[논문 리뷰] Beto, Bentz, Becas: The Surprising Cross-Lingual Effectiveness of BERT
자연어처리 논문 리뷰
preface

1. Introduction
Artetex et al(2018)은 기존의 cross lingual 모델은 단어간의 연결 고리를 직접 만들어서 학습을 진행하였다. 하지만 BERT가 출시 된 이후로는 어느 alignment도 없이, 언어적 연결고리를 직접 만들지 않고도 사전적으로 이해가 가능해졌다. 그리고 zero shot learning과 같이, low resource를 가지는 언어들에 대한 학습도 가능해지면서 cross lingual 분야는 굉장히 인기가 많아졌다.
분야별로도 유명해진 부분들이 많았고, 그중에서 저자는 5개의 Task (NLI, document Classification,NER, POS, dependency parsing)분야에서 조사하였고, 기존의 MBERT보다 더 좋은 성능을 보이고자 하였다. 그리하여, 저자는 파라미터를 수정하거나, 다른 방식으로 feature extraction을 하고, 다른 방식으로 fine tuning을 하고, parameter freezing을 이용하여 등등으로 ,SOTA를 달성할 수 있었다. 게다가 mBERT를 Language ID를 통해 정확도를 측정하여 특정 언어에서 벗어나 일반화를 할 수 있게 되었다. 마지막으로 어떻게 subword tokenzation들이 transfer에 영향을 주었는지를 확인해보았다.
2. BackGround
Cross-lingual Transfer
Cross lingual transfer learning 이란 다른 특정 도메인(언어)를 이용한 transductive한 학습 방법 중 하나이다. 과거에는 lexicalized parser를 이용하지 않고, 조잡한 representation을 통해서 사용이 되었었다. 최근에는 cross lingual word embedding들이 NER,POS, dependency parsing과 같은 task들과 함께 사용이 되고 있다.
Cross - lingual Word Embeddings
cross lingual space를 정의하는데 있어서 zero shot learning은 굉장히 중요하다. Conneau et al(2017)과 Artetxe et al(2018)은 두 개의 단일 언어 임베딩들이 각각 identical string들과의 orthgonal mapping 관계를 통해서 배울 수 있다는 것을 보여주었다.
Contextual Word Embedding
ELMo은 langauge modeling objective와 함께 pretrained이 되었는데 문맥을 판단하는 embedding을 배운다. 이 ELMo는 Word2Vec이나 Glove와 같은 word representation보다 더 좋은 성능을 보였다. GPT와 Howard and Ruder (2018)들은 특정 테스크에 pretrained model의 파라미터들을 fine tuning을 하기도 하였다. 또한 GPT는 Transformer의 Encoder를 사용하여 높은 성능을 보였고, Howard and Ruder (2018)은 each layer들 마다 각각의 learning rate를 사용하거나, gradual freezing 방법을 통해서 다른 fine tuning strategy를 제안하기도 하였다.
Schuster et al(2019)는 ELMo를 다른 언어로 pretrained 하여 orthogonal mapping을 하였고, zero shot learning과 few shot learning을 통해서 높은 성능을 보였다. mBERT랑 비슷하게, Mulcaire et al(2019)는 single ELMo를 학습하여 pretraining의 이점을 보여준다.
Pires et al(2019)는 저자와 비슷하게 NER과 POS Tagging에서 mBERT가 가지는 장점을 보여준다.
3. Multilingual BERT
BERT, Fine tuning BERT, mBERT, Transformer
각 모델은 다른 포스팅에서 확인해보실 수 있습니다.
4. Tasks
mBERT가 각각 언어에 대해서 own embedding space를 만들기 위해서, 5개의 task에 zero transfer learning을 진행하였고, pretraining은 영어로 진행하고, target language로 infer을 진행했다.

각 TASK에 대해서 언어는 위와 같다.
5. Experiments
mBERT를 사용하고, 12개의 attention head, 12개의 transformer block을 이용해서 학습을 진행하였다.
Training
WordPiece를 통해서 subword를 tokenization을 진행하고, Adam을 optimization으로, 이용하였다.
Maximum Subwords Sequence Length
Training time 동안, subword의 길이를 128로 제한하여 학습을 진행하였습니다.. NER와 POS Tagging task에는, sliding window approach를 추가적으로 사용하였습니다. 첫번째 window 이후에는, 마지막 64개의 subwords들을 keep 하였고, evaluation time에, 똑같은 방식으로 접근을 하였습니다. 그래서 140개의 단어를 한계로 설정하였고 실제로 사용을 할때는 140 또는 512를 maximum word로 설정하여 확인하였습니다.
Hyperparameter Search and Model Selection
하이퍼파라미터 서치를 통해서 최적의 값을 선정함.
5.1 Question #1 : Is mBERT Multilingual?
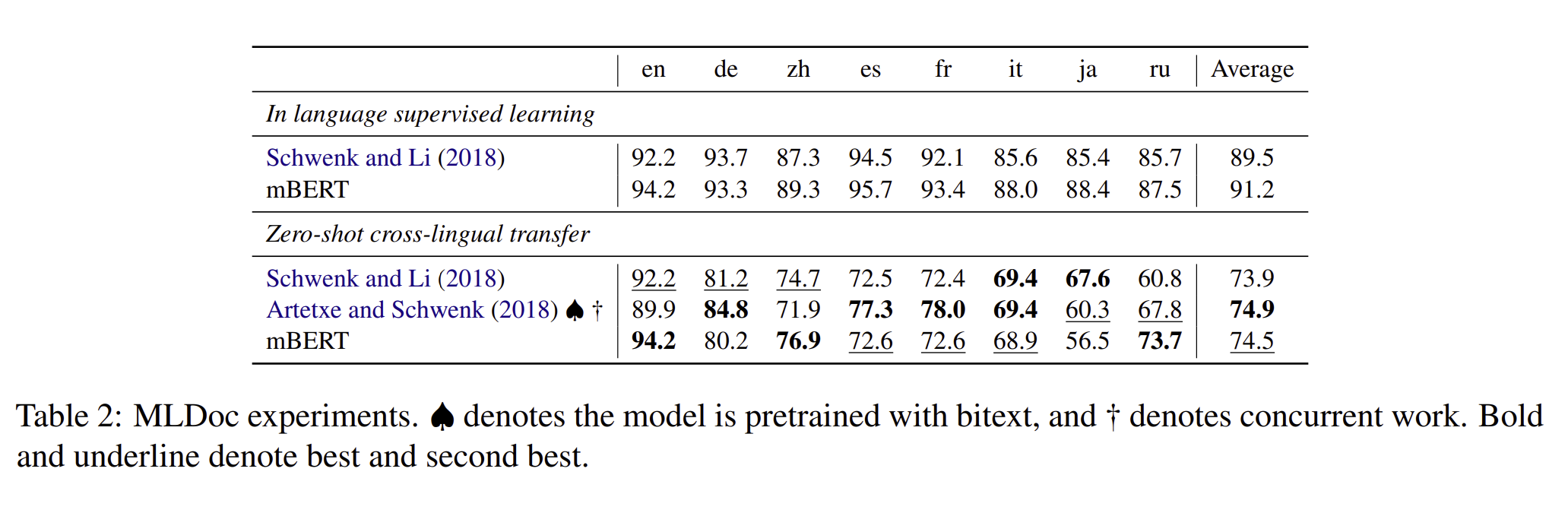
MLDoc
저자는 2개의 강력한 baseline을 기준으로 잡았습니다. Schwenk and Li (2018)은 MultiCCA 데이터셋와 CNN을 통해서 학습을 했습니다. 저자와 비슷하게, Artetxe and Schwenk (2018)은 영어 or 스페인어와 나머지 언어들을 통해서 bitext를 만들고, 이를 가지고 Seq2Seq 방식으로 pretrain을 진행하였습니다.
mBERT는 bitext로 학습을 하지 않아도 이미 성능이 좋았습니다. 흥미롭게도 mBERT는 Artexte and Schwenk(2018)로 진행했던 것 보다 중국어나 러시어와 같이 직접적으로 관련된 언어에 outperform 하였고, 인도나 유럽의 언어와는 under perform 하였습니다.
XNLI
저자는 3개의 baseline을 잡았는데, Artetxe and Schwenk (2018) 과 Lample and Conneau(2019) 방식과 연결되어 진행하였습니다. 일단 MLM 구조는 mBERT랑 너무 유사하였고 오직 차이나는 것이 mBERT보다 40퍼센트나 더 많은 언어를 가졌다는 점이다. 그리고 MLM + TLM은 bitext를 쓴다는 점?
Conneau et al(2018)은 LSTM Encoder와 max - pooling을 이용하여 supervised learning을 하였고, 영어 encoder와 classifier을 학습해서, target언어가 얼마나 영어를 잘 따르는 지를 확인하였습니다. ****
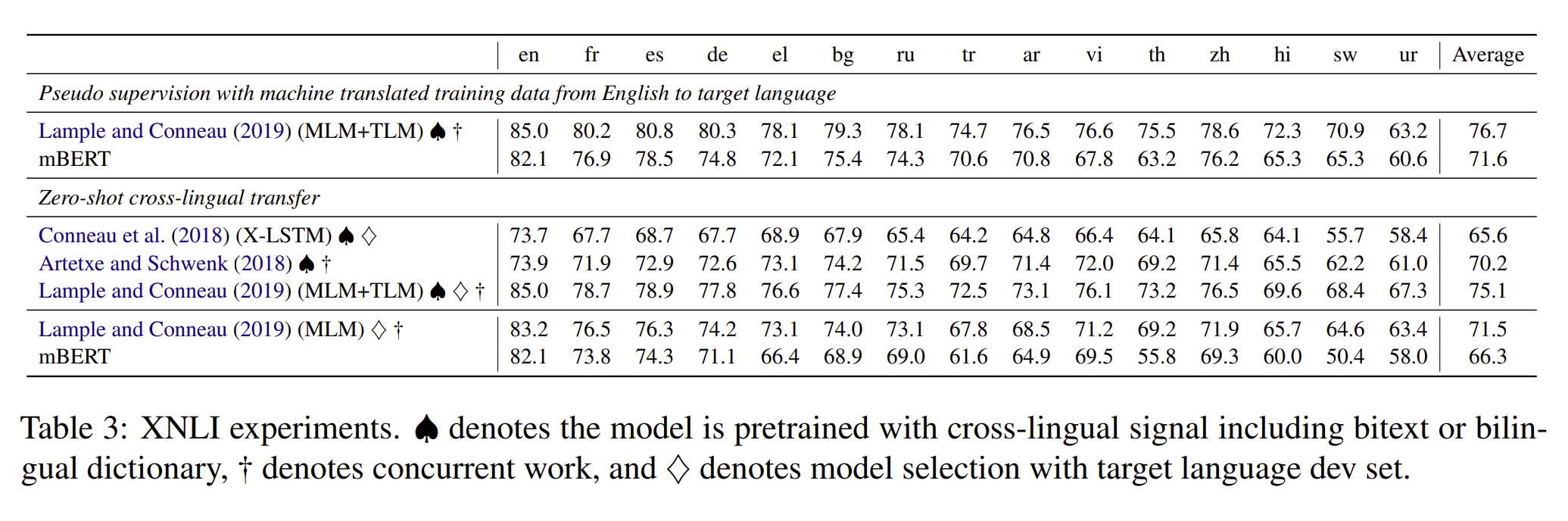
XNLI에서도 mBERT는 한 모델에서만 outperform 하였고 나머지는 그다지 높은 성능을 내지 못하였다. MLM과 mBERT와의 공통점은 training language와 관련없이 거의 똑같다는 점이 있는데 mBERT보다는 MLM이 더 높은 성능을 내고 있다는 것을 알 수 있다. 그리하여 저자는 pretraining을 하는 언어를 제한하는 것이 더 효율적이라고 생각하였다.
NER
zero shot learning의 기본 base로 Xie et al(2018)을 사용하였다. 이 방식은 unsupervised embedding을 사용하였고, LSTM과 self attention, CRF를 통해서 hybrid로 진행이 되었다. mBERT는 baseline 보다 더 높은 성능을 보였고, 이 차이는 supervised learning과 관련된 언어들에 한해서 엄청난 차이가 났다.
POS
저자는 Kim et al(2017)을 사용하였다. 그들은 영어 supervision뿐만 아니라 target language의 supervision을 만들어서 활용을 하였고, 결과는 그래서 비슷하지 않았습니다.
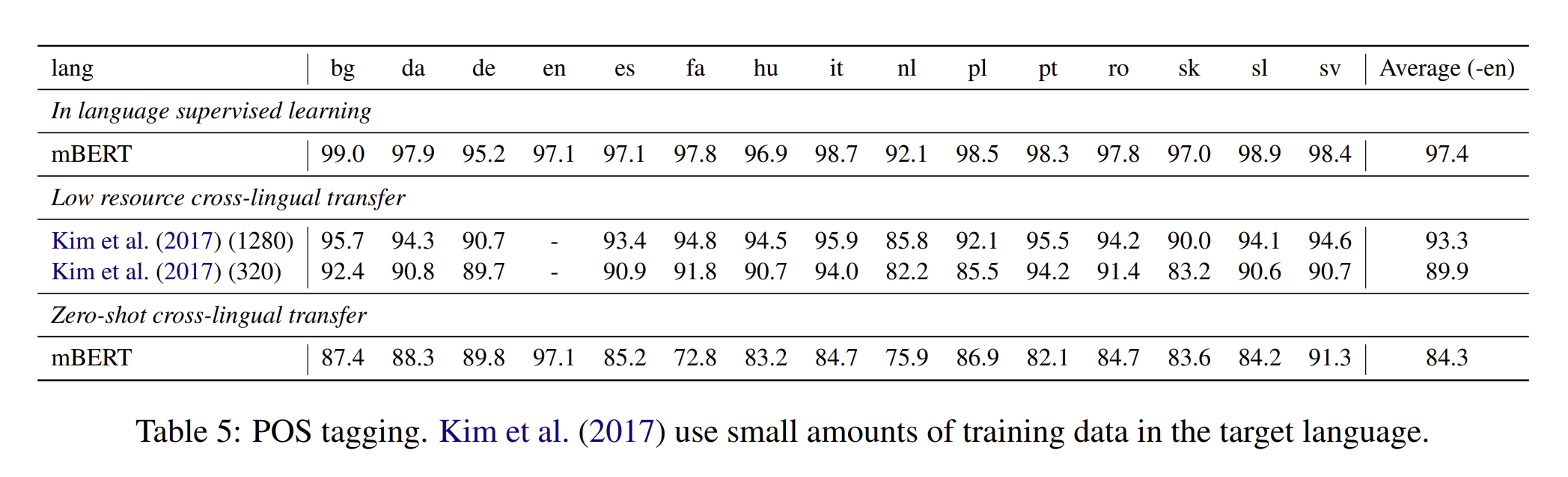
누가봐도 mBERT가 더 성능이 높다는 것을 알 수 있었습니다.
Dependency Parsing
이 task에서는 Ahmad et al (2019)를 활용하였습니다. 이는 Transformer encoder를 graph based parser를 활용하였습니다. 저자는 2개의 mBERT 버전을 고민을 하였는데 gold pos tag가 있는지 없는지를 방식으로 나눴습니다. tagging이 가능할 때는, tagging embedding에 mBERT output을 붙혀서 진행을 했습니다.
Summary
5개의 task를 확인해보면서, mBERT는 zero shot cross-lingual performace에서 굉장히 높은 성능을 보였습니다. target language supervision의 적은 양과 cross lingual signal이 있으면, mBERT는 아마 더 좋아질 것입니다.
5.2 Question #2 : Does mBERT vary layer - wise?
ELMo 논문에서는 각각의 layer 들이 확인할 수 있는 분야가 다르다고 했다. 예를 들어, 어느 layer는 syntax에 강조하는 반면, 다른 layer는 semantics 등을 강조하는 것이다. 그러나 cross lingual 에서는 각각의 layer들이 어떻게 다른지를 모르기 때문에, 저자는 13개의 layer를 통해서 2가지의 scheme을 세웠다.
먼저, 2개의 LSTM을 통해 weighted combination을 만들어서, ELMo의 방식을 따르는 것이다. Adam과 1e-3의 learning rate, 32의 batch_size를 통해서 학습을 진행하였다.
두 번째로는, mBERT를 fine tuning 할 때, 0,3,6,9 번째의 bottom layer들을 고정하였다
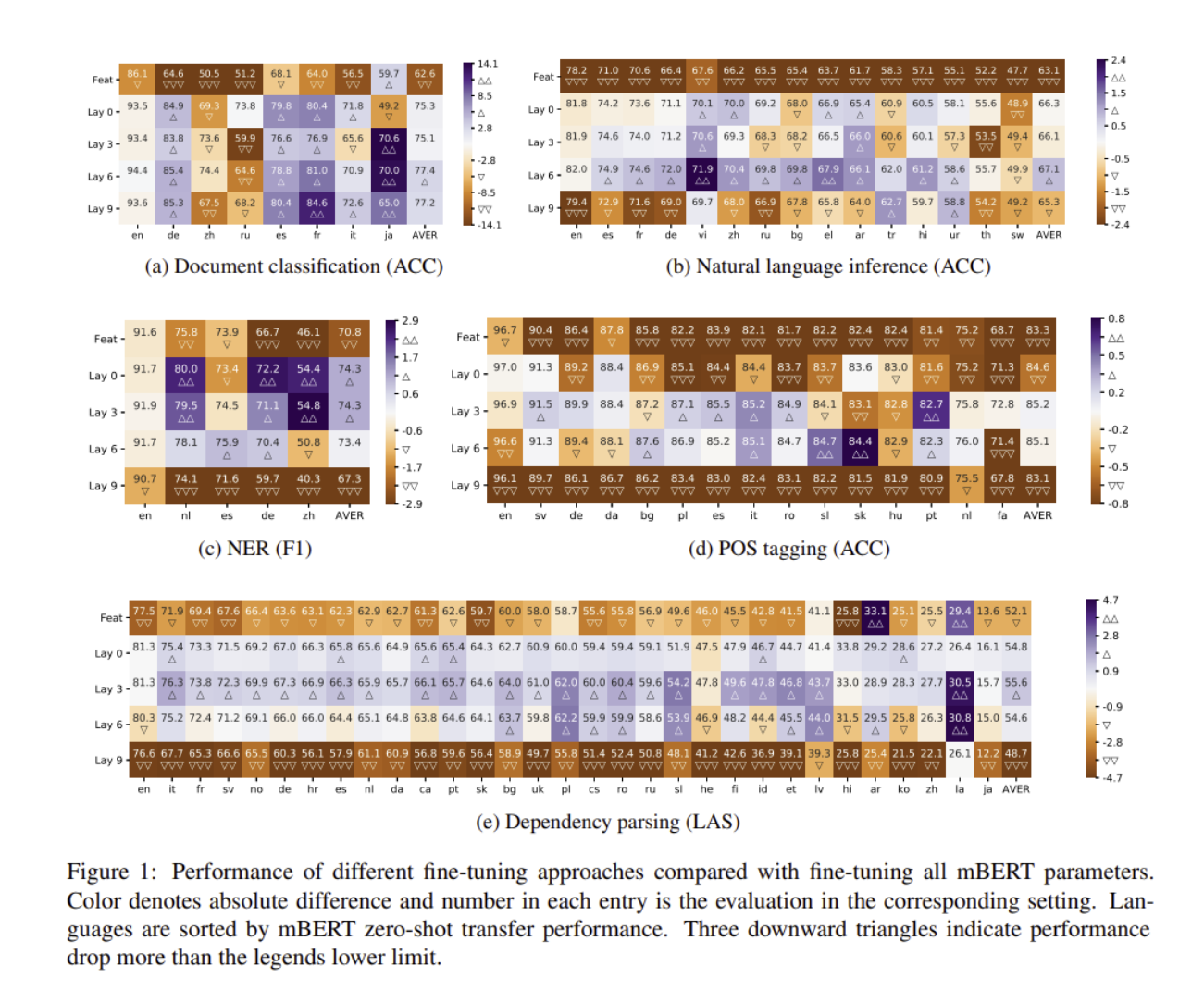
결과를 보면, freezing 한 layer 들의 성능이 높다는 것을 확인할 수 있다. 위의 사진을 통해서 , sentence - level tasks들은 6번째의 layer에서, NER,POS tagging and parsing에서는 3번째 layer에서 높은 성능을 보였다.
LSTM으로 feature-based approach했던 방식은 fine tuning 했던 방식을 under perform까지 시키게 되었고, 그리하여 저자는 많은 언어 모델로 학습을 해놓았던 것은 이기기 힘들다고 하였다. 추가적으로 LSTM도 하나의 문제점이라, dependency parsing에서, LSTM encoder는 당연히 Transformer Encoder를 이기지 못하였다.
정리하자면, layer들마다 각각의 성질이 있는데 이것이 task를 통해 나눴을 때 잘 보인다는 것이다.
5.3 Question #3 : Does mBERT retain language specific information?
mBERT는 과연 언어의 specific information을 잊을까 라는 질문인데, 저자는 두 언어의 차이를 배우지 않기 때문에 이 두 언어를 구분하는 법을 잊었을 것이라고 한다. classifier를 만들어서 test를 진행해보니 정확도가 96퍼센트 이상이라고 한다. 그리하여 이는 각 layer들이 language의 specific 한 정보를 들고 있음을 보여준다.

5.4 Question #4 : Does mBERT benefit by sharing subwords across language?
mBERT는 가까운 언어의 subwords들을 공유한다. 만약에 fine tuning 하는 과정에서, target language의 subword가 training data에도 등장을 한다면, supervision은 target language를 정확하게 확인을 못할 것입니다. 그러나 deep network와 같이 깊은 차원의 해석하지 못하는 방법으로 된 subwords들은 sourcel language에 overfitting을 해서, transfer performance에 큰 영향을 줄 것입니다. 이러한 실험들에서, 저자는 cross lingual들이 어떻게 subwords들을 공유하는지에 대해서 정리를 하였습니다.
예를 들어서, 을 English training set에서 모든 subwords라고 가정을 하고, 을 language 의 subwords들이라고 하고, 을 subwords 가 language가 l인 test set에 얼마나 들어가 있는지를 계산한 것이다. 그래서 각 percentage를 계산하고, 이를 token-level로 정리하여서 계산을 하였다.
로 비율을 만들어서 계산을 하였습니다.
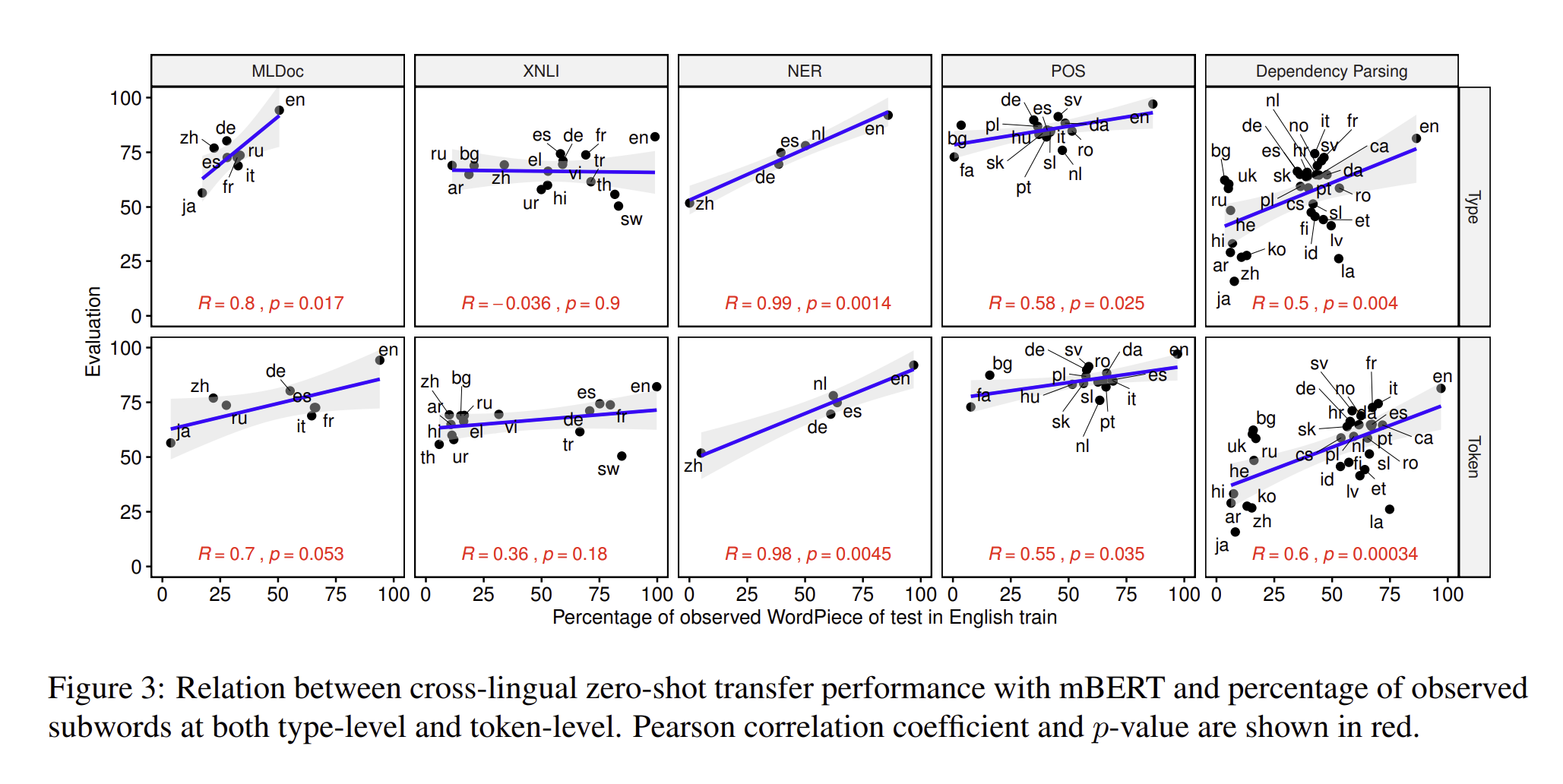
5개의 task 중 4개의 task에서는, 강력한 양의 상관관계를 확인할 수 있었습니다. 인도-유럽 언어 사이에서, 은 50~75퍼나 관찰되었으나, 은 50퍼센트 이하로 관찰되었습니다. 이러한 점은 subwords들이 매우 높은 빈도를 가지고 있다는 점입니다.
정리를 해보자면, 영어를 train data로, 영어랑 비슷한 subword를 공유하는 언어를 test 셋으로 하였을 때, 두 개의 비율을 점점 늘려보면, Evaluation 값이 증가한다는 것으로 해석이 가능하며, 이는 둘 간의 양의 상관관계가 있다는 것을 의미합니다.
한 줄로 정리하면
mBERT를 freezing을 하고, subwords를 공유하는 언어들로 학습을 시키는 것이 mBERT의 기본 성능을 더 높일 수 있는 방법이다.
