[논문리뷰] Coin3D: Controllable and Interactive 3D Assets Generation with Proxy-Guided Conditioning
논문

Introduction
최근 3D Object Generation에 대한 많은 연구가 이루어지고 있고, 짧은 시간내에 꽤 근사한 에셋을 만들어줄 수 있게 되었습니다.
그러나 이미지 생성 분야와 달리 3D 에셋 생성은 여전히 아티스트들이 사용하기 어려워하는데요. 논문에서는 그 이유를 크게 두 가지로 꼽습니다.
- 텍스트 프롬프트 또는 이미지만을 입력으로 받기 때문에, 사용자가 정확히 원하는 형상을 표현하기 어려움
- 생성한 것에 대해 마음에 들지 않은 부분을 자유롭게 수정할 수 있어야 하는데, 기존 파이프라인으로는 통째로 재생성해야하기 때문에 시간이 너무 오래 걸림
때문에 아티스트들도 활용할 수 있는 3D 에셋 생성 프레임워크는 다음과 같은 성질을 가져야 한다고 합니다.
- 3D-aware controllable : 아이가 레고를 쌓는 것과 비슷하게, Basic shape(큐브, 구, 원뿔 등)를 조립하여 기초 모양을 제공하고, 이를 통해 디테일한 생성이 가능해야 함
사실 레고를 쌓는 것 보다는 대략적인 스케치를 그리면 스케치대로 디테일한 이미지를 생성해주는 ControlNet의 3D 버전이라고 이해했습니다.
-
Flexible : 사용자가 인터랙티브하게 수정이 가능해야 한다. 이상적으로는 이미지 인페인팅 툴만큼 쉬워야 함
-
Responsible : 사용자가 수정을 했을 때, 짧은 시간 내로 수정 내용에 대한 미리보기를 제공해야 함
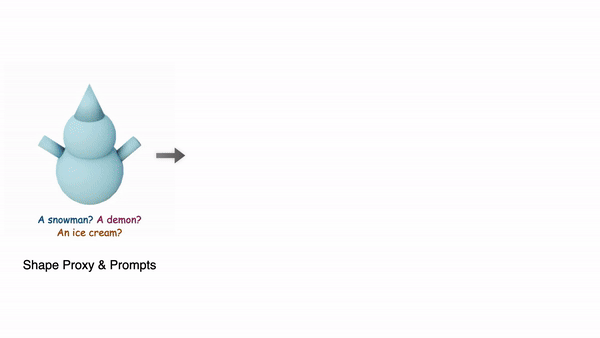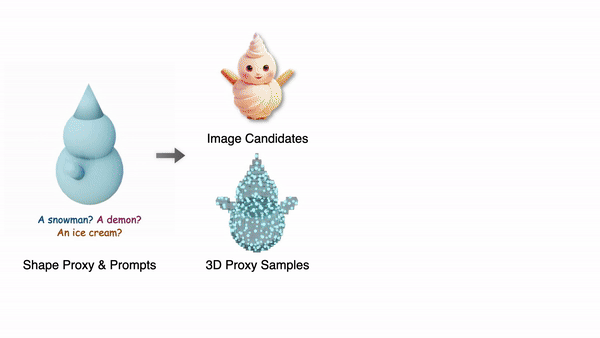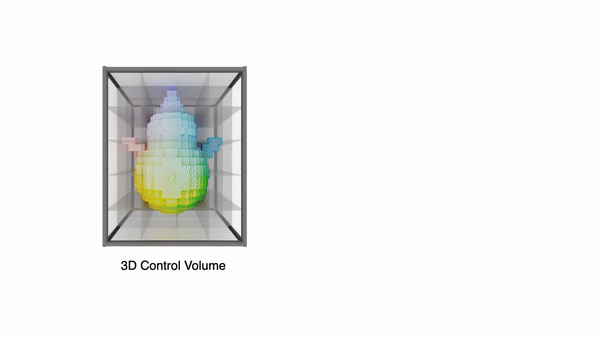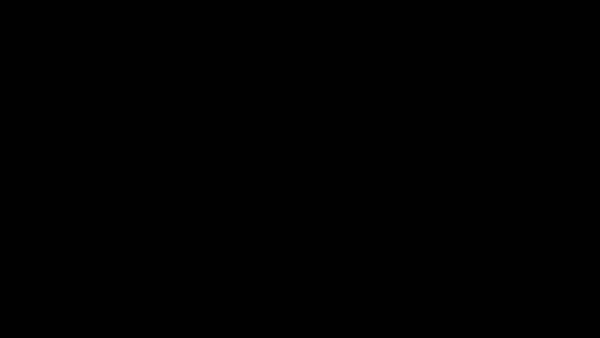
Coin3D는 위 세가지 조건을 만족하는 프레임워크로, 기존 3D 툴에서 간단한 basic shape을 만들어 프롬프트와 함께 제공하는 것으로 사용자가 정확히 원하는 형상의 3D 모델을 만들 수 있습니다.
이러한 프레임워크를 개발하기 위해 적용한 테크닉들을 다음 섹션에서 소개하겠습니다.
Method
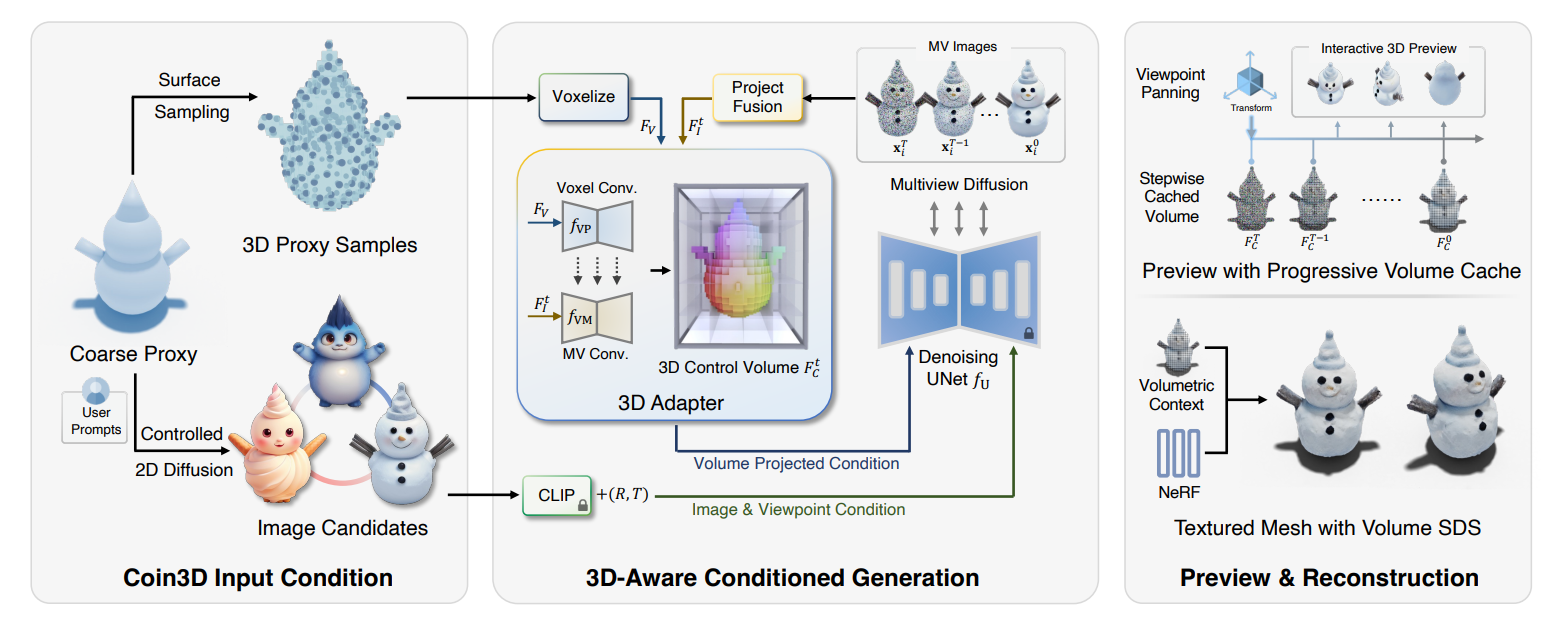
Coin3D는 Multiview Diffusion 모델을 통해 3D 표현을 생성합니다.
Multiview Diffusion 모델은 한 오브젝트에 대해 동시에 여러개의 시점(view)에서 바라본 형태의 이미지를 생성하도록 훈련된 diffusion 기반 모델입니다.
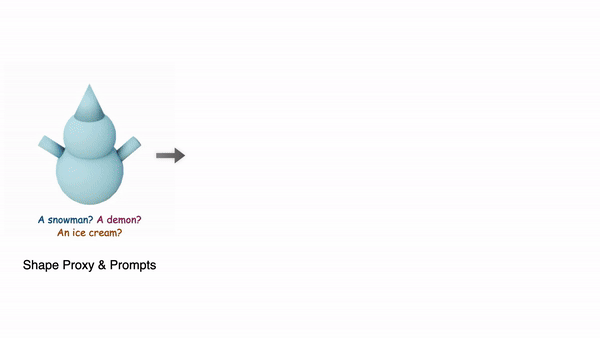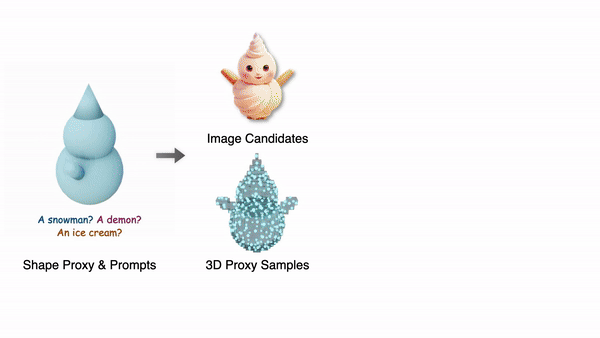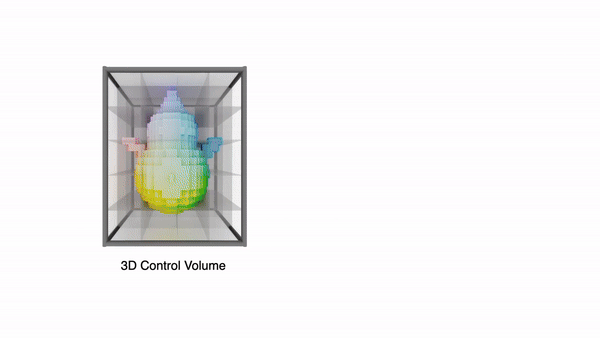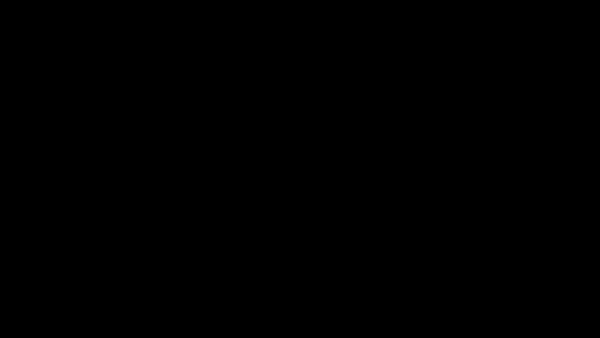
단, Coin3D는 입력으로 3D basic shape을 입력으로 받기 때문에 이 3D 정보를 모델에 주입할 수 있습니다. 이렇게 3D 정보를 제공하는 basic shape를 coarse proxy라고 합니다. coarse proxy로 diffusion 모델을 제어하는 과정을 통해 제공된 proxy에 맞는 3D 멀티뷰 이미지를 생성할 수 있습니다.
1. Proxy-Guided 3D Conditionding for Diffusion
3D proxy as initial condition
파이프라인에 제공되는 입력을 구체적으로 다음과 같이 정리할 수 있습니다.
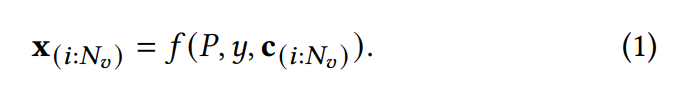
- : basic shape (coarse shape)
- : prompt
- : 생성할 멀티뷰 이미지 개수
- : i번째 뷰의 카메라 포즈(pose)
- : i번째 뷰에 해당하는 이미지
- : diffusion 기반 생성 모델
여기서 basic shape은 3D 모델링 툴에서 primitive를 조립하는 것 만으로 간단히 만들 수 있습니다. 이를 coarse proxy로써 모델에 입력(condition)으로 제공하기 위해서 두 종류의 경로로 전처리 과정을 거칩니다.

먼저 제공된 basic shape의 표면으로부터 개의 포인트 개를 샘플링합니다. (논문에서는 )

다른 하나는 basic shape을 렌더링해서 실루엣을 딴 후 프롬프트와 함께 여러장의 이미지를 생성하여 인터랙티브한 형상 선택의 후보로 제공합니다.
논문에는 이정도로 설명되어있지만, 아마 기존 multiview diffusion 모델이 이미지와 함께 카메라 시점(R, T)를 입력으로 받기 때문에 해당 입력을 간단히 만드는 과정으로 이해했습니다.
3D-aware control with 3D adapter
proxy의 3D 정보를 diffusion에 전달하기 위해서는 모델 파이프라인과 호환이 되도록 변환해주는 3D 어댑터가 필요합니다.
정보 손실 없이 3D control 정보를 제공하기 위해 One-2-3-45++에서 영감을 얻어, coarse proxy를 기반으로 3D control volume을 구축합니다. volume은 개의 정점(vertex)으로 구성된 voxel feature grid이며, 주어진 뷰에따라 volume을 투영한 feature image를 이미지 생성 UNet에 전달합니다.

먼저 앞서 샘플링한 포인트를 기반으로 해상도의 0으로 초기화된 voxel grid를 만들고, 각 grid안에 포인트가 들어있다면 1을 할당하여 occupancy volume 형태로 만들어 줍니다.
이렇게 만든 volume은 proxy feature volume 이라고 합니다.
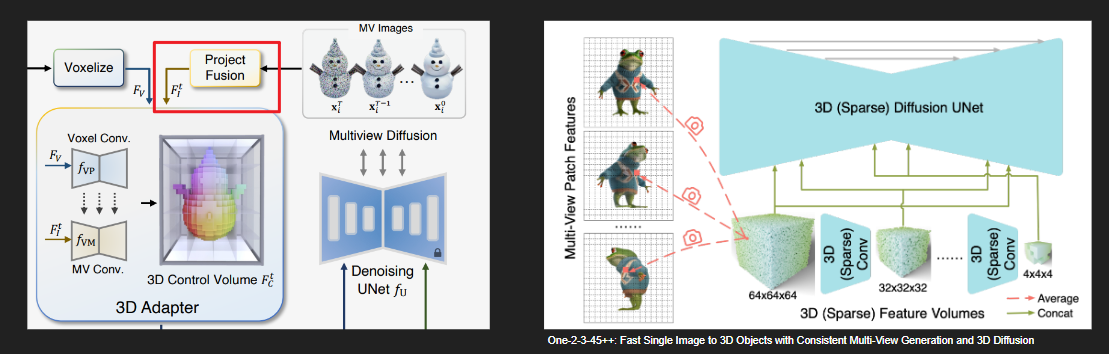
그 다음으로는 Multiview diffusion 모델로 생성한 개의 멀티뷰 이미지를 또다른 voxel grid 에 투영합니다. 이렇게 각 view에서 얻은 이미지 feature들을 3D CNN을 통해 융합합니다.
최종적으로 Multiview image fused volume 를 얻을 수 있습니다.
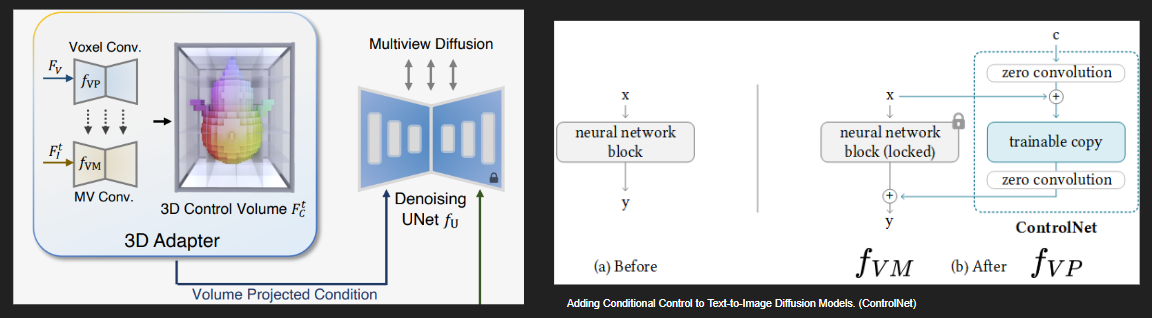
에 3D CNN()을 적용하여 각 레이어에서 중간 feature를 추출합니다.
그 뒤, 에 또다른 3D CNN()을 적용하면서 각 중간 레이어에 에서 얻은 feature를 더해줍니다. 단순히 더하는 것은 아니고 zero convolution을 적용하여 가중치를 갖고 더해질 수 있도록 합니다.
논문에 구체적인 언급은 없지만 해당 부분은 ControlNet(우측 이미지)과 유사한 아이디어인 것 같습니다.
ControlNet은 기존 2D Diffusion의 UNet을 건들지 않고 새롭게 학습한 feature를 추가하는 방법입니다.
초기값이 0으로 초기화된 zero convolution을 이용해 학습이 불안정한 초기에는 feature가 거의 더해지지 않도록하고, 이후에는 학습에 따라 적절한 가중치만큼 feature가 더해지도록 하여 control strength를 조절합니다.
여기서 은 사전학습된 것으로 가져와서 가중치를 프리징하였다고 합니다. 정확한 언급은 찾지 못했지만, 아마 one-2-3-45++의 사전 학습된 가중치인 것 같습니다.
Training 3D adapter with proxy samples
이제 3D adapter의 가중치(, zero convolution 등)를 학습시켜야 합니다.
학습 과정은 diffusion 학습과 유사하게 노이즈 예측 error를 기반으로 학습하였습니다.
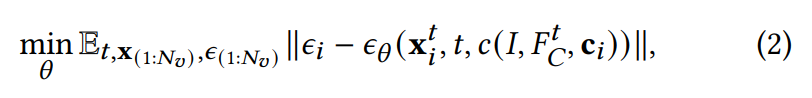
- : 후보 이미지 의 conditioned 임베딩
- : 카메라 포즈
- : 3D control volume
2 Interactive Generation Workflow
사용자가 인터랙티브하게 생성된 에셋을 수정할 수 있도록 개발된 workflow에 대한 설명입니다.
Proxy-bounded part editing
생성된 3D 에셋에서 유저가 정확히 원하는 부분만 수정하는 것은 상당히 어려운 task입니다. 3D 영역을 지정하는 것도 어렵고, 수정된 부분과 기존 에셋간의 경계면을 어떻게 처리할지에 대한 문제도 있기 때문입니다.
Coin3D는 유저가 제공한 basic shape를 기반으로, shape 단위의 수정을 통해 이 문제를 해결합니다.

먼저 수정할 부분에 대해 두 종류의 경로로 마스킹을 진행합니다.
하나는 3D 에셋을 view에 대에 2D로 투영하여 마스킹하고, diffusion 기반 inpainting을 통해 수정해야할 부분을 생성합니다.
다른 하나는 3D volume에 대해 마스크를 생성하되, 약간의 delate를 주어 실제 shape보다 넓은 범위를 마스킹합니다. 이는 새롭게 생성된 영역과 기존 영역을 자연스럽게 이어지게 하기 위함이라고 합니다.
그 뒤, 각 denoise 단계에서 미리 캐시해둔 원본 3D control volume을 가져와 feature mask 에 따라 마스킹이 되지 않은 volume 부분만 업데이트를 진행합니다.
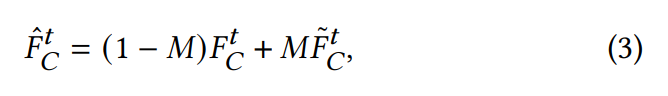
- : 예측된 새로운 volume
- : 업데이트 된 volume
Interactive preview with progressive volume caching
이 섹션은 사용자에게 빠르게 미리보기를 제공하여 느린 전체 재생성 과정 없이 빠르게 수정을 하기 위한 테크닉으로, 3D 에셋 생성에는 영향을 주지 않는 과정입니다.
Coin3D는 주어진 임의의 view에 대해 수 초내로 미리보기 결과를 생성하기 위해 점진적인 volume 캐싱 매커니즘을 설계하였습니다.
여기서 volume 캐싱 매커니즘은 각 타임스탭 별로 가장 최신의 3D control volume을 저장하여, 3D 어댑터를 거치지 않고도 캐싱된 3D control volume을 사용해 미리보기 이미지를 디코딩 할 수 있도록 합니다.
이 부분을 정확히 이해하지는 못했습니다.
다소 추측을 하자면 3D volume을 view에 맞게 투영하여 2D 이미지를 만든 후, 이를 interpolate하며 4x64x64 크기의 latent로 만들어, 이를 곧바로 decoder에 태워 빠르게 이미지를 생성한다는 것으로 생각됩니다.
또한 디코더로 Tiny AutoEncoder for Stable Diffusion을 사용하여 빠르게 이미지를 생성합니다. Tiny AutoEncoder는 latent를 입력으로 받아 해당 latent가 Stable Diffusion을 거쳤을 때 생성될 이미지를 빠르게 출력하는 VAE 모델입니다.
3 Volume-Conditioned Reconstruction
마지막으로 생성된 멀티뷰 이미지를 바탕으로 3D reconstruction을 진행하는 과정입니다.
Coin3D는 최종적으로 textured mesh를 생성하는데, 이를 위해 NeuS를 사용했다고 합니다.
그러나 NeuS를 그냥 그대로 적용하면 멀티뷰 이미지의 제한된 시점으로 인해 예상치 못한 지오메트리를 얻을 수 있다는 문제가 있습니다.
때문에 Coin3D에서는 3D control volume 를 활용하여 3D-aware context를 NeuS의 reconstruction 과정에 통합하는 것을 통해 품질을 개선하였습니다.
구체적으로는 volumetric 기반 score distillation sampling인 volume-SDS를 적용했습니다.
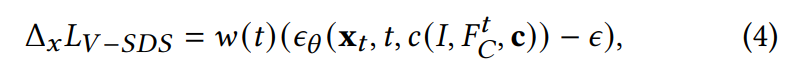
이는 로부터 얻은 3D control prior를 NeuS의 역전파 field와 통합하는 역할을 한다고 합니다.
논문에 이것보다 자세한 설명이 제공되지 않았습니다.
SDS기반 loss이기 때문에 는 NeuS에 의해 렌더링 된 이미지이고, 여기에 노이즈를 더한 뒤, 이를 3D control prior와 함께 diffusion 모델이 더해진 노이즈를 예측하도록 하고, 예측값과 실제값의 차이를 loss로 사용하는 것으로 이해했습니다.
최종적으로 NeuS에 사용되는 loss term은 다음과 같습니다.
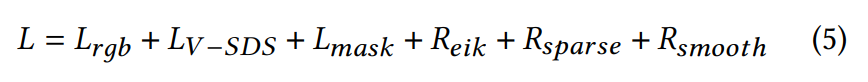
제가 아직 NeuS에 대해 알고 있는 상태가 아니어서, 나머지 loss에 대해서는 추가적인 공부가 필요할 것 같습니다.
Experiments
Coin3D와 유사한 파이프라인을 갖는 3D 생성 모델과의 성능을 비교하겠습니다.
1. Comparison on Proxy-based and Image-based 3D Generation
첫번째 비교 대상은 Wonder3D와 SyncDreamer입니다.
Coin3D가 multiview diffusion 모델을 이용해 멀티뷰 이미지를 생성하듯이, 이 두 모델도 single image를 기반으로 멀티뷰 이미지를 생성하는 SOTA 모델들이기 때문에 비교 대상으로 선택하였다고 합니다.

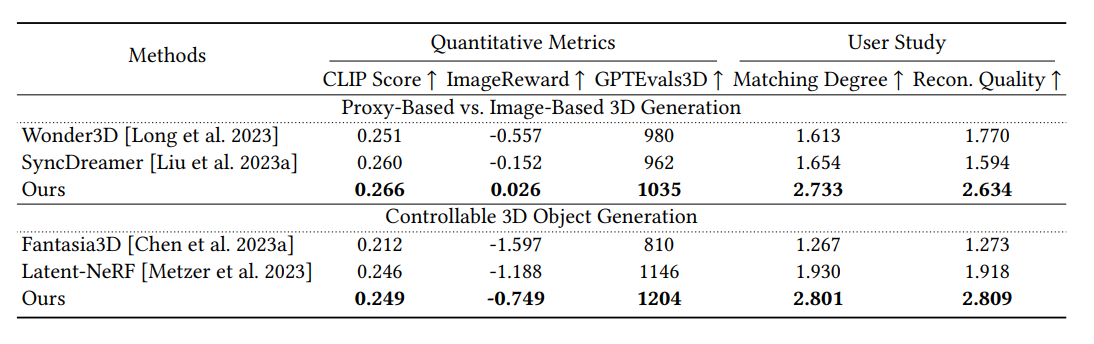
아무래도 다른 모델들이 single image만을 사용하다보니 ambiguity로 인해 아티팩트들이 많이 생긴것을 확인할 수 있습니다.
반면 Coin3D는 proxy로부터 3D context를 지속적으로 얻을 수 있어 view ambiguity 문제에서 자유로운 것 같습니다. 사실 proxy가 이미 충분히 3D 에셋의 모양을 잘 설며애서 더욱 그런 것 같습니다.
더 복잡한 모양에서의 생성 결과가 다소 궁금하네요
2. Comparison on Controllable 3D Object Generation
다음은 input으로 coarse shape를 입력으로 받는 3D 생성 모델들과의 비교입니다.

생성 결과가 훨씬 뛰어난 것을 확인할 수 있습니다.
4. Ablation Study

다른 부분은 생략하고 Volume-SDS에 대한 부분만 가져왔습니다.
렌더링 결과의 rgb, mask 이미지만을 loss로 사용했을 때와는 달리 volume-SDS를 통해 3D 지오메트리 정보가 NeuS 네트워크에 보다 명확히 전달되는 것을 확인할 수 있습니다.
소감
최근 실무에서 StableDiffusion을 다루면서, 딱 원하는 모양의 이미지를 생성해주는 ControlNet을 요긴하게 사용하고 있습니다.
아직 3D 생성에서는 이런 모델이 없었는데 Coin3D가 정말 ControlNet 역할의 적절한 해결책을 제공해 준 것 같습니다.
Basic shape을 만들어주어야 한다는 별도의 노력이 필요하지만, 도형을 이어 붙이는 것 정도는 수십분만 매워도 쉽게 할 수 있으니까요
코드가 공개되어 사용할 수 있게되면 좋겠습니다.
