합성곱 신경망(Convolutional Neural Network)
- computer vision 영역에서 거의 default로 사용되는 핵심 deep learning 구조
- 분류 문제, 자세 추정 문제, 정보 인식, 의료 영상이나 문자 인식, 알파고 등에 사용된다.
기존 computer vision tasks challenge
- 다양한 경우에 대해 robust하게 영상 인식을 하는 알고리즘이 동작해야한다.
- 이러한 challenge에 정상적으로 작동을 하지 못하였지만, CNN은 패턴 분석을 하여 검출하고 인식할 수 있도록 하였다.
CNN의 작동 원리

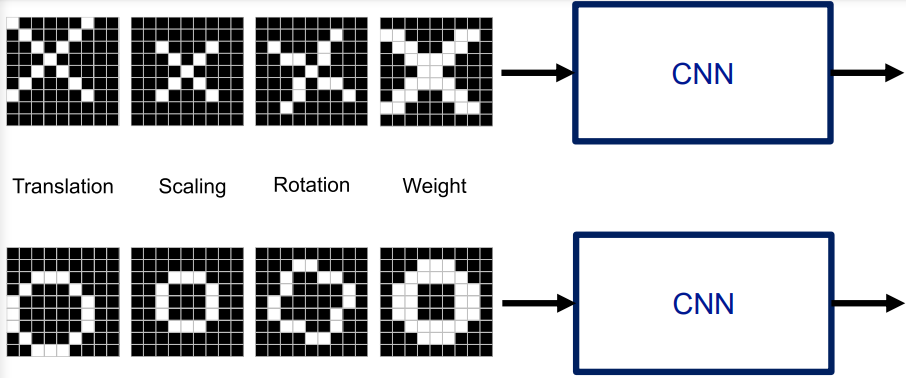
- 표준화된 상태와 변형된 상태의 이미지를 class화 해야한다.
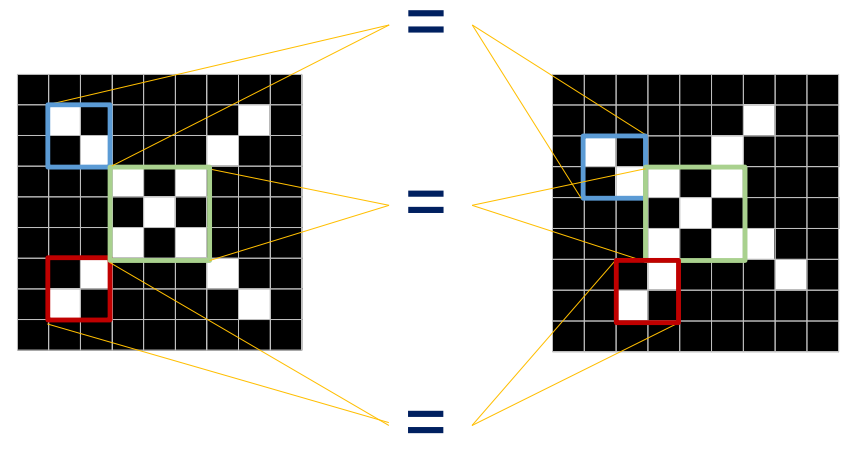
- 주어진 이미지의 부분을 보면 일관된 패턴이 존재하는 것을 확인할 수 있다.
- CNN에서는 작은 특정 패턴들을 정의하고, 해당 패턴들이 주어진 이미지 상에 있는지를 판단한다.
- 패턴을 정의한 뒤, 주어진 이미지 상에 어느 위치에 나타나는지 만약에 패턴이 나타나면 얼마나 정확하거나 강하게 나타나는지 파악한다.
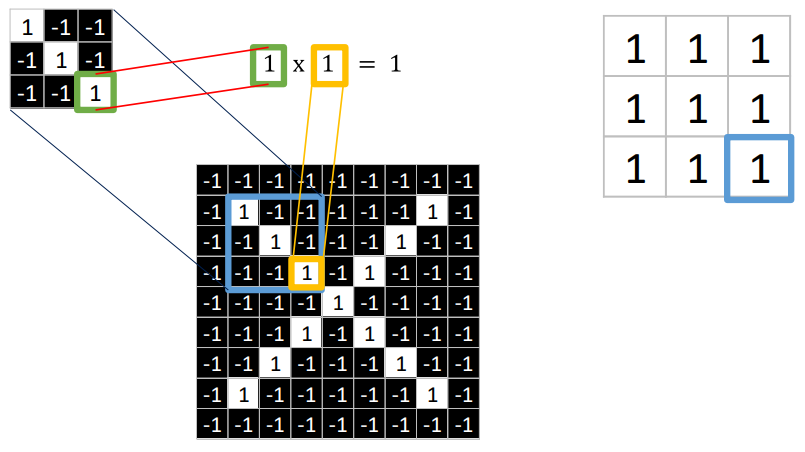
- 이러한 패턴을 이미지에 overlap 시킨 뒤 pixel값과 이미지에 있는 값을 곱하여 두 값들의 곱셈으로 나타낸다.
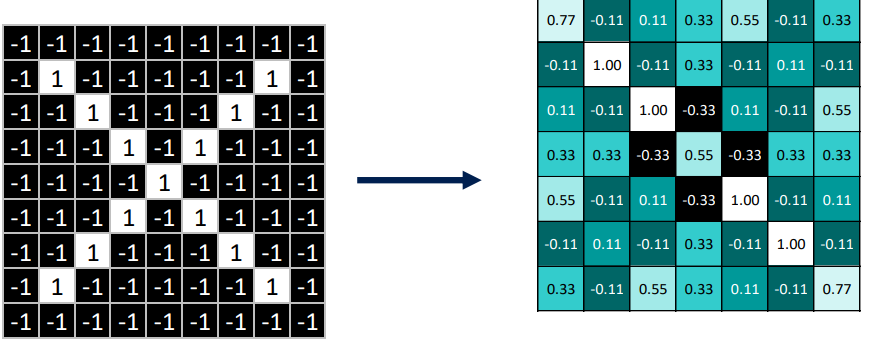
- 이 값을 다 합하고 패턴의 총 pixel의 개수로 나누면 현재 위치의 매칭 값을 %로 나타낼 수 있다.
- 이러한 매칭의 정도를 나타내는 결과 이미지를 활성화 지도(activation map)이라고 한다.
- 특정한 활성화 지도는 특정 convolution filter를 주어진 입력 이미지에 가능한 모든 위치에 overlap을 시켜서 매칭 되는 정도를 얻었을 때 나오는 결과 이미지가 된다.

- 특정 convolution filter를 이미지 상의 각 특정 위치에 overlap을 시킨다.
- 각 이미지 pixel과 filter의 이미지 pixel을 곱하고 더한다.
- 이를 feature의 pixel 수로 나누어 확률을 구한다.(생략하는 경우도 많다.)
Convolution Layer
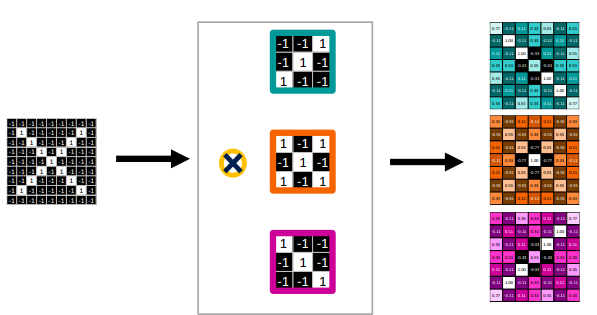
- 여러 개의 고유한 패턴을 가진 다수의 filter가 존재하고, 이를 주어진 이미지에 적용하여 activation map을 filter의 수만큼 만든다.
- 한 convolution layer는 여러 장의 사진으로 이루어질 수 있다.
- 이러한 여러 장의 사진 수를 channel이라고 한다.
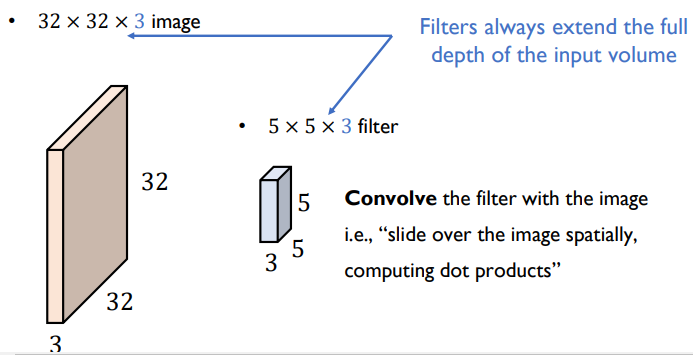
- 하나의 convolution filter는 입력 채널의 수와 같은 채널 개수를 가진 형태로 존재하게 된다.
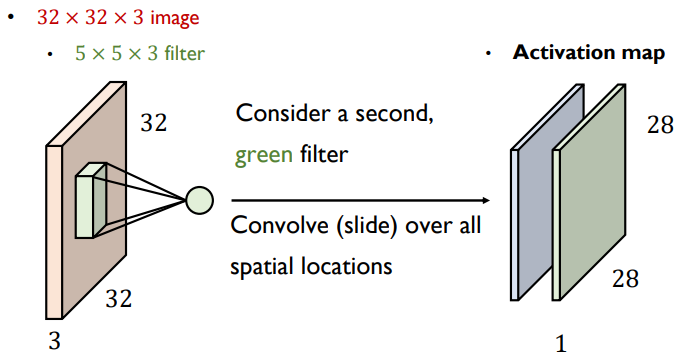
- convolution filter를 특정한 위치에 overlap을 시켜 과정을 진행하면 여러가지 convolution filter에 해당하는 여러 activation map이 나오게 된다.
- 총 output activation map의 채널 수는 filter 개수와 동일한 개수로 나오게 된다.
Pooling layer

- 이미지 패치를 옮겨가며 overlap을 시켜 최대 값을 추출하는 작업을 진행한다.
- 원래 이미지가 특정 size를 가질 때, max pooling을 진행하면 가로, 세로 size를 줄여주지만, 영액 내의 가장 큰 영향을 미친 값을 추출하기 때문에 위치에서의 대략적인 요약 과정을 수행하게 된다.
- 이러한 과정을 각 채널별로 진행하고, 각 activation map에 대해 각자의 max pooling을 진행한 output이 나오게 된다.
ReLU layer
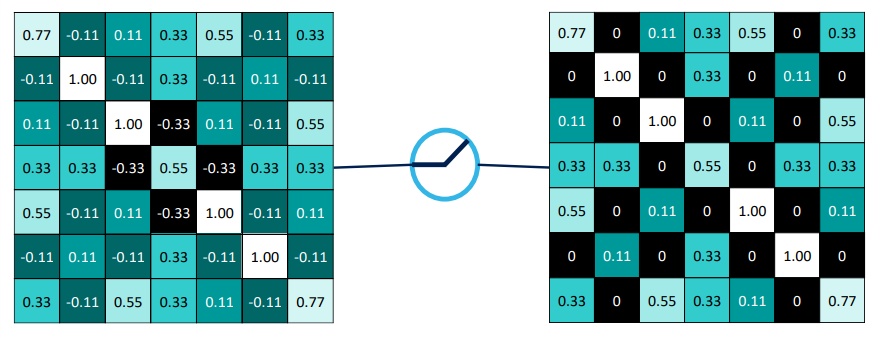
- 선형 연산 이후 activation function을 이용하여 각 값에다 적용을 하게 된다.
- 양수면 해당 값, 음수면 0으로 clipping 해주는 변형된 output activation map을 구할 수 있다.
- 각 원소별로 적용해주기 때문에 동일한 채널 수를 유지한다.
Fully Connected Layer
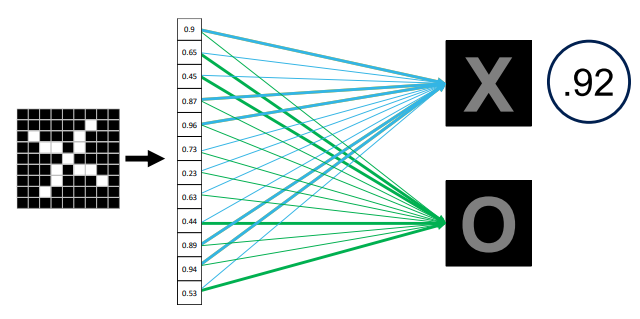
- Conv, ReLU, Pooling을 숫자만큼 반복하여 쌓은 다음, 작은 이미지 size로 변환이 된다면 특정 시점 이후는 한 줄의 vector로 만들게 된다.
- 이러한 vector를 이용하여 학습을 시키고, 가중치 기반으로 계산하여 class 값에 대하여 매칭을 하여 판단을 한다.
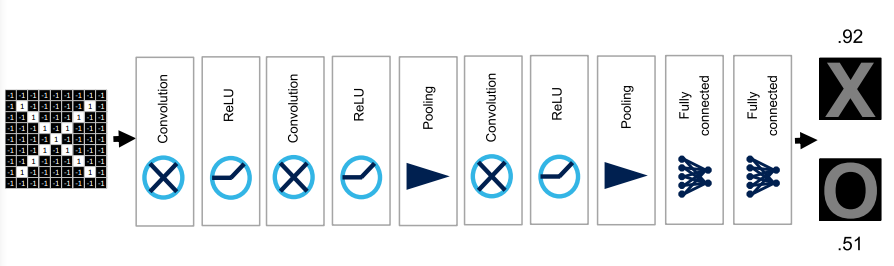
- 이러한 과정을 multi-layer로 진행하고 back propagation을 진행하여 학습을 진행한다.
Hyperparameter
Convolution
- 몇 개의 convolution filter를 사용할 지
- filter의 가로, 세로 size
Pooling
- 이미지에 적용하는 window size
- window stride : 옮겨 가는 칸(pixel)의 수
Fully Connected
- 몇 개의 layer를 쌓을 지
- 한 layer 내에는 몇 개의 뉴런을 사용할 지
VGGNet
- 각각의 convolution layer에서 사용하는 convolution filter의 가로, 세로 size를 무조건 3 by 3으로만 한다.
- 작은 size의 filter로는 제한적인 패턴을 정의할 수 있지만, 한 layer 내에서 더 큰 filter를 썼을 때보다 layer를 깊이 쌓는 방식
ResNet
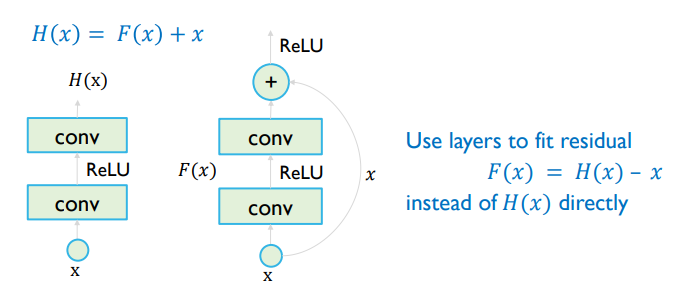
- layer를 더 쌓는 것은 output에 layer를 추가하는 것인데, 이는 순기능을 할 수도 있지만 random initialize부터 순기능을 발휘하는데까지 시간이 오래 걸린다는 단점도 존재한다.
- layer를 필요할 땐 건너뛸 수 있도록 skip connection을 제안한 방식
- 중간 결과물이 있을 때, 중간 결과물에 입력을 함께 더하여 진행하는데, 이 때 skip을 하고 싶다면 를 0에 가까운 값으로 주어 이전 결과물을 거의 그대로 전달하는 방식이다.

안녕하세요 :) Data/AI 공부 중인 한국외대 컴퓨터공학부 조권휘입니다.