preface

1. Introduction
기존의 BERT는 영어 텍스트만을 통해서 학습해왔습니다. 그리하여 이 논문에서는, representation을 다양한 언어를 통해서 일반화를 진행하자는 취지로 조사를 시작했습니다. 저자는 새로운 BERT인 M-BERT를 제안하였습니다. 기존의 BERT는 Wikipedia corpora의 단일 언어로 pretrained 된 모델입니다. M-BERT는 단일 언어로 학습되어 있는 구조를 zero shot learning을 통해서 해결하는 것에 최적화되어 있습니다. 저자는 one language로 학습을 하고, evaluation 과정에서 different language를 사용했다는 점이 신기하다.
논문에서는 서로 비슷한 어휘들은 transfer이 잘되는 모습을 보여주었고, 이는 multilingual representation이 잘 된다는 것을 보여주는 결과입니다. 더불어 어법이나 문법 등 언어의 구조적 형태가 비슷한 단어들끼리는 번역이 잘 된다는 사실을 보여줍니다. 그래서 새로운 단어나 언어에 맵핑은 잘 할 수 있습니다만 단어 순서의 체계가 바뀐다면 번역이 힘들다고 합니다.
2. Models and Data
EN-BERT와 같이, M-BERT는 12개의 layer로 구성되어 있고, 104개의 언어로 구성된 Wikipedia pages로 학습되어 있습니다. 어느 언어에 대한 설명도 적지 않고, 비슷한 구조가 잘 학습되게 번역 쌍 또한 넣지 않았습니다.
NER와 POS 분야에서, 저자는 BERT와 같은 구조의 tagging architecture을 사용했습니다. input sentence를 tokenize하고, BERT를 학습하고, 마지막 activation function을 활용하여 결과를 prediction 하는 구조로 똑같습니다.
2.1 Named entity recognition experiments
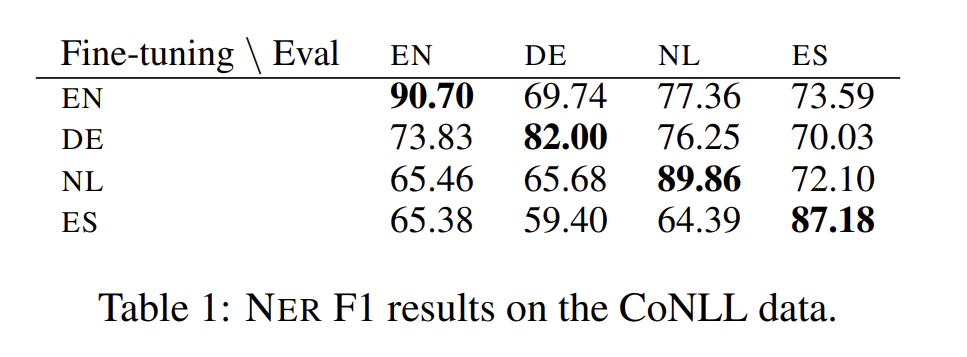
NER 실험은 2가지 데이터 셋으로 진행이 되었는데 CoNLL-2002와 -2003 버전입니다. 여기에는 네덜란드어, 영어, 스페인어, 그리고 독일어를 포함하여 16개의 언어셋이 들어가있습니다.
2.2 Part of speech tagging experments
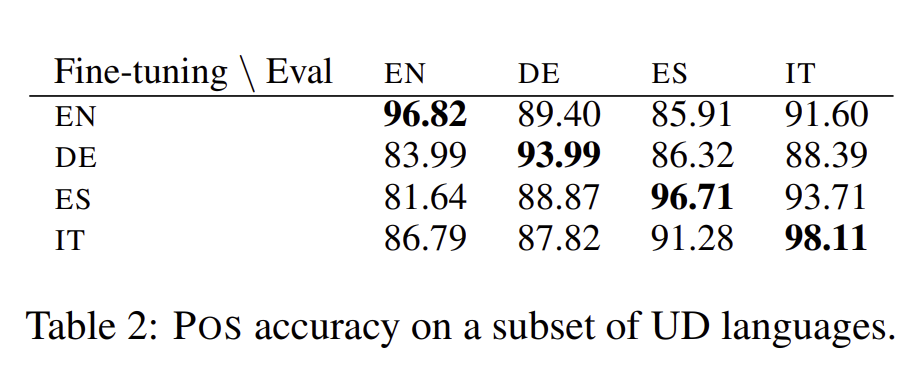
POS 실험에서는 UD 데이터셋을 사용하였고, 이 데이터셋은 41개의 언어로 구성되어 있습니다. 저자는 Ze-man et al의 데이터셋을 통해 평가하였습니다. 위 표를 통해 M-BERT가 다른 언어들을 가지고 일반화가 잘된다는 점, 80퍼센트 이상의 정확도를 보여준다는 점이 핵심입니다.
3. Vocabulary Memorization
M-BERT은 하나의 어휘집에 여러 언어가 들어가기 때문에, fine tuning을 할 때, cross lingual transfer 하는 과정이 평가 언어에서 발생합니다. 섹션 3에서는, M-BERT의 일반화 성능에 대해서 보여줍니다. transfer 하는 정도가 어휘의 유사성에 얼마나 의존을 하는가? 그리고 어휘적 유사성도 없이, 다른 스크립트를 단순하게 transfer 할 수 있는가?
3.1 Effect of vocabulary overlap
M-BERT의 일반화 ability는 거의 vocab의 momerization 덕분이라면, 저자는 word piece에서 높은 성능의 어휘적 유사성을 통해서 NER에 높은 성능을 기대할 수 있습니다. 왜냐하면 entities는 다중언어를 다루는 것과 유사하기 때문이죠. 그래서 이러한 가정을 검증하기 위해, 데이터셋을 사용하고, overlap을 아래와 같이 정의합니다.
각각의 집합의 원소의 숫자로 나눠서 overlap을 정의하여 사용합니다.
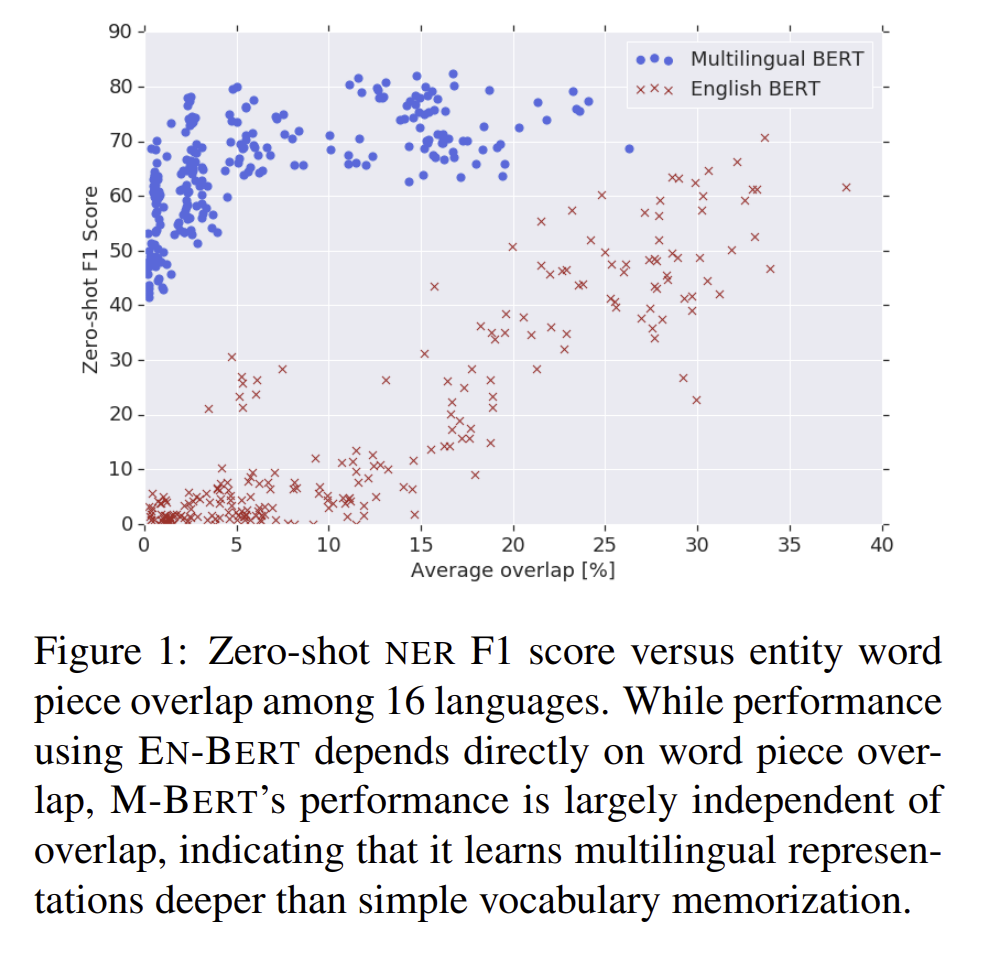
위 그림은 NER의 F1 score를 그린 것으로, E-BERT와 M-BERT의 성능을 비교한 그림입니다. 그림을 해석하면 E-BERT는 word piece overlap에 의존하는 것으로 보이는데 이는 각 언어별로 유사한 단어들이 적어지면 적어질 수록, transfer의 능력이 낮아지는 것을 보여줍니다. 그리고 F1 score는 다른 언어로 쓰인 script에 대한 점수는 거의 0점에 가깝습니다. 반면에 M-BERT는 overlap이 넓게 펄쳐져있으며, lexical overlap이 거의 없어도 flat한 성질을 보여줍니다. score는 40~70점 사이이며, M-BERT의 pretraining은 simple vocab memorization보다 더 깊은 양의 representation을 가능하게 해줍니다.
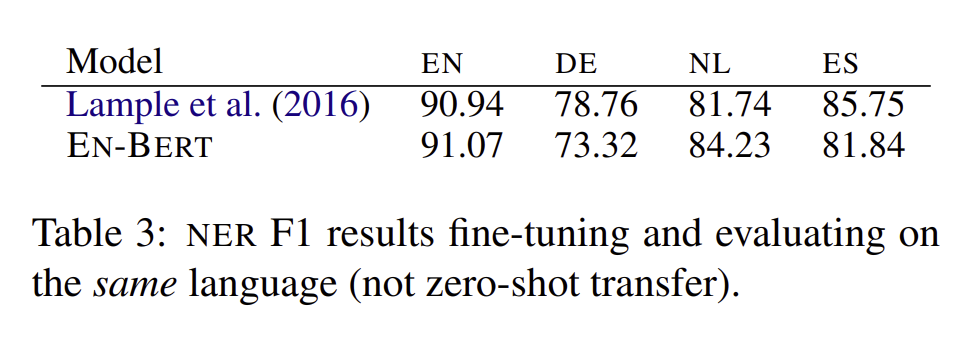
위 표는 NER 테스크에 대한 F1 result의 결과로 영어 테스크에 대한 evaluation 당시의 결과입니다. 확실히 영어로 학습하면 이는 성능이 높지만, 이 이외의 언어로 평가하는 것은 낮은 평가를 보인다는 것을 보입니다.
3.2 Generalization across scripts
M-BERT의 언어 사이의 transfer 하는 능력은 다른 script를 이용하고, 전혀 어휘적인 유사성이 없음에도 불구하고, 높은 성능을 보인다는 점입니다. 더불어 각각의 monolingual corpora로 학습이 되고, multilingual objetive로는 학습되지 않았다는 점도 신기합니다.

Table 4에서는 단일 언어로 학습하고, 그 언어로 평가를 하면 성능이 당연히 높다는 점도 신기하지만, 본 언어로 학습하고, 다른 언어로 평가를 해도 높은 성능을 보일 수 있다는 점에도 신기하다는 것입니다.
M-BERT 모델은 아라비아 어로 쓰인 script의 Urdu로 fine tuning되었는데, 인도 언어에서 91퍼센트의 높은 성능을 보였다는 점입니다. 심지어 POS tagged 에서는 Devanagari word를 전혀 보지 못했음에도 말입니다.(Devanagari는 인도어의 알파벳 이라고 생각하면 됩니다.)
하지만 cross script로 transfer 하는것은 성능이 확실히 낮은것이 보이고, English나 Japanese 관계에서 이를 특출나게 보여줍니다. 그래서 M-BERT가 모든 것에 성능이 높지는 않습니다. 원래 영어랑 일본어는 주어와 목적어, 술어 간의 관계가 다르기 때문에, 낮은 성능을 보인다는 것으로 해석할 수 있습니다.
4. Encoding Linguistic Structure
이번 섹션에서, 저자는 언어학적인 유사성이 얼마나 M-BERT의 성능에 큰 영향을 줄 것인가?, M-BERT가 단일 언어의 input에서 시작해서 여러 언어가 같이 나오는 구조도 잘 generalize 할 수 있을 것인가? ,모델이 다국어로 사전학습 되지 않고, 다국어 텍스트를 보면 얼마나 잘 해석할 것인가? 등의 질문을 해석하려고 합니다.
4.1 Effect of language similarity
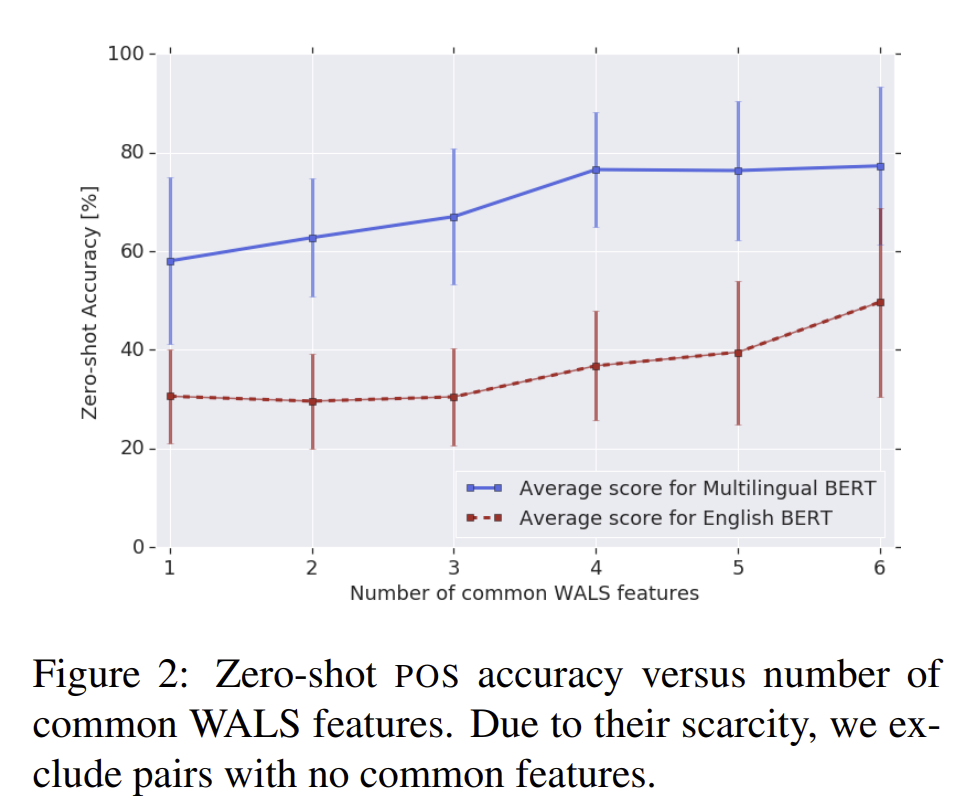
저자는 이번 섹션에서 문법적으로 가지는 순서에 대해서 성능 비교를 하였습니다. 유사도가 높은 문법들끼리는 높은 성능을 보여주었습니다.
4.2 Generalizing across typological features

위 표는 macro - averaged 된 POS 문법적 성질을 보았을 때의 정확도를 써놓은 것으로, 주어, 목적어, 동사 또는 형용사 명사 순서 등 이를 고려한 표입니다. SVO는 영어,중국어의 구조이며, SVO와 SVO 구조가 만나면 높은 성능을, SOV는 한국어와 일본어의 구조이며, SOV와 SOV가 만나면 높은 성능을 보이는 것을 알 수 있었습니다. 부사와 형용사 관계도 이와 똑같은 구조를 보이고 있습니다.
4.3 Code switching and transliteration
CS는 한 문장에 여러 언어가 들어간 것을 뜻한다.(약간 전청조 밈처럼 I am 신뢰에요 와 같이 영어와 한글이 한 문장에 같이 있는 경우를 의미한다.) code switching CS를 일반화 하는 것은 다른 cross lingual transfer 시나리오와 비슷하지만, 더 좋은 성능을 보여줍니다. 마찬가지로, 음역(한 언어를 다른 언어로 바꾸어 쓸 때, 발음대로 옮겨 적는 행위)또한 cross script transfer experiments와 비슷합니다. 그러나 M-BERT는 target과 같은 text에 pretrained 되어 있지 않는다는 하나의 caveat(경고)가 있습니다. ****
저자는 표준 스크립트가 아닌 텍스트나 여러 언어가 혼합된 텍스트를 얼마나 잘 처리할 수 있을지를 탐구하고자 하였습니다. 인도어와 영어의 UD corpus로 M-BERT를 실험해보았습니다. 데이터는 힌디어와 데반나가리 언어로 되어 있는 2가지 형태의 텍스트가 있습니다.

결과를 보게 되면, coding switch로 된 텍스트를 보게 되면, 이에 대한 결과는 좋지만, 만약에 음역 처리가 된 텍스트를 모델 평가에 사용하게 되면, 이는 결과가 굉장히 낮다는 것을 알 수 있게 됩니다.
5. Multilingual characterization of the feature space
5.1 Experiment Setup
저자는 WMT 16으로 부터 5천개의 문장을 sampling 하고, 각 문장은 fine tuning 없이 M-BERT에 학습시켰습니다. 각 layer의 hidden feature activation을 추출하고, CSL와 SEP를 제외하여 representation을 평균내렸습니다.각 pair의 문장별로 로 표현이 되며, 각각의 벡터 포인트들을 옮겨서 이를 평균 내렸습니다. 마침내, 각각의 each sentence를 번역하고, 가장 가까운 german sentence의 vector를 찾아냅니다. 몇번의 시도간에 가장 가까운 이웃들이 몇 번이 나오는지를 계산하여, 이를 ‘nearest neighbor accuracy’ 라고 정의합니다.
5.2 Results
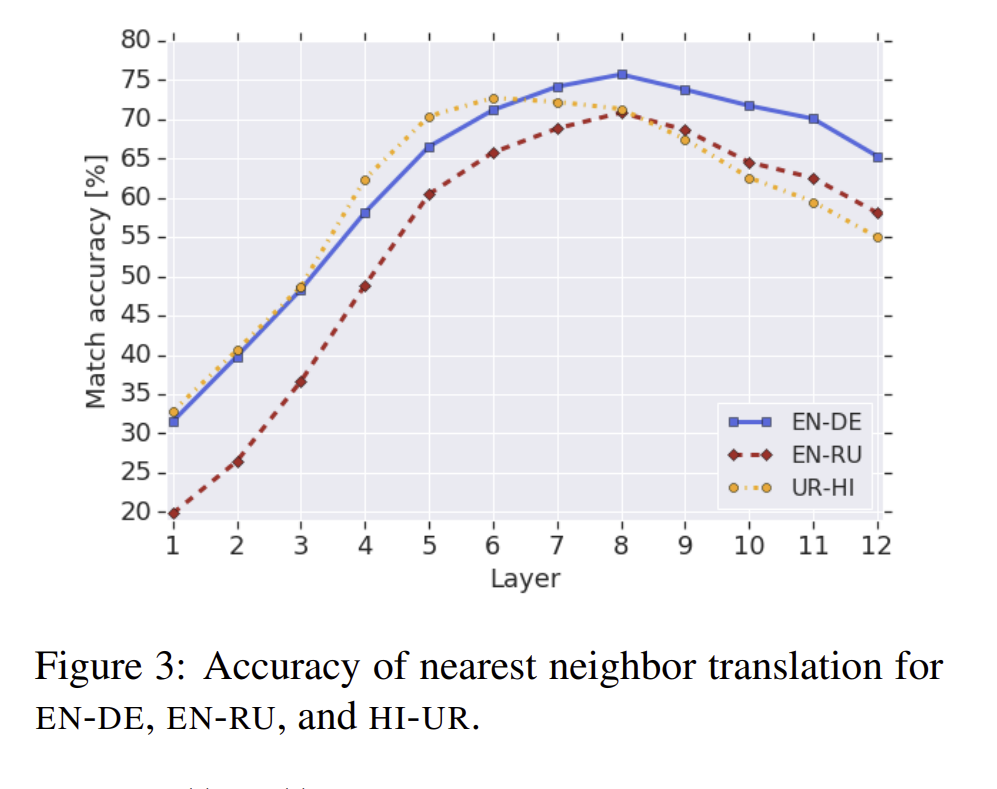
Figure 3에서 저자는 EN-DE 사이의 nearest neighbor accuracy를 그렸습니다. 거의다 50퍼센트 이상의 정확도를 보였고, EN-RU나 UR-HI 구조에서도 비슷한 커브를 보였습니다. layer가 8이상 일때, 점점 정확도가 내려가는 이유 중 저자가 생각한 것은 모델이 언어 모델로 pre-trained 되었기 때문에, missing word를 예측하기 위해선 더 구체적인 language - specific information이 필요하다고 예측하였습니다.
6. Conclusion
이 논문에서는 M-BERT의 성능 결과에 대해서 말해주었고, 나라별 언어 script들을 통해서 zero shot learning과, code - switching을 통해서 학습이 될 수 있다는 점, 하지만 구조적으로 다른 언어나 변환된 타겟에 대한 전달은 추가적인 다국어 훈련이 필요할 수도 있다는 점, 모든 언어들은 같은 벡터 space에 놓여있다는 점 등 논문을 활용하면서 사용했던 방식들에 대해서 정리해주고 있습니다. 그리고 이러한 능력이 명시적으로 다국어 훈련 목표를 위해 훈련되지 않았음에도 불구하고 나타난다는 것을 보여줍니다
한 줄로 요약하자면?
M-BERT는 기존의 BERT 구조에서 다국어 언어 데이터 셋의 변경하고, zero shot learning을 통해서 높은 성능을 보일 수 있으며, 문법적인 구조를 맞춰서 학습을 진행하고 code switching과 같은 방식으로도 높은 성능을 낼 수 있는 BERT이다.
논문을 읽고 느낀점
문법적인 성질이 모델에 영향을 주면 애초에 SVO 구조를 SOV로 다 바꾼 다음에 학습하는 것도 가능하지 않을까? 라는 생각이었다. 애초에 데이터 양이 부족한 거니 소수민족의 언어와 같은 구조도 맞춰줄 수 있으면 좋지 않을까?
