Score Distillation Sampling이란
SDS(Score Distillation Sampling) loss는 DreamFusion 논문에서 처음 제시된 손실 함수로, 현재 다양한 Text-to-3D 모델에서 중요하게 사용되고 있다.
SDS의 기반이 되는 손실 함수
SDS는 latent diffusion model을 기반으로 한다.
latent diffusion model은 이미지를 latent화 하여 이 latent에 노이즈를 더하고, 이를 denoise하도록 학습하여 주어진 condition에 해당하는 새로운 latent를 만들어내는 2D 이미지 생성형 모델이다.
latent diffusion model의 손실 함수를 수식으로 나타내면 다음과 같다.

단순하게 위 수식을 설명하자면 t 시점에서 실제로 더해진 노이즈와, denoise 모델이 예측한 노이즈의 Loss이다.
는 t 시점에 대한 가중치 함수이다.
DreamFusion 논문에서는 추가로 텍스트 임베딩을 통한 컨디셔닝과, classifier-free guidence(CFG)를 적용하였다.
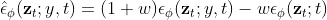
이것 역시 간략히 설명하자면 텍스트 임베딩()을 통해 컨디셔닝된 모델, 컨디셔닝하지 않은 모델을 동시에 이용한다. scaling factor()가 0보다 크면 모델의 다양성은 감소하지만 더 좋은 품질의 sample을 얻을 수 있다고 한다.
SDS 유도
SDS는 앞에서 설명한 latent diffusion model의 구조를 이용하여 3D 생성형 모델(여기서는 NeRF)을 최적화하고자 한다.
구체적으로는 NeRF에 임의의 카메라 앵글을 주어 렌더링 한 이미지가 그럴듯한(plausible) 이미지를 만들어 내도록 최적화 한다.
NeRF를 diffusion model에 적용할 경우 diffusion model 파라미터는 고정(freeze)한 상태에서, input 를 만들어내는 NeRF 모델의 파라미터()를 학습할 수 있다. ()
먼저 앞서 살펴본 diffusion model의 학습 함수를 그대로 적용해보자.
- 수식 표현 :
하지만 Dreamfusion 논문의 저자들이 실험한 결과 이대로 적용하면 timestep schedule을 튜닝하는 것이 어렵고, 입력의 작은 변화, 초기 조건의 미묘한 차이에도 민감하게 반응(objective brittle)하여, 괜찮은 3D 모델을 얻는 것에 실패했다고 한다.
이러한 이유를 알기 위해 손실 함수의 그라디언트 계산을 들여다 보면
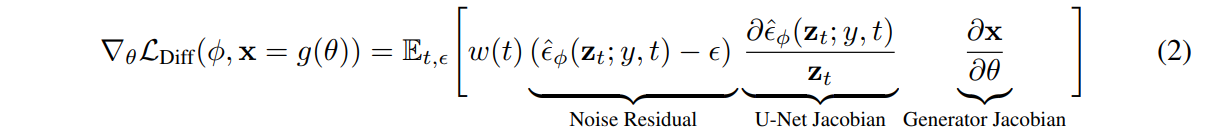
논문에 직접 설명되어있지 않지만, 추측컨대 이 경우 노이즈 예측 모델인 U-Net과 3D generator를 동시에 최적화하는 것이 되어, 결국 최적화가 잘 이루어지지 않는다고 볼 수 있을 것 같다.
저자들은 U-Net 그라디언트를 계산하는 것은 많은 계산이 필요하고, 작은 노이즈에 대한 컨디셔닝이 좋지 않다고 보고, U-Net Jacobian 항을 아예 빼는 것으로써 효과적인 최적화를 수행하는 그라디언트를 얻을 수 있게 되었다고 한다.
즉 Eq. 2에서 U-Net Jacobian을 제거한 수식이 바로 SDS(Score Distillation Sample) Loss이다. 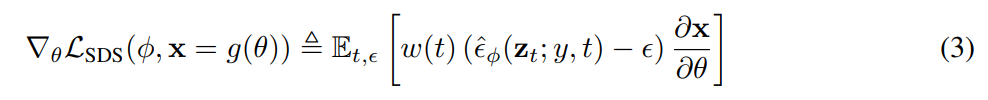
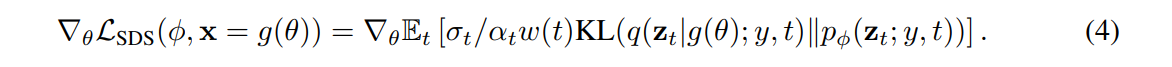
이 SDS Loss는 선택에 대해 상대적으로 robust하며, diffusion model은 고정되어 있으므로 backpropagation시 diffusion model까지 계산할 필요가 없어 효율적으로 연산이 가능하다.
SDS loss 슈도 코드
Dreamfusion 논문의 appendix에서 SDS loss 계산의 슈도코드를 제공한다.
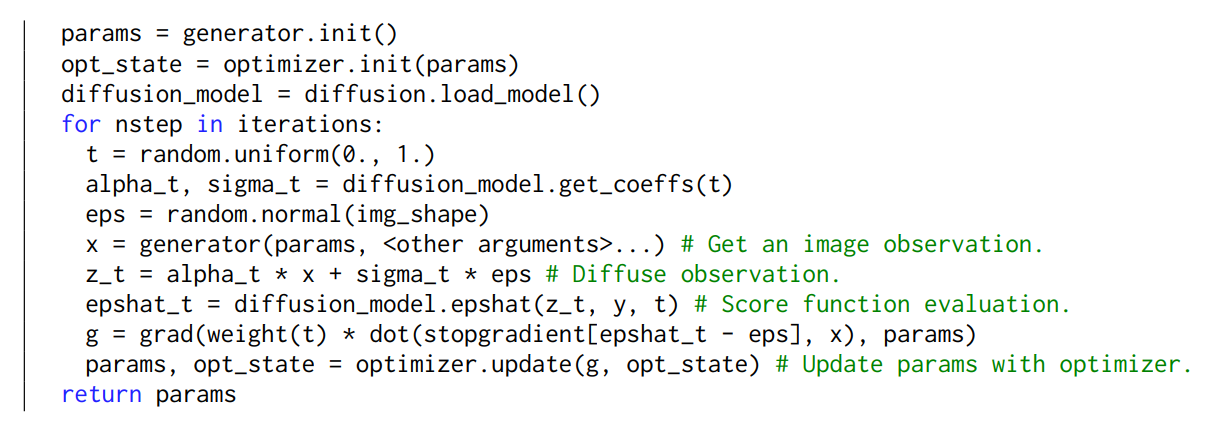
- 균일하게 정의된 time step 에 따라 노이즈를 결정하는 alpha_t, sigma_t 정의
- reparameterization trick을 위한 랜덤 노이즈 eps 생성
- generator 모델로부터 이미지 생성
- 랜덤 노이즈를 더해 미분 가능한 형태의 새로운 이미지 z_t를 만듦
- 주어진 컨디션 y, time step t에서의 노이즈 예측
- 예측 결과에 대한 그라디언트 계산 (위에서 살펴본 3번 식과 동일, diffusion model을 고정하는 것을 알 수 있다)
- 모델 업데이트
결론
이렇게 Dreamfusion에서 설명된 SDS는 pre-trained diffusion model의 강력함을 잘 이용하여 3D 생성형 모델의 학습에 적용될 수 있도록 하였다.
하지만 diffusion model은 기하학적인 prior를 학습하지 않았기 때문에 카메라 앵글을 컨디셔닝하는 것에 많은 어려움이 있었고, 이로 인해 생성된 모델의 얼굴이 여러개인 Janus faced 현상과 같은 문제가 발생했다.
이러한 문제를 해결하기 위해 diffusion model에 3D 지식을 주입하려는 여러가지 연구가 이루어지고 있는 것으로 알고 있다. 이 부분에 대해서도 공부가 많이 필요할 것 같다.
