preface

motivation
2019년 당시 머신러닝 학습은 엄청난 데이터셋과 supervised learning을 통해 진행되었습니다.. 그러나 이러한 구조는 다루기 힘들고, 약간의 변화에도 민감하다 보니 이를 일반화할 수는 없을까? 라는 생각에서 GPT2 논문이 나오게 되었습니다.
1. Introduction
ML 시스템을 만드는 가장 기본적인 방식은 적합한 데이터셋을 모으는 것, 이러한 행동들을 모방하게 할 수 있게 하는 것, 독립적으로 이에 대한 퍼포먼스를 실험해보는 것입니다. 하지만 당시에는 captioning models, reading comprehension systems , iamge classifiers 등 특정한 테스크에 적합한 방식만을 연구하다 보니 일반화시키는 것이 어렵습니다.
그리하여 저자는 한 테스크에 적합한 single domain datasets은 일반화 능력을 떨어뜨리기에, 여러 분야에 사용할 수 있는 데이터셋이 필요하고, 이것이 최근에는 GLUE나 decaNLP로 나오게 됩니다.
저자가 핵심적으로 말하고 싶은 파트는 Multitask learning 입니다. Multitask learning은 ML 분야에서는 유명하지만 NLP에서는 그렇게 유명하지 않습니다. 그리하여 Multitask learning을 NLP 분야에 도입해서 일반화의 문제를 해결해보려고 합니다.
매번 supervised learning으로 인해서 돈과 시간을 뺏기는 것이 아니라 한 번 학습한 것으로 모든 task를 해결할 수 있다면 얼마나 좋을까? 라는 생각으로 zero shot learning을 통해 down stream task에 적용을 합니다.
2. Approach
이런 테스크에 적용할 수 있는 방식은 langauge modeling입니다. language modeling은 unsupervised learning 학습 방식을 사용하고, 이전의 값들을 가지고 가장 높은 확률이 나오게 만드는 구조를 만드는 것입니다.
위에 처럼, 1부터 까지의 값이 나왔을 때, 이 나올 확률을 가장 크게 만드는 것입니다. Transformer의 self attention과 같은 구조에서, 엄청난 performance를 보여주었습니다.
single task에 대한 학습 확률은 이와 같이 작성할 수 있지만, 일반화를 하면 으로 작성할 수 있습니다. large language model의 목적은 결국 supervised learning의 목적과 같기에, 목적들 각각의 최솟값은 같다고 할 수 있습니다. 다만 y label의 데이터가 없기에 학습속도가 느린 것은 어쩔 수 없지만, 결국엔 학습에 넣는 X 데이터는 엄청나게 많기 때문에 이 데이터들을 통해서 다양한 테스크에 적용해볼 수 있다는 것이 이 본문의 핵심이다.
2.1 Training Dataset

기존에는 데이터셋을 특정 테스크에 맞춰서 학습을 하지만, 이제는 큰 데이터셋을 모아 학습에 활용하려고 합니다. 그래서 GPT2 논문에서 활용한 방법은 Common Crawl와 같은 web scrapes 방법입니다. Common Crawl 방식은 사실 Trinnh & Le 논문에서 데이터셋에 대해서 좋지 않은 평가를 내놓았지만, 위 논문에서는 다른 방식으로 데이터를 수집하였다고 합니다. Trinnh & Le 에서는 document 에서 target dataset과 비슷한 방식으로만 데이터를 모았지만 데이터셋이 별로 안좋았고, 그리하여 GPT 논문에서는 사람에 의해서 데이터셋을 거르려고 했습니다. 그 방법도 비용 지출이 높기에 레딧과 같은 커뮤니티에서 적어도 3개의 별 이상만 받은 데이터를 사용하였습니다.
그리하여 데이터셋은 45기가 이상의 데이터만 모이게 되었고, HTML 전처리를 진행하여 40기가만 남게 되었습니다.
위의 사진을 보게 되면, 데이터셋에 downstream task에 해당되는 번역이나 요약 등의 문장들이 존재합니다. 이는 pretraining 이후, 따로 fine tuning을 하지 않고, prompt만 추가를 하게 되면 학습이 되는 구조임을 보여주는 것입니다.
2.2 Input Representation
기존의 LM 모델은 확률을 계산해야 되고, pre processing과 같은 lower casing, tokenization, out of vocab과 같은 작업을 진행해야 됩니다. 하지만 최근의 byte level LM과 같은 것들은 large scale의 dataset과는 맞지 않은 word level을 가지고 있습니다. 그리하여 GPT2 논문에서는 BPE 방식을 이용하여 데이터를 처리하고 시작합니다.
BPE 방식은 반복되어 나온 단어들을 처리하기 쉽게 해주고, 특성을 살리기 좋습니다. 논문에서 언급하는 BPE 방식은 모든 유니코드를 사용하여 13만개 이상의 사전을 만들어내는데, 이는 기존의 BPE과는 차이가 있습니다. 기존의 BPE 방식은 3.2만개에서 6.4만개의 토큰 어휘를 사용하는데 이 보다 엄청 큰 어휘를 사용하게 되는 것입니다. 그리하여 GPT2 논문에서는 바이트 수준의 BPE를 활용하여 256개만을 가지고 사용하고, 공백에 대한 예외를 추가해서 높은 word representation의 방식을 보여주게 됩니다.
2.3 Model
기반이 되는 구조는 Transformer로 사용이 되었고, Layer normalization은 input 구조로 움직이고, additional layer normalization도 또한 마지막 attention block에 추가가 되었다. context size는 512에서 1024로 확장을 하여 학습을 하였다.
3. Experiments
저자는 여러 benchmark를 4개의 LM 구조에 학습을 시켰고 결과는 아래와 같다.
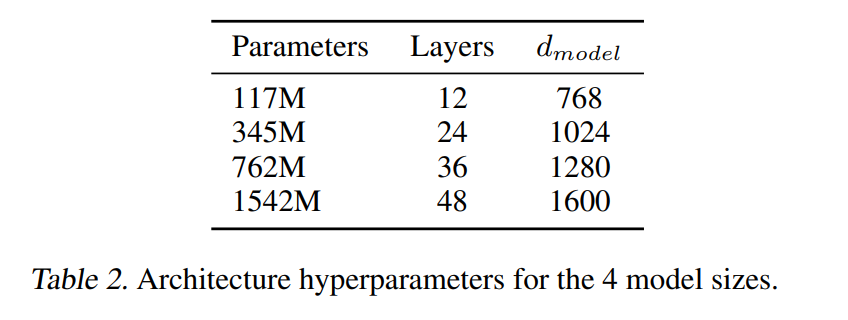
3.1 Language Modeling
먼저 zero shot learning에서 WebText’LM이 어떻게 transfer 되는지에 대한 과정을 알아내는 것이다. GPT2 구조는 byte level 수준의 BPE를 사용하고 pre processing이 필요하지 않기 때문에, 어느 language model benchmark에 다 적용이 가능하다는 것이다. 그리하여 de tokenization을 진행하고, 이에 대한 GPT2 결과는 아래와 같다.
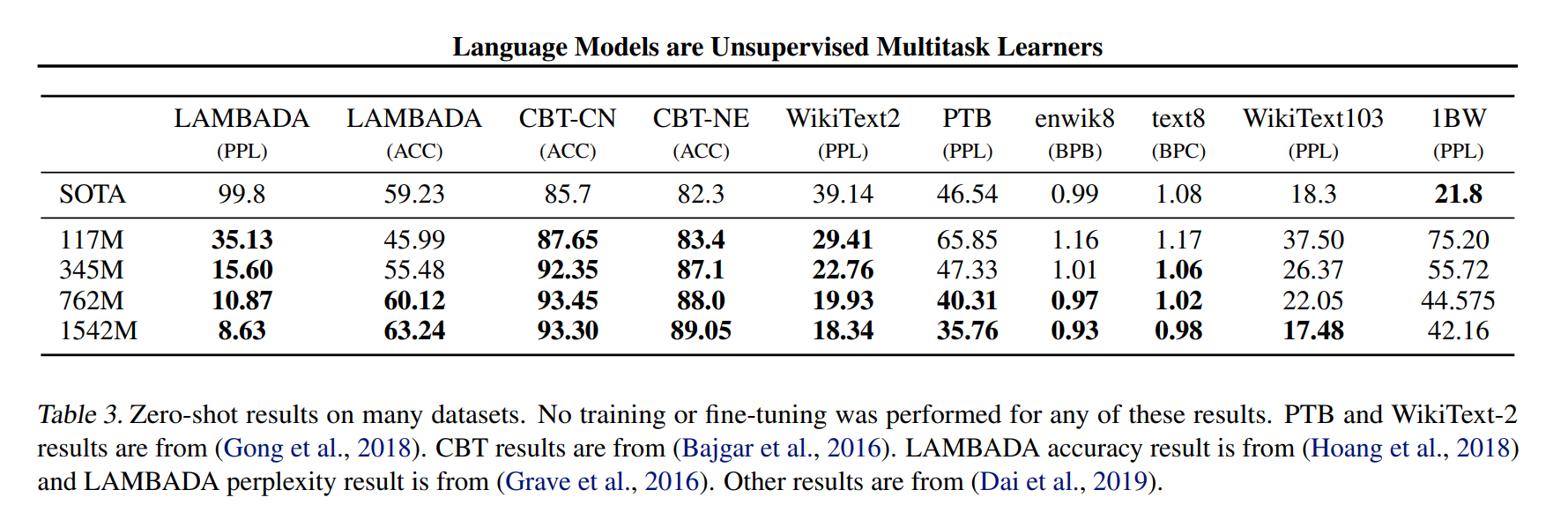
WebText LM으로 학습을 했던 구조는 8개 데이터 셋에서 7개의 SOTA를 달성할 수 있었다.
3.2 Children’s Book Test
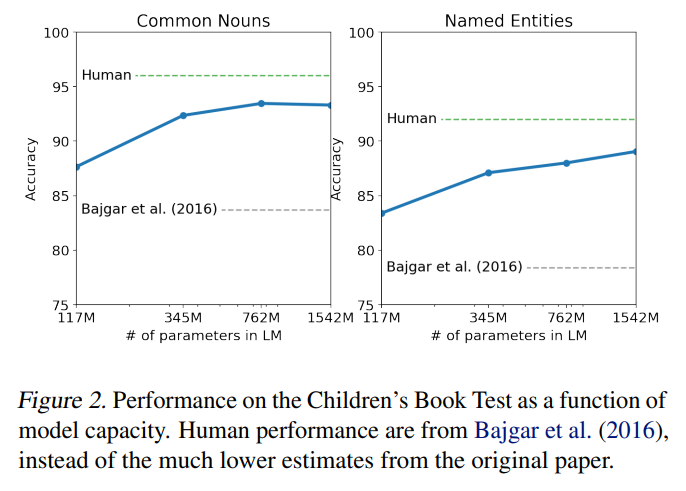
CBT는 name entities, nouns, verbs, prepositions 등과 같은 다양한 카테고리의 LM 퍼포먼스를 확인하기 위해 만들어졌다. CBT는 accuracy를 평가지표로 사용하였다. 모델 사이즈가 점점 커질수록, 모델의 평가 지표인 accuracy가 계속 증가하는 것을 볼 수 있었고, 인간의 차이와 점점 가까워 지는 것을 확인할 수 있다.
3.3 LAMBADA
LAMBADA dataset은 문장의 long range dependency를 확인하기 위해 만들어진 능력으로, 이 task는 문장의 마지막 단어를 예측하여 적어도 맥락의 50개의 토큰들을 필요로 한다. GPT2 모델은 SOTA를 달성하였고, 다른 모델들 보다 매우 높은 성능을 보였다. 여기서 신기했던 점은 LM이 예측했던 문장들은 타당하게 연속적이었으나 마지막 단어는 그렇지 않았다. 그리하여 LM은 문장이 마지막에 있어야 하는 constraint를 사용하지 않는 다는 것을 알게 되었다. 이전에 SOTA를 달성했던 Hoang et al 모델은 모델의 output을 마지막 단어에 제한하는 것인데, 이 방식은 GPT에 적절하지 않았다고 한다.
3.4 Winograd Schema Challenge
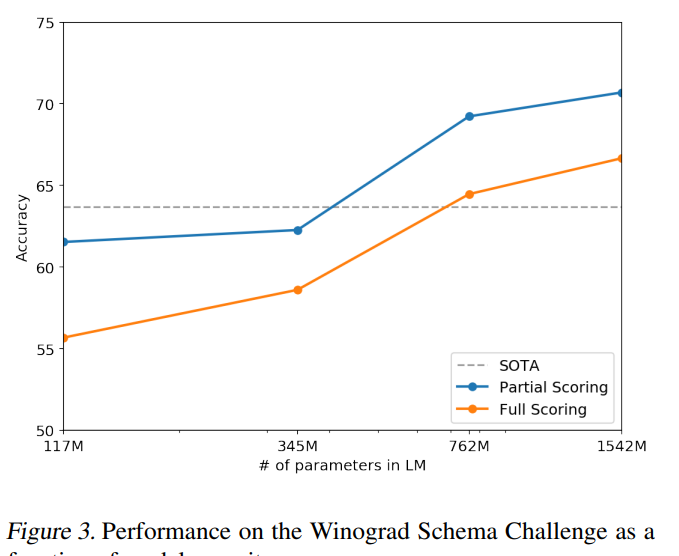
Winograd Schema challenge는 문장의 모호함을 해결하는 능력을 측정해서 상식을 수행하는 능력을 검증하기 위한 것으로 만들어졌다. 최근에 Trinh & Le는 LM 모델을 활용하여 높은 성능을 보여주었고, 저자또한 이러한 문제를 GPT2로 높은 성능을 보여주었다.
3.5 Reading Comprehension
CoQA는 7개의 다른 도메인으로 질문과 대답을 하는 것으로 구성되어 있다. CoQA test는 읽기 능력과 모델이 질문에 답하는 능력을 검증하는 것이다. GPT2는 unsupervised learning 이기 때문에 정답 데이터 없이 순수하게 학습을 하여 55F1 점수를 얻었다고 한다. 그에 반면 BERT는 89F1 스코어를 얻었다는 것을 볼 수 있어 점수 차이가 심한 것으로 보인다.
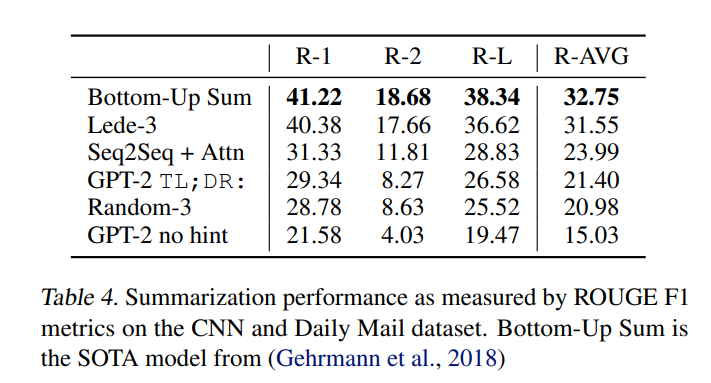
3.6 Summarization
CNN과 Daily Mail dataset을 활용하여 GPT-2의 성능을 확인해보았다. 텍스트에 TL와 DR을 추가하여 요약을 하였고, Top 2개만을 가지고 100개의 토큰을 만들어서 성능을 검증해보앗다. 저자는 3개의 생성된 문장으로 100개의 토큰을 이용하여 요약에 사용하였다고 한다.
3.7 Translation
추론을 잘 하기 위해서, english sentence = french sentence를 넣은 구조를 조건을 주고, 나중에 english = sentence는 무엇인가 라는 문장으로 decoding을 했다고 한다. WMT-14 English - French test set을 활용하면, GPT-2는 BLEU에서 5점이 나왔고, 이건 word - by - word로만 해석했을 때보다 훨씬 낮은 점수이다. 점수는 낮았지만 여기서 놀라웠던 점은 고의적으로 영어가 아닌 페이지를 없애고 학습을 진행하였다는 점이다. 그래서 이걸 확인하기 위해서, WebText에서 오직 10 MB 이하의 데이터셋만을 구하여 byte - level - langugage detector을 발견하여 검사를 했다고 한다.
3.8 Question Answering
무슨 정보가 lauguage model에 가장 많이 포함되어 있는지를 알기 위해서는 얼마나 올바른 문장을 잘 generate 하는지를 확인하는 것이다. 신경망에 모든 정보가 포함되어 있는 상황은 높은 질적인 데이터셋이 없기 때문에 질적인 문제를 보고하였다. 최근에는 NQ 데이터셋이 나와 질적인 데이터셋을 확인할 수 있게 되었다. 번역과 비슷하게, 언어 모델의 맥락은 예시 문장과 대답 문장의 쌍이 같이 들어가서 모델이 이를 잘 추론하게 만들어 준다.
GPT-2는 SQUAD와 같은 독해 데이터셋에서 흔히 사용되는 정확한 일치 측정 방식으로 평가했을 때 4.1%의 질문에 정확하게 답합니다. 비교를 위해 가장 작은 모델은 각 질문 유형(누구, 무엇, 어디 등)에 대해 가장 흔한 답변을 반환하는 매우 단순한 기준의 1.0% 정확도를 초과하지 않습니다. GPT-2는 5.3배 더 많은 질문에 정확하게 답함으로써, 모델 용량이 이러한 종류의 작업에서 신경 시스템의 성능 저하의 주요 요인이었음을 제안합니다.
4. Generalization vs Memorization
최근 CV 분야에서는 공통의 이미지 데이터셋에 non - trivial amount of near duplicate image를 공개하고 있다고 한다. 예를 들어서, CIFAR 10은 3.3 퍼센트의 overlap 되는 train와 test 이미지를 가지고 있으며, 이는 일반화 성능의 over reporting 되는 결론을 일으킨다. 데이터셋이 커지면 커질수록, 이는 WebText와 같이 비슷한 현상을 일으킬 수 있다고 생각한다. 그래서 test data가 얼마나 training data에 나오는 지를 알아내는 것도 굉장히 중요하다고 할 수 있다.
그래서 저자는 Bloom filters를 만들어서 연구를 진행하였다. 8 gram 의 방식으로 WebText 문장 토큰을 바탕으로 Bloom filter를 구성하였다. 연구 결과, 일반적인 벤치마크 보다 WebText 데이터셋이 3.2 퍼센트로 overlap 되어 있는 것을 알 수 있습니다.

중복 데이터는 WebText에만 국한된 문제가 아닙니다. 예를 들어, WikiText-103 테스트 셋에는 훈련 데이터셋에도 포함된 기사가 있었습니다. 이러한 중복은 모델의 성능 평가에 영향을 줄 수 있습니다.
대표적으로, CoQA와 LAMBADA 데이터셋에서도 중복이 관찰되었으며, 이러한 중복은 모델 성능에 작은 영향을 미칩니다. 예를 들어, CoQA의 경우 뉴스 도메인 문서 중 약 15%가 WebText에 이미 포함되어 있으며, 이러한 중복은 모델의 F1스코어를 약간 향상시켰습니다. LAMBADA에서는 1.2%의 평균 중복이 있었고, 15% 이상 중복되는 예시에서는 GPT-2가 더 낮은 perplexity를 보여주었습니다,
그리하여 저자는 overlap 되어 있는 파일을 제거하는 것이 중요하며, WebText의 데이터셋으로 학습한 GPT-2는 underfitting 되어 있다고 말할 수 있다고 합니다. 그래서 n-gram 방식을 이용하여 데이터셋의 학습 결과를 확인해보라는 것입니다.
7. Conclusion
저자는 크고 다양한 데이터셋에서 훈련된 대규모 언어 모델이 다양한 도메인과 데이터셋에서 높은 성능을 보일 수 있다는 것을 강조합니다. GPT-2는 8개의 언어 모델링 데이터셋 중 7개에서 최고의 성능을 달성함으로써, 다양한 텍스트 코퍼스의 가능성을 최대한 활용하여 훈련된 고용량 모델이 다양한 작업을 수행할 수 있음을 보여줍니다.
이는 GPT-2와 같은 모델이 언어 모델링을 넘어서 다양한 NLP 작업에서 우수한 성능을 보일 수 있음을 의미합니다. 이는 언어 모델이 단순한 텍스트 생성을 넘어서 실제 응용 프로그램에서 다양한 기능을 수행할 수 있음을 보여주는 중요한 지표입니다.
한 줄로 요약하면?
이 논문은 엄청나게 충분히 많은 데이터셋을 기반으로 하면 unsupervised learning도 zero shot learning을 기반으로 해서 NLP 다른 task 부분에서 높은 성능을 보여줄 수 있다는 점, 밴치마크에서 사용하는 데이터셋이 종종 중복되어 있는 경우가 많아서, 이를 WebText 라는 데이터셋을 만들어서 검증을 했다는 점이다 .
