[논문 리뷰] SCOPA : Soft Code - Switching and Pairwise Alignment for Zero-Shot Cross - Lingual Transfer
자연어처리 논문 리뷰
Preface

1. Introduction
각 언어가 pretrained 을 되면서 독립적으로 학습이 되지만, 언어들 사이에는 ‘common feature’ 이 같은 weight들을 공유하면서 학습이 진행됩니다. 이러한 transfer을 더 enhance 하기 위해서, XLM-R은 Common CRawl Corpora에서 100개의 언어로 pretrained 하였고, resource-rich language 에서 resource poor langauge로 supervised learning을 하며 학습이 진행되었습니다.
cross lingual transfer을 더 enhance 하기 위한 다른 방향은 code-switching 입니다. code switching 은 문장의 어느 단어를 다른 언어로 번역하는 것입니다.
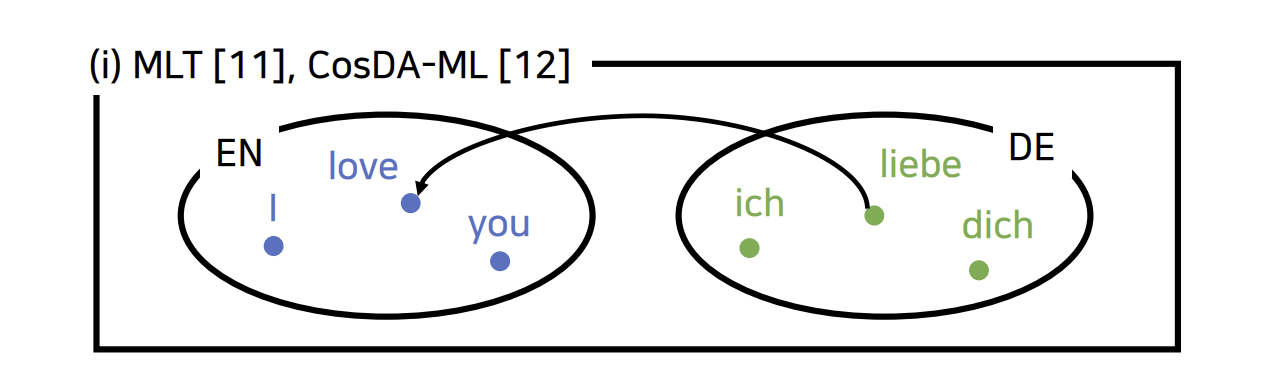
예를 들어서, 영어의 love와 독일어의 liebe는 ‘사랑한다’라는 같은 뜻이 있습니다. 이 과정은 embedding을 align 하는데 도움을 주는 과정으로 언어가 아무리 다라도, 동일어의 같은 구조는 각각 비슷하게 나열되어 있습니다.
저자는 여기서 code - switching에 대한 2가지 제안을 합니다.
- word embedding은 language specific signal을 가지고 있다는 점.
- 여기서 language specific signal은 다른 언어로 번역을 하게 되면, signal을 잃게 된다는 점.
- 그리하여 저자는 source와 target word embedding을 섞어서 사용하자는 점.
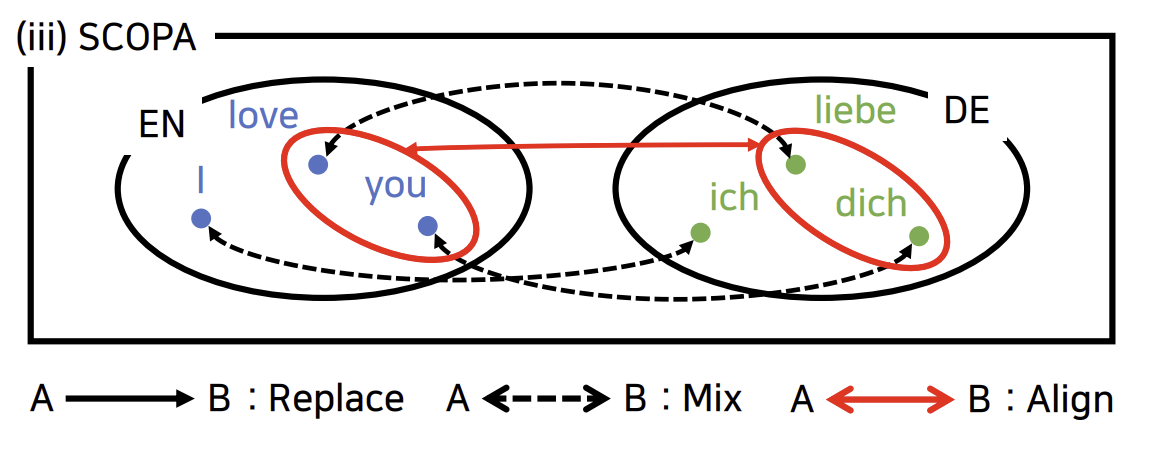
- SCOPA - 새로운 language alignment 제안
- 예를 들어서, apple은 사과도 있지만 IT 기업 이름도 있어서 이들이 매칭 안되어왔엇음.
- 반면에 apple과 tree는 엄청 구분 잘 됨.
- 그래서 pairwise alignment를 제안하게 됨.
2. Related Works
Zero - Shot Transfer Learning
Zero shot Transfer은 document classification, dependency parsing과 같은 분야에서 low resource target language를 위한 성공을 이루었습니다. 이런 방식들은 high-resource language를 잘 transfer 하는 것이 목적이고, 저자가 제안한 alignment 방식들은 zero shot transfer을 더 잘 되게 하였습니다.
Mixed Representation
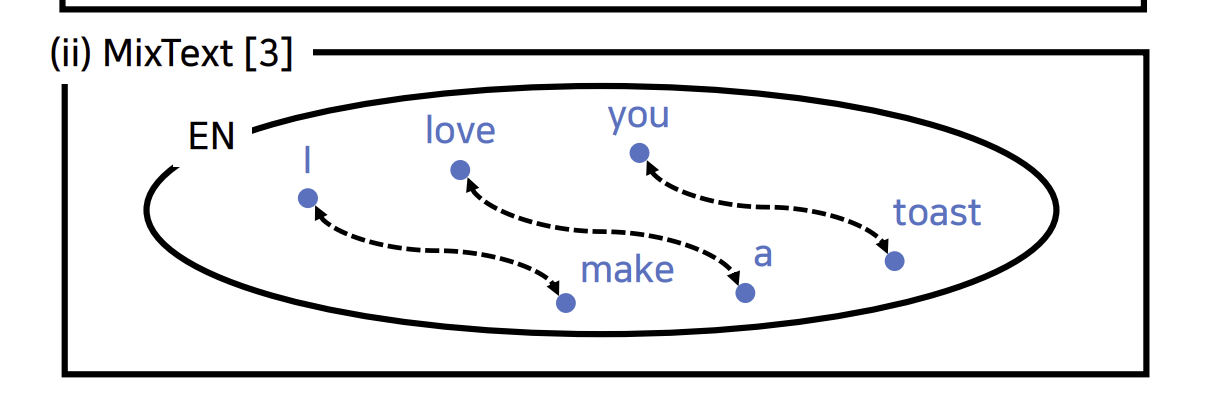
MixUp은 2개의 input data를 섞어서 image에 새로운 데이터셋을 만들어낸 데이터셋입니다. 이 방식과 비슷하게, MixText는 2개의 다른 문장들을 섞어서 text classification task에 활용하는 데이터셋입니다. 저자는 이와 비슷한 방법을 통해서 언어를 mixed 시키는 방법을 제안하였습니다.
Alignment
MUSE, RC-SLS, mBERT와 같이, Multilingual Embedding들은 inital alignment로 취급되었습니다. 하지만 misalignments들이 종종 cross lingual transfer들을 방해하기도 합니다. 이러한 misalignment들을 해결하기 위해서, 여러 가지 방법이 제안되었습니다.
먼저 CLBT는 additional aligning layer를 넣어서 zero shot adaption을 improve 하였습니다. 그들은 target language의 context embedding을 BERT로 부터 배워서 source language에 embedding을 하였고, pre-trained 된 input으로 contextual embedding을 aligned 하였습니다.
반면에 target language를 바로 code swtiching sentence를 gernerating 함으로써, embedding을 사용하는 방법도 고안되었습니다. 즉 training dataset에 있는 단어를 target language로 바꾸어 주는 것입니다.
3. Proposed Techinque
3.1 Soft Code Switching
Code switching은 언어 임베딩 사이의 misalignment를 완화하기 위해 고안된 방법입니다. 그러나 이러한 word replacement는 언어의 specific 한 signal을 잃을 수 있기 때문에 저자는 soft하게, code switched sentence를 original sentence랑 섞어서 하는 것을 추천하였습니다.
Soft Code Switching
문장 (s = langauge)이 주어졌을 때, subset word 를 선택해서 T를 번역 해서 code switched sentence 을 얻는 것이 목표입니다. 여기서 구성되어 있습니다. multiple target word가 선정이 되면, randomly 하게 선택합니다.
예를 들어서, 언어에 대해서, 을 의 word embedding라고 가정을 하고, 을 input hidden state라고 합니다.
이제 문장별로 섞기 위해서, 이라고 쓰는 것 대신에, mix를 한 상태로 넣을 것입니다.
와 를 의 비율을 조합하여 를 만들어 내는 것입니다. 여기서 의 값은 beta distribution 로 설정하였습니다.
Normalizing Word Embeddings
mBERT와 GPT 같은 언어 모델들은 subword embedding을 사용하는 것이 일반적이기 때문에, length of source와 target word embedding은 다를지도 모릅니다.(사용한 단어의 개수가 문장마다 다르기 때문에) 그래서 2가지 방법을 통해서 normalization을 하게 됩니다.
- n-to-1은 subword embedding의 weight sum을 이용하는 것입니다. 여기서 weights는 length of subword token으로 구성됩니다.
- 1-to-1은 소스 언어의 단어가 서브워드로 분해되었을 때, 가장 의미가 가까운 서브워드 하나만을 선택하여 해당 서브워드의 임베딩을 사용합니다
그래서 식을 다음과 같게 업데이트를 하게 됩니다.
3.2 Pairwise Alignment Objective
저자는 더 좋은 pairwise alignment 기술을 제안합니다. 먼저 언어들 사이에 word pair alignment를 보충시키기 위해, auxiliary loss function을 사용합니다.
Pairwise Alignment Loss
저자는 의 워드 임베딩 쌍과 target language corresponding pair들 사이의 pairwise alignment를 improve를 목표로, 계산을 합니다.
source language에서는 Asahi et al 데이터셋에서 word pairs를 사용하였고, MUSE dictionary를 이용한 word로 교체를 하였습니다. 만약 multiple corresponding counterparts가 존재하면, dictionary에서 averaged embedding을 이용하였습니다.
Aligning the Words Not in the Dictionary
만약에 단어가 dictionary에 없다면 어떻게 될까요? 그래서 저자는 auxiliary layer 를 가지고 source language의 target word embedding으로 근사를 진행하였습니다. 이 방식으로 더 많은 단어를 사용해서 alignment를 향상시킬 수 있었습니다.
그렇다면 를 최대화하기 위해서는 어떠할까요? 아래와 같은 sum function에서 를 제일 크게 만드는 값으로 목표를 잡았습니다.
그리하여 업데이트 된 식은 아래와 같습니다.
3.3 Cost-Effective Mixed Representation
MixText에 영감을 받아, language model의 representation을 어떻게 mix 할 것인지에 대해서 조사를 하였습니다.
각 파라미터에서 multiple time train을 할 필요가 없기 때문에, 값을 찾는 것이 굉장히 효율적입니다.
4. Experiments
4.1 Setup
SCOPA의 효율성을 판단하기 위해, PAWS-X 와 MLDoc를 사용하였습니다. 둘다 똑같은 Batch size와 learning rate를 사용하였습니다. MUSE에서 dictionary를 이용하여 code switching을 활용하였습니다.
4.2 Effectiveness of SCOPA
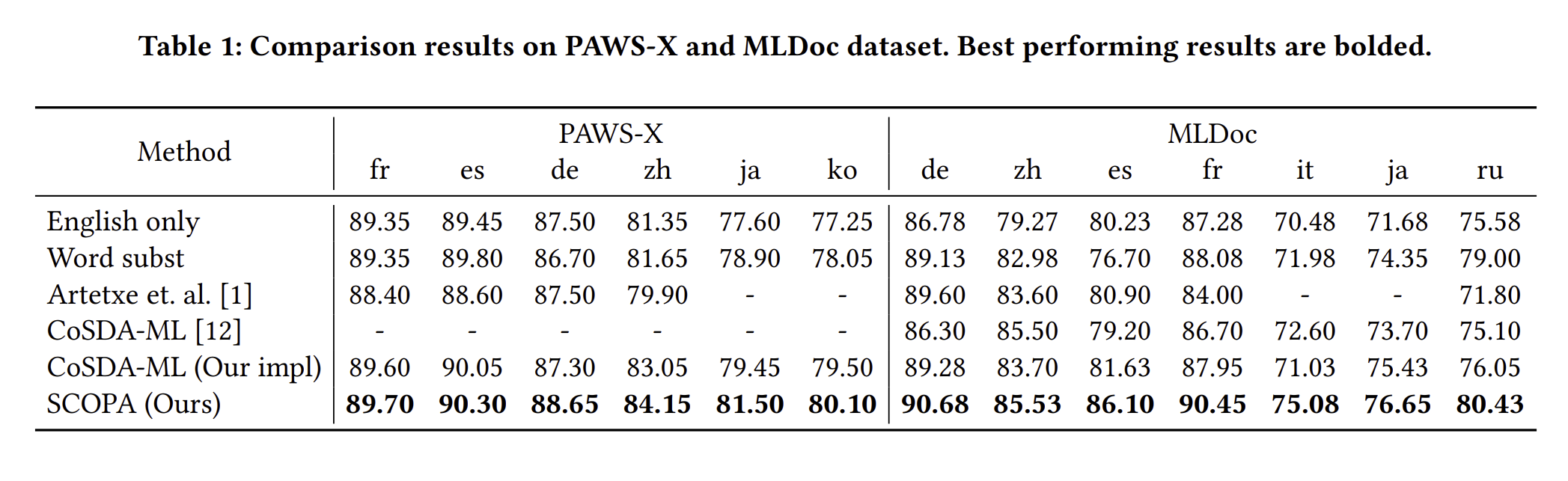
SCOPA의 효율성을 보여주기 위해서, English only, Word subsistitution, CosDA-ML 3가지 방식으로 비교를 하였습니다. 성능을 보게 되면, SCOPA의 성능이 모든 언어에서 높다는 것을 확인할 수 있습니다.
위 결과는 naive word substitution에 어떤 한계점이 있다는 것을 보여주며, SCOPA는 이런 점들을 해결하기 좋은 모델임을 알 수 있습니다. 게다가 SCOPA는 pairwise alignment metric 자체가 naive 하게 word substitution을 하는 것보다 성능이 더 좋게 될 수 있다는 점을 알게 됩니다.
4.3 Ablation Study
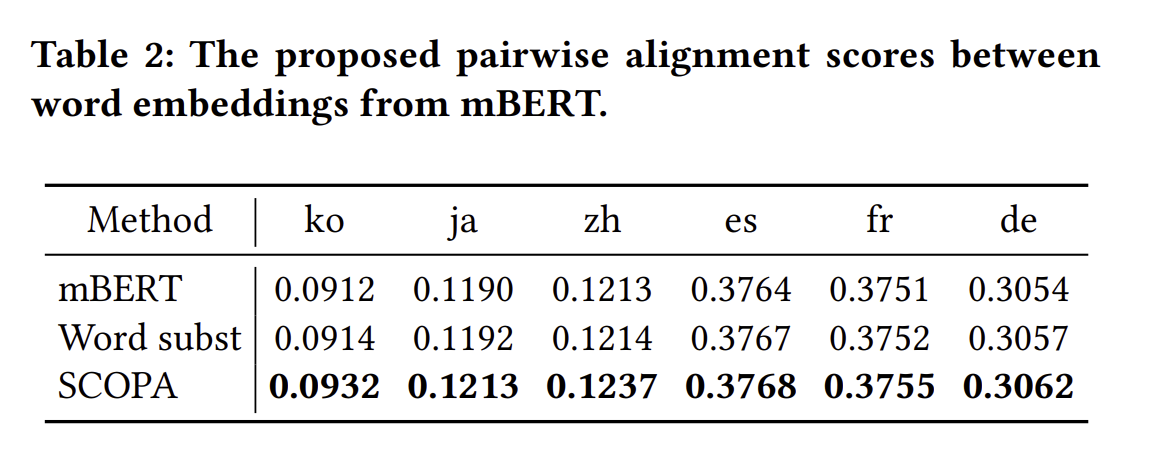
pairwise alignment 의 효율성을 보여주기 위해, layer 의 점수를 매겨 결과를 보여줍니다.
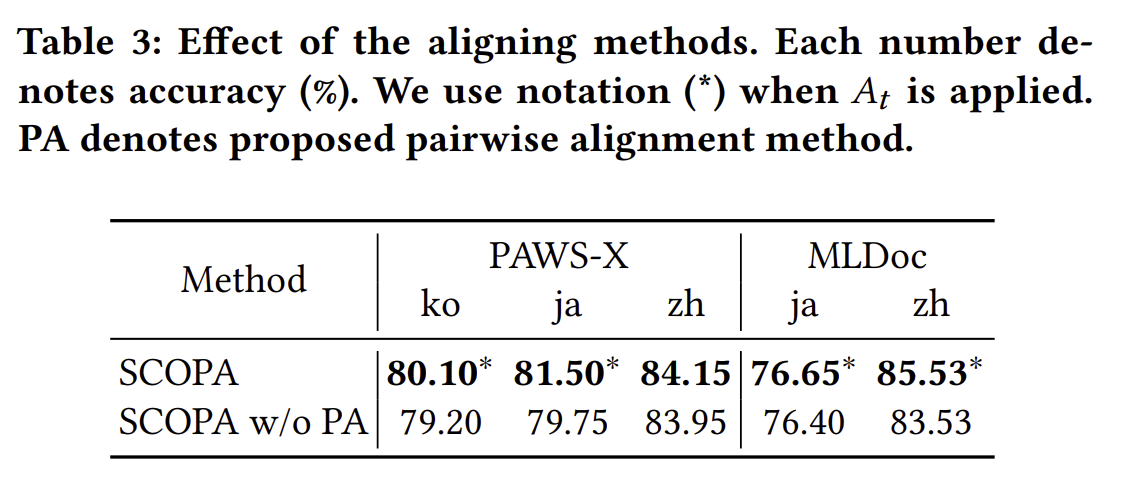
Table 3 에서는 PA를 적용하냐 안하냐에 대한 결과로 적용을 한 결과가 더 좋았음을 확인할 수 있습니다.
5. Conclusion
위 논문은 cross lingual transfer 의 효율성을 증진시키기 위해 고안된 논문으로, mBERT와 같은 cross lingual model들이 misalignment와 같은 문제가 있을 것이라고 가정하여 작성된 것입니다. 그래서 저자는 2가지 방법으로 이를 해결하였습니다. 첫 번째, alignment metric을 제안하였고, 2번째는 softly 하게, original sentence와 embeddnig 한 것들을 조합하는 방식입니다.
한 줄로 요약하면
SCOPA는 code switching에서 original text와 code switchined text를 섞어서 embedding을 사용하였고, 단어간의 연결고리를 만들어서 pairwise alignment를 통해 성능을 더 올린 모델이다.
