
Introduction
기존의 diffusion 기반 모델들은 이미지 생성은 정말 뛰어났지만, 텍스트 프롬프트 만으로는 우리가 원하는 이미지를 뽑기에는 상당히 어려웠습니다.

예를들어 왼쪽과 같은 포즈 스켈레톤과 동일한 자세를 취하는 사람 이미지를 생성하고 싶어도, 프롬프트 만으로는 여러차례 시도해야 간신히 한 두장 정도 비슷한 사진을 건질 수 있습니다.
파인 튜닝을 통해 저 포즈를 취하는 이미지를 생성하도록 모델을 학습시킬 수 있으나, 데이터 문제, 학습 비용등의 수많은 문제가 남아있죠. 또한, 이렇게 모델의 파라미터를 변경시키면 이전에 학습했던 prior들을 잃어버리는 등의 문제가 발생합니다.
이 논문에서는 이러한 태스크를 수행하기 위해 ControlNet이라는 구조를 기존의 diffusion model에 연결하는 방식을 제안합니다.
Method
1. ControlNet의 기본 구조
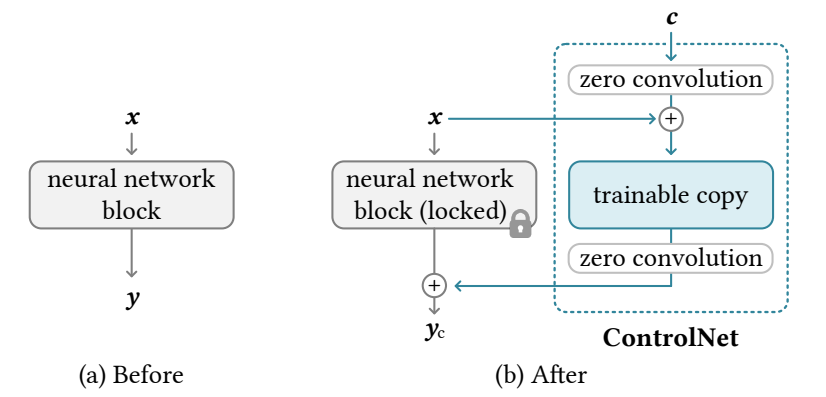
ControlNet의 기본 구조는 다음과 같습니다.
- pre-trained UNet의 인코딩 레이어를 복제한 사본을 만듦. 이 사본이 ControlNet이 됨
- ControlNet과 diffusion model의 레이어를 zero convolution layer 2개로 연결
- 복제된 사본은 원래 모델의 input feature map에 더해 conditioning vector를 입력으로 받아, (학습된) 스타일을 갖도록 feature를 처리하여 기존 UNet에 합침
여기서 zero convolution layer는 모든 weight, bias가 0으로 초기화된 1x1 convolution layer를 말합니다.
수식으로 나타내자면 기존의 Diffusion model의 각 블록의 동작은 다음과 같이 나타낼 수 있습니다.

input feature 를 입력으로 받아 파라미터 를 갖는 블록을 통과하면 output feature 가 출력됩니다.
여기에 ControlNet을 더하면 다음과 같습니다.
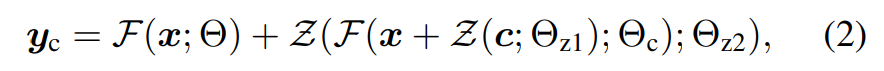
- 에 zero convolution으로 인코딩 된 condition feature 를 합산
- 학습가능한 사본 layer를 통과하여 와 동일한 크기의 condition feature를 추출
- 두번째 zero convolution을 통과하여 원래 layer의 출력값 에 합산
학습시에 기존 UNet layer는 동결되므로, 이렇게하면 기존 pretrained diffusion model의 능력은 보존하면서 컨디션으로 주어진 스타일의 이미지를 출력하도록 학습이 가능하다고 합니다.
또한, zero convolution을 사용함으로써, 아직 ControlNet의 학습이 덜 된 초기에 노이즈가 생성 결과에 영향을 끼쳐 잘못 학습되는 문제 역시 예방할 수 있다고 합니다.
2. ControlNet for Text-to-Image diffusion
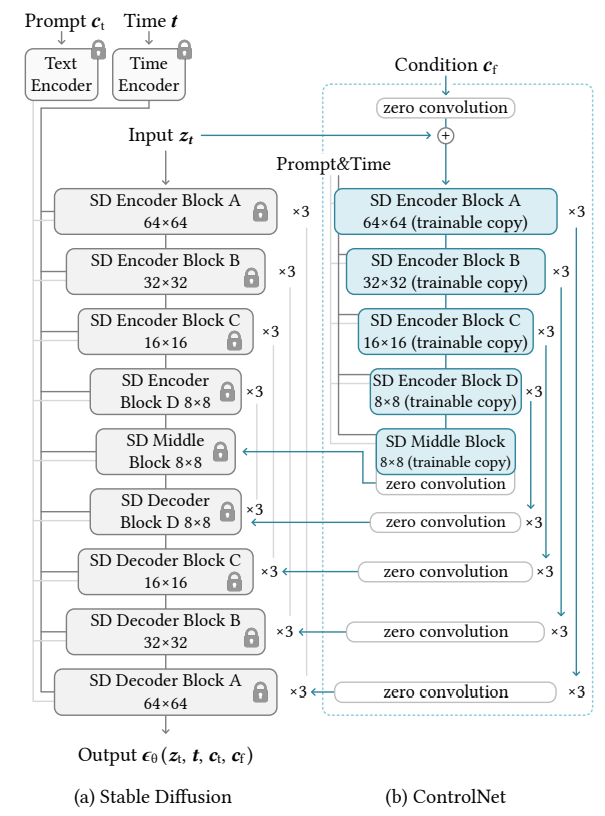
논문에서는 가장 대중적인 Stable Diffusion(SD)에 ControlNet을 적용하는 것을 예시로 설명합니다.
자세한 구조는 생략하고 설명드리자면, SD의 인코더 블록 12개와 bottleneck 역할을 하는 미들 블록 1개 총 13개의 블럭을 복제합니다.
또한 SD와 동일한 크기의 feature를 추출하기 위해 512x512 이미지를 컨디션 입력 으로 받아 64x64x128의 latent image를 추출하도록 별도의 인코딩 레이어를 구성했다고 합니다.
이렇게 모델 구조를 구성했을 때, SD를 그냥 최적화 하는 것보다 오직 23% GPU 메모리와, 34%의 시간이 더 소요되었다고 합니다.
사실 ControlNet도 SD의 절반 이상의 크기를 갖기 때문에 아무리 기존 SD 파라미터를 동결하더라도 GPU 메모리나 시간은 줄일 수 없는 것 같습니다.
단순 계산해보니 25개 블럭의 기존 SD를 학습할 때는 대충 2배로 50개 블럭만큼의 메모리가 필요하고, ControlNet을 붙였을 때는 25 + (13 * 2) + (zero convolution)로 메모리가 더 필요한 것이 맞는 것 같습니다.
3. Training
ControlNet 학습에 적용된 기법에 대해 설명하겠습니다.
ControlNet이 적용된 Diffusion model의 학습을 수식으로 나타내면 다음과 같습니다.
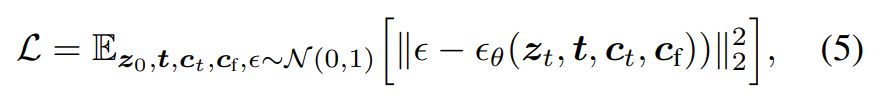
- : input latent
- : timestep
- : input prompt
- : input condition
즉 실제 더해진 노이즈와 예측된 노이즈 사이의 차이를 최소화하는 일반적인 diffusion model의 학습 방식입니다.
하지만 저자들은 주어진 condition에 맞는 이미지를 더 잘 만들어내도록 하기 위해, 학습 데이터의 절반에 대해 를 빈 문자열을 인코딩 한 것으로 교체했다고 합니다.
이렇게 함으로써 모델이 텍스트 프롬프트에 의존하지 않고 주어진 condition image의 의미론적인 부분을 더 잘 인식할 수 있다고 합니다.

추가적으로 저자들은 모델이 점진적으로 학습하지 않고, 어느 순간 갑자기 입력 컨디션을 정확히 따라가는 것을 관찰했다고 합니다.
위 figure에서 주어진 condition image를 잘 따르지 못하다가, step 6133부터 갑자기 입력 이미지를 잘 따르는 것을 확인할 수 있습니다.
저자들은 이를 sudden convergence phenomenon이라고 명명했습니다. 일반적으로 10K 이전에 이런 현상이 관측되었다고 합니다.
4. Inference
추론시에 생성 이미지에 영향을 미치는 몇가지 조절 방법에 대해 설명하겠습니다.
Classifier-free guidance resolution weighting
SD는 CFG(Classifier-free guidance) 기법을 통해 고품질의 이미지를 생성할 수 있습니다.
CFG의 공식은 으로, 에 따라 예측 노이즈에 input prompt가 얼마나 영향을 끼칠 것인지 결정합니다.
여기에 ControlNet의 컨디션(hint)이 더해진다고 했을 때, 이 cond, uncond 양쪽에 더할 것인지, cond에만 더할 것인지 선택할 수 있다.

논문에서는 양쪽에 더하는 경우 CFG guidance의 영향을 완전히 제거해버린다고 하며(b), cond에만 더하는 경우 guidance가 너무 강력하게 적용된다고 합니다(c).
때문에 저자들은 cond에만 를 더하되, 가중치 를 곱해서 더하는 방식으로 적용되는 정도를 조절했다고 합니다.
구체적으로 로 는 i번째 블럭의 사이즈를 의미합니다.

그런데 이상한 점이 논문에서는 로 설명하고 있는데, 이 경우 가 1보다 커지게 됩니다.
또, 제가 알기로 블럭의 사이즈는 512, 256, ... , 64로 점점 줄어드는 것으로 알고 있는데 8, 16, ..., 64로 커지는 형태도 이상하다고 생각했습니다.
그래서 코드를 살펴보아는데, 제가 코드를 잘 못읽은 것인지 를 적용하는 부분을 찾을 수 없었습니다.
대신에 다음과 같은 코드를 발견했습니다.
model.control_scales = [strength * (0.825 ** float(12 - i)) for i in range(13)] if guess_mode else ([strength] * 13)
# Magic number. IDK why. Perhaps because 0.825**12<0.01 but 0.826**12>0.01이 코드가 를 계산하는 코드가 맞다면, 실제로는 0.825의 제곱으로 로 점점 커지도록 설계된 듯 합니다.
어느쪽이 맞는지는 모르겠지만, 저는 0.825의 제곱을 사용하는 코드의 구현이 논문이 제시한 설명에 더 부합한다고 생각합니다.
혹시 이부분에 대해 잘 알고계신 분이 있다면 댓글 남겨주시면 감사하겠습니다...
코멘트
이미 ControlNet은 이미지 생성 태스크에서 특정 조건의 이미지를 출력하기 위해 메이저하게 사용되고 있는 것으로 알고 있습니다.
때문에 짚고 넘어가는 것이 좋을 것 같아 리뷰하게 되었습니다.
사실 특정 도메인에 모델을 적용하기 위해 일반적으로 파인튜닝을 수행하는데, 파인튜닝이 항상 만능은 아니라는 것을 알 수 있었습니다.
또, zero convolution을 이용해 특정 task만을 위한 구조를 추가로 붙이는 방법이 인상깊었습니다. 혹시 SD 뿐만 아니라 다른 모델(3D 생성모델 등)에도 feature encoder 부분에 기존 파라미터를 두고 새롭게 사본을 붙이는 방법이 가능하지 않을까 고민하게 되네요
