preface

1. Introduction
Zero shot learning을 통해서 low source language을 살릴 수 있는 방법이 점점 고안되고 있습니다. 특히 M-BERT는 소말리아어나 위구르언어와 같이 데이터가 부족한 언어들 또한 살릴 수 있다는 것이었습니다. 하지만 M-BERT가 그렇다고 모든 언어를 커버할 수 있다는 것은 아니고, 오직 104개의 언어 이들은 전체 언어의 3퍼센트도 안됩니다.
그리하여 저자는 새로운 언어를 포함한 데이터셋을 학습시키는 M-BERT를 만들고자 하였는데, 이는 너무 비싸고 시간 낭비이기에, EXTEND 라는 방법을 제안합니다. EXTEND는 M-BERT의 vocab을 늘려서 새로운 언어를 수용하고, 이를 pretraining에 넣는 방법입니다.
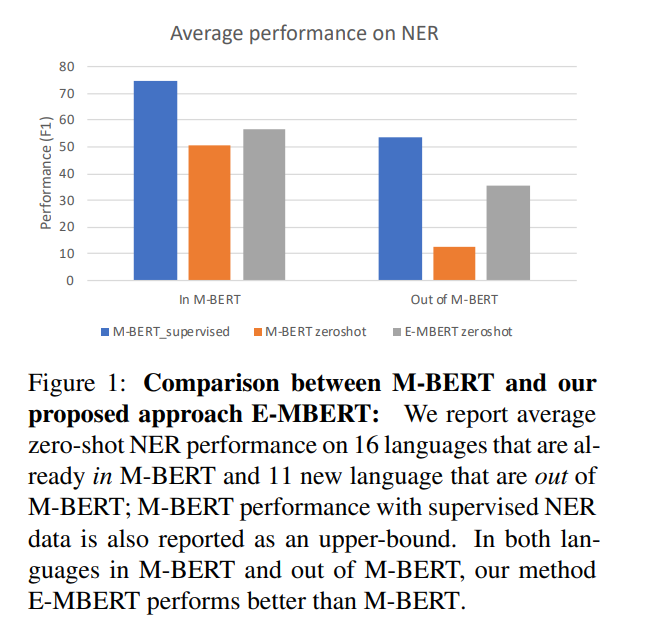
Zero shot learning으로 학습을 했을 때는, M-BERT에 포함된 언어들은 굉장히 높은 성능을 보이지만, 다른 언어들은 포함되지 않아 높은 성능을 보이지 않았습니다. 반면, E-MBERT는 F1 스코어가 엄청 내려가지는 않았습니다.
그래서 저자가 제안한 방법을 3가지로 정리를 하면
- M-BERT에 새로운 언어를 넣어서 EXTEND하기
- M-BERT에 맟나가지로 있지 않았던 언어들의 성능을 올려는 것을 보여주기
- EXTEND 방식이 대부분의 케이스에서 B-BERT보다 더 높은 성능을 보인다는 것을 보여주기.
2. Related Work
당시에는 BICCA, LASER, XLM과 같은 데이터셋을 통해서 Cross lingaul 데이터를 supervised learning을 진행해왔습니다. 하지만 현재 저자가 제안하는 방법은 Zero shot learning으로 어떤 supervision도 필요하지 않습니다.
더불어 mBERT는 low source language에서 mono BERT보다 더 높은 성능을 보이는 것이 확인되었습니다. 단일 클라우드 TPU에서 7시간 미만의 학습으로 새 언어를 모델에 추가할 수 있는 방식은, 기존의 모델을 처음부터 다시 학습하는 것에 비해 시간과 비용을 크게 절약할 수 있는 효율적인 접근법
3. Background
3.1 Multilingual BERT (M-BERT)
M-BERT는 Transformer 기반의 언어 모델로, Wikipedia text에서 104개의 언어를 기반으로 pretrained 한 모델입니다. 주 언어를 바탕으로 학습이 진행이 되었고, target language가 얼마나 성능이 좋은지를 평가하는 모델로 사용되고 있습니다.
3.2 Bilingual BERT (B-BERT)
B-BERT는 M-BERT와 같은 방식으로 학습이 되었고, 언어를 오직 2개만 사용했다는 점이 다릅니다(영어, target language).
4. Our Method : Extend
이번 Section에서는 EXTEND를 어떻게 진행시켰는지에 대해서 알아보겠습니다. 먼저 M-BERT의 vocab을 , extended 새로운 vocab을 라고 정의합니다. 일단 를 3만으로 고정을 하고 학습 방법은 아래와 같습니다.
- Vocab, Encoder, Decoder를 늘려서 를 학습시키기. 즉 로 설정을 하고, dimension을 에서 로 확장을 시킵니다.
- M-BERT의 초반 가중치를 계속 새로운 가중치로 학습을 시킵니다.
- 그리고 target 언어의 monolingual data를 pretraining을 시키고, 이렇게 학습된 모델을 E-MBERT라고 정의합니다.
5. Experiments
5.1 Experimental Settings
데이터는 LORELEI 데이터셋에서 가져왔으며, BERT의 토큰화 방법을 사용하여 전처리되었습니다.K-교차 검증을 적용하여 성능을 추정합니다. 각 폴드는 다른 폴드에서 훈련된 모델로 평가되며, 평균 F1 점수가 보고됩니다.
AllenNLP와 표준 Bi-LSTM-CRF 프레임워크를 사용합니다. 성능 지표로는 NER에서 보고된 점수는 다른 랜덤 시드를 사용한 다섯 번의 실행에 걸쳐 평균낸 F1 점수입니다.
EXTEND 학습 설정으로는 배치 크기 32, 학습률 2e-5로 설정하고, 500K 반복 동안 학습합니다. B-BERT 학습 설정으로는 배치 크기 32, 학습률 1e-4로 설정하고, 2M 반복 동안 학습합니다.
5.2 Comparing E-MBERT and M-BERT
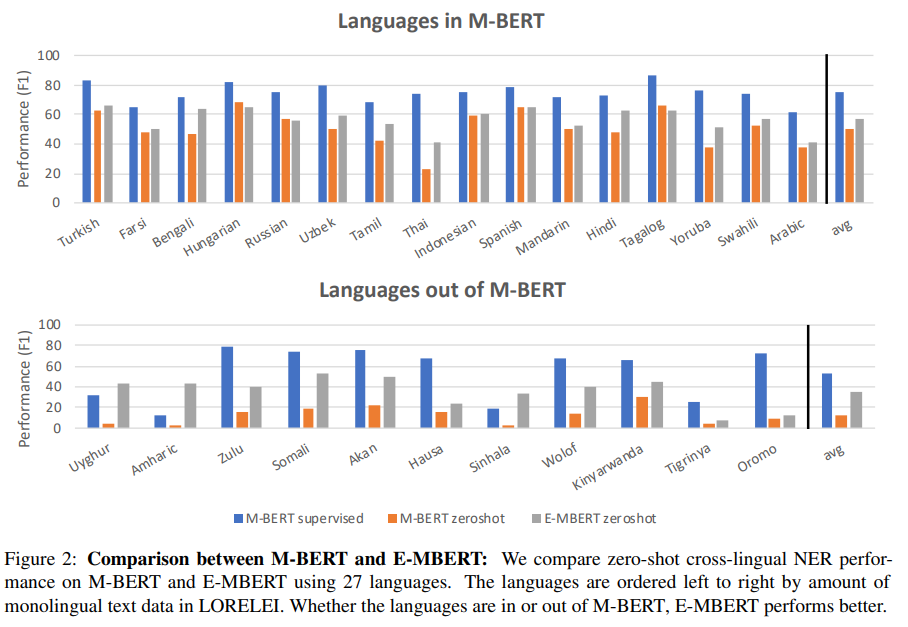
결과를 보게 되면, 대부분의 모델이 EXTEND를 거쳤을 당시에, 성능이 더 좋아진 것을 확인해볼 수 있습니다. 특히 기본의 M-BERT보다 데이터를 더 추가했을 때 결과가 더 좋은 것을 알 수 있었습니다.
그 이유로는 3가지가 있습니다.
- 목표 언어의 어휘 크기 증가: 대부분의 언어는 영어에 비해 상대적으로 작은 데이터셋을 가지고 있기 때문에, M-BERT 내에서의 어휘 크기도 더 작습니다. EXTEND 방법을 통해 이 문제를 해결함으로써, 목표 언어에 대한 모델의 어휘를 확장합니다. 모든 언어에 대해 더 큰 어휘 크기를 가진 단일 M-BERT 모델을 훈련하는 것은 비현실적이므로, 이 접근 방식은 어휘 크기의 한계를 극복할 수 있었습니다.
- 추가 monolingual language data: 목표 언어의 추가 monolingual 데이터는 유익할 수 있습니다. 이는 모델이 해당 언어의 더 많은 예시를 학습함으로써, 그 언어의 문맥적 뉘앙스와 구문을 더 잘 이해할 수 있게 해줍니다.
- 목표 언어에 대한 더 집중된 최적화: E-MBERT는 마지막 500K 학습 단계 동안 목표 언어에서 잘 수행되도록 최적화됩니다. 이는 모델이 특정 언어의 특성과 요구 사항에 더 잘 맞춰지게 함으로써, 해당 언어에 대한 성능을 개선합니다.
5.3 Extra vocabuluary
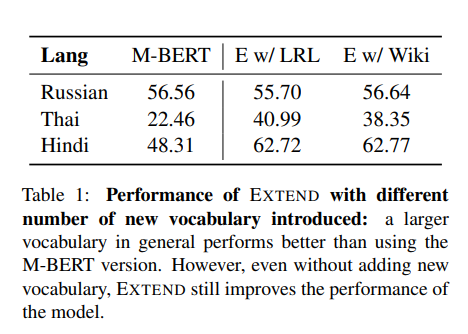
데이터셋은 위와 같이 확장이 되었고, 데이터셋이 많아짐에 따라 모델의 성능도 올라감을 확인할 수 있습니다.
5.4 Extra data
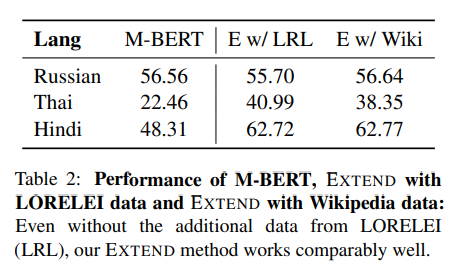
태국어와 힌디어의 성능이 엄청나게 올라감을 확인할 수 있습니다.
5.5 Comparing E-MBERT and B-BERT
두 모델을 비교하기 위해서 같은 문장에 대해서 번역을 어떻게 하는지 확인을 하는 것입니다. 일단 M-BERT에 포함되지 않은 언어를 초점으로 해서 E-MBERT가 얼마나 큰 성능지표를 가지는 지 확인하는 것입니다.
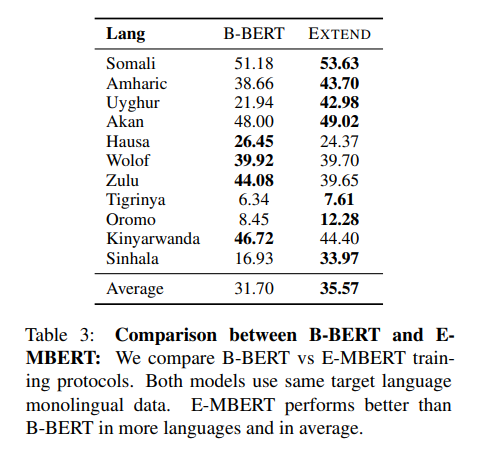
결과를 확인해보면, E-MBERT가 B-BERT보다 압도적으로 성능이 좋은 것을 확인해볼 수 있습니다. 게다가 B-BERT는 2M step을 학습을 하였지만 E-MBERT는 500k step으로 학습을 진행했습니다. 이는 즉, 단순하게 monolingual data로 학습을 진행한다고 해도, E-MBERT가 더 성능이 좋다는 것을 확인해볼 수 있습니다. 예로 들어서, Sinhala와 Uyghur의 경우에, Tamil 과 Turkish와 같은 유사한 언어들이 E-MBERT의 성능을 더 높여줌을 확인해볼 수 있습니다.
5.6 Rate of Convergence
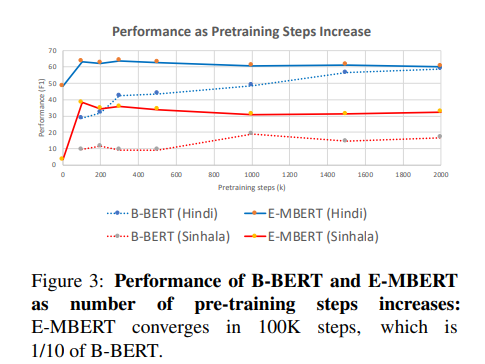
E-MBERT는 단순히 100k 의 step으로 학습이 가능한 반면 ,B-BERT는 1M보다 더 큰 step으로 진행을 해야만 수렴하는 것을 확인해볼 수 있습니다.
5.7 Performance on non-target langauges
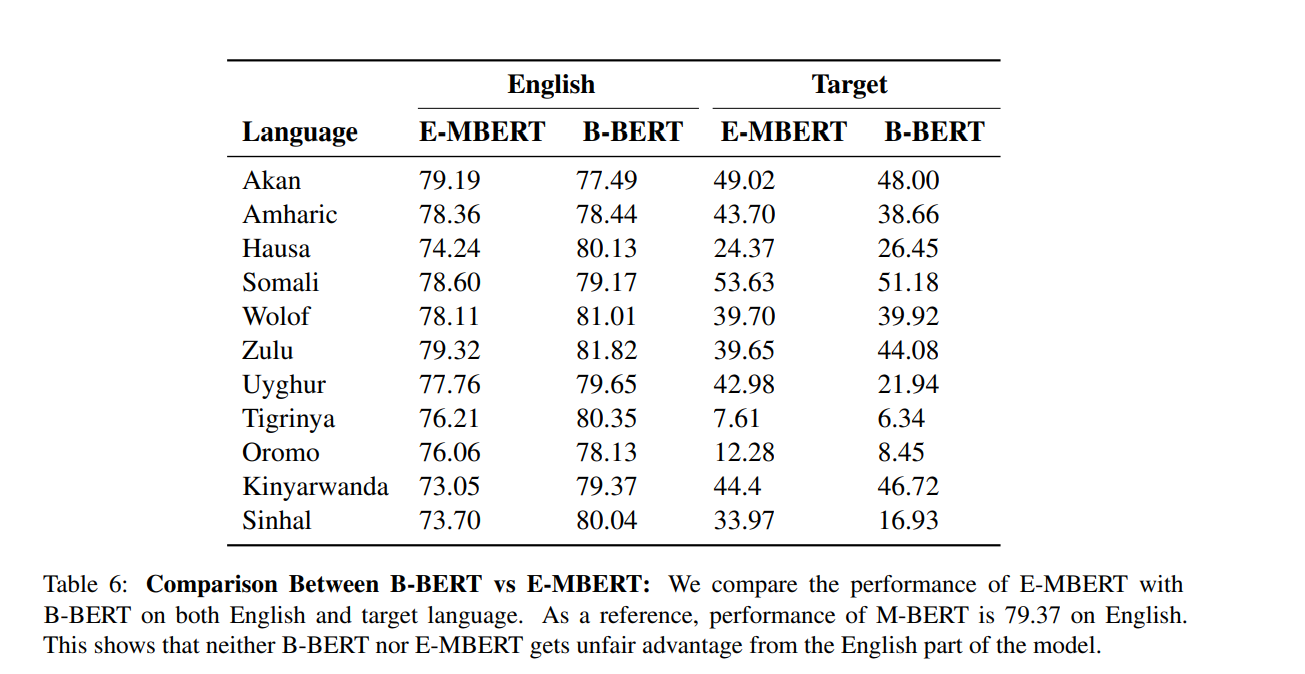
"English" 열은 각 모델이 영어 데이터에 대해 얼마나 잘 수행하는지를, "Target" 열은 각 모델이 다른 언어들에 대해 얼마나 잘 수행하는지를 F1 점수로 보여줍니다. 이는 English에 대해서는 별로 차이가 없다는 점에서, 어느 모델이 더 우위에 있는지 알 수 없다는 것을 보여줍니다. 반면 Target E-MBERT는 대부분의 언어에서 B-BERT보다 더 높은 F1 점수를 보입니다. 이는 E-MBERT가 해당 언어들을 처리하는 데 더 효과적임을 나타냅니다.
6.Conclusions and Future work
위 논문의 저자는 EXTEND 방식을 제안하여 M-BERT를 제안하여 더 좋은 성능으로 만들었습니다. 현재는 EXTEND 방식이 한 언어를 처리하는 방식이지만, 미래에는 multiple language 방식으로 더 빠르게 처리할 수 있을 것입니다.
한 줄로 요약하면?
E-MBERT는 기존의 M-BERT에 소수 언어의 vocab을 추가하여 Pretraning을 진행한 모델로, M-BERT를 굳이 다 학습하는 것보다 추가만 하여 학습을 하고, 성능 또한 순수한 M-BERT보다 더 좋아짐을 확인할 수 있었습니다.
