[논문 리뷰] BART - Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension
자연어처리 논문 리뷰
Preface

Self supervised learning이란?
일반적인 supervised learning과 unsupervised learning의 중간 단계라고 볼 수 있습니다. 학습 방식은 기존의 train data의 일부를 test data로 사용합니다. 그렇데 되면 일부를 누락시킨 다음에, 이를 맞추는 방식으로 학습이 되기 때문에 test data를 따로 준비할 필요가 없습니다.
Denosing Autoencoder 이란?
기존의 train data에 일부러 noise를 추가합니다. 여기서 noise를 추가하는 방식은 무작위로 일부 데이터를 삭제하거나 변형하는 방식입니다. 그래서 noise가 추가된 data는 encoder와 decoder를 거치면서 noise가 추가 되기 전의 형태로 가는 것을 목표로 합니다.
1. Introduction
논문은 Self-supervised learning이 굉장히 높은 성공을 이루었다고 합니다. 대표적으로 Mask된 방식인 denosing autoencoder입니다. 하지만 이와 같은 방식은 특정 마지막 task를 목적으로 하고, 이는 모델의 능력을 제한하기만 합니다.
그리하여 저자는 BART (Bidirectional and Auto-Regressive Transformer)를 제안합니다. BART는 denosing autoencoder로 지어진 seq2seq 모델입니다.
Pretraining은 2가지 방식으로 진행됩니다.
- arbitrary noising function을 이용하여 text를 누락시키기.
- seq2seq 모델은 original text를 다시 만드는 방식으로 학습되기.
BART 모델은 기본적인 Transformer 모델을 사용한 것으로, BERT와 GPT를 일반화 시킨 모델로도 볼 수 있습니다. BART는 noising flextibility를 가지는데, 이는 nosing을 통해 train data를 랜덤화해서 기존의 문장의 순서를 바꾸고, 새로운 구조의 데이터를 사용하여 학습하는 것입니다. 이러한 방식은 마치 BERT의 MLM과 비슷하다고 볼 수 있습니다.
BART는 Roberta와 같이 GLUE나 sQuAD와 같은 데이터셋을 사용했을 때도 굉장히 높은 성능이 나왔으며, 새로운 fine tuning 방식도 제안하였습니다. Transformer 모델을 추가적으로 사용해서, 외국어를 noise 된 영어로 번역하게 하는 것입니다. 이는 WMT 데이터에서 1.1이나 높은 BLEU 스코어를 보여줍니다.
2. Model
2.1 Architecture
BART는 Transformer 아키텍쳐에 기본적인 Seq2Seq를 사용한 것입니다. 저자는 6개의 encoder와 decoder를 사용하였고, 각각 12개의 layer를 사용했습니다. 이는 마치 BERT 구조와 굉장히 유사한데, 차이점은
- 각 decoder의 layer들은 encoder의 마지막 hidden layer를 사용해서 cross attention 을 수행한다는 것
- BERT는 word prediction 하기 이전에, feed forward network를 사용하지만, BART는 아님.
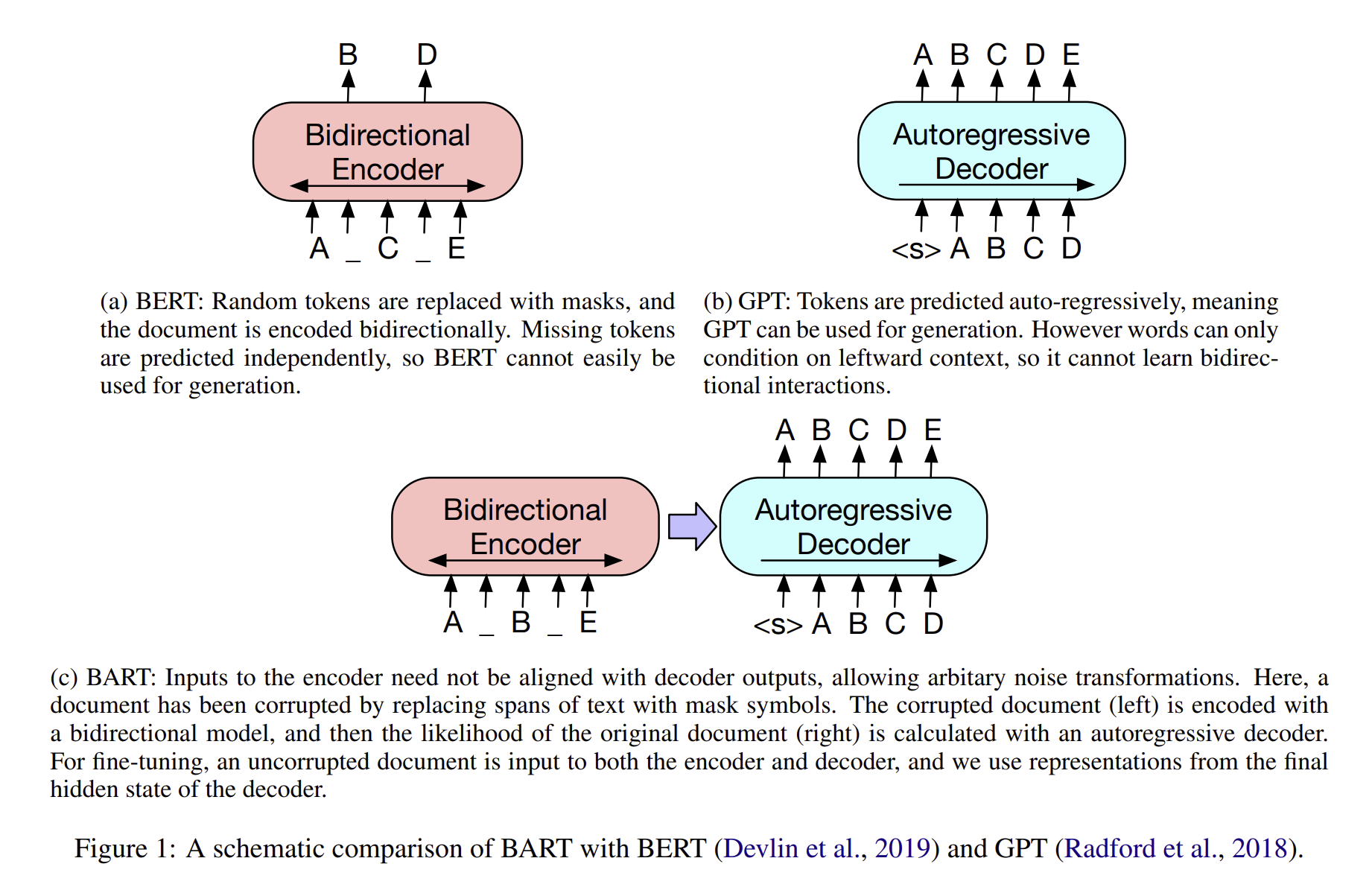
2.2 Pre-training BART
BART는 데이터를 누락시키고, 이를 다시 만드는 방법으로 학습을 진행합니다. decoder의 output과 기존의 데이터를 cross entropy하는 방식을 사용합니다. BART는 기존의 denoising autoencoder들과는 다르게, 데이터 타입에 상관없이 누락을 시켜서 학습을 하게 되는데, 만약에 모든 데이터를 누락시키면, 이는 하나의 언어 모델과도 같다고 할 수 있습니다.
저자는 새로운 구조를 제안하였습니다.
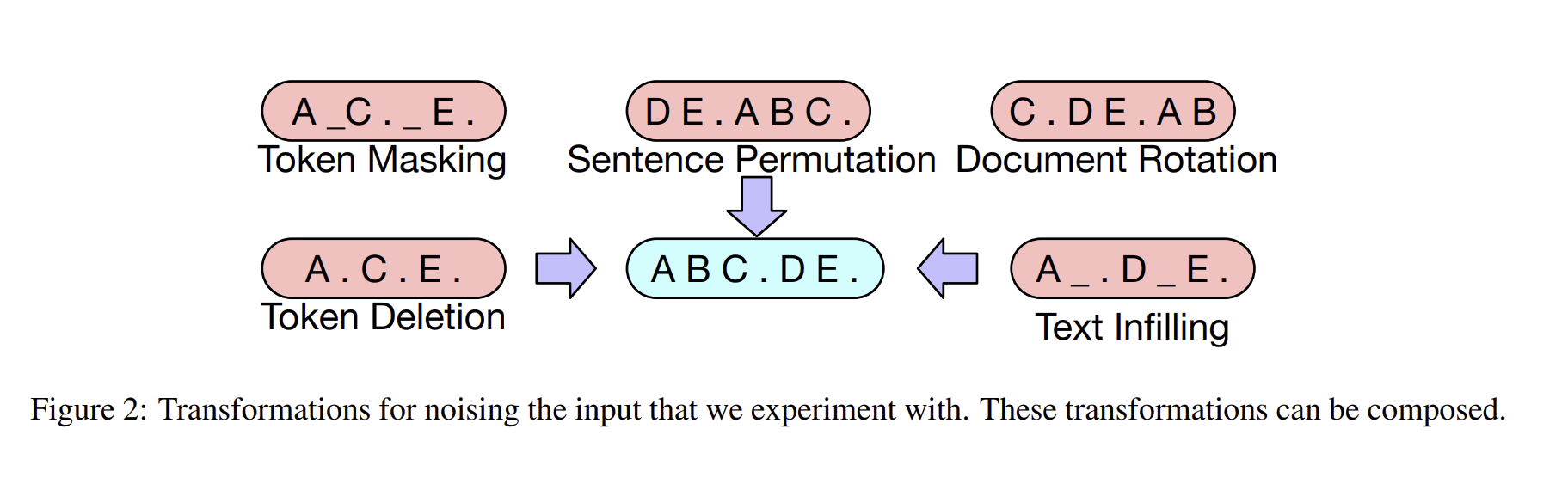
- Token Masking
- BERT와 비슷하게, random tokens들을 sampled 하고, MASK로 replace 하는 방식입니다.
- Token Deletion
- random 한 토큰들은 input에서 삭제가 되고, token masking과는 다르게, 모델들은 어느 poisition이 input position인지도 맞춰야 합니다.
- Text Infilling
- text span들이 포아송 분포를 따라 sampling 되고 각 span들은 single MASK 토큰들로 변형이 됩니다.
- Text infilling 방식은 모델들이 얼마나 많은 토큰들이 span으로 부터 없어졌는지를 알려주는 방법입니다.
- Sentence Permutaiton
- document들이 sentence로 나뉘는데, random order로 섞힘.
- Document Rotation
- 토큰들은 uniformly 하게 선택이 되고, document들은 token들과 함께 섞입니다. 그래서 이 과정은 모델들이 document의 start를 알게 해주는 테스크입니다.
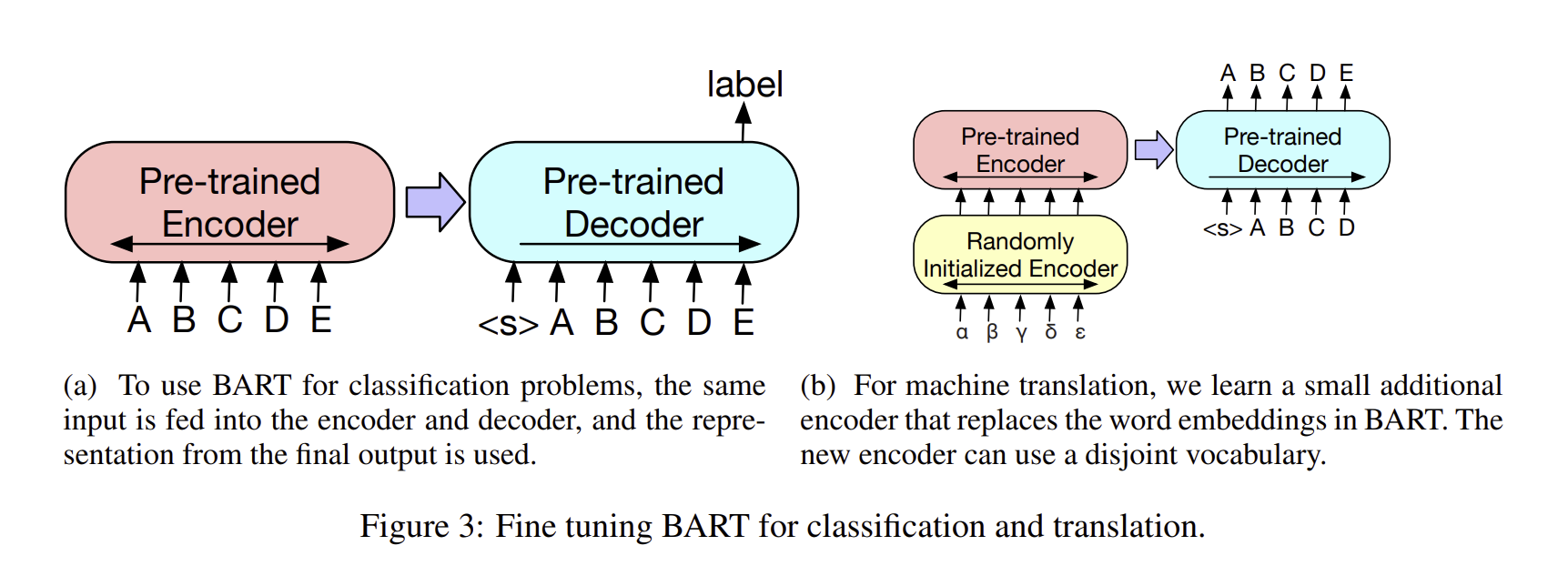
3. Fine-tuning BART
3.1 Sequence Classification Tasks
문장을 분류하는 task에서, same input들은 encoder와 decoder로 들어가고, final hidden state로 나오게 되면, 이는 multi classi linear classifier로 들어가게 됩니다. 이는 BERT의 CLS 구조와 비슷할 수도 있지만, 추가적으로 end 토큰을 추가하여 학습합니다.
3.2 Token Classification Tasks
answer endpoint classifcation과 같이, 저자는 encoder와 decoder에 완벽한 document들을 학습하는데 사용하였고, decoder의 hidden state를 각 단어의 representation으로 사용하였습니다.
3.3 Sequence Generation Tasks
BART가 autoregressive 한 decoder이기 때문에, abstractive question answering 이나 summarization과 같은 sequence generation tasks에 fine tuning 될 수 있습니다.
이러한 task들에는, input으로 부터 데이터를 복사하고, 이를 denosing pretraing objective와 최대한 비슷하게 수정을 합니다. 여기서 encoder input은 input sequence이고, decoder는 output을 autoregressively하게 만들어냅니다.
3.4 Machine Translation
저자는 또한 BART는 MT로 사용하였습니다. 기존에는 Encoder만을 pretrained 하여 사용하였고, decoder는 pretrained를 하지 못하고 limitation이 있었습니다. 이와 다르게 저자는 entire BART model을 single pretrained decoder로써 사용하여 machine translation을 진행하였습니다.
저자는 BART의 Encoder embedding layer를 가중치가 새롭게 저장된 encoder로 변경을 하였고, 이 모델은 end - to -end 방식으로 외국어 단어를 BART가 영어로 'noise corruption' 처리할 수 있는 입력으로 변환하는 역할을 합니다. 새로운 encoder들은 기존의 BART 모델에서 vocab을 사용할 수 있습니다.
저자는 2가지 step으로 학습을 진행하였고, 두 방법 전부 BART의 output을 이용해서 역전파를 통해 학습을 진행하였습니다.
- 첫번째로, 모든 BART의 parameter들을 고정을 하고, 오직 encoder의 시작 부분의 파라미터만 랜덤화를 진행했습니다.(BART의 positional embeddings,과 encoder first layer의 self attention 구조)
- 모든 파라미터를 최대한 적은 수의 iteration으로 학습을 했습니다.
4. Comparing Pre-training Objectives
4.1 Comparision Objectives
많은 pretraining 모델들이 제안되었지만, 이를 공평하게 비교하는 것은 사실상 힘듭니다. training data, training resource, 아키텍쳐의 차이, fine tuning procedures 등의 차이로 비교를 하는 건 힘듭니다. 저자는 기존에 존재하는 여러 모델들과 최대한 비슷한 구조로 만들어서 비교를 진행했습니다.
Language Model
GPT와 비슷하게, left-to-right Transformer language model로 학습을 진행했고, BART의 decoder와 똑같았습니다.
Permuted Language Model
XLNet을 기반으로 하여, 1/6 개의 토큰들을 샘플링하고, 그들은 autoregressively 하게 random order들을 만들었습니다.
Masked Language Model
BERT와 똑같이, 15퍼센트의 토큰들을 MASK화 시키고 독립적으로 학습을 진행하였습니다.
Multitask Maksed Language Model
UniLM과 비슷하게, Masked Language Model을 학습시켰습니다. self attention masks는 1/6 확률로 왼쪽에서 오른쪽, 오른쪽에서 왼쪽, 1/3은 masked, 나머지 1/3의 50퍼는 unmasked 토큰 그리고 왼쪽에서 오른쪽으로 하는 remainder를 위한 마스크 구조
Maksed seq2seq
MASS에 영감을 받아서, token의 50퍼센트들을 포함하는 span을 mask 하고, seq2seq 모델로 학습을 하였습니다.
Permuted LM, Masked LM, Multitask Masked LM 방식같이, 저자는 2개의 two stream attention을 이용하여서 ouput의 likelihood들을 효율적으로 계산하였습니다.
- 먼저 task를 기본적인 seq2seq 문제로 보고
- decoder에 있는 target에 prefix를 추가하여 target part의 sequence에만 loss를 넣는 것입니다.
4.2 Tasks
데이터 설명으로 생략
4.3 Results
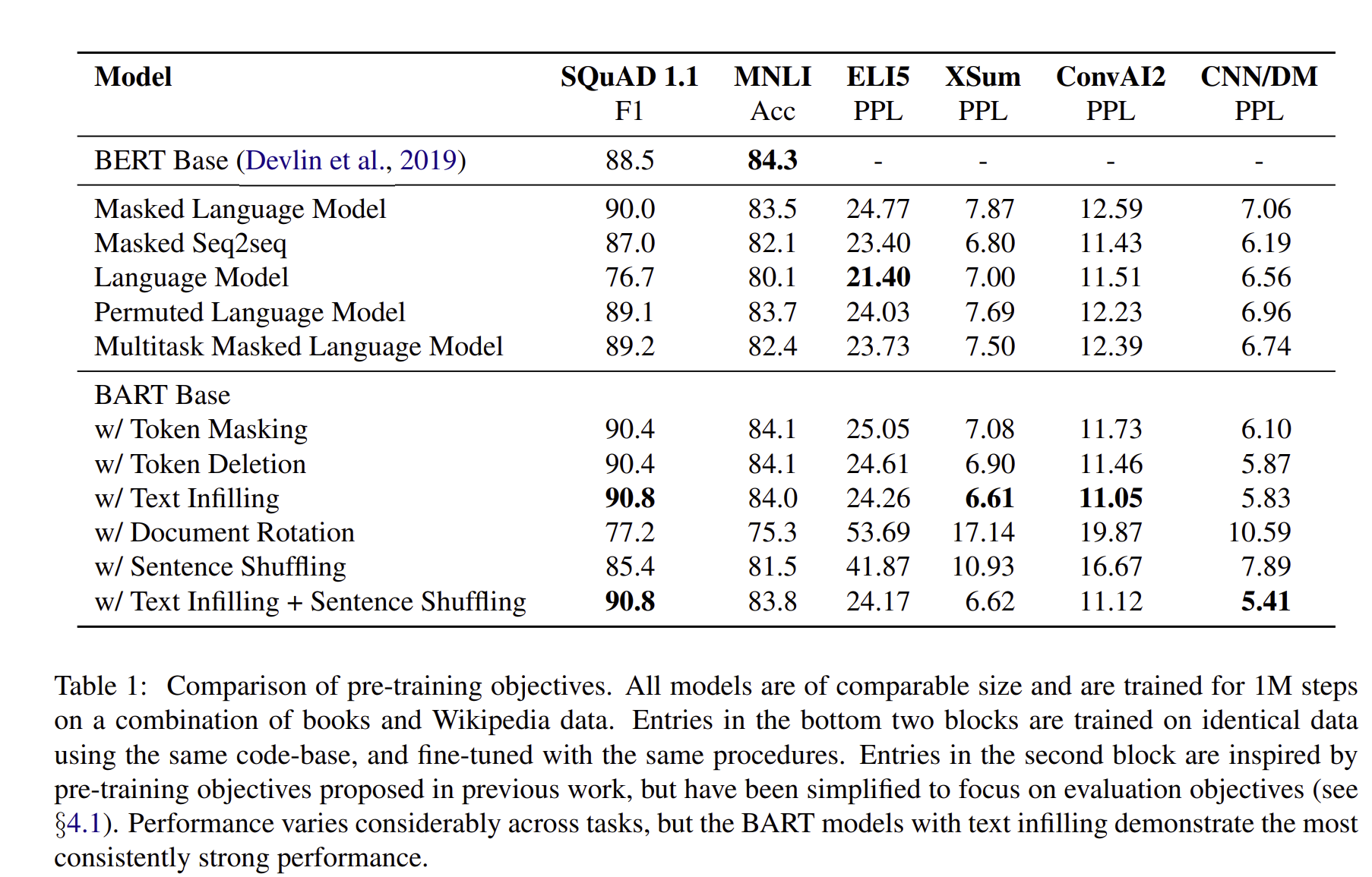
Performance of pre-training methods varies signifi-cantly across tasks
pretraining의 효율은 task에 따라 다릅니다. 예를 들어서, simple language model은 ELI5에서 좋은 성능을 얻을 수 있지만, SQUAD 에서는 최악의 결과를 받았습니다.
Token masking is crucial
Pre-training objectives based on rotating document와 permutaing sentence는 낮은 점수를 받았지만, token deletion과 masking, self attention masks에는 성공적인 결과를 보여주었습니다.
Left to right pre-training improves generation
MLM과 PLM 모델들은 일반적인 것보다 낮은 성능입니다.
Bidirectional encoders are crucial for sQuAD
left to right decoder는 sQuAD 데이터에서는 굉장히 낮은 점수를 받았습니다. 이는 future context는 classification decision에 굉장히 중요하기 때문입니다. 그러나 BART는 bidirectional layer를 오직 절반만 썼는데 비슷한 performance를 받게 되었습니다.
The pre-training objective is not the only important factor
Permutated 모델은 XLNet 보다는 성능이 좋지 못했습니다. 이는 relative position embeddings나 segment - level recurrence와 같은 모델 아키텍처를 향상시키지 않았기 때문입니다.
Pure language models perform best on ELI5
ELI5 데이터셋은 다른 테스크에 비해서 더 높은 perflex를 가지고 있고, 다른 모델들이 유일하게 BART를 이길 수 있는 것입니다. 이는 즉, BART는 output이 약하게 제한되어 있을때, 덜 효율적이라는 것을 보입니다.
BART achieves the most consistently strong performance
ELI5 데이터셋을 제외하고는, BART 모델은 모든 테스크에서 좋은 성적을 보입니다.
5. Large - scale Pre-training Experiments
Pretrained을 하고 모델을 학습하면 굉장히 높은 성능을 보여서 저자는 Roberta와 똑같은 방식으로 BART를 학습시켜서 실험해보았습니다.
5.1 Experimental Setup
각각의 decoder와 encoder에 12개의 layer를 만들고, hidden size는 1024로 설정하였다. GPT2와 같이 BPE를 설정하여 tokenization을 진행하고, text infilling과 sentence permutation를 사용하였으며, 각 document에 30퍼센트로 mask를 진행하였다. sentence permutation은 CNN/DM 요약 데이터셋에서만 좋은 성능을 보였지만, 저자는 더 많은 데이터셋이 더 높은 성능을 이끌 것이라고 믿었기에, 마지막 step의 training step의 10퍼센트에 넣어 dropout을 못하게 하였습니다.
5.2 Discriminative Tasks
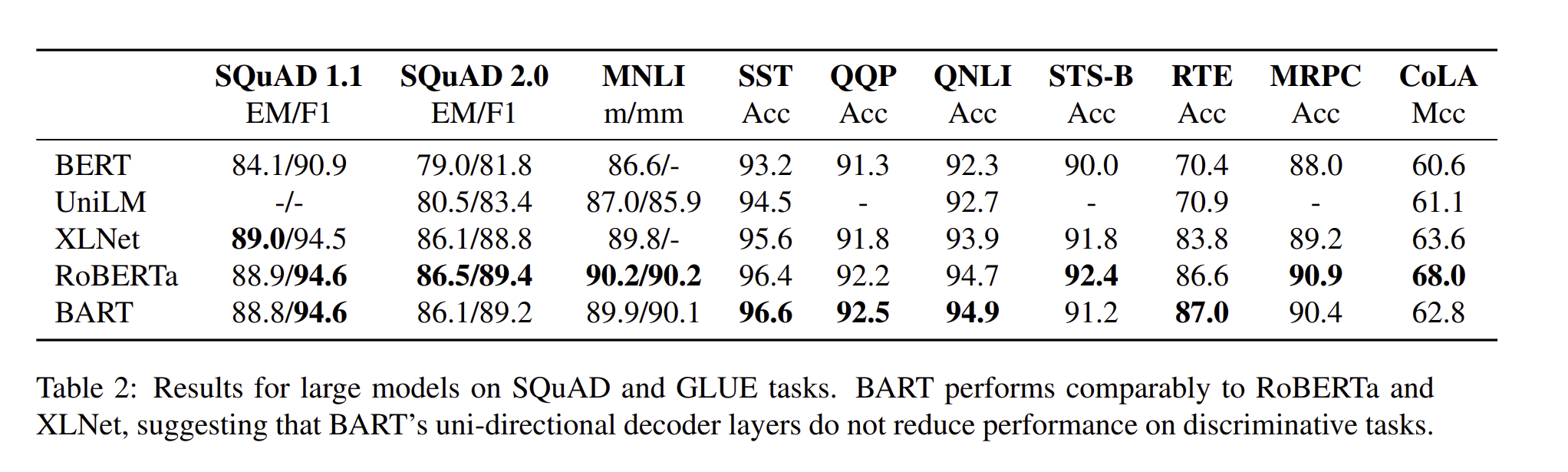
RoBERTa랑 굉장히 비슷한 성능을 보이고, 다른 면에서는 BART 성능이 더 좋음.
5.3 Generation Tasks
Summarization과 Dialogue, Abstractive QA 에서 BART가 다른 모델들에 비해서 높은 성능을 보인다는 것을 확인할 수 있습니다.
5.4 Translation

또한 WMT 16 데이터셋으로 높은 퍼포먼스를 보였습니다. 6 layer의 encoder를 사용하고, BART가 영어 단어를 noise 하며, Romanian 언어를 잘 번역하기 위해 만들어졌습니다.
결과는 위 그림과 같습니다.
6. Qualitative Analysis

이는 BART 모델을 가지고 Summarization을 진행한 결과로, Wikipedia article을 가져와서 학습을 진행했습니다. 결과가 종종 input data를 그대로 복사하는 경우도 있고, background를 통해서 대답하는 경우도 있었습니다.
Conclusion
BART는 기존의 document를 corruption 하여 이 부분을 원래대로 매꾸기 위한 방식으로 학습을 진행하였습니다.
한 마디로 요약하면?
BART는 Transformer의 Encoder와 Decoder를 사용하고, Denosing Autoencoder로 원래 데이터에 noise를 넣고 이를 다시 원상복구 하는 방식으로 학습을 진행한 Seq2Seq 모델입니다.
