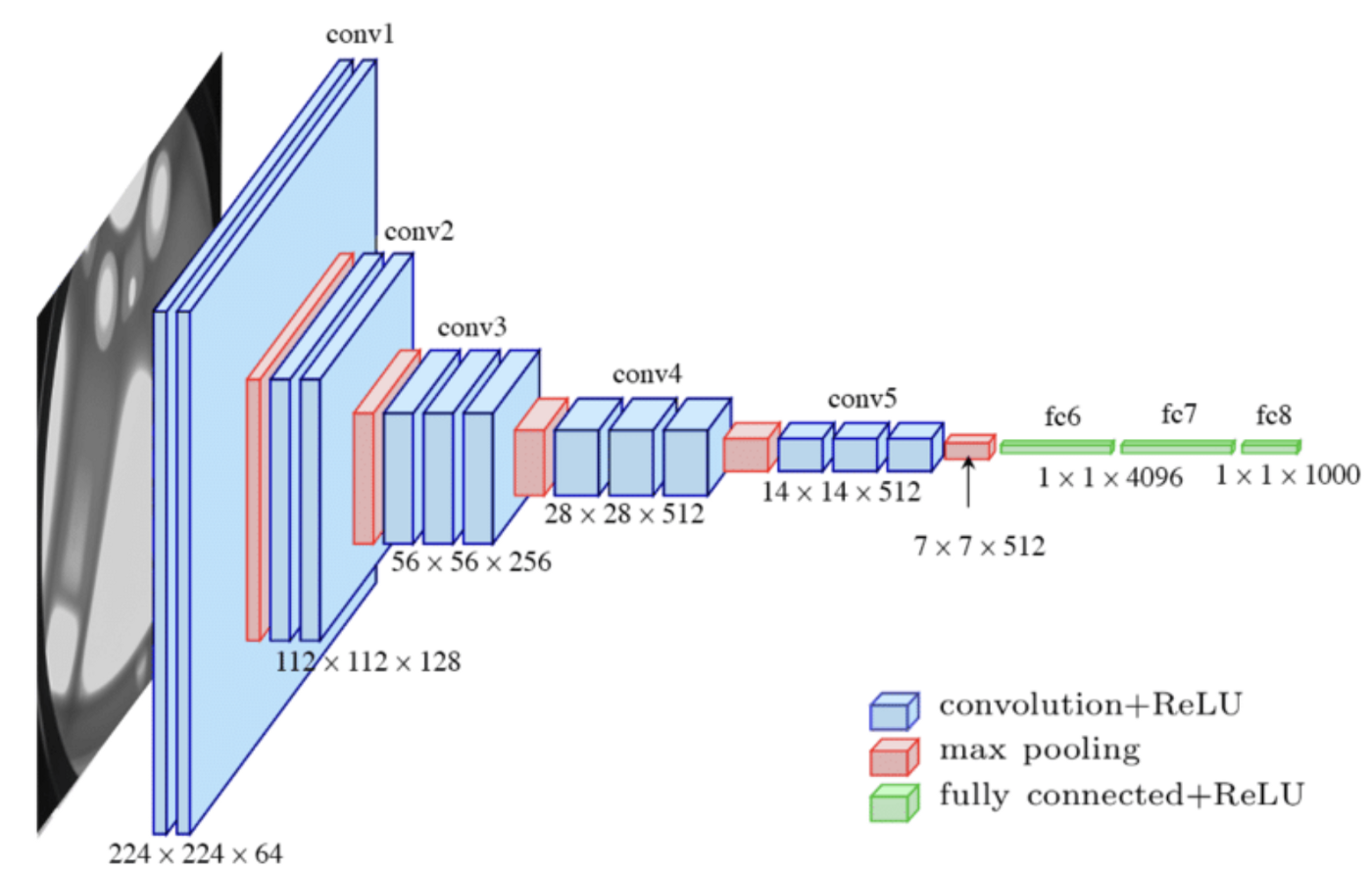
VGG16은 총 1억 3300만개의 파라미터를 가지며, 모든 합성곱 커널 크기는 3X3, 최대 풀링 커널 크기는 2X2이며, 스트라이드는 2이다. 결과적으로 64개의 224X224 특성맵(224X224X64)들이 생성된다. 마지막 16번째 계층을 제외하고 모두 ReLU 활성화 함수가 적용된다.
| 계층 유형 | 특성 맵 | 크기 | 커널 크기 | 스트라이드 | 활성화 함수 |
|---|---|---|---|---|---|
| 이미지 | 1 | 224X224 | - | - | - |
| 합성곱층 | 64 | 224X224 | 3X3 | 1 | ReLU |
| 합성곱층 | 64 | 224X224 | 3X3 | 1 | ReLU |
| 최대 풀링층 | 64 | 112X112 | 2X2 | 2 | - |
| 합성곱층 | 128 | 112X112 | 3X3 | 1 | ReLU |
| 합성곱층 | 128 | 112X112 | 3X3 | 1 | ReLU |
| 최대 풀링층 | 128 | 56X56 | 2X2 | 2 | - |
| 합성곱층 | 256 | 56X56 | 3X3 | 1 | ReLU |
| 합성곱층 | 256 | 56X56 | 3X3 | 1 | ReLU |
| 합성곱층 | 256 | 56X56 | 3X3 | 1 | ReLU |
| 합성곱층 | 256 | 56X56 | 3X3 | 1 | ReLU |
| 최대 풀링층 | 256 | 28X28 | 2X2 | 2 | - |
| 합성곱층 | 512 | 28X28 | 3X3 | 1 | ReLU |
| 합성곱층 | 512 | 28X28 | 3X3 | 1 | ReLU |
| 합성곱층 | 512 | 28X28 | 3X3 | 1 | ReLU |
| 합성곱층 | 512 | 28X28 | 3X3 | 1 | ReLU |
| 최대 풀링층 | 512 | 14X14 | 2X2 | 2 | - |
| 합성곱층 | 512 | 14X14 | 3X3 | 1 | ReLU |
| 합성곱층 | 512 | 14X14 | 3X3 | 1 | ReLU |
| 합성곱층 | 512 | 14X14 | 3X3 | 1 | ReLU |
| 합성곱층 | 512 | 14X14 | 3X3 | 1 | ReLU |
| 최대 풀링층 | 512 | 7X7 | 2X2 | 2 | - |
| 완전연결층 | - | 4096 | - | - | ReLU |
| 완전연결층 | - | 4096 | - | - | ReLU |
| 완전연결층 | - | 1000 | - | - | Softmax |
VGG11 구현(pytorch)
# import library
import copy # copy object
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torch.utils.data as data
import torchvision
import torchvision.transforms as transforms
import torchvision.datasets as Datasets
import time
import matplotlib.pyplot as plt
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')# define vgg model
class VGG(nn.Module) :
def __init__(self, features, output_dim) :
super().__init__()
self.features = features
self.avgpool = nn.AdaptiveAvgPool2d(7)
self.classifier = nn.Sequential(
nn.Linear(512*7*7, 4096),
nn.ReLU(inplace=True),
nn.Dropout(0.5),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Dropout(0.5),
nn.Linear(4096, output_dim)
)
def forward(self, x) :
x = self.features(x)
x = self.avgpool(x)
h = x.view(x.shape[0], -1)
x = self.classifier(h)
return x, hVGG 모델을 정의한다.
# define model type
vgg11_config = [64, 'M', 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M']
vgg13_config = [64, 64, 'M', 128, 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M']
vgg16_config = [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512,
'M', 512, 512, 512, 'M']
vgg19_config = [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 256, 'M', 512, 512,
512, 512, 'M', 512, 512, 512, 512, 'M']모델 유형을 정의한다. VGG11, VGG13, VGG16, VGG19 모델 계층을 정의한 것으로, 숫자는 Conv2d를 수행하라는 의미이며, 출력 채널이 다음 계층 입력 채널이 된다. M은 Maxpooling 수행을 의미한다.
# Define VGG-layer
def get_vgg_layers(config, batch_norm) :
layers = []
in_channels = 3
for c in config :
assert c == 'M' or isinstance(c, int)
if c == 'M' : # adapt Maxpooling for 'M'
layers += [nn.MaxPool2d(kernel_size=2)]
else : # adapt Conv2d for numbers
conv2d = nn.Conv2d(in_channels, c, kernel_size=3, padding=1)
if batch_norm : # batch normalization
layers += [conv2d, nn.BatchNorm2d(c), nn.ReLU(inplace=True)]
# batch normalization + ReLU
else :
layers += [conv2d, nn.ReLU(inplace=True)]
in_channels = c
return nn.Sequential(*layers) # 네트워크 모든 계층 반환VGG 모델 네트워크를 정의한다. 여기서는 VGG11을 구현하고자 하므로 앞서 정의한 vgg11_config를 사용한다.
vgg11_layers = get_vgg_layers(vgg11_config, batch_norm=True)
print(vgg11_layers)
모델 계층을 생성한다.
여기서batch_norm(배치 정규화)은 데이터의 평균을 0, 표준편차를 1로 분포시키는 것이다. 각 계층에서 입력 데이터의 분포는 앞 계층에서 업데이트된 가중치에 따라 변하기 때문에, 정규화를 해주지 않으면 학습 속도가 늦어지고 학습이 어려워진다.
output_dim = 2 # class numb
model = VGG(vgg11_layers, output_dim)
print(model)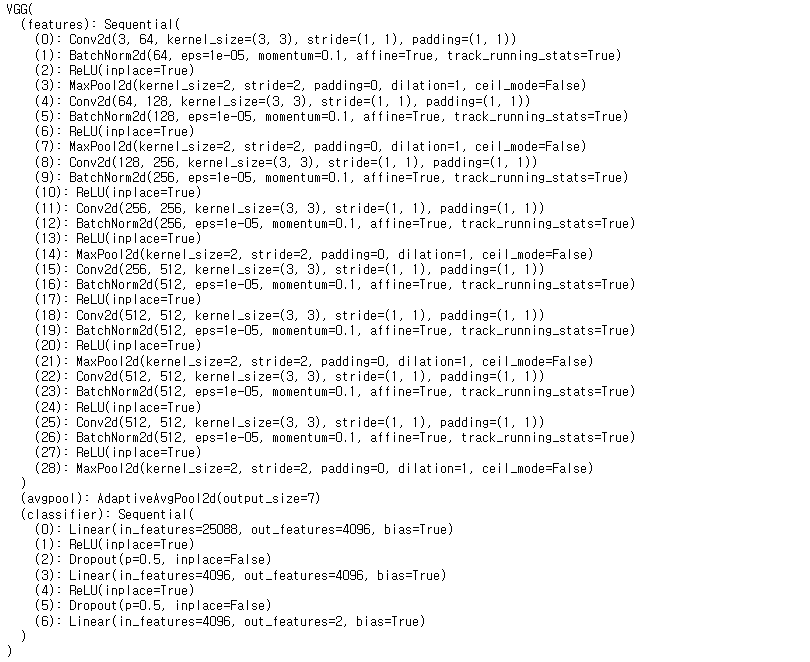
VGG11 전체 네트워크를 출력한다.
# use pretrained VGG model
import torchvision.models as models
pretrained_model = models.vgg11_bn(pretrained=True)
print(pretrained_model)
pretrained=True옵션으로 사전학습된 VGG 모델을 가져다 사용할 수 있다.
# image preprocess
train_transforms = transforms.Compose([
transforms.Resize((256, 256)),
transforms.RandomRotation(5),
transforms.RandomHorizontalFlip(0.5),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
test_transforms = transforms.Compose([
transforms.Resize((256, 256)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229,0.224, 0.225])
])이미지 전처리 부분을 정의한다.
train_path = '../080289-main/chap06/data/catanddog/train'
test_path = '../080289-main/chap06/data/catanddog//test'
train_dataset = torchvision.datasets.ImageFolder(
train_path,
transform=train_transforms)
test_dataset = torchvision.datasets.ImageFolder(
test_path,
transform=test_transforms)
print(len(train_dataset), len(test_dataset))ImageFolder로 모델 학습에 필요한 데이터셋을 불러온다.
# split dataset
valid_size = 0.9
n_train_examples = int(len(train_dataset) * valid_size)
n_valid_examples = len(train_dataset) - n_train_examples
train_data, valid_data = data.random_split(train_dataset,
[n_train_examples, n_valid_examples])데이터를 분할한다(9:1)
valid_data = copy.deepcopy(valid_data)
valid_data.dataset.transform = test_transforms검증 데이터에 전처리를 적용한다.
print(f'Number of training examples : {len(train_data)}')
print(f'Number of validation examples : {len(valid_data)}')
print(f'Number of testing examples : {len(test_dataset)}')데이터 셋 분포를 확인한다.
batch_size = 128
train_iterator = data.DataLoader(train_data,
shuffle=True,
batch_size=batch_size)
valid_iterator = data.DataLoader(valid_data,
batch_size=batch_size)
test_iterator= data.DataLoader(test_dataset,
batch_size=batch_size)DataLoader로 데이터셋의 데이터를 메모리로 가져온다.
optimizer = optim.Adam(model.parameters(), lr=1e-7)
criterion = nn.CrossEntropyLoss()
model = model.to(device)
criterion = criterion.to(device)옵티마이저와 손실함수를 정의한다.
def calculate_accuracy(y_pred, y) :
top_pred = y_pred.argmax(1, keepdim=True)
correct = top_pred.eq(y.view_as(top_pred)).sum()
acc = correct.float() / y.shape[0]
return acc모델 정확도를 측정하는 함수를 정의한다.
def train(model, iterator, optimizer, criterion, device) :
epoch_loss = 0
epoch_acc = 0
model.train()
for (x, y) in iterator :
x = x.to(device)
y = y.to(device)
optimizer.zero_grad()
y_pred, _ = model(x)
loss = criterion(y_pred, y)
acc = calculate_accuracy(y_pred, y)
loss.backward()
optimizer.step()
epoch_loss += loss.item()
epoch_acc += acc.item()
return epoch_loss / len(iterator), epoch_acc / len(iterator)모델을 학습시키는 함수를 정의한다.
def evaluate(model, iterator, criterion, device) :
epoch_loss = 0
epoch_acc = 0
model.eval()
with torch.no_grad() :
for (x, y) in iterator :
x = x.to(device)
y = y.to(device)
y_pred, _ = model(x)
loss = criterion(y_pred, y)
acc = calculate_accuracy(y_pred, y)
epoch_loss += loss.item()
epoch_acc += acc.item()
return epoch_loss / len(iterator), epoch_acc / len(iterator)
검증 및 테스트 데이터셋을 통한 모델 성능 측정 함수를 정의한다.
def epoch_time(start, end) :
elapsed_time = end - start
elapsed_mins = int(elapsed_time / 60)
elapsed_secs = int(elapsed_time - (elapsed_mins * 60))
return elapsed_mins, elapsed_secs모델 학습 시간을 측정하는 함수를 정의한다.
# train model
epochs = 5
best_valid_loss = float('inf')
for epoch in range(epochs) :
start = time.monotonic()
train_loss, train_acc = train(model, train_iterator, optimizer, criterion, device)
valid_loss, valid_acc = evaluate(model, valid_iterator, criterion, device)
if valid_loss < best_valid_loss :
best_valid_loss = valid_loss
torch.save(model.state_dict(), '../data/VGG-model.pt')
end = time.monotonic()
epoch_mins, epoch_secs = epoch_time(start, end)
print(f'Epoch : {epoch+1:02} | Epoch Time : {epoch_mins}m {epoch_secs}s')
print(f'\t Train Loss : {train_loss:.3f} | Train Acc : {train_acc*100:.2f}%')
print(f'\t Valid Loss : {valid_loss:.3f} | Train Acc : {valid_acc*100:.2f}%') 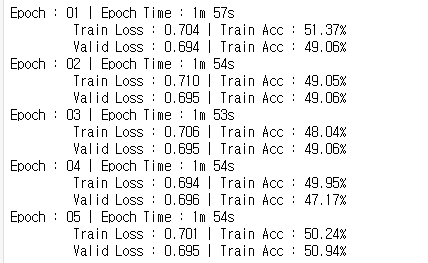
모델을 학습시킨다. 데이터셋으로 사용되는 이미지 수가 적고, 에포크도 적기 때문에 성능이 좋지 않다. 성능을 향상시키려면 더 많은 데이터셋을 사용해야 할 것이다.
# 테스트 데이터셋 성능 측정
model.load_state_dict(torch.load('../data/VGG-model.pt'))
test_loss, test_acc = evaluate(model, test_iterator, criterion, device)
print(f'Test Loss : {test_loss:.3f} | Test Acc : {test_acc*100:.2f}%')저장된 모델을 불러와 테스트 데이터셋 성능을 측정한다.
# 모델 예측 확인
def get_predictions(model, iterator) :
model.eval()
images = []
labels = []
probs = []
with torch.no_grad() :
for (x, y) in iterator :
x = x.to(device)
y_pred, _ = model(x)
y_prob = F.softmax(y_pred, dim=-1)
top_pred = y_prob.argmax(1, keepdim=True)
images.append(x.cpu())
labels.append(y.cpu())
probs.append(y_prob.cpu())
images = torch.cat(images, dim=0)
labels = torch.cat(labels, dim=0)
probs = torch.cat(probs, dim=0)
return images, labels, probs테스트 데이터셋을 이용하여 모델 예측을 확인하는 함수를 정의한다.
images, labels, probs = get_predictions(model, test_iterator)
pred_labels = torch.argmax(probs, 1)
corrects = torch.eq(labels, pred_labels)
correct_examples = []
for image, label, prob, correct in zip(images, labels, probs, corrects) :
if correct :
correct_examples.append((image, label, prob))
correct_examples.sort(reverse=True, key=lambda x : torch.max(x[2], dim=0).values)예측한 결과 중에 정확하게 예측된 것을 추출한다.
def normalize_image(image) : # 이미지를 출력하기 위해 전처리
image_min = image.min()
image_max = image.max()
image.clamp_(min=image_min, max=image_max)
image.add_(-image_min).div_(image_max-image_min+1e-5)
return image
def plot_most_correct(correct, classes, n_images, normalize=True) : # 이미지 출력용 함수
rows = int(np.sqrt(n_images))
cols = int(np.sqrt(n_images))
fig = plt.figure(figsize=(25, 20))
for i in range(rows*cols) :
ax = fig.add_subplot(rows, cols, i+1)
image, true_label, probs = correct[i]
image = image.permute(1, 2, 0)
true_prob = probs[true_label]
correct_prob, correct_label = torch.max(probs, dim=0)
true_class = classes[true_label]
correct_class = classes[correct_label]
if normalize :
image = normalize_image(image)
ax.imshow(image.cpu().numpy())
ax.set_title(f'True label : {true_class} ({true_prob:.3f})\n' \
f'Pred label : {correct_class} ({correct_prob:.3f})')
ax.axis('off')
fig.subplots_adjust(hspace=0.4)
classes = test_dataset.classes
n_images = 5
plot_most_correct(correct_examples, classes, n_images) 
이미지 출력 함수를 정의하고 예측 결과를 출력해 본다.
📚 reference
- (길벗) 딥러닝 파이토치 교과서 / 서지영 지음
- github
