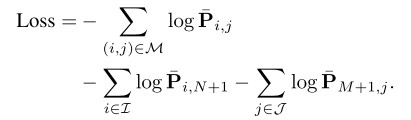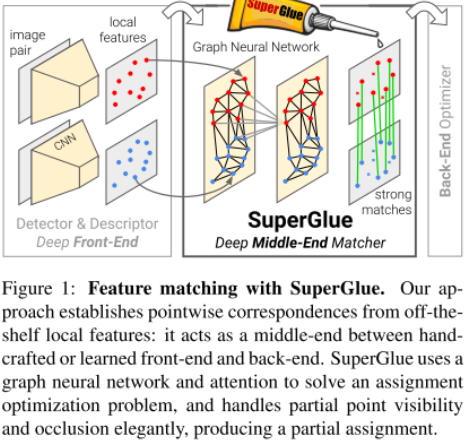
Abstract
-
Task of matching two sets of local features.
-
Solving differentiable optimal transport problem derived from graph neural network.
-
introduce flexible context aggregation mechanism based on attention.
Introduction
- Introduce a different view of feature matching problem => learning pre-existing local feature while using a novel neural network.
- Can be inserted on the middle section of Simultanuous Localization And Mapping system (SLAM)
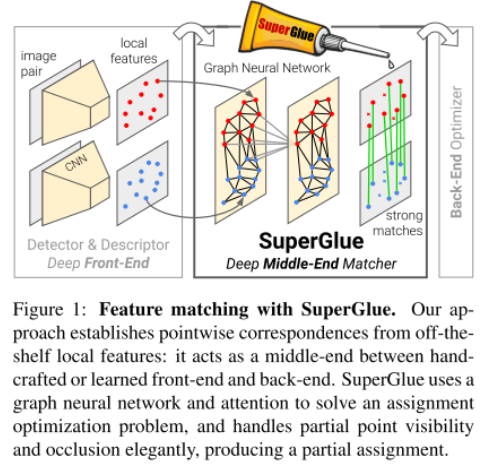
Solve optimization problem using graph neural network and attention.
Method
Proposed model
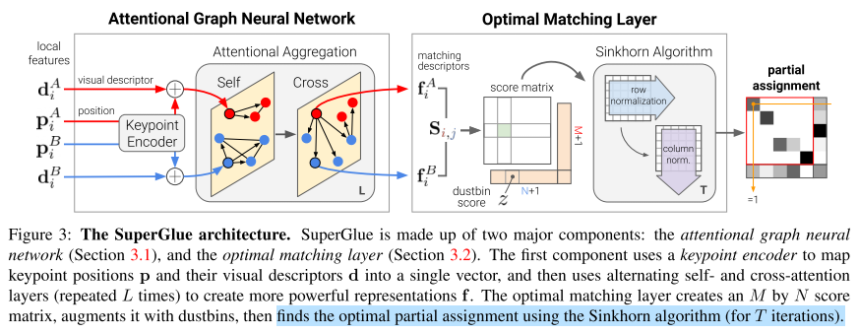
- Attentional Graph Neural Network
i) 모델의 앞단에서는 visual descriptor에 대한 정보와 position에 대한 정보를 infusion하는 모듈이다. position정보는 MLP를 통하여 정보가 encode되어 descriptor의 정보와 joint하게 들어간다.
ii) Attention Aggregation에서는 크게 2가지 attention 방법으로 나뉘는데, 정확히 self-attention의 idea와 다른 이미지 상에 있는 feature point와의 correspondence를 고려하는 idea를 사용하였다.
위 2가지 방법을 하나의 aggregation 식으로 나타내면 아래와 같다.
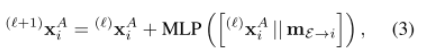
는 이미지 에 대한, 번째 element, 번째 layer의 중간 representation이다.
은 self, cross edges들의 정보를 담고 있는 message이다. 즉, intermidiate representation과 message를 aggregation하여 MLP에 넣어준 값과 다시 중간 representation을 더해주는 형식이다.
(나의 해석) 결국, 본 모델의 효과는 MLP와 Layer를 깊게 쌓기 위함이고, attention된 message를 계속 전달해줌으로써 long term dependency에 대한 효과도 존재할 것이라는 생각이든다.
self-attention에 대한 수식적인 이야기를 더 한다.
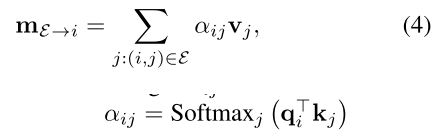
알파는 보는 것과 같이 key와 query를 연산하여 softmax를 해준 값이고, v는 value이다. 이는 self attention에서 하는 동작과 동일히다.
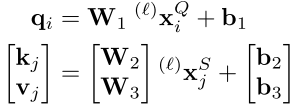
key, query, value를 연산하기 전에 1x1 conv를 해주는 것과 마찬가지로 여기서도 Fully connected layer의 식으로 표현하고 있다.
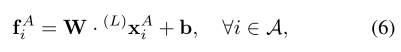
Attentional Graph Neural Network에서 L개의 layer를 거쳐 얻어낸 intermidiate representation을 다음 단계인 score predection으로 넘긴다.
- Optimal Matching Layer
[Score Prediction]
각 이미지의 point들에 대한 매칭쌍 만큼 각 descriptor 쌍에 대한 score를 아래와 같이 계산할 수 있다. 단순히 inner product를 하여 M x N의 matrix를 형성한다.
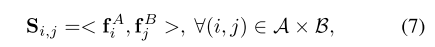
[Occlusion and Visibility]
Matching이 되지 않은 occulsion된 point 등에 대한 point들까지 효율적으로 matching하기 위하여 빈 공간인 dustbins를 할당하는 방법을 이용한다. Super point에서 65개 (8x8 + 1)의 자리를 할당한 것과 마찬가지의 매커니즘이다.
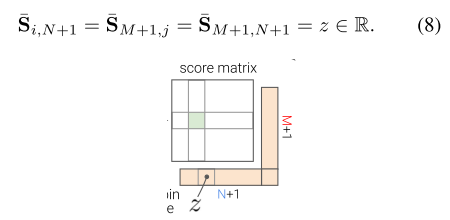
위 그림과 같이 단순히 M x N이 었던 matrix가 (M+1) x (N+1)의 matrix가 되는 꼴이 된다. (8) 수식을 보면 score가 z라는 실수 형태를 가진 parameter인데, 마지막 행, 열의 score 값이 모두 같다는 것을 의미한다. (이렇게 해도 되는지는 사실 왜그런지 모르겠다. 저렇게 할거면, 그냥 하나의 dustbin만 둬도 괜찮은게 아닌지)
이후, Partial Assignment의 constraint (모든 component = P의 행 의 확률값을 더하면 1)를 이용하여 아래와 같은 식을 유도할 수 있다.
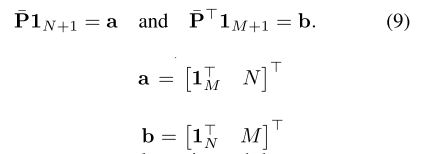
Optimization에 대한 solver로 Sinkhorn 알고리즘을 이용한다. 이후 T iteration이 지나면 dustbin을 떼어내고, 각각의 descriptor에 대한 최적의 confience 값을 가진 Partial matrix를 얻게 된다.
이후, negative log likelyhood를 통해 loss function이 최소화 될 수 있도록 아래와 같이 Loss function을 정의한다.