preface

1. Introductions
저자는 NLP의 역사를 읊으면서 task-specific한 모델이 아닌 task-agnostic을 제안합니다.
첫번째로, large dataset을 모으기는 힘들다는 점, 두번째로, training data의 spurious correlations(허위 상관)이 모델 결과에 영향을 줄 수 있다는 점입니다. 좁은 데이터셋의 분포에서 학습을 하게 되면, 허위된 상관관계를 배울 수 있습니다. 이러한 점들은 pre-training과 fine tuning의 페러다임에 문제를 주게 됩니다. 예를 들어서, Large model은 distribution 외에는 잘 일반화가 안된다는 점입니다. training distribution에 너무나도 치중되어서 결과가 일반화를 잘 나타내지 못할 수도 있다는 점입니다. 인간 수준의 학습된 모델의 performance도 결국 실제 테스크에서 잘 나오지 못할 수도 있다는 점입니다.
세번째로, 인간들은 언어를 배우는 데 사실 엄청나게 많은 데이터셋이 필요한 것이 아닙니다. 마찬가지로 NLP 시스템에서도 이와 같이 같은 유동성과 일반화를 가질 수 있을 것입니다.
저자는 위와 같은 방식을 위해 meta learning을 제안합니다. 언어 모델의 context 안에서, 모델들은 더 넓은 스킬들을 발전시킬 수 있으며, 그런 스킬들을 inference 시간에 desired_task에 적용시킬 수 있다는 것입니다. (예를 들어서, 인간은 자전거를 타는 것을 배우면, 오토바이를 타는 것도 금방 배우고, 활 쏘는 방법을 알면 총 쏘는 것도 금방 배울 것임. 이와 같이 모델도 어느 한곳에 학습을 제대로 해 놓으면 비슷한 방법을 학습하는데에는 큰 material이 필요하지 않다는 점). 하지만 성능이 그렇게 높지 않다는 사실.
언어모델에서 다른 특이한 점은 forward way을 알려주는 것입니다. 최신 Transformer 모델은 100만개의 파라미터에서 170억개의 파라미터까지 굉장히 많은 파라미터로 구성되어 있습니다. 이렇게 기하급수적으로 증가한 것은, downstream task에 좋은 결과를 가져다 주었고, 이는 인간과 비슷한 구조를 가지고 있다고 볼 수 있습니다.
저자는 GPT3를 1750억개의 파라미터를 통해서 실험을 하였습니다. 구체적으로 24개의 NLP dataset을 평가하였고, 각 테스크에는 3가지의 방식으로 진행이 되었습니다.
- few - shot learning or in-context learning where we allow as many demonstrations as will fit into the model’s context window
- one - shot learning
- zero shot learning
와 같이 3가지의 방식으로 진행이 되었습니다.
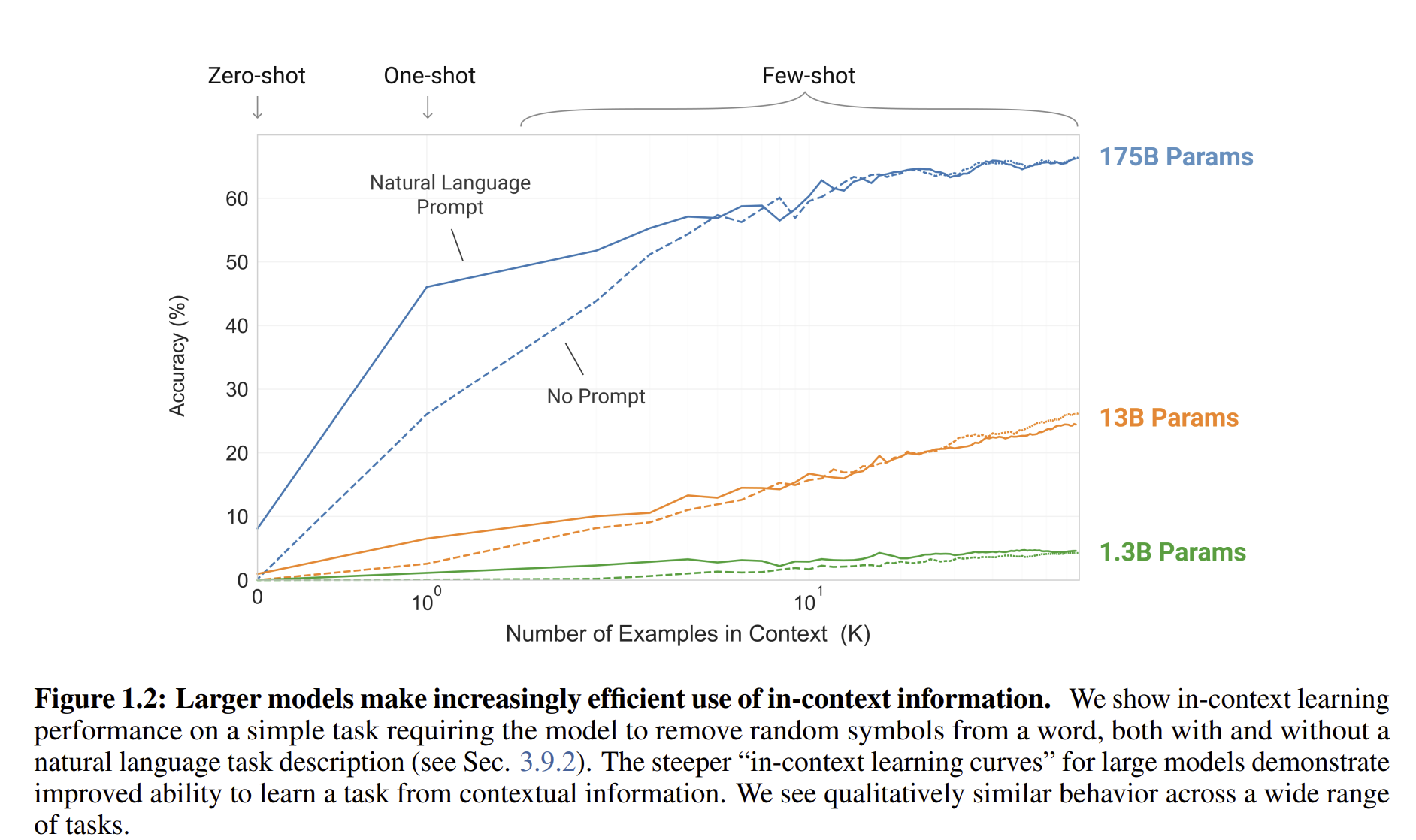
Figure 1.2를 보게 되면, few shot learning이 굉장히 높은 성능을 보이는 것을 알 수 있습니다. (진짜 돈 때려부어서 학습)
zero shot learning이나 one shot learning은 높은 성능을 보였고, Few-shot learning은 SOTA를 뛰어넘을 정도의 performance를 보여주었습니다.
GPT3는 또한 one shot learning과 few shot learning의 효율성도 보여주었는데, 빠르게 학습을 할 수 있다는 점들을 보여주었습니다. 저자는 또한 few shot learning에서, GPT3는 인간 평가원들이 인간이 만들었는지 구별하기 어려운 news articles을 또한 만들어낼 수 있었습니다.
또한 저자는 data contamination을 겪었다고 하는데, data contamination은 model의 데이터셋의 데이터 양이 너무 많아서 이는 test dataset에도 언젠가는 겹칠 수 있게 된다는 의미입니다. 그래서 이 논문에서 data contamination을 확인하고 이를 구별하는 방법에 대해서 제안합니다.
2. Apporach
일단 2020년 당시에 유명했던 학습 방법들을 소개하면서 GPT 3는 어떻게 학습할 것인지에 대해서 알아봅시다.
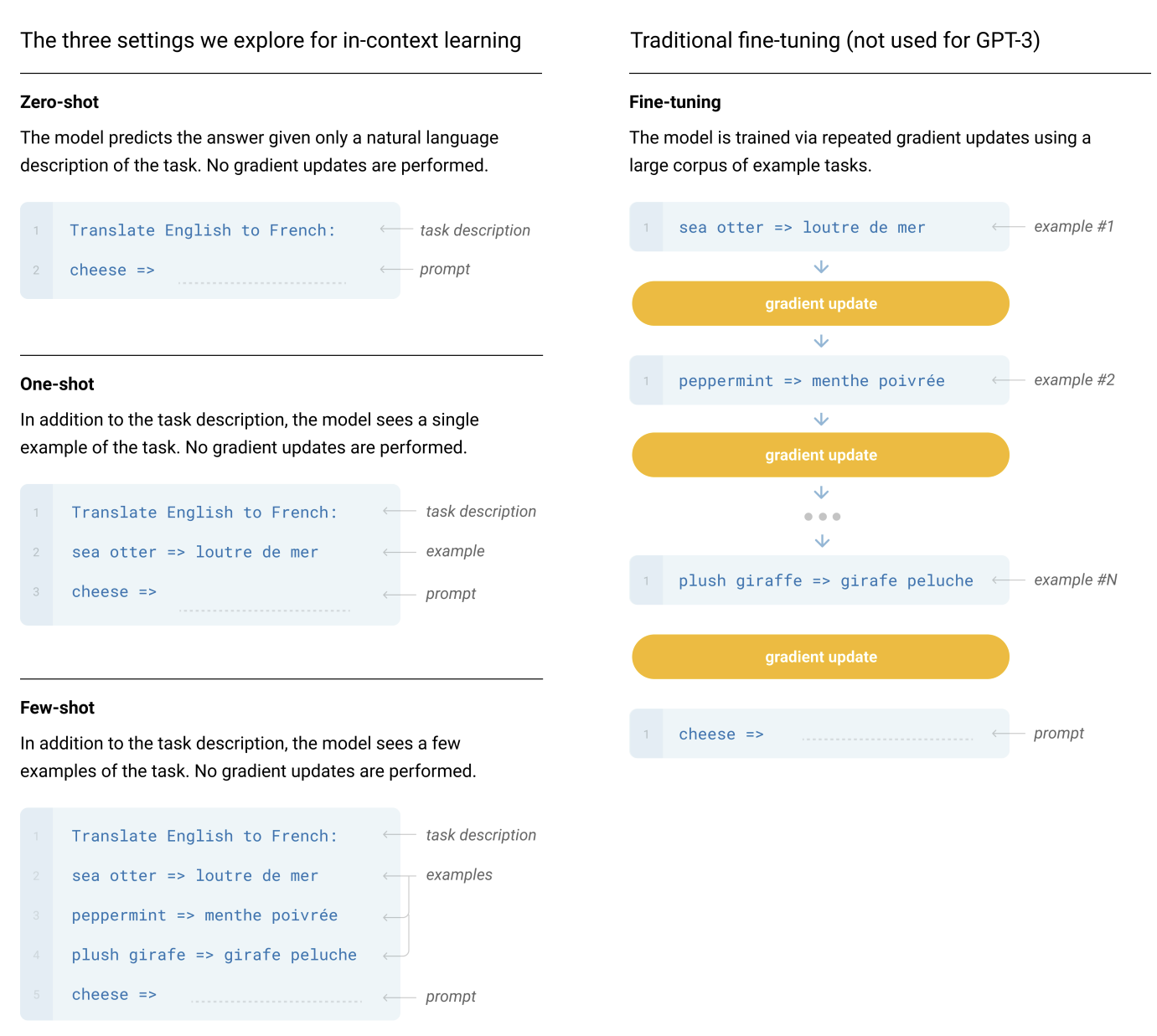
- Fine tuning
- fine tuning은 굉장히 유명하고, benchmark에서 높은 성능을 보이지만 매번 large dataset이 필요하다는 점 때문에 GPT3 에서는 사용하지 않는다는 점.
- weight update 덕분에 굉장히 높은 성능을 보인다.
- Few-Shot
- Few shot learning은 weight update는 없지만, K개의 sample을 주어서 모델이 결과를 내는데 큰 도움을 준다. 성능이 나쁘지 않다는 점과 데이터셋이 그렇게 많이 필요하지 않다는 점이 장점이다.
- 반면에 Fine tuning을 한 모델보다 성능이 별로 좋지는 못하다.. 그리고 task specific한 데이터가 조금은 필요하긴 하다.
- One-Shot
- One-shot learning은 few shot learning과 비슷한데 다만 데이터 샘플이 1개라는 점.
- Zero-Shot
- Zero shot learning은 Y 데이터가 아예 없다는 점이다. 그냥 바로 결과를 물어보는 것인데, 이는 이상한 데이터로 부터 학습될 일이 없다는 점이 좋지만, setting이나 기준이 전혀 없기에 무엇을 보고 나아가야 하는지를 거의 모른다.
GPT 한 모델의 다른 내용들 집합
2.1 Model and Architectures
GPT2와 똑같은 아키텍쳐를 사용하였습니다. 유일하게 다른 점은 sparse Transformer를 활용했다는 점입니다.
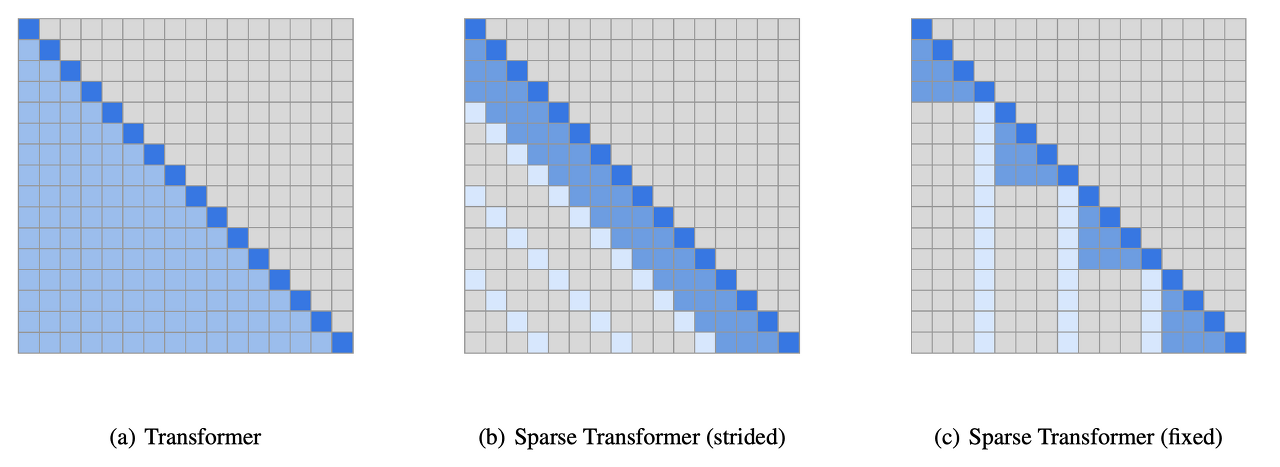
일정한 패턴을 두고 Attention을 적용하기 때문에 계산량의 이점을 가지고 있습니다.
2.2 Training Dataset
언어 모델을 위한 Dataset은 굉장히 많아졌는데 특히 Common Crawl dataset은 1조 단위의 데이터셋으로 구성되어 있습니다. 이 데이터들을 다 학습하면 당연히 좋겠지만, unfiltered되었거나 가볍게 filtered가 된 Common Crawl 모델들은 더 낮은 성능을 내는 경우가 있기 때문에 3가지의 스탭으로 데이터셋을 전처리 하였습니다.
- 고품질 참조 코퍼스와의 유사성을 기반으로 한 Common Crawl 버전 다운로드 및 필터링: 이는 고품질 reference corpus와 비교하여 유사성을 기준으로 Common Crawl 데이터를 선별하고 필터링하는 과정을 포함합니다. 이를 통해, 데이터의 질적 수준을 높입니다.
- 문서 수준에서의 퍼지(Fuzzy) 중복 제거: 이는 데이터셋 내부와 데이터셋 간에 문서 수준에서 중복을 제거하는 과정입니다. 이는 중복을 방지하고, 보유한 검증 세트의 무결성을 유지하여 과적합에 대한 정확한 측정치를 제공하기 위함입니다.
- 고품질 참조 코퍼스 추가: Common Crawl을 보완하고 다양성을 증가시키기 위해 알려진 고품질 reference corpus를 훈련 데이터셋에 추가했습니다. 이는 데이터셋의 다양성과 품질을 개선하는 데 도움이 됩니다.
그리고 WebText dataset을 추가하였습니다.
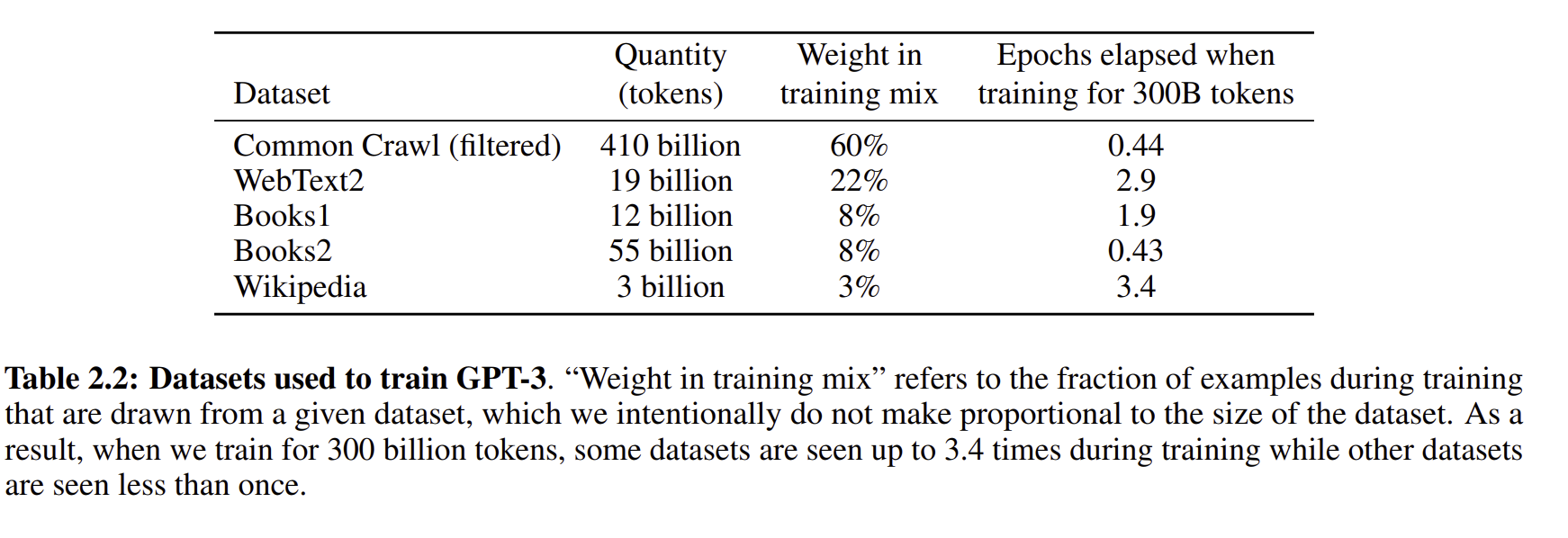
위 표는 모델에서 사용한 학습된 데이터의 양을 표현한 것이다.
pretraining을 하면서 가장 걱정되는 점은 pretraining한 데이터가 downstream task에 적용을 할 때, potential contamination이 야기될 수도 있다는 점입니다. 그래서 overlap되는 데이터를 삭제하고, 모든 benchmark의 데이터셋을 test 해보았습니다. 하지만 이 문제는 해결을 못해서 미래에..
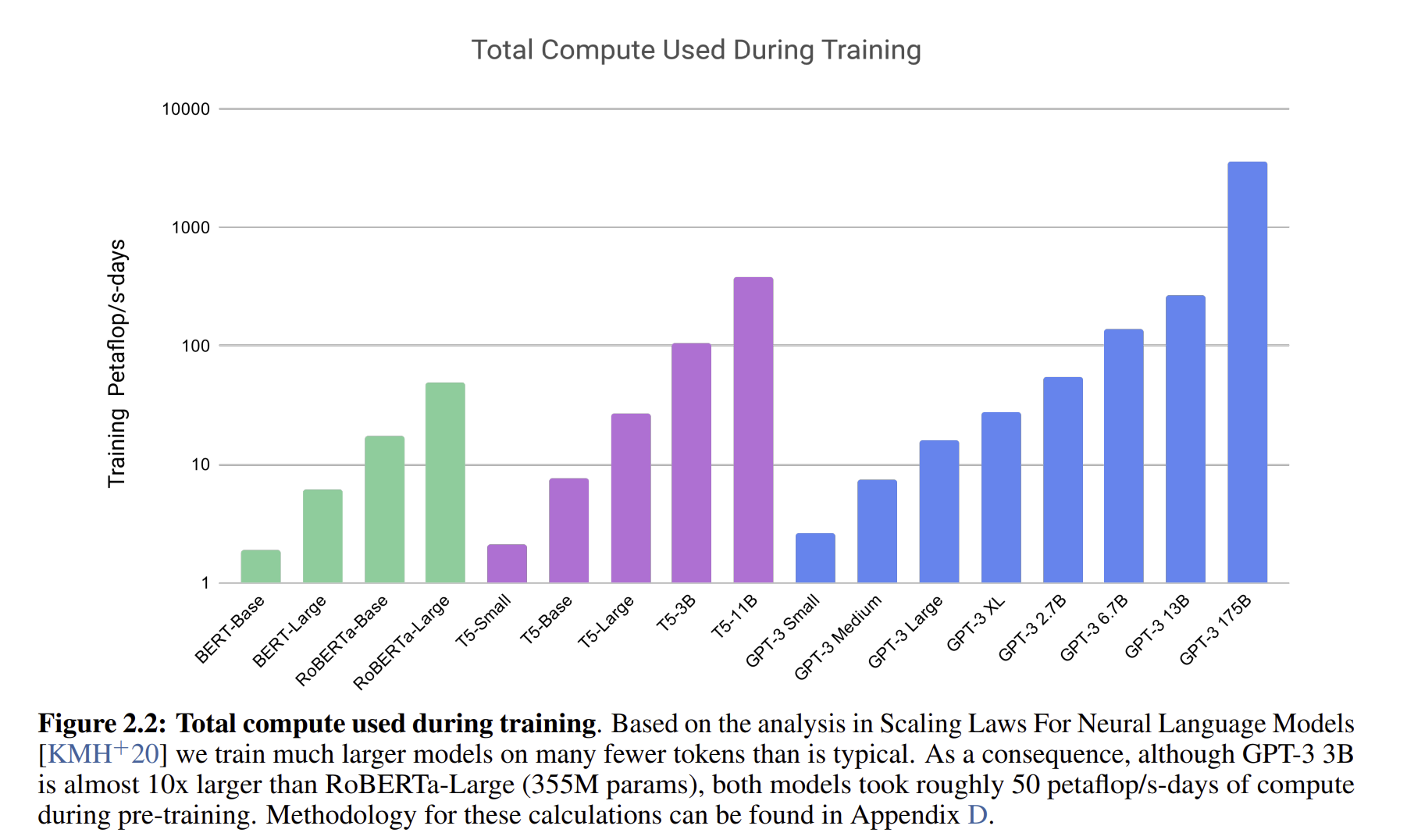
이는 모델별로 사용한 pretraining 데이터셋으로 GPT3가 압도적으로 많은 것을 볼 수 있다.
2.3 Training Precess
larger model은 더 큰 larger batch size를 사용하지만 smaller learning rate가 필요합니다. 저자는 training 과정동안 gradient noise를 측정하였고, 이를 batch_size를 정할때 사용하였습니다.
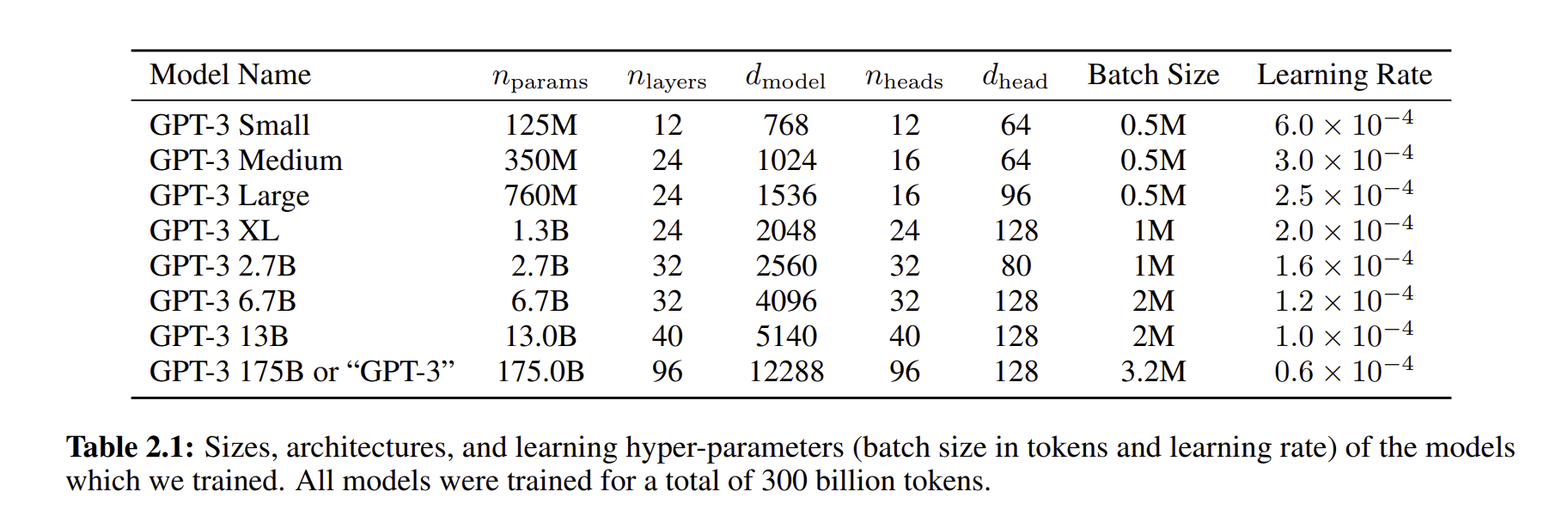
2.4 Evaluation
few - shot learning으로, 저자는 K개의 example을 다 평가를 하였습니다. K개는 0개부터 모델의 context window의 최댓값이 될 수도 있습니다. 큰 K값은 종종 있지만 더 좋다고 할 수는 없었고, 최고의 성능을 낼 수 있는 구조로 보았습니다.
여러개에서 한개를 선택하는 task에서는, K개의 예시에 정답 데이터를 한 개 추가해주었고, binary classification에서는 0과 1 같이 극단적인 선택보다는 True나 False와 같이 의미론적인 이름들을 붙여서 multiple choice와 같이 취급해주었습니다. 또한 그냥 free 한 form에서는, beam search를 사용하여서 F1 similarity score, BLEU 점수를 사용하여 평가하였습니다.
3. Result
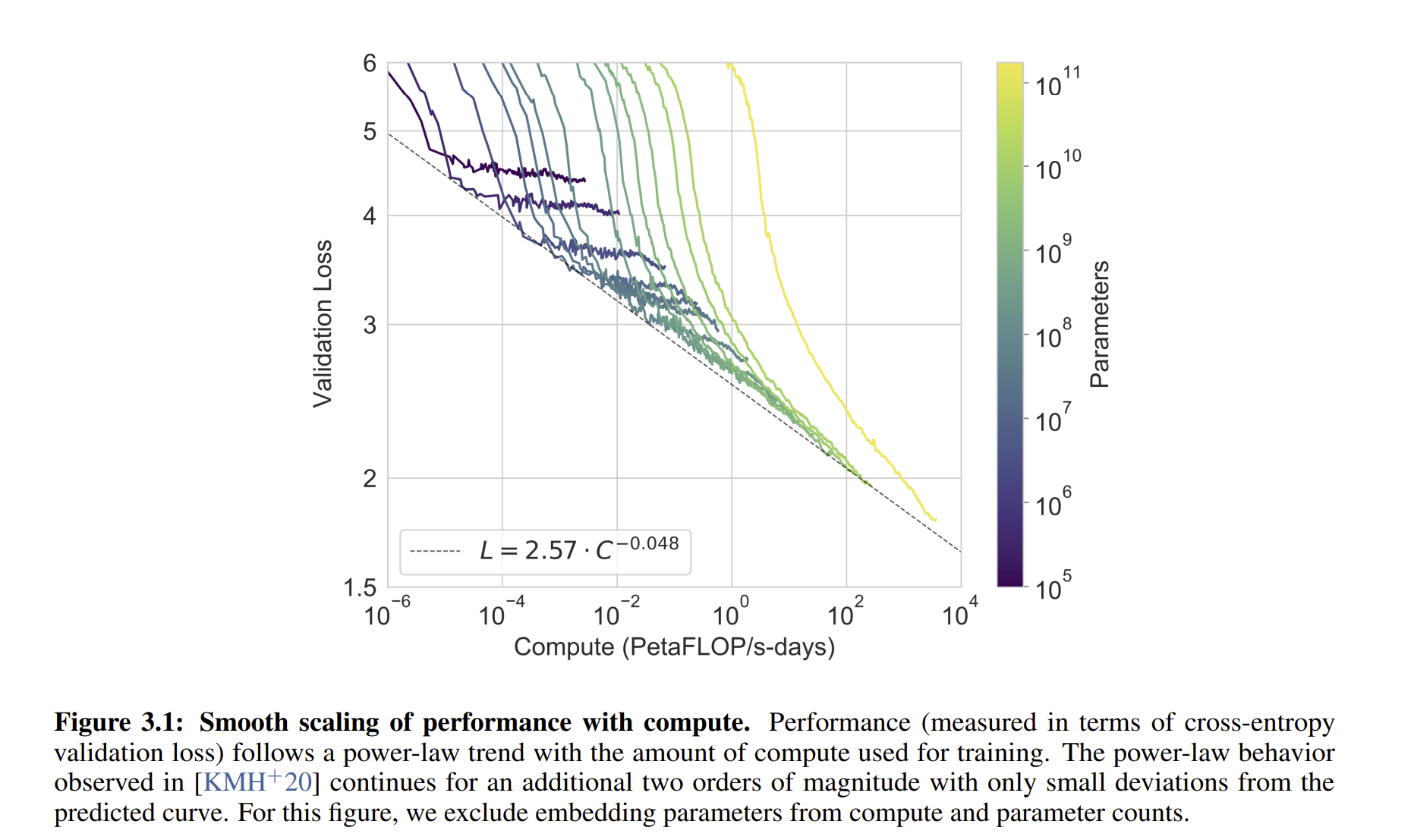
이는 위의 8개의 모델의 validation loss의 차이를 보여주는 것입니다.
3.1 Language Modeling, Cloze, and Completion Tasks
모델을 결과를 어떻게 평가했고, 이를 어떻게 해석할 수 있는지 설명해주는 섹션입니다.
3.1.1 Langauge Modeling
저자는 GPT3를 PTB 데이터를 통해서 zero shot perplexity를 계산하였습니다. PTB 데이터셋은 전통적인 language modeling 데이터셋으로 one shot, zero shot을 구분할 수 없기 때문에 zero shot으로 측정해서 평가하였습니다.
3.1.2 LAMBADA
LAMBADA 데이터셋은 text 에서 long range dependency를 확인하는 용도로 사용하였습니다. - 모델은 문장의 마지막 단어를 예측하도록 되었음. GPT 3는 zero shot learning으로 LAMBADA 데이터셋을 통해 76%의 정확도를 보여주었습니다. SOTA 모델 보다 8퍼센트나 높은 수준입니다.
또한 few shot learning의 flexibility를 평가하는데도 사용이 되었습니다. 앞의 문장의 마지막 단어를 평가하는 것도 하면서, 다음에 어느 문장이 오는 것이 맞는지를 평가하기도 하였습니다. few shot setting으로는 86.4%의 높은 성능을 보여주었고, SOTA 보다 18%나 높은 성능이었습니다.
3.1.3 HellaSwag
HellaSwag 데이터셋은 특히 문맥이 주어졌을 때, 그 다음에 발생할 가장 가능성 있는 사건을 예측하는 작업에 초점을 맞추는 데이터 셋입니다. 인간에게는 판단하기 쉬운 데이터지만 언어 모델이 이를 평가하기는 생각보다 힘듭니다. GPT-3는 one shot learning으로 78.1%의 정확도와 few shot setting으로 79.3%의 정확도를 보여주었습니다.
3.1.4. StoryCloze
StoryCloze 2016 dataset을 통해서 GPT 3가 5문장의 긴 스토리에서 정확한 앤딩을 마칠 수 있는지를 평가한 데이터셋이다. GPT는 zero shot learning으로 83.2%의 높은 정확도와 few shot learning으로 87,7%의 높은 정확도를 보여주었다. 당시 SOTA인 BERT 모델 보다 4.1%나 낮지만 zero host learning은 이전 zero shot learning보다 10퍼센트나 높였다고 한다.
3.2 Closed Book Question Answering
평가는 일반적으로 정보 검색 시스템을 사용하여 관련 텍스트를 찾고, 검색된 텍스트를 바탕으로 답을 생성하는 모델을 학습시키는 방식으로 접근되었습니다. 이러한 설정을 "open-book"이라고 합니다. 반면에 Closed book은 어느 보조 장치에 도움도 받지 않는 설정입니다. 3가지의 데이터셋으로 평가가 되었고, Closed book 상태에서 질문과 답을 받게 되었습니다.
- TriviaQA: zero-shot 설정에서 64.3%, one-shot 설정에서 68.0%, few-shot 설정에서 71.2%의 성능을 달성했습니다. zero-shot 결과는 이미 fine-tuned T5-11B를 14.2% 초과하며, 사전 훈련 중 Q&A 맞춤형 스팬 예측을 사용한 버전을 3.8% 초과합니다. few-shot 결과는 이전의 SOTA 성능을 추가로 3.2% 향상시킵니다.
- WebQuestions: zero-shot 설정에서 14.4%, one-shot 설정에서 25.3%, few-shot 설정에서 41.5%의 성능을 달성했습니다. 이는 fine-tuned T5-11B의 37.4%와 Q&A 특화 사전 훈련 절차를 사용한 fine-tuned T5-11B+SSM의 44.7%와 비교됩니다. few-shot 설정에서 GPT-3는 최신 fine-tuned 모델의 성능에 근접합니다.
- Natural Questions: zero-shot 설정에서 14.6%, one-shot 설정에서 23.0%, few-shot 설정에서 29.9%의 성능을 달성했습니다. 이는 fine-tuned T5 11B+SSM의 36.6%와 비교됩니다.
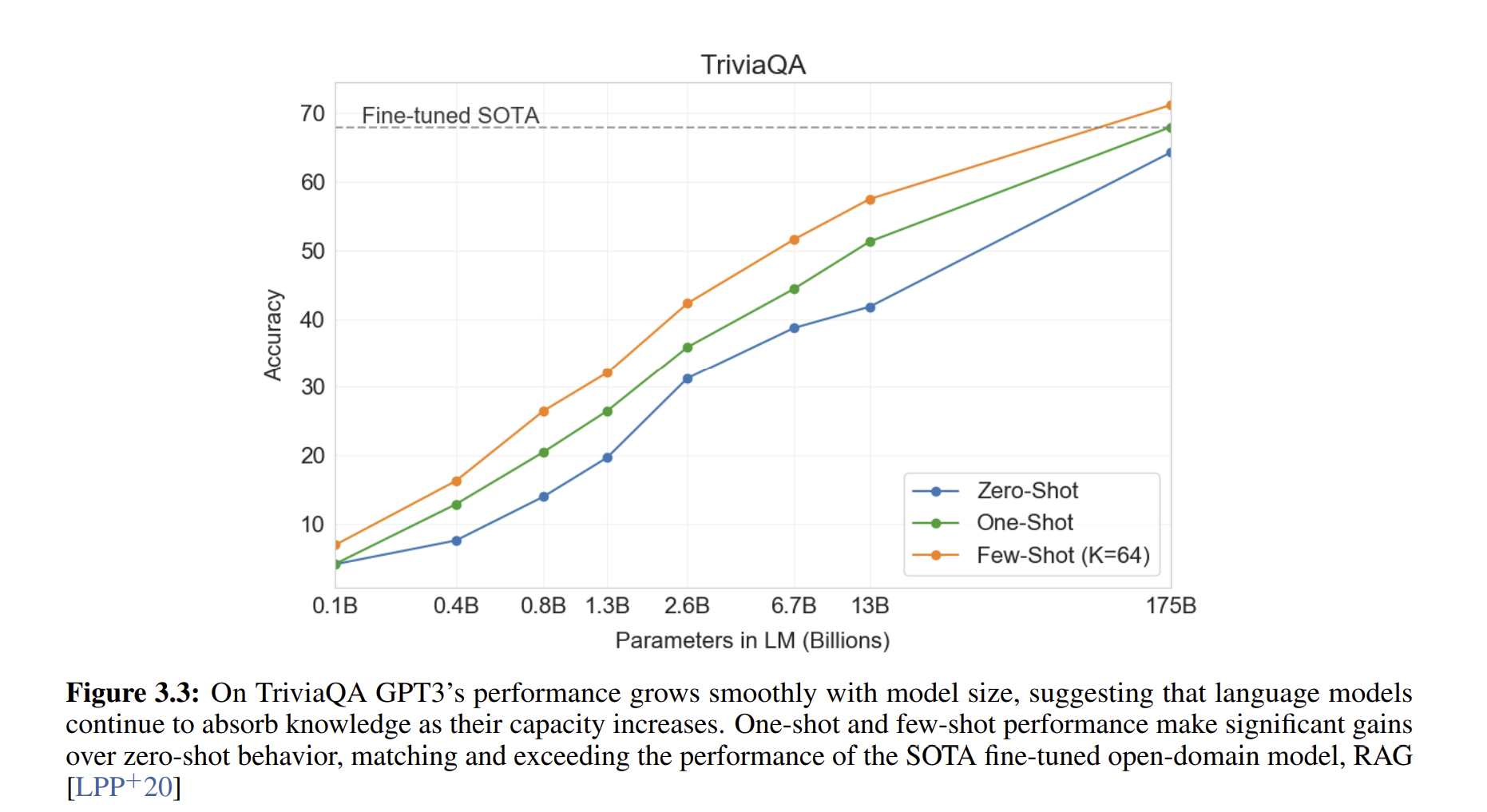
결과적으로, GPT-3의 성능은 모델 크기가 커질수록 매우 부드럽게 증가하며, 이는 모델 용량이 모델에 흡수된 '지식'의 양으로 직접적으로 변환될 수 있음을 반영할 수 있습니다. GPT-3는 fine-tuning을 사용하지 않고도 두 데이터셋에서 closed-book SOTA의 성능에 근접하며, 한 데이터셋에서는 open-domain fine-tuning SOTA와 일치하는 one-shot 성능을 달성합니다.
3.3 Translation
GPT2에서 GPT3로 모델의 크기를 2배 이상 크게 했기 때문에, 모델에서 사용하는 언어의 종류 또한 더 늘렸습니다. pretrain을 할때 사용했던 대부분의 데이터는 Common Crawl + filtering을 거친 데이터입니다. 93퍼센트의 데이터는 영어이고, 나머지 7퍼센트의 언어는 다른 언어입니다.
일반적으로 unsupervised learning에서 MT를 할 때는, 한 언어를 먼저 pretrain에 넣고, 2개의 언어를 연결하는 작업을 가집니다. 반면에, GPT3에서는 자연적으로 모든 언어를 집어 넣어서 학습을 진행했습니다. 그리고 특별하게, 어느 task에도 잘 디자인 되지 않았던 모델은 단일 언어로 집어 넣어서 학습을 하기도 했습니다. 그렇다고 이게 unsupervised learning 방식과 같은 것이 아닙니다. 데이터의 양부터 너무 나도 차이납니다.
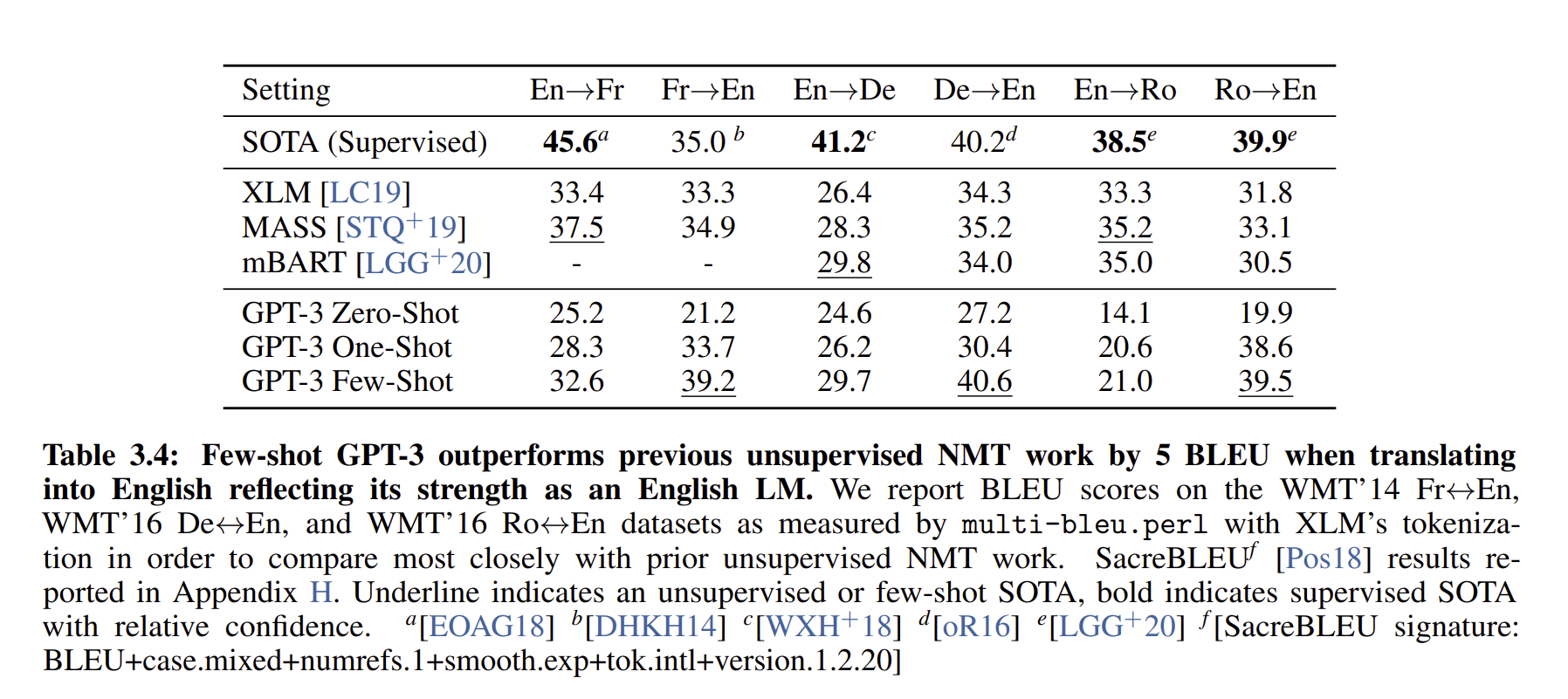
모델 결과를 보면 SOTA 모델이 굉장히 높은 성능을 보이는 것은 맞지만, GPT 3 모델이 Fr→ EN 이나 De→ EN 등 의 분야에서는 더 높은 성능을 보이는 것을 확인할 수 있습니다.

특정 언어에 대해서 높은 성능을 보이기도 했고, 그 외의 언어들에서는 Unsupervised learning보다 더 낮은 성능을 보여주기도 하였습니다.
3.4 Winograd-Style Tasks
Winograd Schemas Challenge는 대명사가 어느 단어를 지칭하는지를 알아 맞추는 classical한 task입니다. 최근 언어 모델은 Winograd dataset에 높은 성능을 보이는 반면, 더 어려운 데이터셋은 Winograde datset에는 아직 인간의 능력 밖에 있다고 합니다. 그래서 GPT-3의 모델을 가지고 Winograd 와 Winogrande 데이터셋을 평가하였습니다.
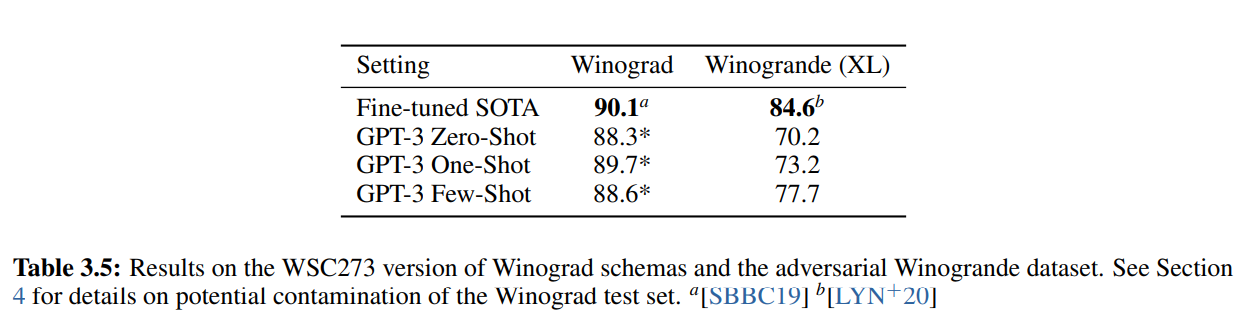
Winograd 데이터셋에서는 GPT 3가 88.3, 89,7, 88.6 % 들의 점수를 얻게 되었습니다. 반면에 더 어려운 데이터셋인 Winogrande dataset에서는, 각각 zero shot, one shot, few shot learning에 70.2%, 73.2%, 77.7%의 정확도를 얻었습니다. 다른 점수들에 비하면 높지는 않은 점수 입니다.
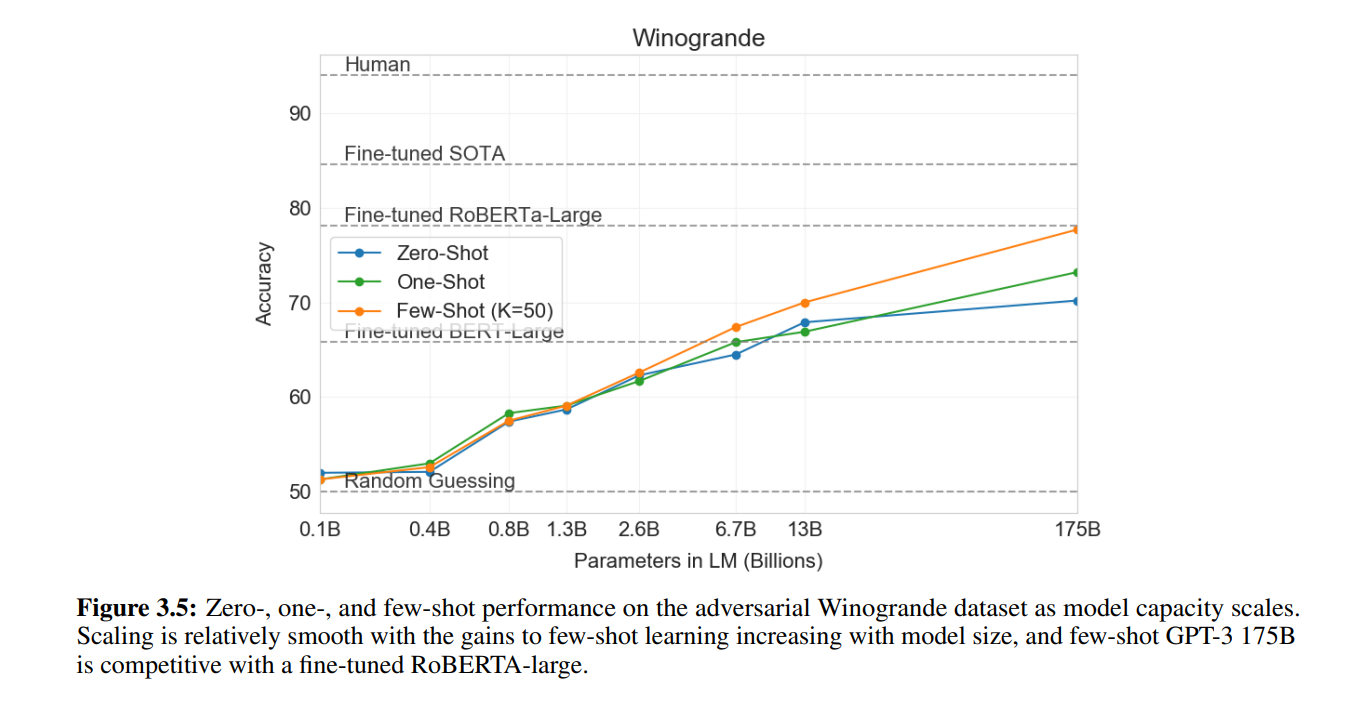
3.5 Common Sense Reasoning
상식 질문에 대해서 어떻게 모델이 답하는지를 평가하는 분야로 PhysicalQA는 physical world가 얼마나 잘 작동하고, 잘 이해하는지를 평가하는 데이터셋으로, GPT-3 에서는 zero,one,few shot learning으로 각각 81.0, 80.5, 82.8%의 성능을 보여주고 있는데, 이는 현재 SOTA 모델 79.4%의 정확도 보다 높은 성능을 보여줍니다.
ARC (AllenAI Reasoning Challenge)은 ****3학년부터 9학년까지의 과학 시험에서 수집한 다지선다형 질문들로 구성된 데이터셋입니다. "Challenge" 버전은 단순한 통계적 또는 정보 검색 방법으로는 정답을 찾을 수 없는 질문들로 필터링되어 있습니다. "Easy" 버전은 언급된 기준 접근 방식(통계적 또는 정보 검색) 중 하나라도 정답을 찾을 수 있는 질문들로 구성되어 있습니다.
- Challenge 세트:
- Zero-shot: 51.4%
- One-shot: 53.2%
- Few-shot: 51.5%
- 이는 UnifiedQA의 RoBERTa 기반 모델(55.9%)에 근접하는 성능입니다.
- Easy 세트:
- Zero-shot: 68.8%
- One-shot: 71.2%
- Few-shot: 70.1%
- 이는 RoBERTa 기반 모델의 성능을 약간 상회합니다.
- UnifiedQA가 ARC 데이터셋에서 GPT-3의 few-shot 결과보다 Challenge 세트에서 27%, Easy 세트에서 22% 더 높은 성능을 보여줍니다.
OpenBookQA는 일반적인 지식과 추론 능력을 평가하기 위한 다지선다형 질문으로 구성된 데이터셋입니다. GPT-3는 zero-shot에서 few-shot 설정으로 상당히 향상되었지만, 전체 SOTA에 비해 여전히 20점 이상 뒤처져 있습니다. GPT-3의 few-shot 성능은 리더보드의 BERT Large 기반 모델과 유사합니다.
PIQA 데이터셋은 물리적 상호작용에 대한 이해를 평가하기 위해 설계된 데이터셋으로, 모델이 물리적 세계에서의 다양한 상호작용을 얼마나 잘 이해하고 있는지를 평가합니다. GPT-3는 모든 평가 설정에서 PIQA 데이터셋에서 SOTA를 달성합니다.
3.6 Reading Comprehension
저자는 5개의 데이터셋을 바탕으로 GPT 모델을 평가하였고, 대화 내용과 질문을 얼마나 이해하는지를 평가하였습니다. CoQA와 QuAC 데이터셋에서 best performance를 보여주었고, DROP에서는 BERT의 baseline 모델을 이겼습니다.
3.7 SuperGLUE
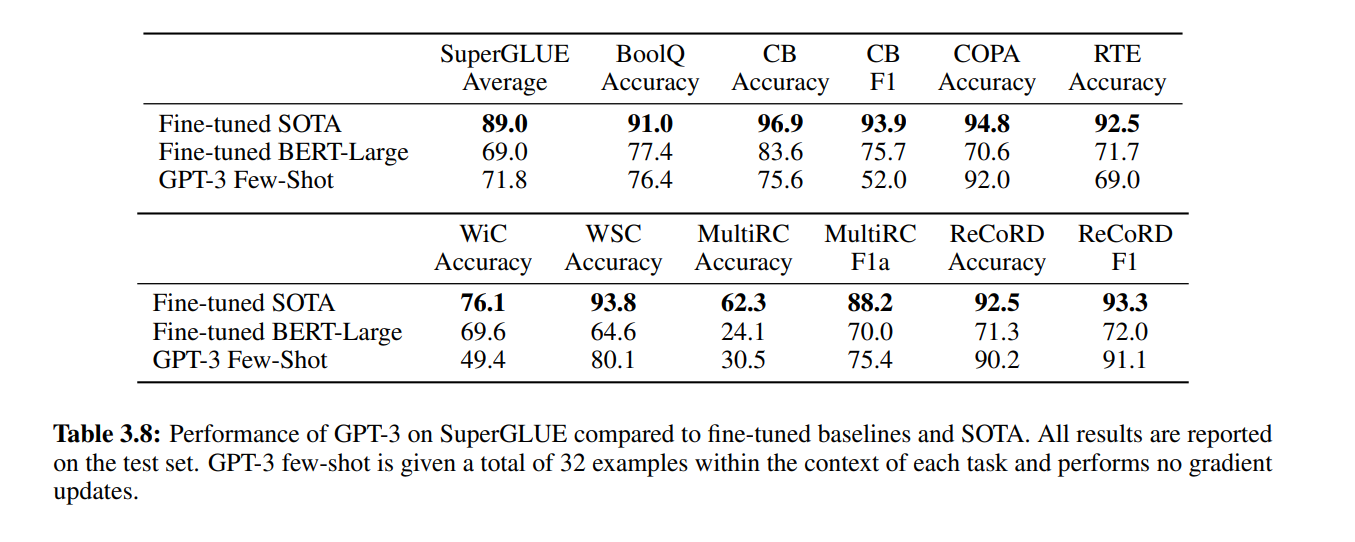
SuperGLUE는 한 데이터셋으로 모든 테스크를 평가할 수 있는 데이터셋입니다. 결과는 아래와 같습니다. COPA와 ReCoRD: GPT-3는 one-shot 및 few-shot 설정에서 거의 SOTA 성능을 달성했습니다. COPA에서는 리더보드에서 2위를 차지했으며, 1위는 11억 파라미터를 가진 T5 모델에 의해 차지되었습니다. WSC: Few-shot 설정에서 80.1%의 성능을 보여 상대적으로 강한 성능을 나타냈습니다. 원래의 Winograd 데이터셋에서는 88.6%의 성능을 보였습니다. BoolQ, MultiRC, RTE: 성능은 합리적으로, fine-tuned BERT-Large와 대략 비슷한 수준입니다. CB: Few-shot 설정에서 75.6%의 성능을 보여 생명의 징후를 보입니다. WiC: Few-shot 성능이 49.4%로, 무작위 추측 수준에 불과합니다. 이는 GPT-3가 두 문장이나 문구를 비교하는 작업에서 약할 수 있음을 시사합니다.
8개의 task 중에서 4개의 task가 BERT-LAREG 모델을 이겼으며, 2개의 task에서는 11억개의 파라미터를 가진 모델에 근접한 성능을 보였습니다.
3.8 NLI
NLI는 두 문장 사이의 관계성을 판단하는 모델입니다. 원래, 2개 또는 3개의 분류 문제로 2번째의 문장이 첫 번째 문장 이후로 오는 것이 맞는 지를 평가하는 것입니다. SuperGLUE도 이러한 데이터셋을 포함하고 잇고, GPT 3 에서는 좋은 성능을 보여주었습니다. 그러나 few shot learning에서는 그다지 좋은 성능을 내지는 못했습니다. 그리고 ANLI 데이터셋으로 평가를 진행하였는데, 결과는 그다지 좋지 못했습니다.
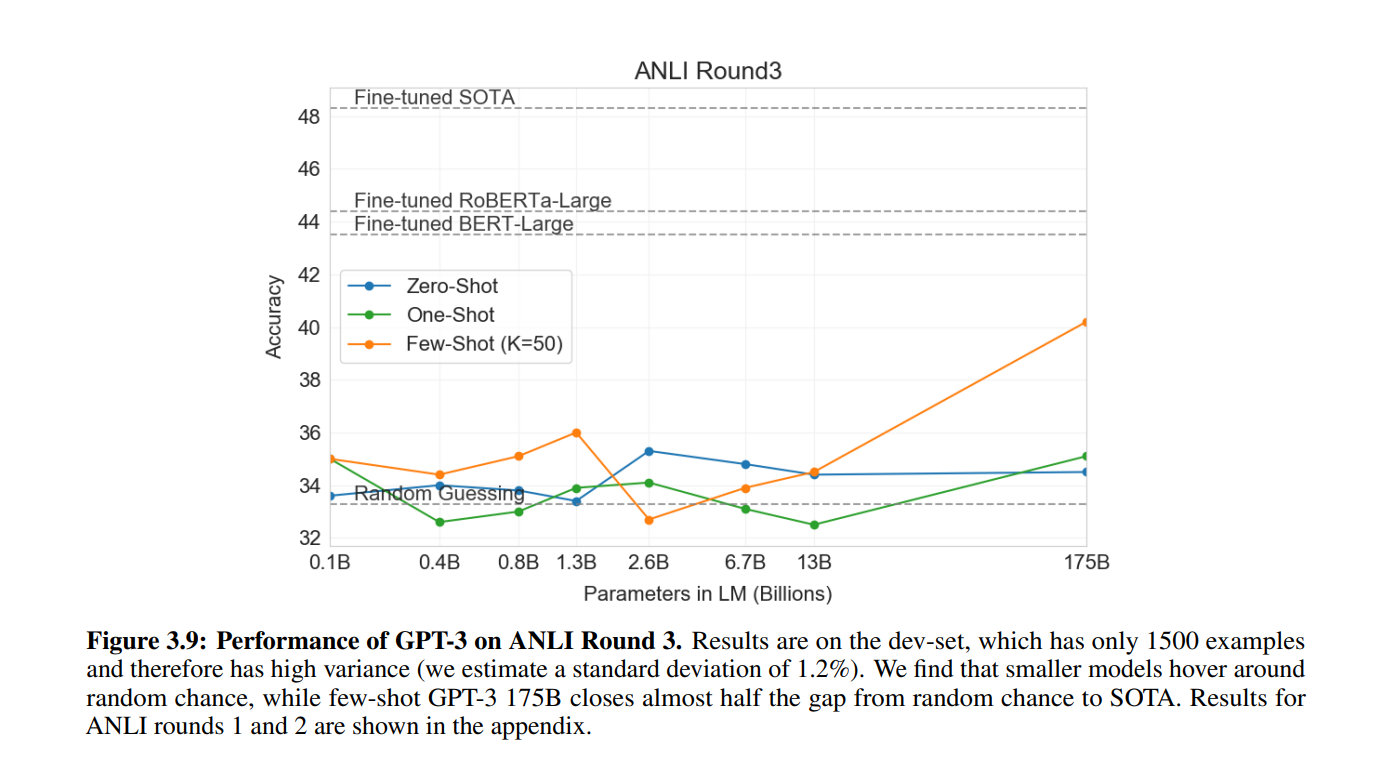
4. Measuring and Preventing Memorization Of Benchmarks
Section 3에서는 모델의 각 Task 별 성능을 확인할 수 있었습니다. Section 4에서는 모델 학습에서 사용하는 train dataset이 test 데이터셋과 겹칠 수도 있다는 contamination을 언급하면서 시작이 됩니다. 인터넷에서 수집한 대규모 데이터셋을 사용하여 모델을 훈련시키면, 벤치마크 테스트 세트와 훈련 데이터 사이의 오염이 발생할 가능성이 있습니다.
그렇기에 인터넷 규모의 데이터셋에서 테스트 오염을 정확히 탐지하는 것은 신규 연구 분야로, 아직 확립된 최고의 방법론이 없습니다. 데이터셋의 오염 문제는 점점 중요해지고 있으며, 이를 주의 깊게 다루어야 합니다.
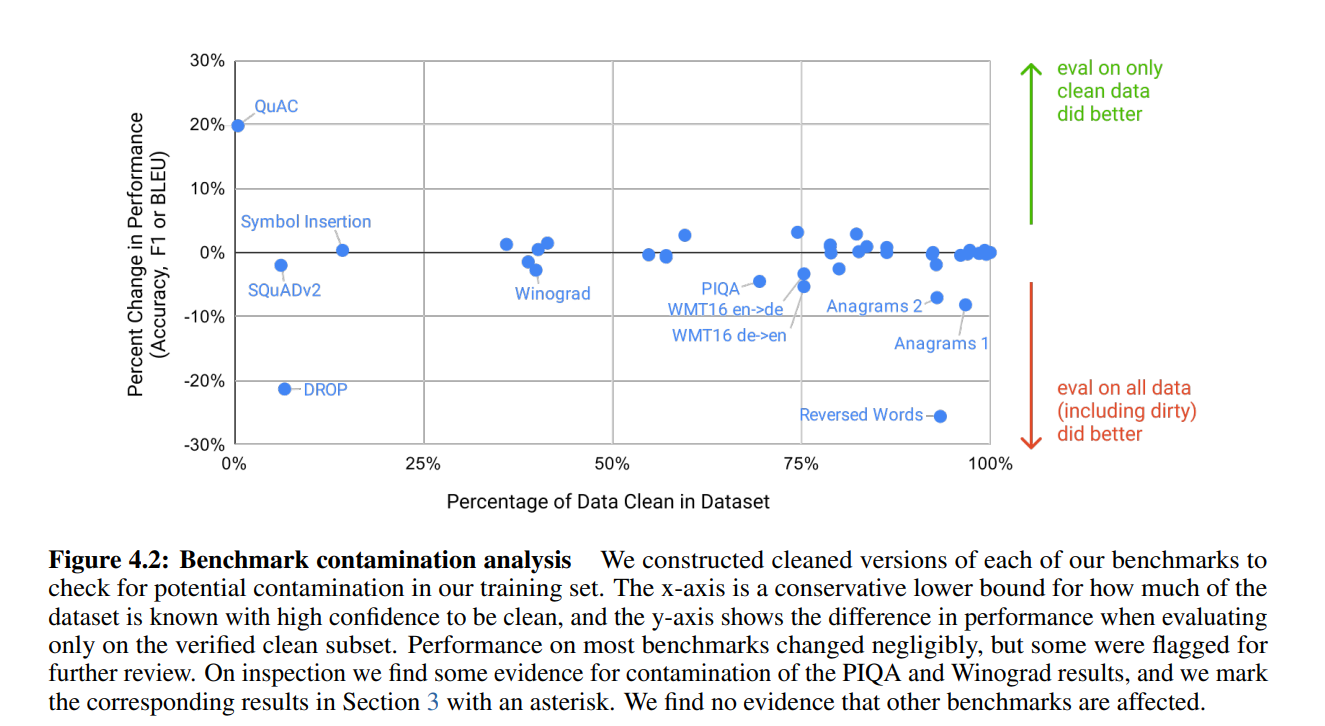
과거 GPT2 논문에서는 Common Crawl 데이터를 사용한 초기 연구에서는 훈련 문서와 평가 데이터셋 간의 중복을 탐지하고 제거했습니다. GPT-2는 사후 중복 분석을 실시하여 비교적 좋은 결과를 얻을 수 있었습니다.
저자는 중복된 데이터셋을 어떻게든 해결하기 위해서 연구팀은 '깨끗한' 벤치마크 버전을 생성하여 오염이 결과에 미치는 영향을 조사했습니다. 이 '깨끗한' 버전은 13-gram 이상 중복되는 예시를 제거하여 생성되었습니다. 하지만 결과 대부분이 그렇게 큰 영향을 주지 못하여 큰 상관관계를 보지는 못했습니다.
5. Limitation
아무리 좋은 문장들로 모델을 학습시켰지만, text synthesis나 몇 NLP Task에는 문제가 있습니다. 특히 common sense physics 분야에 데이터 학습이 잘 안되었다는 점, performance가 큰 문제가 있지 않았다는 점을 볼 수 있었습니다. 또 구조적으로 단일 방향 학습인 점, Few-shot learning이 scatch에서 학습이 되었는지 여부, bias 해석 문제 등 다양한 문제를 가지고 있습니다.
그래서 저자는 이후에 GPT-3와 같은 양방향 모델을 적용하거나 모델 축소를 하는 등의 방향성에 대해서 언급해주고 있습니다.
한 줄로 요약하면
GPT-3는 1750억개의 파라미터를 이용한 Few shot learning한 모델로 돈을 쏟아부어서 만든 모델이다.
