이번에 정리할 논문은 YOLO9000 : Better, Faster, Stronger 이다. YOLO 시리즈를 정리한 서머리 논문도 읽고 있어서 이 포스팅 이후로 조만간 YOLO 모델별로 비교글도 올릴 예정이다.
Abstract
본 논문에서는 9000개 이상의 객체 카테고리를 탐지할 수 있는 SOTA 실시간 객체 탐지 시스템인 YOLO9000을 소개한다. 먼저, 본 논문은 YOLO 탐지 방식에 대한 다양한 개선사항(새로운 방법+이전 연구에서 착안한 방법)을 제시한다. 개선된 모델 YOLOv2는 PASCAL VOC와 COCO 같은 표준 탐지 태스크에서 SOTA의 성적을 거둔다. 새로운 멀티 스케일 훈련 방식을 사용하면, 동일한 YOLOv2 모델을 다양한 크기에서 실행할 수 있고, 속도와 정확도 간의 단순한 trade-off를 제공한다.
YOLOv2는 VOC 2007 데이터에서 67FPS, 76.8mAP를 달성한다. 40FPS에서는 78.6mAP를 달성하고, ResNet과 SSD를 탑재한 Faster R-CNN과 같은 SOTA 방법들의 성능을 능가하며, 훨씬 더 빠르게 작동한다. 마지막으로, 본 논문에서는 객체 탐지(detection)와 분류(classification)를 공동으로 훈련시키는 방법을 제시한다. 이 방법을 통해 COCO detection dataset과 ImageNet classification dataset에서 YOLO9000을 동시에 훈련시킨다. 공동 훈련(joint training)은 YOLO9000이 라벨링된 탐지 데이터를 갖지 않는 객체 클래스도 예측할 수 있도록 한다. 이러한 접근법은 ImageNet detection task에서 검증된다.
YOLO9000은 200개의 클래스 중 44개의 detection data만 갖고 있음에도 불구하고, ImageNet detection validation set에서 19.7mAP을 달성한다. COCO에 없는 156개의 클래스에서는 16.0mAP를 달성한다. 그러나, YOLO는 200개를 넘는 클래스를 탐지할 수 있다. YOLO는 9000개 이상의 다양한 객체 카테고리의 탐지를 예측하며 실시간으로 작동한다.
1. Introduction
일반적인 목적의 객체 탐지는 빠르고, 정확하고, 다양한 객체를 인식할 수 있어야 한다. 신경망의 도입 이래로, 탐지 프레임워크는 점진적으로 빠르고 정확해져 왔다. 그러나, 대부분의 탐지 방법은 아직까지 적은 객체 셋에 한정되어 있다.
현재 객체 탐지 데이터셋은 분류나 태깅과 같은 태스크의 데이터셋과 비교했을때 한정되어 있다. 가장 일반적인 객체 데이터셋은 수십~수백개의 태그(tag)와 수천~수십만 개의 이미지를 포함하고 있다. 분류 데이터셋은 수백만 개의 이미지를 가지고 있다.
본 논문에서는 탐지 태스크를 객체 분류 수준까지 확장하고자 한다. 그러나, 탐지를 위한 이미지 라벨링은 분류나 태깅(태깅은 보통 사용자로부터 무료로 제공된다)보다 훨씬 더 많은 비용이 든다. 그러므로, 본 논문에서는 탐지 데이터셋을 분류 데이터셋과 동일한 규모로 보려고 하지 않는다.
본 논문에서는 우리가 이미 가지고 있는 대규모의 분류 데이터를 이용하는 새로운 방법을 제시하고, 이러한 방법을 사용하여 현재의 detection system의 반경을 확장하고자 한다. 이러한 방법은 별개의 데이터셋을 결합할 수 있도록 하는 계층형 객체 분류 관점을 사용한다.
또한, 본 논문에서는 탐지와 분류 데이터에서 모두 객체 탐지기를 훈련할 수 있도록 하는 공동의 훈련 알고리즘을 제안하다. 이러한 방법은 라벨링 된 탐지 이미지를 이용하여 객체의 위치를 정확하게 특정하는 방법을 훈련하며, 분류 이미지를 사용하여 어휘와 강건함을 향상시킨다.
이러한 방법들을 사용하여 9000개 이상의 객체 카테고리를 탐지할 수 있는 실시간 객체 탐지기, YOLO9000를 훈련시킨다. base YOLO system을 개선하여 SOTA, realtime detector YOLOv2를 만들고, 앞서 언급한 데이터셋 결합 방법과 공동 훈련 알고리즘을 사용하여 COCO의 detection data 뿐만 아니라, 9000개 이상의 클래스를 가진 ImageNet에서 모델을 훈련시킨다.

2. Better
YOLO는 SOTA detection system과 비교하여 다양한 결점이 있다. Fast R-CNN과 비교했을 때 YOLO의 오분석을 보면 YOLO가 상당히 많은 localization error를 발생시킨다는 것을 알 수 있다. 게다가, YOLO는 region proposal-based method(RPN)에 비해 낮은 재현율(recall)을 보인다. 따라서, 본 논문에서는 주로 재현율과 localization을 향상시키면서 분류 정확도를 유지하고자 한다.
- Region Proposal-based method(RPN)
Faster R-CNN에서 제안된 개념으로, 각 position에서 object bounds와 objectness score를 동시에 예측하는 fully convolutional network이다. RPN은 end-to-end로 훈련되어 high quality의 region proposal을 생성한다. RPN과 Fast R-CNN과 같은 알고리즘들은 convolutional features를 공유함으로써 단일 네트워크로 병합될 수 있다.
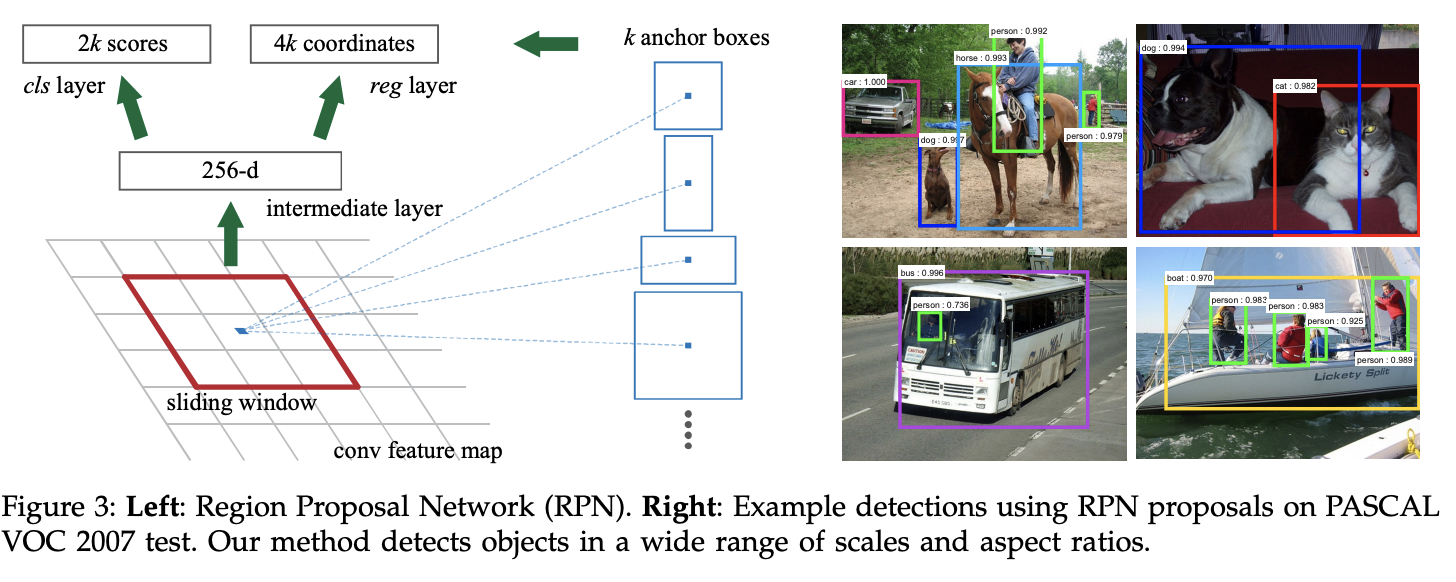
RPNs은 region proposals을 다양한 규모와 aspect 비율에서 효율적으로 예측하기 위해 설계되었다. RPN은 multiple scale과 aspect ratio에서 reference로 작용하는 앵커 박스를 사용한다. 이러한 전략은 regression reference의 pyramid 구조로, multiple scale이나 aspect ratio의 이미지나 필터를 나열하는 것을 피한다.
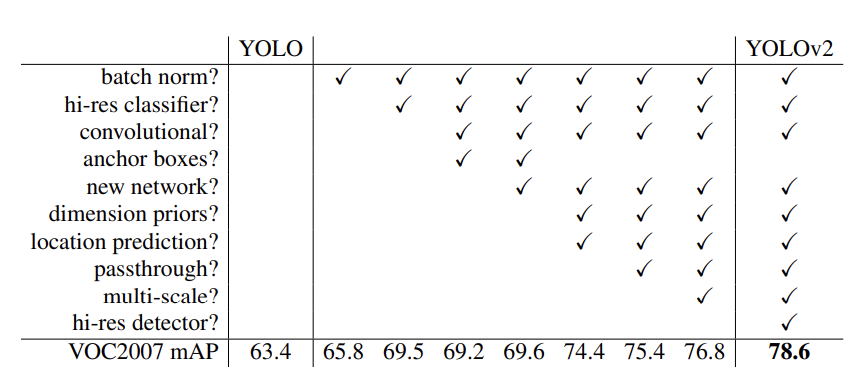
computer vision은 일반적으로 더 크고, 더 깊은 신경망이 트렌드가 되었다. 더 좋은 성능은 보통 더 큰 신경망의 훈련이나 여러 모델의 앙상블에 달려 있다. 그러나, YOLOv2에서는 빠른 속도를 유지하면서, 더 정확한 탐지기를 추구한다. 네트워크의 규모를 키우지 않고, 네트워크를 단순화 한 다음 representation을 더 훈련하기 쉽도록 만든다. YOLO 성능을 향상시키는 새로운 개념을 다루었던 선행 연구에서 다양한 발상을 모아왔고, Table 2에 그 결과가 요약되어 있다.
Batch Normalization (배치 정규화). 배치 정규화(BN)는 다른 규제 형식에 대한 필요성을 없애면서도 수렴(convergence)을 크게 개선한다. YOLO의 모든 컨볼루션 레이어에 배치 정규화를 추가함으로써, mAP에서 2%의 성능 향상을 얻는다. 배치 정규화는 모델의 정규화를 돕기도 한다. 배치 정규화를 사용하면, 과적합(overfitting) 없이 모델의 드롭아웃을 제거할 수 있다.
High Resolution Classifier (고해상도 분류기). 모든 SOTA detection 방법은 ImageNet에서 사전학습된 분류기를 사용한다. AlexNet부터 시작해서, 대부분의 분류기들은 256x256보다 작은 크기의 입력 이미지에서 작동한다. 원조 YOLO 모델은 224x224에서 분류기 네트워크를 훈련시키고, 탐지에서는 448로 해상도를 향상시킨다. 이는 네트워크가 객체 탐지 훈련으로 전환하면서 동시에 새로운 입력 해상도로 조정해야 한다는 것을 의미한다.
YOLOv2에서는, 먼저 분류 네트워크를 448x448 해상도로 ImageNet에서 10 epochs동안 파인튜닝한다. 이러한 과정은 네트워크가 더 높은 해상도 입력에서 더 잘 작용하도록 필터를 적응시킬 시간을 준다. 그리고 나서, 탐지에 대한 resulting network를 파인튜닝한다. 이러한 고해상도 분류 네트워크는 4%가량의 mAP를 향상시킨다.
Convolutional With Anchor Boxes (앵커 박스와의 컨볼루션). YOLO는 컨볼루션 특징 추출기(feature extractor) 위에 완전 연결층(fully connected layers)을 사용하여 직접적으로 바운딩 박스의 좌표를 예측한다. Faster R-CNN은 직접적으로 좌표를 예측하지 않고, 미리 선택된 사전 값(hand-picked priors)을 사용하여 바운딩 박스를 예측한다. Faster R-CNN의 region proposal network(RPN)은 컨볼루션 레이어만을 사용하여 앵커 박스의 offset과 confidence를 예측한다. 예측 레이어가 컨볼루션이기 때문에, RPN은 이러한 offset을 특징 맵의 모든 위치에서 예측하게 된다. 좌표 대신 offset을 예측하는 것은 문제를 단순화하고, 네트워크가 훈련하기 더 편하게 만든다.
본 논문에서는 YOLO의 완전연결층을 제거하고, 앵커 박스(anchor boxes)를 사용하여 바운딩 박스를 예측한다. 먼저, 풀링 레이어 하나를 제거하여 네트워크의 convolutional layer의 출력을 더 높은 해상도로 만들고자 한다. 또한, 입력 이미지를 448x448에서 416으로 축소시켜 작동하도록 한다. 이러한 작업은, 특징 맵에 홀수 개의 locations를 만들어 단일 center cell이 생기도록 하기 위함이다. 객체, 특히 큰 객체는 이미지의 센터를 차지하는 경향이 있기 때문에, 중앙에 단일 location을 갖는 것이 근처 4개의 location을 갖는 것보다 이러한 객체를 예측하기 좋다. YOLO의 convolution layer는 입력 이미지를 32로 다운샘플링하고, 따라서 416의 입력 이미지를 사용했을 때 13x13의 출력 특성 맵을 얻을 수 있다.
앵커 박스의 경우도 클래스 예측 매커니즘을 공간적 위치에서 분리(decouple)하고, 대신 모든 앵커 박스에 대한 클래스와 객체성(objectness)을 예측한다. YOLO를 계승하여, 객체성 예측은 실제 값(GT)과 제안된 박스의 IOU를 예측하고, 클래스 예측은 한 객체가 주어졌을 때 특정 클래스에 대한 조건부 확률을 예측(conditional probability)한다.
앵커 박스를 사용하여 정확도가 약간 하락했다. YOLO는 이미지당 98개의 박스만 예측하지만, 앵커 박스를 사용한 모델은 천 개 이상을 예측하게 된다. 앵커 박스가 없다면, 중급 모델은 재현율 81%와 69.5mAP를 달성한다. 비록 mAP가 감소하였지만, 재현율의 상승을 보면 본 논문에서 제안한 모델이 더 향상될 여지가 있음을 알 수 있다.
Dimension Clusters (차원 클러스터). YOLO에 앵커 박스를 사용했을 때, 두 가지 문제에 직면하게 된다. 첫 번째는 박스의 차원이 선택(hand-pick)되었다는 것이다. 신경망은 대략적으로 박스에 적응하도록 훈련하지만, 신경망에서 더 좋은 선행 값을 골라서 시작한다면, 네트워크가 더 좋은 탐지 예측을 하도록 훈련하는 것이 쉬워질 수 있다.
직접 선행 값을 고르지 않고, 훈련 세트의 바운딩 박스를 k-means clustering하여 자동으로 좋은 선행값을 찾도록 한다. 유클리디안 거리를 사용한 표준 k-means를 사용하게 되면, 더 큰 박스들이 작은 박스보다 더 많은 에러를 생성한다. 그러나, 좋은 IOU score를 얻기 위한 선행값은 박스의 크기에 독립적인 값이다. 따라서, 본 논문에서 사용한 거리 계량법은 다음과 같다 :
다양한 값의 k에서 k-means를 시행하고 가장 가까운 센터점과 평균 IOU를 그린다. (Figure 2 참조).
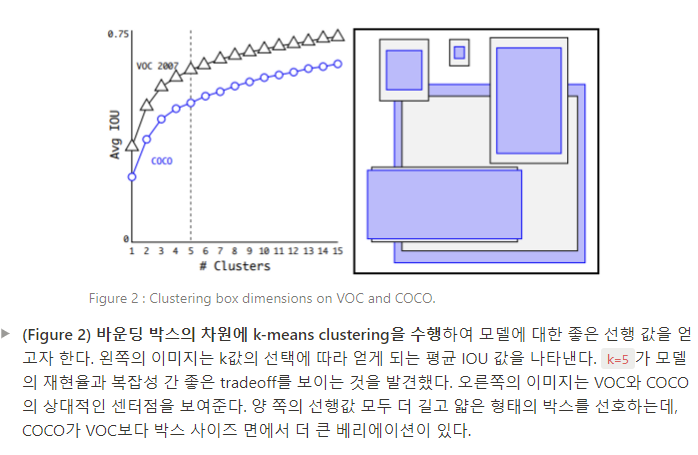
Figure 2에 따라, k=5를 모델 복잡성과 높은 재현율 간 좋은 상충 값으로 선택한다. 클러스터의 센터점은 수작업으로 선택한 앵커 박스와는 큰 차이가 있다. 클러스터 센터점들은 짧고 넓은 박스가 적고, 더 크고 얇은 형태의 박스가 많다.
평균 IOU 값을 본 논문의 클러스터링 전략에서 가장 가까운 선행값과 수작업으로 선택한 앵커 박스를 비교한다 (Table 1).
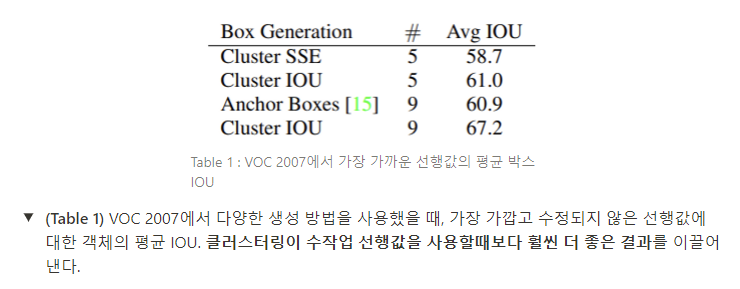
5개의 선행값에서만 센터점이 9개의 앵커 박스와 유사한 성능을 보이고, 평균 IOU는 61.0 vs 60.9로 비슷하다. 9개의 센터점을 사용하면 더 높은 평균 IOU값을 얻을 수 있다. 이는 k-means를 사용하여 바운딩 박스를 생성하는 것이 모델이 더 좋은 representation으로 시작하게 하고 훈련이 더 쉬워지게 한다는 것을 입증한다.
Direct location prediction (직접적인 위치 예측). YOLO와 앵커 박스를 같이 사용했을 때, 두 번째 문제에 직면하게 된다 : 모델의 불안정성(instability), 특히 초기 이터레이션에서 발생한다. 대부분의 불안정성은 박스의 (x, y) 위치를 예측하는 것에서 초래된다. region proposal network(RPN)에서는 와 , 센터 좌표가 다음과 같이 연산된다 :
예를 들면, 이라고 예측하는 것은 앵커 박스의 너비만큼 박스를 오른쪽으로 움직이고, 이라고 예측하는 것은 앵커 박스의 너비만큼 박스를 왼쪽으로 움직이게 된다. 이러한 형식은 한정되어있지 않고, 따라서 모든 앵커 박스는 어떤 위치가 박스를 예측했는지와 관계 없이 이미지의 어떤 점에도 배치될 수 있다. 랜덤 초기화를 사용하면 모델이 합리적인 오프셋을 예측하는 데 오랜 시간이 걸린다. 이러한 방법 대신, 본 논문에서는 YOLO의 접근법을 따라 그리드 셀의 위치에 비례하여 위치 좌표를 예측한다. 이러한 방법은 ground truth가 0~1 사이 값이 되도록 제한한다. 본 논문에서는 네트워크 예측이 이 범위 내에 한정되도록 로지스틱 활성화(logistic activation)를 사용하여 제약을 가한다.
네트워크는 출력 특징 맵의 각 셀에서 5개의 바운딩 박스를 예측한다. 네트워크는 각 바운딩 박스에 대하여 5개의 좌표()를 예측한다. 어떤 셀이 를 기준으로 이미지의 왼쪽 상단 코너에 오프셋이고, 바운딩 박스 선행값이 너비와 높이 , 를 갖는다면 예측 값은 다음과 같다.
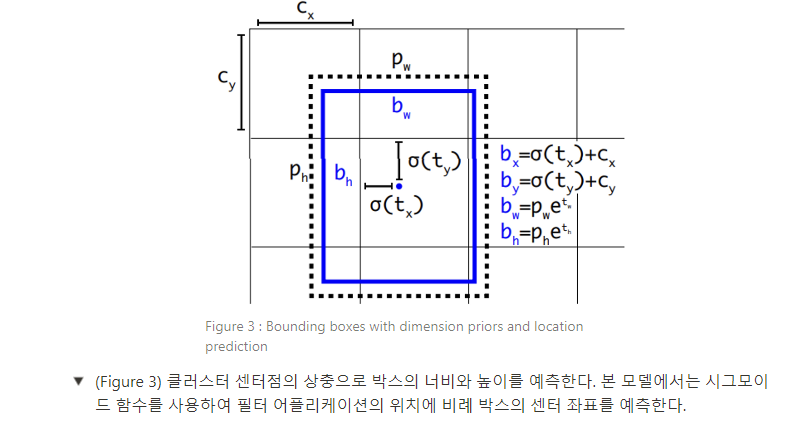
본 논문에서 위치 예측을 제한함으로써 파라미터화를 훈련하기 쉬워졌고, 네트워크는 더 안정적이 되었다. 차원 클러스터와 바운딩 박스의 센터 위치를 직접 예측하는 방법을 함께 사용하여 앵커 박스를 사용한 버전보다 YOLO를 5% 넘게 향상시켰다.
Fine-Grained Features. 이러한 변형 YOLO는 13x13 특징 맵에서 detection을 예측한다. 이러한 특징 맵은 큰 객체에게는 충분하지만, 더 작은 객체를 로컬라이징하기 위해서는 finer grained features를 사용하는 것이 더 좋을 수 있다. Faster R-CNN과 SSD는 모두 다양한 특징 맵에서 proposal network를 실행하여 다양한 해상도를 얻고자 한다. 본 논문에서는 다른 방법을 취하는데, 26x26 해상도에서 이전 레이어의 특성을 가져오는 패스스루(passthrough) 레이어를 추가하는 단순한 접근법이다.
passthrough layer는 인접한 특징을 공간적 위치가 아닌 다양한 채널에 쌓아 더 높은 해상도의 특징을 낮은 해상도의 특징과 연결(concatenate)한다. 이러한 방식은 ResNet의 identity mapping과 유사하다. 이러한 방법으로 26x26x512 특징 맵이 13x13x2048 특징 맵으로 변형되고, 이러한 특징 맵은 원래의 특징(original features)과 연결될 수 있다. 본 논문의 탐지기(detector)는 fine grained 특성에 접근하기 위해 이러한 확장된 특징 맵의 상단에서 작동한다. 이러한 방법은 1%정도의 성능 향상을 가져온다.
Multi-Scale Training. original YOLO는 448x448의 해상도를 입력으로 사용한다. 앵커 박스를 추가함으로써, 본 논문에서는 416x416의 해상도를 사용한다. 그러나, 본 논문에서 제안한 모델이 컨볼루션과 풀링 레이어만 사용하기 때문에, 모델이 즉석에서 리사이징될 수 있다. 본 논문에서는 YOLOv2가 다양한 크기의 이미지에서 실행될 수 있도록 강건(robust)하길 원하고, 따라서 모델이 강건해질 수 있도록 훈련한다.
입력 이미지 크기를 고치지 않고, 특정 이터레이션마다 네트워크를 변경한다. 배치 10개마다 모델 네트워크가 임의로 새로운 이미지 차원 크기를 선택한다. 본 논문의 모델은 32 배수로 다운샘플링을 수행하므로, 다음과 같은 32배수에서 값을 가져온다 : {320, 352, ..., 608}. 따라서, 가장 작은 옵션은 320x320이 되고, 가장 큰 옵션은 608x608이 되는 것이다. 네트워크는 이러한 차원으로 리사이징되고 훈련을 지속한다.
이러한 체제는 네트워크가 다양한 입력 차원에서 예측을 잘 수행하도록 훈련할 수 있게 한다. 이는 동일한 네트워크가 다양한 해상도의 detection을 예측할 수 있다는 것을 의미한다. 네트워크는 더 작은 크기에서 더 빠르게 실행되기 때문에, YOLOv2는 속도와 정확도 간 쉬운 tradeoff를 제공하게 된다.
낮은 해상도에서 YOLOv2는 저렴하고, 꽤 정확한 탐지기를 작동시킨다. 288x288의 해상도에서 90FPS 이상이 실행되고, mAP는 거의 Fast R-CNN과 맞먹는다. 이는 더 작은 GPU, 높은 주사율의 영상, 또는 다중 비디오 스트림에 적합하다.
높은 해상도에서 YOLOv2는 SOTA 탐지기로, 실시간 속도 이상을 유지하면서 VOC2007에서 mAP 78.6을 기록한다. Table 3에서 VOC 2007에서 YOLOv2와 다른 프레임워크들을 비교한 결과를 볼 수 있다.
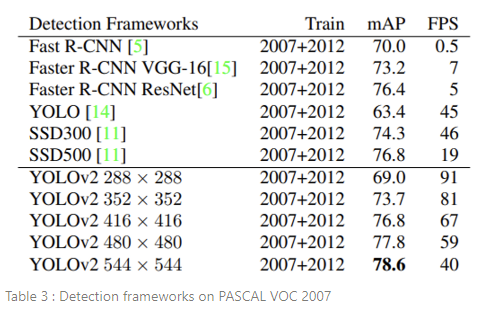
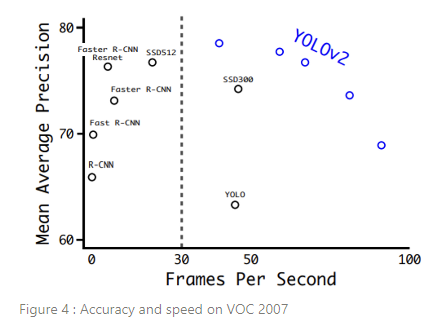
YOLOv2는 이전 detection method보다 더 빠르고 정확하다. YOLOv2는 속도와 정확도 간 단순한 tradeoff로 다양한 해상도에서 실행하는 것도 가능하다. 각 YOLOv2 엔트리는 실제로 동일한 가중치로 동일하게 훈련된 모델이고, 평가만 다른 크기로 진행했다. 모든 시간 정보는 Geforce GTX Titan X 기준이다(PASCAL model이 아닌 original).
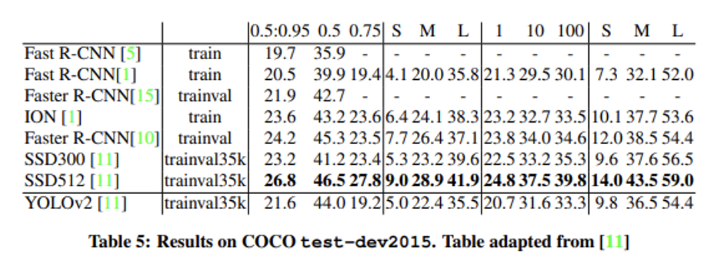
Further Experiments. YOLOv2의 detection은 VOC2012에서 훈련된다. Table 4는 YOLOv2와 다른 SOTA detection system의 상대적인 성능을 보여준다. YOLOv2는 73.4 mAP를 달성하였고, 다른 방법보다 훨씬 더 빠른 속도로 실행된다. 또한, YOLOv2는 COCO에서도 훈련하고 Table 5의 다른 방법들과 비교한다. VOC metric(IOU =.5)에서 YOLOv2는 44.0 mAP를 달성했는데, SSD나 Faster R-CNN에 필적하는 수치이다.

3. Faster
detection은 정확하면서도 빨라야 한다. 로봇이나 자율주행 차와 같은 대부분의 detection용 어플리케이션은 지연율이 적은 예측이 필요하다. 성능을 최대화하기 위해, YOLOv2는 처음부터 빠르도록 설계되었다. 대부분의 detection framework는 VGG-16을 특징 추출기로서 의존한다. VGG-16은 강력하고 정확한 분류 네트워크지만, 지나치게 복잡하다. VGG-16의 컨볼루션 레이어는 224x224 해상도의 단일 이미지에 대해 단일 패스로 306.9억 개의 부동 소수점 연산이 필요하다.
YOLO 프레임워크는 Googlenet 구조를 기반으로 하는 커스텀 네트워크를 사용한다. 이러한 네트워크는 전방 패스에 85.2억개의 부동 소수점만을 사용하고, VGG-16보다 빠르다. 그러나, 네트워크의 정확도는 VGG-16보다 약간 떨어진다. 224×224 해상도에서 단일 크롭으로 평가한 경우, YOLO 사용자 정의 모델은 ImageNet에서 top-5의 정확도인 88.0%를 달성한다(VGG-16은 90.0%).
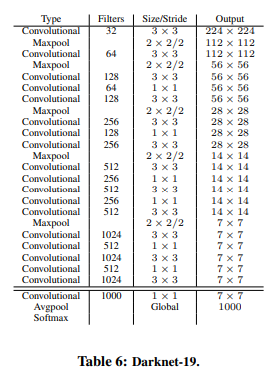
Darknet-19. 본 논문에서는 YOLOv2의 베이스로 사용할 새로운 분류 모델을 제시한다. 이 모델은 이전의 네트워크 디자인 연구와 해당 분야의 일반적인 지식을 기반으로 구축되었다. VGG 모델과 마찬가지로 주로 3x3 필터를 사용하고, 풀링 단계마다 채널 수를 2배로 늘리는 방식을 사용한다. Network in Network(NIN)의 연구를 따라, 본 논문에서는 1x1 필터를 사용하여 3x3 컨볼루션들 간의 특징 표현(feature representation)을 압축할 뿐만 아니라 global average pooling을 사용하여 예측을 수행한다. 본 논문에서는 batch normalization을 사용하여 훈련을 안정화하고, 수렴 속도를 빠르게 하고, 모델을 정규화한다.
본 논문의 최종 모델, Darknet-19는 19개의 컨볼루션 레이어와 5개의 맥스 풀링 레이어가 있다. 전체적인 설명은 Table 6에 쓰여 있다. Darknet-19는 55.8억번의 연산만으로 이미지를 처리할 수 있지만, 72.9%의 정확도로 top1 정확도를 달성하였고, ImageNet에서는 91.2%로 top5 정확도를 달성했다.
Training for classification. YOLOv2의 네트워크는 standard ImageNet 1000 class classification dataset에서 SGD(stochastic gradient descent) 학습률 0.1, polynomial rate decay(다항식 감쇠) power 4, weight decay(가중치 감쇠) 0.0005, momentum(모멘텀) 0.9를 사용하고, Darknet 신경망 구조를 사용하며, 160 epochs동안 훈련되었다.
앞서 언급된 바와 같이, YOLOv2의 최초 훈련은 224x224 크기의 이미지로 진행되고, 448 사이즈에서 파인튜닝을 진행한다. 파인 튜닝이 진행되는 동안, 상단의 파라미터들로 훈련하는데, 학습률로 시작하여 10 epochs 동안만 훈련을 진행한다. 이와 같이 더 높은 해상도(448x448)에서 YOLOv2의 네트워크는 top1 정확도 76.5%, top5 정확도 93.3%을 달성했다.
Training for detection. 객체 탐지(detection)을 위한 네트워크는 기존 네트워크에서 마지막 컨볼루션 레이어를 제거하고 대신 3개의 3x3 컨볼루션 레이어와 1024 필터, 그리고 detection에 필요로 하는 출력의 수와 함께 최종 1x1 컨볼루션 레이어가 뒤따르는 구조를 사용한다. VOC에서 5개의 박스를 각 5개의 좌표와 박스마다 20개의 클래스, 125개의 필터로 예측한다. 또한, 패스스루 레이어를 마지막 3x3x512 레이어부터 두번째 ~ 마지막 컨볼루션 레이어에 추가하고, YOLOv2 모델이 fine-grain feature를 사용할 수 있도록 한다.
YOLOv2 네트워크는 160 epochs 동안 훈련되고, 학습률은 부터 시작하며, 60과 90번째 에포크에서 10으로 나뉜다. weight decay(가중치 감쇠) 0.0005, momentum(모멘텀) 0.9 (classification과 동일)가 사용된다. YOLO와 random crops, color shifting, 등을 사용하는 SSD와 유사한 데이터 증식 방식을 사용한다.
4. Stronger
본 논문에서는 classification과 detection data를 동시에 훈련하는 메커니즘을 제안한다. 본 논문의 방식은 detection 라벨링이 된 이미지를 사용하여 공통 개체를 어떻게 분류할 것인지 뿐만 아니라, 바운딩 박스 좌표 예측과 objectness와 같은 detection-specific한 정보를 훈련하고자 한다. 또한, 클래스 라벨만 존재하는 이미지를 사용하여 탐지할 수 있는 카테고리의 수를 확장하고자 한다.
훈련 중에는, detection과 classification 데이터셋의 이미지를 혼합한다. 네트워크가 detection labeling이 된 이미지를 바라볼 때, full YOLOv2 손실 함수에 기반하여 역전파가 가능하다. 반면 네트워크가 classification 이미지를 바라볼 때, 네트워크 구조에서 classification-specific한 부분의 손실만을 역전파할 수 있다.
이러한 접근법은 몇 가지 챌린지를 제시한다. Detection dataset은 “dog”나 “boat”와 같은 공통적인 객체와 general label만 갖고 있다. Classification dataset은 훨씬 더 많고, 깊은 범주의 라벨을 갖는다. ImageNet은 100개가 넘는 개(노퍽테리어, 요크셔테리어, 베들턴테리어 등..)의 품종을 포함하고 있다. Detection과 Classification dataset에서 모두 학습하고자 한다면, 이러한 라벨링들을 병합할 일관된 방법이 필요하다.

대부분의 classification 접근법은 모든 possible categories에 소프트맥스 레이어를 사용하여 최종적인 probability distribution을 연산한다. 소프트맥스를 사용하면 상호 배타적인 클래스를 추정하게 되고, 이는 데이터 결합에 있어 문제를 발생시킨다.
예를 들면 이 모델을 사용하여 ImageNet과 COCO 데이터를 결합하고 싶지 않을 수 있는데, “노퍽테리어” 와 “개”는 상호 배타적인 클래스가 아니기 때문이다.
대신, 데이터셋을 결합하기 위해 상호간 배제를 추정하지 않는 multi-label model을 사용한다. 이러한 접근법은 우리가 데이터에 대해 알고 있는 모든 구조를 무시하는데, 예를 들면 모든 COCO 데이터셋의 클래스가 상호 배타적이 된다.
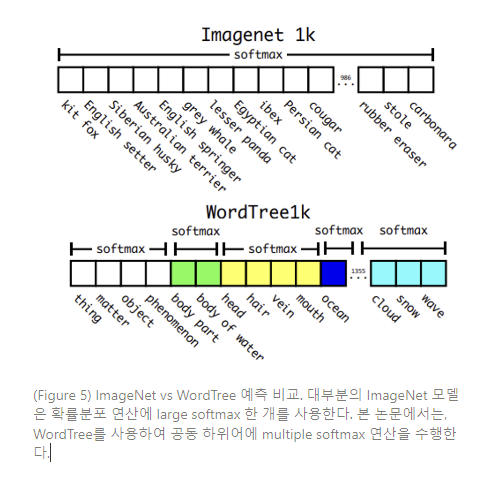
Hierachical classification. ImageNet의 라벨들은 개념과 연관성을 구조화하는 언어 데이터베이스인 WordNet에서 도출된 것이다. WordNet에서 “노퍽테리어”와 “요크셔 테리어”는 모두 “개과(canine)”인 “개(dog)”의 일종으로, “사냥하는 개(hunting dog)”의 일종인 “테리어(terrier)”의 하위어(hyponyms)이다. classification에 대한 대부분의 접근법들은 데이터셋 결합에 있어 어떤 구조가 필요하던간에 flat한 라벨 구조를 가정한다.
WordNet은 tree 구조가 아닌 유향 그래프(directed graph) 구조로, 언어는 complex하기 때문이다. 예를 들면 “개(dog)”는 “개과(canine)”의 일종이면서 “가축(domestic animal)”의 일종으로 모두 WordNet에서 synset(정보 검색을 위해 의미적으로 동일한 것으로 간주되는 데이터 요소 그룹)에 해당된다. full graph 구조를 사용하는 대신, ImageNet의 개념에서 위계 트리(hierachical tree) 구조를 구축하여 문제를 단순화한다.
이러한 트리 구조를 구축하기 위해, ImageNet의 visual nouns를 조사하고 WordNet graph를 통해 루트 노드까지 경로를 살펴본다. 이 경우의 루트 노드는 “물리적 대상(physical object)”이다.
대다수의 synsets은 그래프로 통하는 경로를 1개만 갖고 있고, 따라서 먼저 트리에 이러한 경로들을 모두 추가한다. 그리고 나서, 반복적으로 남겨놓은 개념(concepts)에 대해 조사하고 트리를 성장시키는 경로를 가능한 조금씩 추가한다. 따라서, 하나의 개념이 루트에 대하여 2개의 경로가 있고, 그 중 하나의 경로가 3개의 엣지(edge)를 트리에 추가하고 다른 하나의 경로가 1개의 엣지만 트리에 추가할 수 있다면, 더 짧은 경로를 선택하게 된다.
최종 결과는 visual concepts의 hierachical model인 WordTree이다. WordTree로 classification을 수행하기 위해서는 synset이 주어질 때, 각 synset의 하위어의 확률을 위해 모든 노드에 조건부 확률(conditional probabilities)을 예측한다. 예를 들면, “테리어(terrier)” 노드에서는 다음과 같이 예측한다:
(Norfolk terrier|terrier)
(Yorkshire terrier|terrier)
(Bedlington terrier|terrier)
...
특정 노드에 대한 절대 확률(absolute probability)을 연산하고자 한다면, 단순히 트리부터 루트 노드까지의 경로를 따르고 조건부 확률에 곱하면 된다. 따라서, 어떠한 이미지가 노퍽테리어인지 알고 싶다면, 다음과 같이 연산한다 :
(Norfolk terrier) = (Norfolk terrier|terrier)
∗(terrier|hunting dog)
∗ . . .∗
∗(mammal|(animal)
∗(animal|physical object)
classification purpose에서, 이미지가 객체를 포함하고 있다고 가정한다 :
이러한 접근법을 입증하기 위해, Darknet-19 모델을 ImageNet의 1000개 클래스를 사용하여 빌드된 WordTree로 훈련한다. WordTree1k를 구축하기 위해, label space를 1000에서 1369로 확장시킨 중간 노드를 모두 추가한다. 훈련을 지속하는 동안, “Norfolk terrier”로 라벨링 된 이미지가 있다면, “dog”나 “mammal” 등으로도 라벨링 될 수 있게끔 ground truth 라벨을 트리의 상단으로 전파시킨다. 조건부 호가률 연산을 위해, 1369 값의 벡터를 예측하고, 동일한 개념의 하위어인 모든 synset에 소프트맥스 연산을 수행한다. (Figure 5 참조)
이전과 동일한 훈련 파라미터를 사용했을 때, 이러한 hierachical Darknet-19 구조는 71.9% top-1 accuracy, 90.4% top-5 accuracy를 달성한다. 369개의 additional concepts를 추가하고 이 네트워크가 tree structure를 예측하게 하여도 정확도는 크게 하락하지 않는다. 이러한 방식으로 분류를 수행하는 것은 장점도 있다. 새롭거나, 알려지지 않은 객체 카테고리에 대한 정확도가 떨어진다. 예를 들면, 네트워크가 어떠한 개의 사진을 포착했으나 개의 종류를 모를 때, 여전히 높은 confidence로 “개”라고 예측할 수 있지만 하위어에는 lower confidence를 갖게 된다.
이러한 형식은 detection에도 동일하게 적용된다. 모든 이미지가 객체를 갖고 있다고 가정하지 않고, YOLOv2의 objectness predictor를 통해 Pr(physical object)의 값을 사용해 보자. detector는 bounding box와 확률 트리를 예측한다. 일정 threshold에 다다를 때까지 모든 분기점에서 가장 높은 confidence를 취하고 해당 객체의 클래스를 예측하면서, 이러한 트리를 횡단한다.
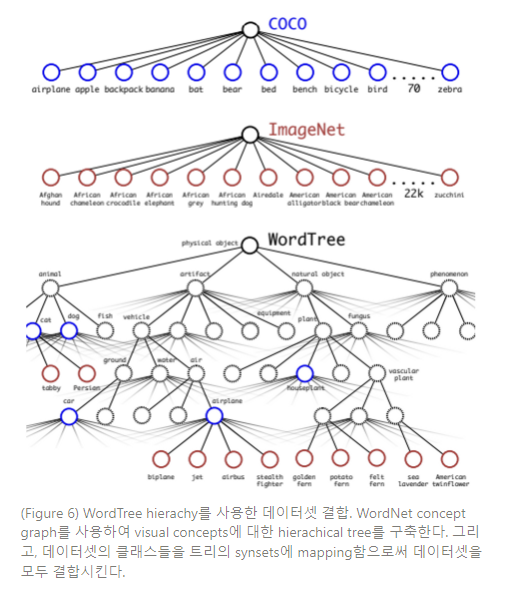
Dataset combination with WordTree. WordTree를 사용하여 다수의 데이터셋을 합리적인 방법으로 결합시킬 수 있다. 데이터셋에 있는 카테고리들을 트리에 있는 synset에 사상시킨다. Figure 6은 WordTree를 사용하여 ImageNet과 COCO의 라벨들을 결합하는 예제를 보여준다. WordNet은 매우 다양하고, 따라서 이 방법은 대부분의 데이터셋에 사용될 수 있다.
**Joint classification and detection**. 이제 WordTree를 사용하여 데이터셋을 결합할 수 있고, classification과 detection 모델을 공동으로 훈련할 수 있다. 대규모의 detector를 훈련하는 것이 목표이므로, COCO detection dataset을 사용하여 결합한 데이터셋과 full ImageNet release에서 top 9000개의 클래스를 생성한다. 또한, 이러한 방식을 평가하기 위해 ImageNet detection challenge에서 아직 포함되지 않은 클래스를 추가한다. 이러한 데이터셋에 상응하는 WordTree는 9,418개의 클래스를 갖는다. ImageNet은 훨씬 더 큰 데이터셋이고, 따라서 COCO를 오버샘플링하여 ImageNet과 4:1의 비율이 되게끔 데이터셋의 밸런스를 맞춘다.
이러한 데이터셋을 사용하여, YOLO9000을 훈련시킨다. base YOLOv2 구조를 사용하고, output size를 제한하기 위해 3개의 선행값만 사용한다. detection 네트워크에서는 일반적인 loss 역전파를 사용하고, classification loss는 특정 라벨의 상응하는 수준에서(또는 그 이상에서)만 역전파한다. 예를 들면, 라벨이 “dog”일 때, 정보를 갖고 있지 않은 “German Shepherd” vs “Golden Retriever”와 같은 prediction에 eror를 할당한다.
classification image에서는 classification loss만 역전파한다. 이를 위해, 특정 클래스에 가장 높은 확률을 예측하는 bounding box를 찾고, 예측한 트리의 로스만 연산한다. 또한, predicted box가 최소 .3 IOU만큼 ground truth label과 겹친다고 가정하며, 이러한 가정에 따라 objectness loss를 역전파한다.
YOLO9000은 이러한 joint training 방식을 사용함으로써, COCO의 detection data를 사용하여 이미지 내 객체를 찾고, ImageNet의 데이터를 사용하여 다양한 객체들을 분류해내는 방법을 학습한다.
YOLO9000은 ImageNet detection task에서 평가되었다. ImageNet의 detection task는 COCO dataset과 44개의 객체 카테고리만 겹치는데, 이는 YOLO9000이 detection data가 아닌 classification data에서만 대다수의 테스트 이미지를 볼 수 있다는 것을 뜻한다. YOLO9000은 전반적으로 19.7 mAP를 달성하고, 라벨링된 detection data를 보지 못한 156개의 서로소(disjoint)인 객체 클래스에서 16.0mAP를 달성한다. 또한, YOLO9000은 9000개의 객체 카테고리를 동시에, 모두 실시간으로 탐지할 수 있다.
YOLO9000의 성능을 ImageNet에서 평가할 때 새로운 종의 동물을 잘 학습하지만, 의류나 장비와 같은 카테고리를 학습하는 데는 어려움을 겪는다는 것을 발견했다.

새로운 동물을 학습하기가 더 쉬운 이유는 objectness의 예측이 COCO 데이터의 동물로 일반화가 잘 되기 때문이다. 역으로, COCO는 의류와 같은 물체의 bounding box 라벨이 존재하지 않아, YOLO9000이 “sunglasses”나 “swimming trunks”와 같은 카테고리 예측에 취약한 것이다.
5. Conclusion
본 논문에서는 YOLOv2와 YOLO9000이라는 실시간 detection system을 소개했다. YOLOv2는 SOTA model로 다른 detection system보다 빠르다. 또한, 속도와 정확도의 tradeoff를 적절히 맞추기 위해 다양한 이미지 크기에서 실행된다.
YOLO9000은 detection과 classification을 공동으로 최적화함으로써 9000개 이상의 객체 카테고리를 인식할 수 있는 실시간 프레임워크이다. WordTree를 사용하여 다양한 소스의 데이터를 결합할 수 있으며,공동 최적화 기법을 사용하여 ImageNet과 COCO를 동시에 훈련시킬 수 있다. YOLO9000는 detection과 classification간의 데이터셋 크기 차이를 줄이기 위한 절차를 밟는다.
YOLOv2의 기술 대다수는 object detection 외부를 일반화한다. ImageNet에서 WordTree representation은 image classification을 위해 더 풍부하고, 디테일한 출력 공간을 제공한다. hierachical classification을 사용한 데이터셋 결합은 classification과 segmentation 영역에서 유용하다. multi-scale training과 같은 훈련 테크닉은 다양한 visual task에 유용하게 사용될 수 있다.

글 잘 봤습니다.