[논문 리뷰] T5 - Exploring the Limits of Transfer Learning with a Unified Text_to_Text Transformers
자연어처리 논문 리뷰
Preface

T5 논문은 너무 길어서 최대한 논문에서 말하고자 하는 바를 위주로만 정리하였습니다…(67장 넘 길어..)
1. Introduction
논문이 나올 당시에는, transfer learning이 명확하게는 진행되지 않았고 하나의 보조 도구로만 취급을 했습니다. 예를 들어서, Word2Vec와 같이, 단어를 단순히 벡터로 변환을 시켜서 모델이 이를 이해하기 쉽게 해주는 보조 도구처럼 말입니다.
CV 분야에서는 labeled된 데이터로 pretraining을 진행하는 반면, NLP 분야에서는 unlabeled된 data로 pretraining을 진행하고 있습니다. 일반적으로 NLP에는 unlabeled된 pretrain이 적합한데, 인터넷에서 많은 글을 긁어올 수 있을 뿐 아니라 모델의 데이터 양이 많으면 많을수록 더 좋아지기 때문에 unlabeled된 데이터를 지향합니다.(CV에서는 ImageNet이라는 벤치마크 덕분에 그냥 labeled로 쓴다고 함)
하지만 이렇게 빠르게 발전을 하다 보니, 너무 나도 많은 방식으로 인해 다른 알고리즘이나 모델들 간의 비교가 힘들어졌습니다. 그래서 저자는 이런 방식들을 비교할 수 있게, unified 된 transfer learning을 만들자는 것입니다.
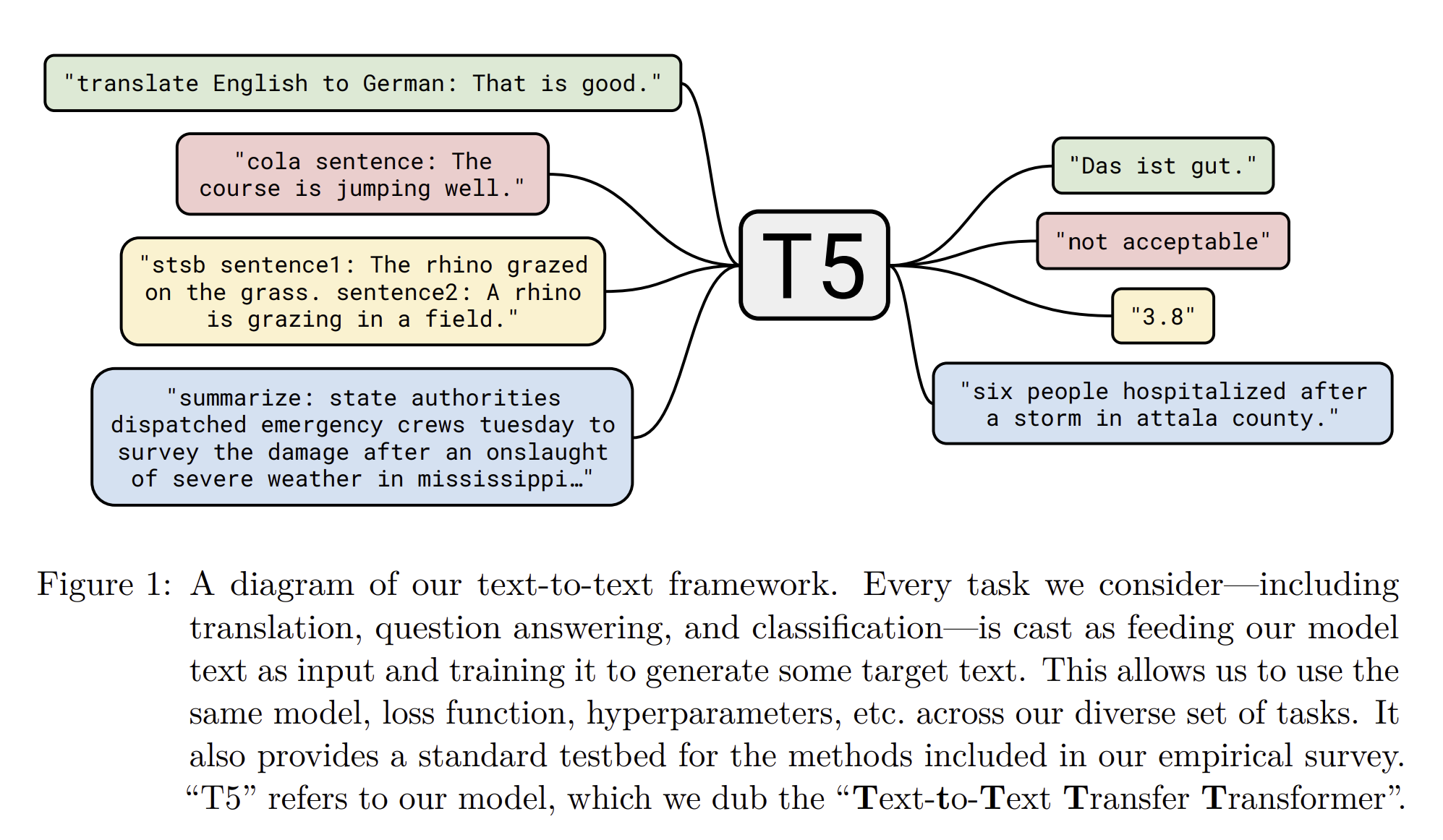
가장 기본적인 생각은 모든 text processing problem을 text-to-text 문제로 변환하자는 것입니다. 이러면, text-to-text의 framework가 다 같아지며, objective,training procedure,decoding precess 들 과 같은 과정들이 같아져서 비교하기 쉬워지게 됩니다.
그래서 저자는 새로운 아키텍처를 제안하기 보다는 NLP 분야의 comprehensive한 관점을 남기는 것을 목표로 하였고, “Colossal Clean Crawled Corpus” for pretraining (C4) 라는 데이터셋을 만들어냈습니다.
2. Setup
저자가 제안한 모델과 프레임 워크의 이름을 “Text-to-Text Transfer Transformer”(T5) 라고 정의를 합니다.
2.1 Model
Model은 기본적으로 Transformer 구조를 따라갑니다. Transformer 구조에서 빠지는 것이 Layer Norm bias, layer normarlization, different position embedding scheme 들 입니다.
2.2 The Colossal Clean Crawled Corpus
많은 NLP 구조에서 활용하는 pretraining은 unlabeled data를 통해서 진행이 됩니다. 그래서 unlabeled data를 어떻게 활용하는지가 굉장히 중요하며 이 데이터의 quality, characteristics, size 등을 고려해서 데이터를 수집하는 것도 굉장히 중요합니다. 그래서 Common Crawl을 통해서 데이터 수집을 진행했습니다. 웹에서 스크랩된 데이터는 종종 비효율적이고, 노이즈가 많으며, 때로는 관련 없는 내용을 포함하고 있습니다.
따라서, 연구팀은 데이터를 더 유용하고 의미 있는 형태로 정제하는 과정을 거쳤습니다. 과정은 다음과 같습니다.
- We only retained lines that ended in a terminal punctuation mark (i.e. a period,
exclamation mark, question mark, or end quotation mark) - We discarded any page with fewer than 3 sentences and only retained lines that
contained at least 5 words. - We removed any page that contained any word on the “List of Dirty, Naughty, Obscene
or Otherwise Bad Words”.6 - Many of the scraped pages contained warnings stating that Javascript should be
enabled so we removed any line with the word Javascript. - Some pages had placeholder “lorem ipsum” text; we removed any page where the
phrase “lorem ipsum” appeared. - Some pages inadvertently contained code. Since the curly bracket “{” appears in
many programming languages (such as Javascript, widely used on the web) but not in
natural text, we removed any pages that contained a curly bracket. - Since some of the scraped pages were sourced from Wikipedia and had citation markers
(e.g. [1], [citation needed], etc.), we removed any such markers. - Many pages had boilerplate policy notices, so we removed any lines containing the
strings “terms of use”, “privacy policy”, “cookie policy”, “uses cookies”, “use of
cookies”, or “use cookies”. - To deduplicate the data set, we discarded all but one of any three-sentence span
occurring more than once in the data set.
그리고 영어가 아닌 데이터가 종종 있어서 langdetect를 이용해 구별했다고 합니다.
2.3 Downstream Tasks
그리고 각 테스크에 맞게, benchmark 데이터셋을 구성하여 학습을 진행하였다.
2.4 Input and Output Format
모델 학습과 pretraing에 있어서, 모든 구조는 ‘text - to - text’구조로 만들어서 학습을 진행하였다.
예를 들어서, 영어에서 독일어로 번역을 할 때는, ‘translate English to German: That is good’ 이라는 표현을 통해서 학습을 진행하였다고 하고, Text classifcation에서는 ‘mnli premise : I hate pigeons. hypothesis : My feelings towards pigeons are filled with animosity” 라고 하였습니다. 저자는 McCann et al. (2018)이 제안한 "Natural Language Decathlon"에서 영감을 받아 다중 작업 처리에 중점을 두고 있습니다.
3. Experiments
3.1 Baseline
3.1.1 Models
모델은 기본적인 Transformer encoder decoder 구조를 사용했습니다. Encoder, Decoder는 12개의 블록으로 구성되었고, 차원은 64차원, 모델의 차원은 768차원 입니다. 220만개의 파라미터를 이용하여 모델을 구성하였고, 이는 BERT_BASE보다 2개 가까이 되는 파라미터 입니다.
3.1.2 Training
optimization 으로는 AdaFactor을 사용하였고, greedy decoding을 통해 평가를 했습니다. 각 모델별로 C4를 524288번 학습을 진행하였고, 최대 길이는 12, batchsize은 128로 구성하였습니다. 데이터셋의 해당되는 batch은 BERT보다 적었으며 RoBERTa와 비슷했습니다. pretraining을 진행하는 동안, inverse square root으로 learning rate shcedule을 설정하였습니다. 그리하여 pretraining을 진행하는 과정에서 learning rate를 줄여나갔습니다.
3.1.3 Vocab
SentencePiece를 사용하였고, 모든 실험에는 3만 2천개의 wordpiece가 구성되었다고 합니다.
3.1.4. Unsupervised Objective
pretraining이 굉장히 큰 이점을 받고 있지만, 요즘에는 denosing objectives로 인한 학습 결과가 더 좋다고 합니다. BERT 구조에서 영감을 받아, 랜덤으로 샘플을 하고, 15퍼센트의 token들을 drop out 하는 경우를 만들었습니다.
3.1.5 Baseline Performance
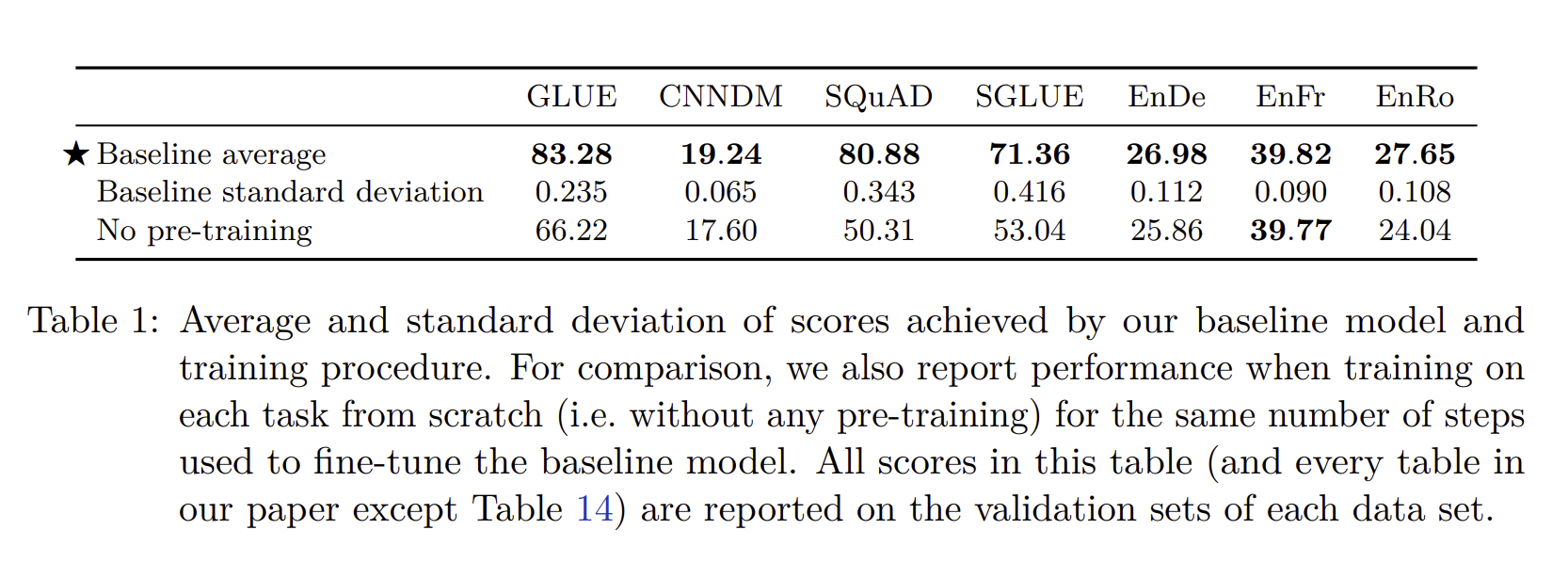
여러 데이터셋에 모델을 10번을 학습을 하였고 각 평균 값을 위에 작성해놓았습니다. 그리고 benchmark을 통해서 pretrained 중요성을 언급하였습니다. 표준 편차가 1보다 작다는 것도 확인을 할 수 있는데, 이 말은 일반화가 잘 된다는 의미를 내포합니다.
3.2 Architectures
T5는 표준 Transformer 어텐션 메커니즘을 사용하지만, 몇 가지 변형을 추가하여 효율성과 성능을 개선합니다. 예를 들어 relative positional encoding을 사용하여 시퀀스 내 각 단어의 위치 정보를 더 잘 통합하기도 하고, 소프트맥스 계산 전에 어텐션 스코어에 대한 정규화를 수행하여, 극단적인 값의 영향을 줄이고 학습의 안정성을 개선합니다.
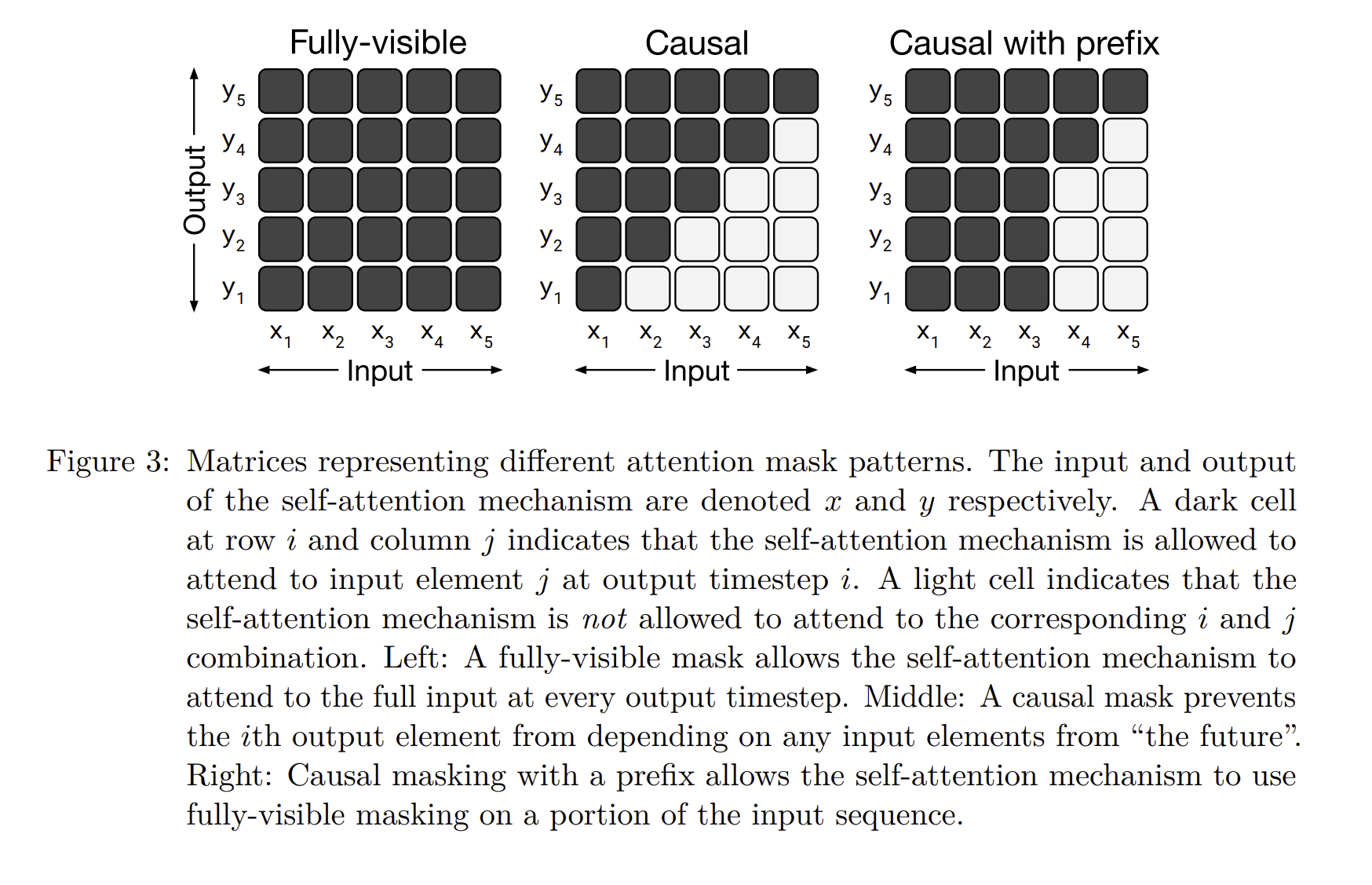
그리고 Decoder 파트에서 신기한 점은 prefix attention을 이용한다는 것입니다. prefix attention은 접두사와 같이 특정 부분에 더 집중하여 본다는 것입니다.
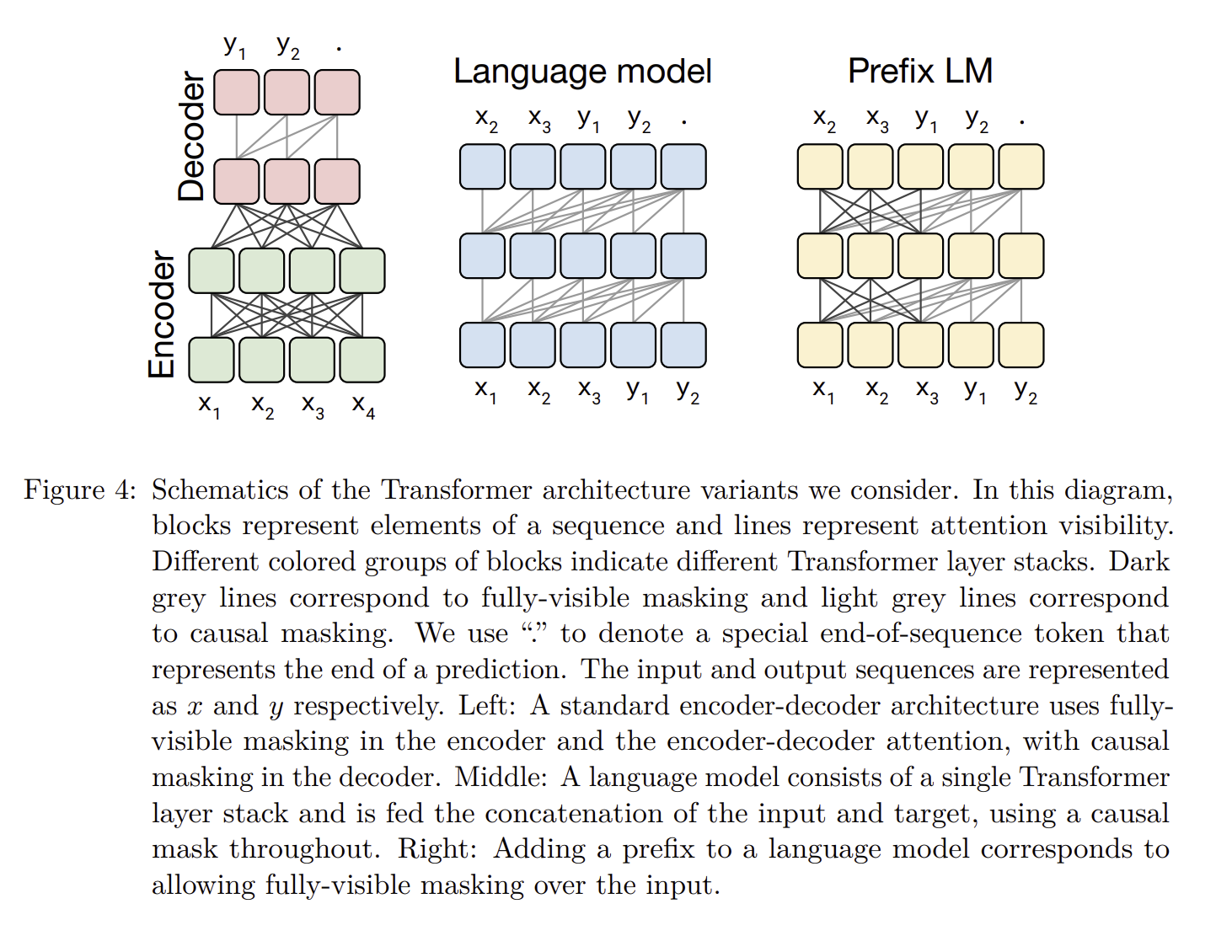
구조는 위와 같습니다.
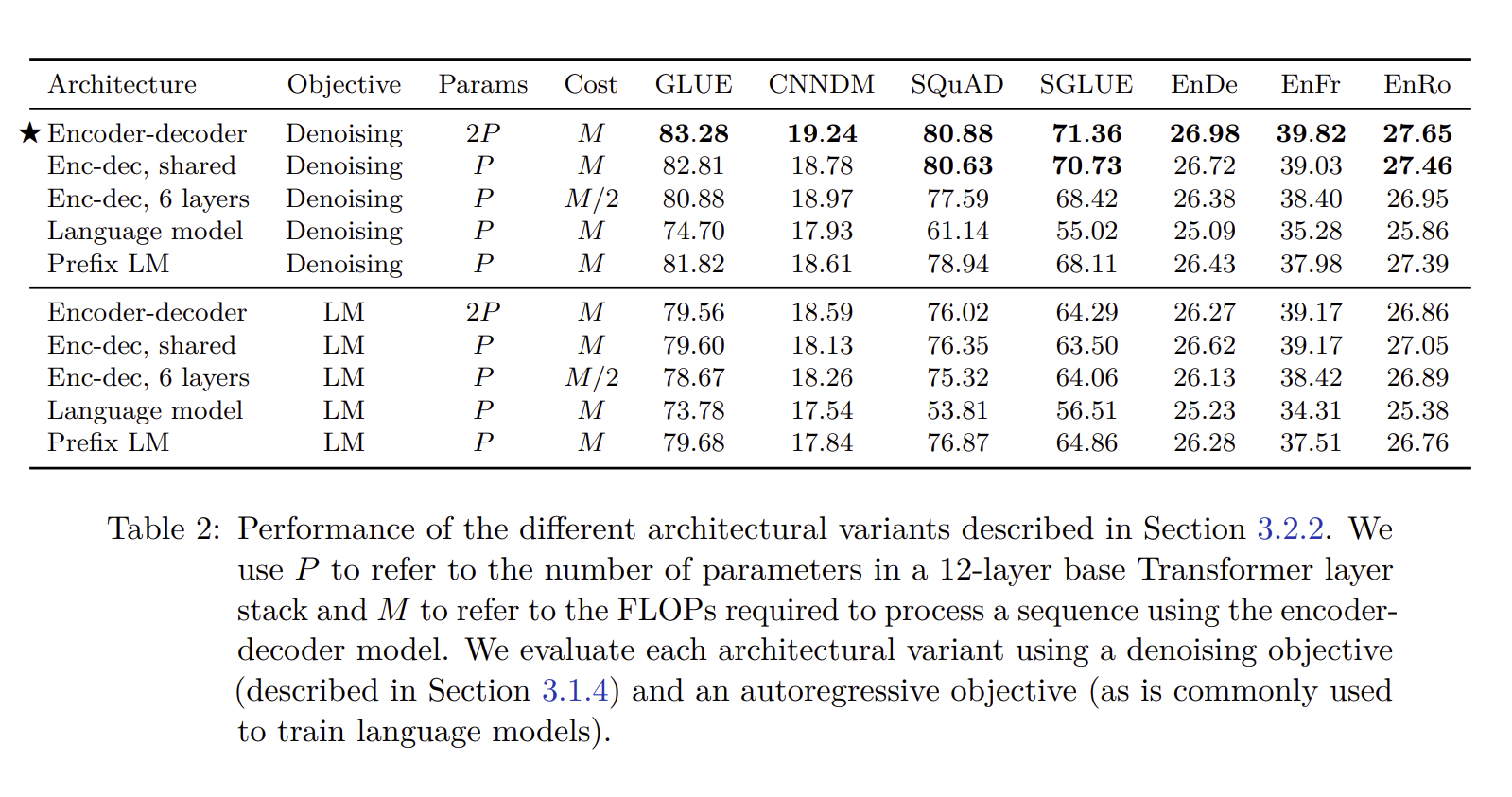
학습 결과, 파라미터와 objective를 어떻게 보느냐에 따라 달라지는데, 결과는 Encoder- Decoder 모델, Denoising을 하며, Parameter를 2배로 늘린 모델의 성능이 가장 높게 나온 것을 확인할 수 있습니다.
3.3 Unsupervised Objectives

T5를 pretrain 하는 과정에서는 bidirectional하게 학습을 진행합니다. BERT는 하나의 토큰을 MASK하여 학습하지만, T5는 연속된 token을 하나의 mask로 바꾸어서 pretrain을 진행합니다.
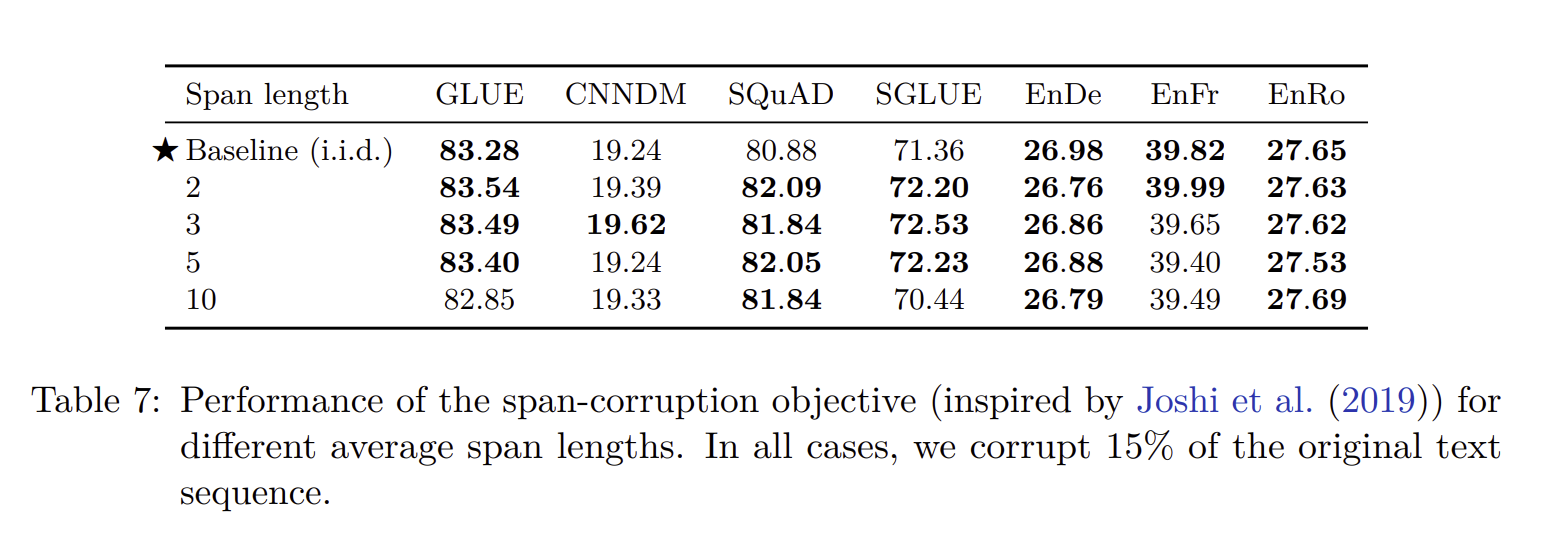
그리고 임의의 단어를 마스킹하기 보다는 span을 마스킹합니다. 그리고 논문을 계속 읽어보면, Scaling 방법이나 Dataset의 차이 등 다양한 부분을 말해놓았는데, 논문의 길이가 너무 길어 마지막에 best performance로 중요한 것만 설명하겠습니다…
4. Reflection
4.1 Takeaways
- Text to text
- 각 테스크 별로 나눈 것이 아니라 텍스트와 텍스트를 붙여서만 해도 학습이 잘 되게 했다는 것.
- Archtectures
- Encoder와 Decoder를 전부 사용했음에도 불구하고, Encoder only와 Decoder only만큼 computational cost도 비슷했다는 점. 그리고 Encoder와 Decoder의 parameter를 공유해도 딱히 큰 performance drop을 일으키지는 못했다는 점.
- Unsupervised Objectives
- Denosing objectives 방법이 제일 좋은 방법이었다는 점.
- Dataset
- C4를 이용한 결과가 제일 좋았고, 도메인 내 레이블이 없는 데이터로 훈련하는 것이 특정 작업의 성능을 향상시킬 수 있지만, 도메인을 한정하면 데이터셋 크기가 작아질 수 있었다는 점.
- Training Strategy
- pretrained된 모델의 모든 파라미터를 fine tuning하는 기본 접근 방식이 적은 파라미터를 업데이트하는 전략보다 성능이 더 우수했다는 점.
- Scailing
- 다양한 작업을 동시에 훈련하는 것은 ensemble 설정에 대한 명확한 전략 없이는 fine tuning이후 단일 작업으로 훈련하는 것과 비슷한 성능을 보였다는 점
등이 위 논문에서 best performance를 하는데 나온 결과들 입니다.
한 줄로 요약하면?
T5는 텍스트와 텍스트만을 가지고 NLP의 모든 테스크에 집중할 수 있으며, C4라는 새로운 데이터셋을 활용하여 Pretrained을 진행하고, BERT와는 다른 Encoder-Decoder를 모두 활용한 구조이다.
