cs 지식
1.디자인 패턴 이란?

디자인 패턴은 프로그램 설계 시 나타난 문제점을 객체 간의 상호 작용을 활용해 해결 가능한 '규약' 형태로 정의한 것입니다. 디자인 패턴은 라이브러리와 프레임워크 개발의 기본 원칙이 되며, 현재 다양한 라이브러리와 프레임워크들 역시 특정 디자인 패턴을 기반으로 만들어져
2.프레임워크 vs 라이브러리

라이브러리는 특정 기능들을 모듈화하여 공통으로 사용할 수 있게 제공하는 것으로, 폴더와 파일명에 대한 규칙이 없고 프레임워크에 비해 더 자유롭습니다.ex) axios코드를 재사용하기 쉽다.코드의 내용을 숨겨 기술 유출을 방지할 수 있다.이미 구현되어 있는 기능들을 가져
3.싱글톤 패턴(Singleton)
싱글턴 패턴은 특정 클래스의 인스턴스가 오직 하나만 존재할 수 있게 하는 디자인 패턴입니다. 비용이 많이 드는 데이터베이스 연결 모듈처럼 인스턴스 생성에 높은 비용이 소모되는 경우에 이 패턴이 효율적으로 활용됩니다. 그러나 싱글턴 패턴의 사용으로 인해 의존성이 높아지고
4.싱글톤 패턴을 구현하는 7가지 방법
싱글톤 패턴의 생성 여부를 확인하고, 인스턴스가 없는 경우에만 새로 생성하며, 이미 존재한다면 기존 인스턴스를 반환합니다. 그러나 이 코드는 메서드의 원자성이 보장되지 않아 멀티스레드 환경에서 싱글톤 인스턴스가 2개 이상 생성될 가능성이 있습니다.synchronized
5.팩토리 패턴
단어 그대로 오브젝트를 찍어내는 공장을 만드는것입니다.팩토리패턴이란 상속 관계에 있는 두 클래스에서 상위 클래스가 중요한 뼈대를 결정하고,하위 클래스에서 객체 생성에 관한 구체적인 내용을 결정하는 패턴입니다.상위 클래스에서는 객체 생성방식에 대해 알 필요가 없어져 유연
6.이터레이터패턴
이터레이터(iterator)는 다양한 컬렉션을 하나의 인터페이스를 통해 조회하고, 컨테이너의 요소들에 접근하는 디자인 패턴입니다. 이 패턴은 각기 다른 자료구조들을 동일한 인터페이스로 쉽게 순회할 수 있도록 지원합니다. 컨테이너는 동일한 요소들을 저장하는 집합으로, 배
7.DI와 DIP
DI 란? 의존성주입(DI, Dependency Injection)이란 메인 모듈(main mudule)이 ‘직접’ 다른 하위모듈에 대한 의존성을 주기보다는 중간에 의존성 주입자(dependency injector)가 이 부분을 가로채 메인 모듈이 ‘간접’적으로 의존성
8.전략 패턴
전략 패턴은 '캡슐화된 알고리즘'을 전략이라고 부르며, 이를 컨텍스트 내에서 변경하고 상호 교체 가능하게 하는 디자인 패턴입니다.
9.옵저버패턴
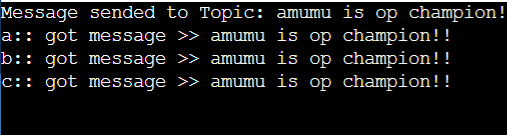
옵저버패턴이란 주체가 어떤 객체(subject)의 상태 변화를 관찰하다가 상태 변화가 있을 때마다 메서드 등을 통해 옵저버 목록에 있는 옵저버들에게 변화를 알려 주는 디자인 패턴입니다.트위터의 메인 로직, 그리고 MVC패턴에도 적용되었습니다.업로드중..
10.프록시 패턴
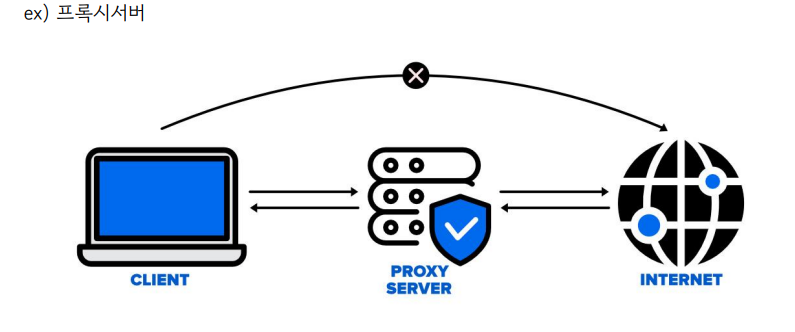
프록시패턴이란 객체가 어떤 대상 객체에 접근하기 전, 그 접근에 대한 흐름을 가로채서 해당 접근을 필터링하거나 수정하는 등의 역할을 하는 계층이 있는 디자인패턴입니다
11.MVC패턴
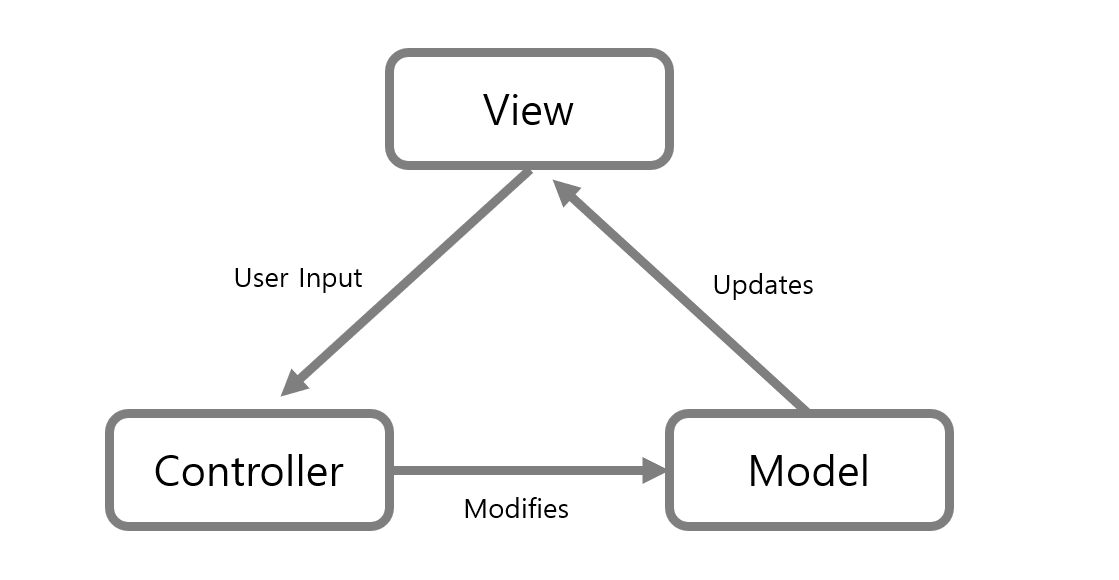
MVC패턴은 모델(Model), 뷰(View), 컨트롤러(Controller)로 이루어진 디자인 패턴입니다.MVC패턴을 반영한 대표적인 프레임워크로 Spring WEB MVC가 있습니다.모델(model)은 애플리케이션의 데이터인 데이터베이스, 상수, 변수 등을 뜻합니다
12. flux 패턴
flux패턴은 단방향으로 데이터 흐름을 관리하는 디자인패턴입니다.ex)페이스북은 “읽은 표시(mark seen)”에 대한 기능장애를 겪었습니다. 어떤 페이지에서 메시지를 읽었는데 다른 페이지에서는 메시지가 안 읽었다고 뜨는 것이죠. 이는 모델(model)과 뷰(view
13.네트워크, 처리량, 트래픽, 대역폭, RTT
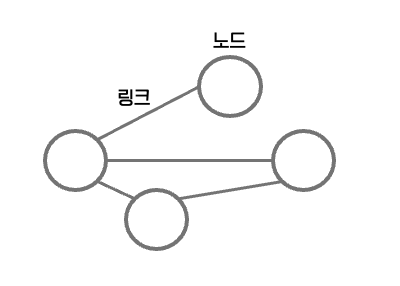
네트워크란 노드(node)와 링크(link)가 서로 연결되어 있으며 리소스를 공유하는 집합을의미합니다.노드 : 서버, 라우터, 스위치 등 네트워크 장치링크(엣지) : 유선 또는 무선과 같은 연결매체 (와이파이나 LAN)트래픽은 특정시점에 링크 내의 “흐르는” 데이터의
14.네트워크 토폴로지 : 버스, 스타, 트리
네트워크 토폴로지 네트워크 토폴로지란 노드와 링크가 어떻게 구성되어있는지를 말하며 버스, 스타, 트리 등의 토폴로지가 있습니다 버스 토폴로지 특징 하나의 회선에 여러개의 노드 노드 추가, 삭제 쉬움 설치비용 적음 장점 소규모 네트워크를 구축하기 매우 쉬움. 한 노드에
15.네트워크 토폴로지 : 링, 메시
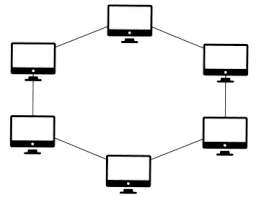
고리형태노드 추가, 삭제가 쉬움노드 수가 많아져도 데이터 손실이 없음. 토큰을 기반으로 연속적으로 노드를 거치며통신권한 여부를 따지고 해당 권한이 없는 노드는 데이터를 전달받지 않음.링크 또는 노드가 하나만 에러 발생해도 전체 네트워크에 영향토큰이 없는 노드는 통신에
16.네트워크 토폴로지의 필요성과 병목현상
토폴로지를 파악함으로써 병목현상을 해결하는 척도가 됩니다.병목(bottleneck) 현상은 여러가지 의미로 쓰이나 네트워크에서는 트래픽에 의해 데이터 흐름이 제한되는 상황을 말합니다. 일명 핫스팟이라고도 합니다.구축된 시스템의 토폴로지를 알고 있다면 어떠한 부분에 어떠
17.유니캐스트, 멀티캐스트, 브로드캐스트
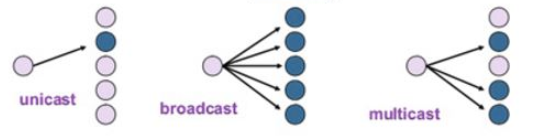
유니캐스트란 1 : 1통신을 말합니다. 대표적으로 HTTP통신이 있습니다.가장 일반적인 네트워크 전송 형태입니다.브로드캐스트는 1 : N 통신입니다. 그룹이 아닌 연결되어있는 모든 노드에게 데이터를 전달합니다. 예로는 ARP가 있습니다.멀티캐스트는 1 : N 통신입니다
18.LAN, MAN, WAN
네트워크는 LAN, MAN, WAN 순으로 분류됩니다. LAN이 가장 작은 단위, WAN이 가장 큰 단위이며 보통은 반경, 속도의 크기를 기반으로 분류합니다.그러나 반경이나 속도는 기술의 발전에 따라 바뀌므로 개념적으로 이해해서 분류하는게 중요합니다.LAN(local
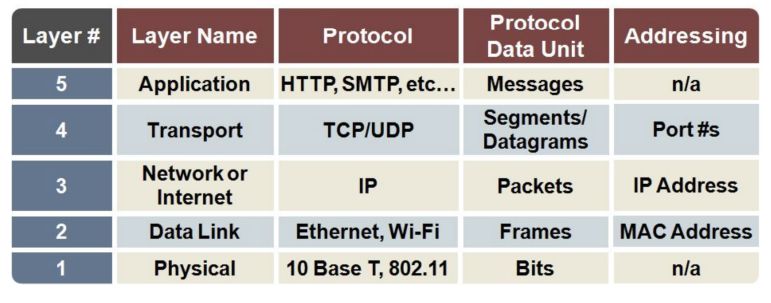
19.TCP-IP 4계층 개념, 캡슐화, 비캡슐화, PDU, OSI 7계층

장치들이 인터넷 상에서 데이터를 주고받을 때 쓰는 독립적인 프로토콜의 집합을 의미합니다.TCP / IP는 TCP(Transmission Control Protocol) / IP(Internet Protocol)이라는 의미인데 인터넷을 통해 데이터를 보낼 때 주로 TCP
20.MTU와 MSS와 PMTUD
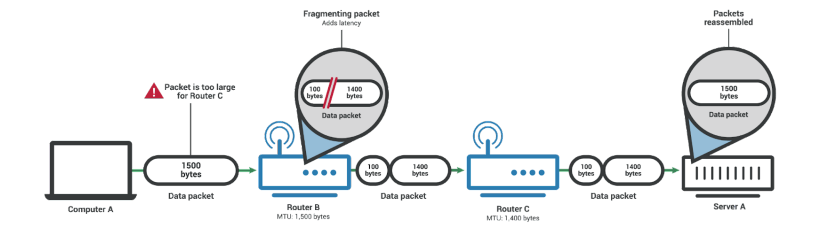
네트워크에 연결된 장치가 받아들일 수 있는 최대 데이터 패킷의 크기를 말합니다. 이크기를 기준으로 데이터는 쪼개져서 패킷화됩니다. 네트워크 경로 상에 있는 아무 장치나 MTU보다 패킷이 크면 그 패킷은 분할될 수도 있습니다.Router C의 MTU가 1400바이트이기
21.애플리케이션 계층(application)
HTTP, SMTP, SSH, FTP가 대표적이며 웹 서비스, 이메일 등 서비스를 실질적으로사람들에게 제공하는 층입니다.HTTP(Hypertext Transfer Protocol)은 처음에는 서버와 브라우저간에 데이터를 주고 받기위해 설계된 프로토콜입니다. 지금은 브
22.전송 계층(transport)
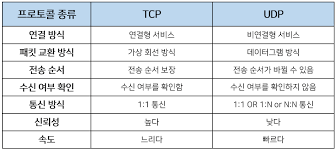
TCP, UDP가 대표적이며 애플리케이션계층에서 받은 메시지를 기반으로 세그먼트 또는 데이터그램으로 데이터를 쪼개고 데이터가 오류없이 순서대로 전달되도록 도움을 주는 층입니다.가상회선패킷교환방식오류검사 메커니즘재전송 : 시간 초과 기간이 지나면 서버는 전달되지 않은 데
23.3-웨이 핸드셰이크
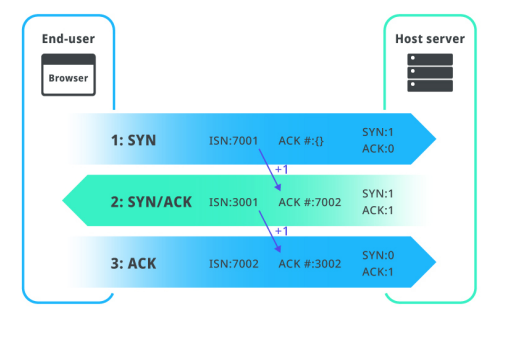
TCP의 연결성립은 다음과 같은 3개의 과정을 거쳐 성립됩니다.SYN 단계: 클라이언트는 서버에 클라이언트의 ISN을 담아 SYN을 보낸다.SYN + ACK 단계: 서버는 클라이언트의 SYN을 수신하고 서버의 ISN을 보내며 승인번호로 클라이언트의 ISN + 1을 보낸
24.4-웨이 핸드셰이크와 TIME_WAIT
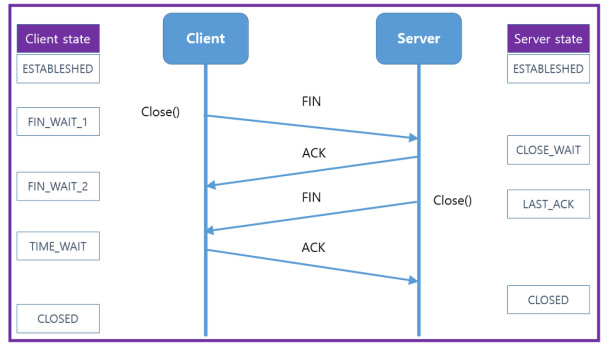
TCP의 연결해제과정은 다음과 같이 4개의 과정으로이루어집니다.1\. 먼저 클라이언트가 연결을 닫으려고 할 때 FIN으로 설정된 세그먼트를 보냅니다. 그리고 클라이언트는 FIN_WAIT_1 상태로 들어가고 서버의 응답을 기다립니다.서버는 클라이언트로 ACK라는 승인 세
25.디자인 패턴이란?
SW 재사용성, 호환성, 유지 보수성을 보장.디자인 패턴은 아이디어임, 특정한 구현이 아님.프로젝트에 항상 적용해야 하는 것은 아니지만, 추후 재사용, 호환, 유지 보수시 발생하는 문제 해결을 예방하기 위해 패턴을 만들어 둔 것임.하나의 클래스는 하나의 역할만 해야 함
26.라우팅 , 라우터
네트워크에서 데이터(패킷)를 보낼 때 최적의 경로를 선택하는 과정이며 라우터가 이를 수행합니다. 데이터는 보통 출발지에서 목적지로 가는 동안 여러개의 라우터를 거치며 여러번의 라우팅을 수행합니다. (라우팅은 보통 초당 수백만번 일어납니다.)라우터는 네트워크 사이에서 데
27.MAC주소, ARP, RARP
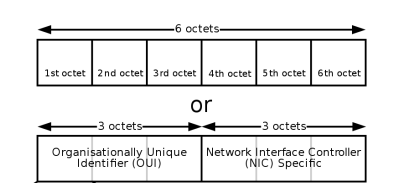
IP 주소(Internet Protocol address)는 논리적 주소이며 컴퓨터 네트워크에서 장치들이 서로를 인식하고 통신을 하기 위해서 사용하는 특수한 번호이며 IP를 기반으로 통신한다고도 하지만 사실상 그 밑에 물리적 주소인 MAC 주소를 통해 통신합니다.MAC
28. IPv4와 IPv6

IPv4는 32비트로 표현되는 주소체계이며 2^32개의 주소(41억 9천만 주소)를 표현할 수있습니다. 8비트 단위로 점을 찍어 4개로 구분해서 표현하며 보통 8비트를 10진수로표현해서 말합니다.이 주소체계만으로는 부족하기 때문에 NAT, 서브네팅 여러개의 부수적인 기
29.클래스풀(Classful IP Addressing)
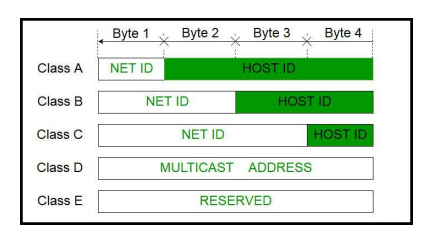
IP주소는 인터넷 주소로 네트워크주소, 호스트주소 즉, 두 부분으로 나뉩니다.네트워크주소는 호스트들을 모은 네트워크를 지칭합니다. 네트워크주소가 동일 = 로컬네트워크호스트주소 : 호스트를 구분하기 위한 주소네트워크 호스트(network host)는 컴퓨터 네트워크에 연
30.클래스리스와 서브넷마스크, 서브네팅

클래스풀의 단점을 해결하기 위해 클래스리스가 나왔습니다. 클래스로 나누는 것이 아닌 서브넷마스크를 중심으로 어디까지가 네트워크 주소고 어디까지가 호스트주소인지를 나눕니다.서브네팅 : 네트워크를 나눈다는 의미서브넷 : 서브네트워크, 쪼개진 네트워크서브넷마스크 : 서브네트
31.공인IP(public IP)와 사설IP(private IP)와 NAT
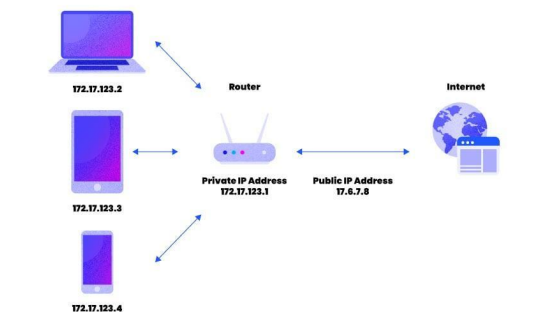
IP주소의 부족을 공인IP(public IP)와 사설IP(private IP)로 나누고 중간에 NAT이라는 기술을 통해 해결합니다.NAT (Network Address Translation)는 패킷이 트래픽 라우팅 장치를 통해 전송되는 동안 패킷의 IP주소를 변경, I
32.HTTP 헤더(header)
사용자가 HTTP요청을 하게 되면 헤더와 바디를 주고 받습니다. https://www.naver.com/ 를 요청할 때 받게되는 리소스 중 하나인 count.nhn를 볼까요? 다음과 같은 부분에서 response탭에 있는 컨텐츠를 body, 그리고 headers에 있
33.HTTP/1.0과 HTTP/1.1의 차이, keep-alive, HOL
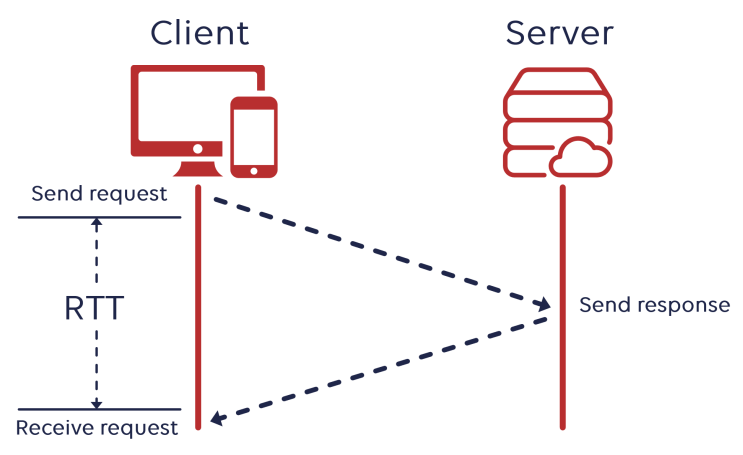
HTTP/1.0은 수명이 짧은 연결이라고 합니다. HTTP요청은 자체 요청에서 완료가 됩니다. 각 HTTP 요청당 TCP 핸드셰이크가 발생되며 기본적으로 한 연결당 하나의 요청을 처리하도록 설계되었습니다.한번 연결할 때마다 TCP연결을 계속해야 하니 RTT가 늘어나는
34.HTTP2와 HTTP3의 차이
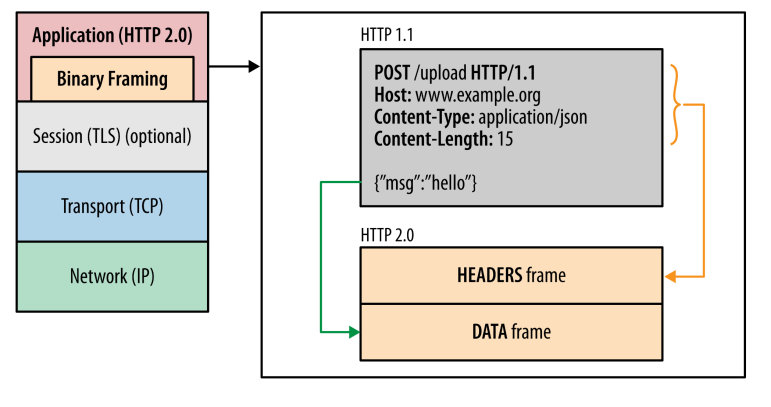
2009년 구글은 HTTP/1.1의 한계를 극복하기 위해 SPDY 프로토콜을 개발했습니다. 이 후 2015년, SPDY를 기반으로 하는 HTTP/2 프로토콜을 만들었습니다.애플리케이션 계층과 전송 계층 사이에 바이너리 포맷 계층을 추가합니다. HTTP 1.0은 일반 텍
35.HTTPS와 TLS 1. 암호화

암호화는 승인된 당사자만 정보를 이해할 수 있도록 데이터를 “스크램블”한 방법입니다. 이를 복호화하려면 송신자와 수신자가 서로 동의한 “키”가 필요합니다. 또한 이를 만들기 위해 키가 쓰이기도 합니다. ciphertext = plaintext + key각 단어나 문자를
36.HTTPS와 TLS 핸드셰이크
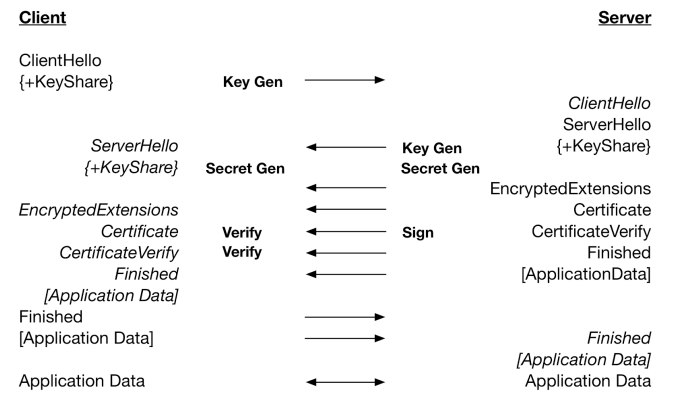
SSL(Secure Socket Layer)은 SSL 1.0부터 시작해서 SSL 2.0, SSL 3.0,TLS(TransportLayer Security Protocol) 1.0, TLS 1.3까지 버전이 올라가며 마지막으로TLS로 명칭이 변경되었습니다. 여기서는 TL
37.로컬스토리지의 개념
로컬스토리지는 웹 스토리지 객체로 브라우저 내에 { key : value } 형태로 오리진에 종속되어 저장되는 데이터를 말합니다. (오리진이 같은 브라우저 내에서 공유 됩니다.)하나의 키에 오로지 하나의 값만 저장됩니다.데이터는 사용자가 브라우저에서 수동으로 삭제하지
38. 세션스토리지
세션 스토리지(session Storage)는 로컬 스토리지와 매우 유사합니다.세션 스토리지는 웹 스토리지 객체로 브라우저 내에 { key : value } 형태로 오리진에종속되어 저장되는 데이터를 말합니다. (오리진이 같은 브라우저 내에서 공유 됩니다.)하나의 키에
39.쿠키(Cookie)

쿠키는 브라우저에 저장된 데이터 조각입니다. 클라이언트에서 먼저 설정할 수도 있고 서버에서 먼저 설정할 수 있으나 보통은 서버에서 먼저 설정해서 쿠키를 만드는게 일반적입니다.서버에서 응답헤더로 Set-Cookie로 설정해서 쿠키를 보내면 그 때 부터 클라이언트에서 요청
40.로컬스토리지, 세션스토리지, 쿠키의 공통점과 차이점
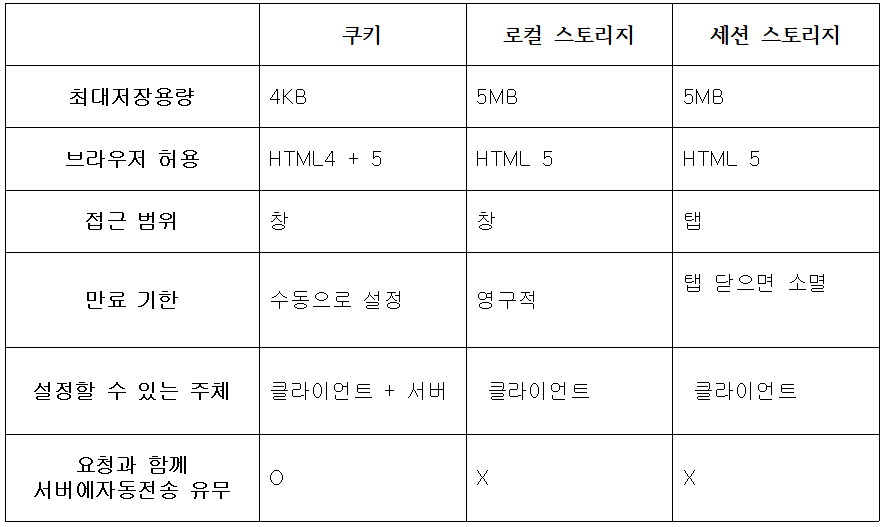
브라우저에 캐싱을 함으로써 서버에 대한 요청을 줄여 서버부하를 방지할 수있습니다.캐싱으로 인해 다운로드 하는 컨텐츠가 줄어들어 웹사이트의 컨텐츠를 더 빨리다운로드가 가능합니다.사이트 기본 설정 커스터마이징(색상, 글꼴 크기 등)을 저장하거나 로그인 상태를유지할 때 사용
41.세션기반인증방식 : 개념

로그인은 세션기반인증방식 또는 토큰기반인증방식으로 구현됩니다.HTTP의 특징 중 하나는 상태없음(stateless) 하다라는 것인데, 즉, HTTP 요청을 통해ㅜ데이터를 주고 받을 때 요청이 끝나면 요청한 사용자의 정보 등을 유지하지 않는 특징이 있습니다.이렇기 때문에
42.토큰기반인증방식(access토큰, refresh토큰) 개념
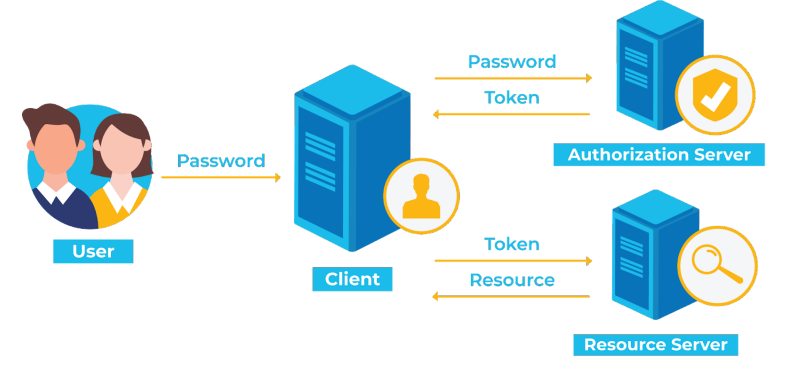
토큰기반 인증방식은 state를 모두 토큰 자체만으로 처리하며 토큰을 처리하는 한 서버를 두고 다른 컨텐츠를 제공하는 서버는 모두 stateless하게 만들자는 이론이 담긴 방식입니다. 왜 토큰을 관리하는 서버는 따로 두어야 할까요?이는 여러개의 서버를 운용한다라고 했
43.HTTP 상태코드(status code)
서버가 요청을 잘 받았으며 해당 프로세스를 계속 이어가며 처리하는 것을 의미합니다.100 : 계속함을 의미합니다.서버가 요청을 잘 받았고 이를 기반으로 클라이언트에게 성공적으로 데이터를 보낸 것을의미합니다.200 OK : 요청이 성공적으로 되었습니다.201 Create
44.GET과 POST의 차이
HTTP 메서드는 다음과 같이 여러개가 있지만 이중에서 오늘은 중요한 GET과 POST를알아보겠습니다.GETPOSTPUTHEADDELETE PATCHOPTIONSCONNECTTRACEurl을 기반으로 데이터를 요구하는 방법입니다.url을 기반으로 하기 때문에 길이 제한
45.PUT과 PATCH의 차이
둘 다 데이터를 수정할 때 쓰는 메서드입니다. 그러나 다음과 같은 차이가 있습니다.업데이트하는 데이터의 전체를 보내다. 요청을 보낼 때 해당 데이터 전체를 보내야 하고 전체 데이터의 교체를 의미합니다.또한, PUT은 만약 해당 데이터가 없다면 새로이 생성하고 있다면 해
46.네트워크를 이루는 장치의 이해
네트워크 기기는 계층별로 나눌 수 있습니다.상위 계층을 처리하는 기기는 하위계층을 처리할 수 있지만 그 반대는 불가합니다. 예를 들어 애플리케이션 계층을 담당하는 로드밸런서는 네트워크 분산처리도 가능하지만 물리계층의 장치 중 하나인 NIC는 이를 하지도 못합니다.레이어
47.애플리케이션 계층
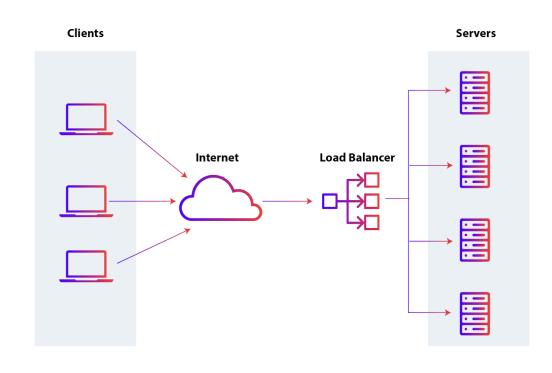
L7 스위치는 로드밸런서라고도 하며, 서버의 부하를 분산하는 기기입니다. 서버이중화,보안에 강점이 있는 장치입니다. IP, Port뿐만이 아니라 url, 헤더, 쿠키 등을 기반으로 트래픽을 분산합니다. 헬스체크를 통해 장애가 발생한 서버를 확인하고 해당 서버로트래픽을
48.전송 계층
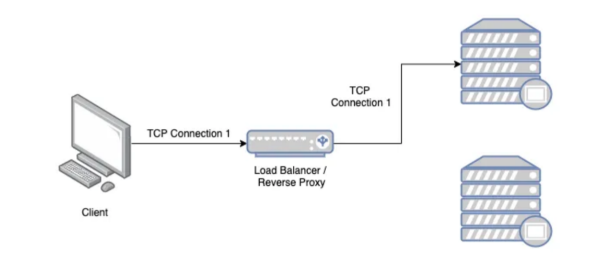
전송계층의 대표적인 네트워크 장치로는 L4스위치가 있습니다.로드밸런서의 특징인 트래픽 분산 등을 할 수 있습니다. 패킷의 IP주소와 Port번호를 참고해서 적절히 트래픽분산을 할 수 있습니다. 또한 전송계층의 TCP, UDP 등의 헤더를 기반으로 우선순위를 판단해서 분
49.인터넷 계층
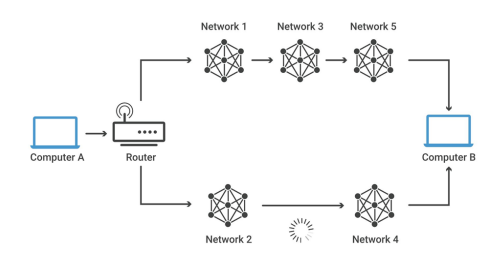
라우팅은 하나 이상의 네트워크에서 경로를 선택하는 프로세스를 말하는데 이 라우팅을하는 장비를 말합니다. 다른 네트워크에 존재하는 장치끼리 서로 데이터를 주고받을 때“패킷소모 최소화”, “경로 최적화"하는 장비입니다.L2 스위치의 기능 + 라우팅을 하는 장비를 말합니다.
50.데이터링크계층
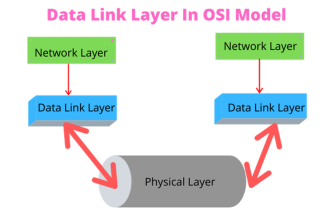
앞서 TCP계층을 설명할 때 데이터링크계층과 물리계층을 합해서 링크계층으로 설명을 했는데요. 이 링크계층을 쪼개서 데이터링크계층과 물리계층으로 나눌 수 있습니다.데이터 링크 계층은 ‘이더넷 프레임’을 통해 에러 확인, 흐름 제어, 접근 제어를 담당하는 계층을 말합니다.