CLIP은 텍스트와 이미지를 모두 다루는 task에서 특징을 추출하기 위해 매우 자주 사용되는 인코더입니다.
CLIP을 그냥 가져다 쓰더라도 어느정도 알고 써야할 것 같아, 간단히 어떤 모델인지만 가볍게 정리하고자 합니다.
Motivation
CLIP이 발표될 당시, 대부분의 Computer Vision 모델은 ImageNet 데이터셋 등을 기반으로 하는 지도 학습(Classification)으로 훈련된 모델을 사용했습니다. 만약 특정 도메인에 이를 적용해야 한다면, 이러한 모델을 가져와 도메인에 맞게 파인 튜닝을 해야했습니다.
반면 NLP 분야에서는 Transformer의 등장으로 인터넷의 무수히 많은 raw text를 학습 데이터로 쓸 수 있게 되면서, 모델이 학습한 적 없는 데이터가 주어져도 뛰어난 성능을 내도록 학습하는 zero shot learning이 가능해지면서 연구적으로나 실용적으로나 폭발적인 발전을 이루게 되었습니다.
논문의 저자들은 Computer Vision 모델 역시 인터넷에 존재하는 무수히 많은 이미지-자연어 쌍을 학습할 수 있다면, NLP와 비슷한 성공을 이룰 수 있을 것이라 생각하였습니다. 이를 바탕으로 등장한 것이 CLIP(Contrastive Language-Image Pre-Training)입니다.
Approach
대규모 자연어-이미지 데이터 셋
이렇게 이미지-자연어 쌍으로 학습하는 것을 논문은 Natural Language Supervision이라 명명했습니다.
이러한 학습 방법은 이미지 representation만 고려하는 기존의 방법과 달리, 자연어와 이미지를 연결하여 유연한 zero shot transfer가 가능하다고 합니다.
또한, 데이터 크기가 한정된 정제된 데이터셋과 달리, 이미지-자연어 쌍은 인터넷에서 거의 무제한으로 모을 수 있습니다. 실제로 CLIP 학습에는 40억 개 이상의 데이터로 학습 데이터를 구성했다고 합니다. 이는 GPT-2 학습에 사용된 것과 비슷한 규모라고 합니다.
Contrasive Learning
하지만 이렇게 대규모 학습을 할 경우 연산에 필요한 시간과 자원이 걸림돌이 됩니다. 기존의 CV 모델들은 ImageNet class(1000개)를 예측하기에도 너무 많은 연산을 필요로 했다고 합니다.
때문에, CLIP에서는 훨씬 더 적은 연산으로도 기존의 예측 기반 학습(predictive objective)과 비슷하거나 더 좋은 성능을 낼 수 있는 Contrastive Learning을 이용했습니다.
Contrastive Learning에 대해서는 이후 학습 방법을 설명할 때 보다 자세히 다루겠습니다.
Training
Contrastive pre-training
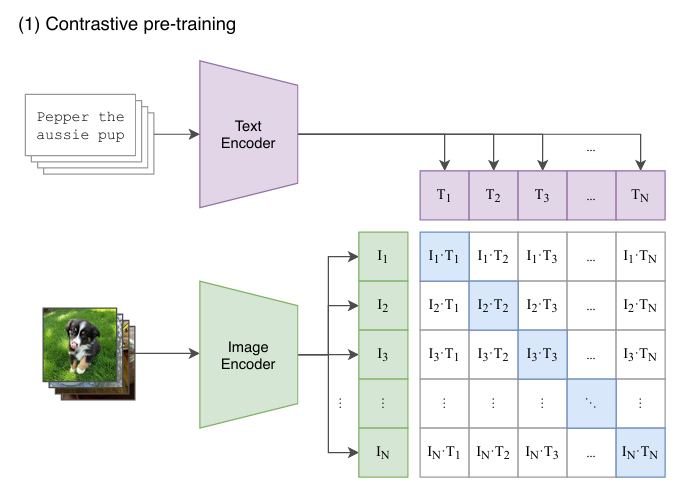
# 각 feature 벡터 추출
I_f = image_encoder(I) # [n, d_i]
T_f = text_encoder(T) # [n, d_t]
# joint multimodal embedding 변환
I_e = l2_normalize(np.dot(I_f, W_i), axis=1) # [n, d_e]
T_e = l2_normalize(np.dot(T_f, W_t), axis=1) # [n, d_e]
# 코사인 유사도 계산 - t는 learnd temperature parameter
logits = np.dot(I_e, T_e.T) * np.exp(t) # [n, n]
# symmetric cross entropy
lables = np.arange(n) # 행렬의 대각 성분이 정답에 해당
loss_i = cross_entropy_loss(logits, labels, axis=0)
loss_t = cross_entropy_liss(logits, labels, axis=1)
loss = (loss_i + loss_t) / 2논문에서 제공하는 figure와 슈도 코드가 CLIP의 학습 방법을 잘 설명하고 있습니다.
- mini-batch 단위로 아래 과정을 반복
- 이미지-자연어 쌍에 대해 각각 이미지 인코더, 텍스트 인코더로 feature 벡터 추출
- learnable parameter matrix를 통해 각 feature 벡터를 동일한 임베딩 공간으로 투영
- batch size가 일 경우 batch 내의 모든 가능한 조합(개)에 대해 코사인 유사도를 계산
- 각 이미지 별로 코사인 유사도 값에 temperature parameter 를 곱하여 softmax 연산을 통해 확률 값으로 만듦
- 행렬 형태로 나타냈을 때, 대각 성분에 해당하는 개 정답의 코사인 유사도가 최대가 되도록, 나머지 개 오답의 코사인 유사도가 최소가 되도록 symmetric cross entropy를 이용하여 모델 업데이트.
Inference
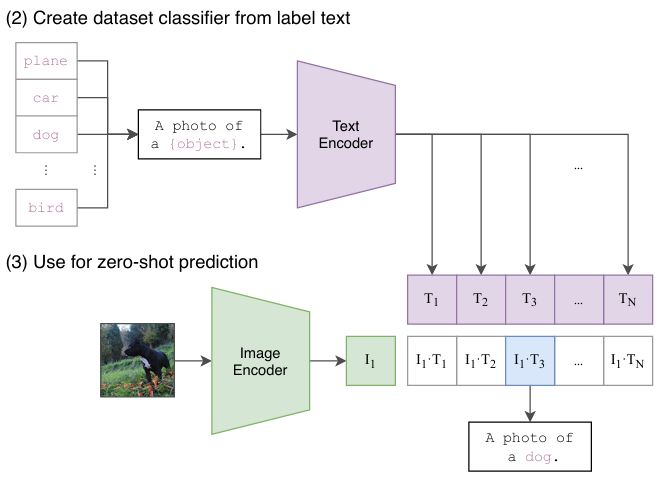
이렇게 학습한 모델은 학습한 적이 없는 클래스에 대해 예측하는 zero-shot이 가능합니다.
그 방법은 아래와 같습니다.
- 추론할 데이터셋의 클래스를 프롬프트로 감싸 각각 인코딩
- 학습 때와 동일한 방법으로 임베딩 공간에 투영한 후 softmax 확률을 계산하여 확률이 가장 높은 임베딩의 클래스가 input image에 대한 예측값이 됨
여기서 클래스를 A photo of a {object}와 같이 프롬프트로 감싸는 과정이 CLIP의 성능을 높여준다고 합니다.
CLIP이 학습한 자연어가 대부분 문장 형태이기 때문에 프롬프트를 추가하는 것이 학습 데이터셋과 더 유사한 형태를 만들기 때문이라고 합니다. 또한 적절한 프롬프트는 동음이의어 문제도 해결할 수 있습니다.
마지막으로 하나의 클래스 명에 대해 여러 프롬프트를 사용하여 앙상블하는 기법을 통해 성능을 더욱 높일 수 있다고 합니다.
다만, 앙상블을 위해 연산이 많이 필요하므로 코사인 유사도를 곱하기 전에 임베딩 공간에서 앙상블을 했다고 합니다.
Result
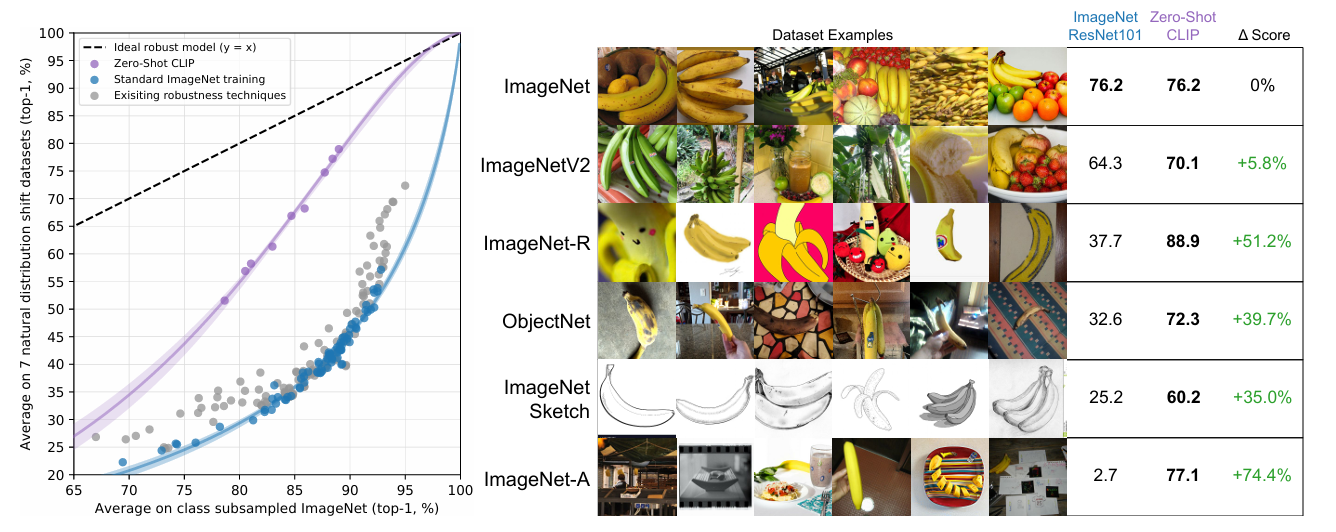
이렇게 학습된 CLIP은 zero shot임에도 데이터셋으로 지도 학습을 진행한 SOTA 모델들과 비교 가능한 수준의 성능을 보였다고 합니다.
학습한 데이터셋과 분포가 다른 테스트셋을 사용할 경우에도 지도 학습 기반 모델들은 성능이 큰 폭으로 감소하는 반면, CLIP은 매우 robust한 성능을 보여 zero shot 능력이 뛰어난 것을 확인할 수 있습니다.
