preface

1. Introduction
ELMo, GPT, BERT, XLM, XLnet과 같은 모델들은 굉장히 높은 성능으로 당시 SOTA들을 기록했습니다. 하지만 어느 측면에서 어느 모델이 가장 높은지를 확인해야 했죠. 학습을 한 번 할 때마다 드는 비용은 엄청나게 많았고, 사용하는 데이터들도 제각각 달랐습니다.
저자는 BERT의 pre training 과정에서 하이퍼 파라미터의 effect와 training size를 확인하면서 undertrained 되었다는 것을 알게 되었고, BERT의 새로운 모델인 Roberta 를 제안했습니다. 정말 간단하게 4가지 방법으로 설명하였습니다. 먼저, 더 큰 배치 사이즈로 모델을 길게, next sentence prediction을 없애고, 다음으로 더 긴 문장을 학습, 마지막으로 training data에 적용된 masking pattern 들을 변경하는 것입니다. 또한 저자는 새로운 모델인 CC-NEWs를 모았고, 이는 training set size effect 들을 더 좋게 할 수 있던 방식 입니다.
그리고 모델 학습할 때, CC-NEWs 데이터로 BERT를 학습하니, 더 좋은 성능이 나온 것을 확인할 수 있었습니다.
2. Background
이번 챕터에서는 BERT를 어떻게 Pretraining을 했는지에 대해서 요약을 합니다.
2.1 Setup
BERT는 input으로 두 개의 문장을 합친 것을 넣습니다. 과 입니다. 그리고 CLS와 SEP, EOS를 통해서 문장을 구분합니다. 그래서 모델은 그 unlabeled된 text corpus를 통해서 pre trained 되고, 마침내 downstream task에 맞게 fine tuning 되는 거싱ㅂ니다.
2.2 Architecture
논문 참고
2.3 Training Objectives
pretraining을 하면서, BERT는 2가지의 목적을 가집니다. 첫 번째로, masked language modeling과 next sentence prediction 입니다.
Masked Language Model(MLM)
문장의 토큰 들이 랜덤으로 MASK 처리가 됩니다. BERT는 15퍼센트를 input token에 유지하여 넣고, 선택된 15퍼 중에 80퍼를 MASK로 랜덤하게, 10퍼는 안변하고, 나머지 10퍼는 vocab 토큰으로 남겨둡니다. original 한 BERT에서는, 처음에 한번 랜덤 마스킹과 replacement가 일어나고, 학습하는 동안에는 저장이 됩니다. 비록 실전은 아니지만, 데이터는 복제되어서 마스크가 항상 같은 문장이 나오지 않게 합니다.
Next Sentence Prediction(NSP)
NSP는 binary classification의 문제로 두 개의 segment가 서로 follow 하게 만들어서 다음 문장을 예측할 수 있게 만드는 것입니다. 긍정적인 데이터로는 연속적인 문장들이 나온다는 점, 부정적인 데이터로는 서로 다른 문서에서 만든 시퀀스들이 붙여진다는 점, 그리하여 각각의 문서에서 나온 시퀀스들이 같은 확률로 샘플링 되어서 학습을 진행하게 됩니다.
2.4 Optimization
BERT는 Adam과 함께 최적화가 진행되었고, 로 설정하여 학습을 진행했습니다. 학습률은 첫번째 1만 스탭이 지나면 1e-4로 줄어들게 하고, 이후 선형적으로 감소시킵니다. BERT는 0.1의 dropout비율로 학습하고, GELU activation function으로 학습을 했습니다. 모델은 백만번 pretrained하고, mini batch 로는 256, maximum lenght로는 512를 유지하면서 최적화를 합니다.
2.5 Data
BERT는 BOOKCORPUS과 English Wikipedia의 조합으로 학습을 진행했습니다.
3. Experiemental Setup
3.1 Implementation
저자는 FAIRSEQ로 BERT를 재학습시켰습니다. 먼저 original bert의 하이퍼 파라미터를 활용하였습니다. 추가로 Adam epsilon term에 매우 민감한 것을 발견하기도 하였고, 로 설정하는 것이 더 안전성이 높다는 것을 확인할 수 있었습니다. 그리고 오직 full - length sequence를 통해서만 학습을 진행하였습니다.
3.2 Data
BERT 스타일의 pretraining은 전적으로 많은 학습 데이터셋을 기반으로 합니다. Baevski et al은 데이터셋이 많아질수록, 성능이 올라가는 것을 확인했기에, 당시 학자들은 더 많고 긴 데이터셋으로 학습을 시도하려고 했습니다. 하지만 모든 데이터셋을 구할 수는 없었기에, 위 연구에서는 가능한 모든 데이터셋을 모아서 학습을 진행하려고 했습니다.
저자는 5개의 영어로 구성된 다양한 사이즈와 도메인, 합쳐서 160 기가 이상의 uncompressed text를 모아서 학습을 진행했고, BOOKCORPUS. CC-NEWs, OPENWEBTEXT, STORIES와 같은 데이터셋으로 구성되어 있습니다.
3.3 Evaluation
그리고 저자는 GLUE, SQuAD,RACE 3개의 NLP benchmark을 가지고 평가를 하였습니다.
4. Training Procedure Analysis
4.1 Static vs Dynamic Masking
BERT는 masking을 랜덤으로 진행하고 있습니다. 그리하여 original BERT은 data를 preprocessing 하는 과정에서 masking을 한번만 진행하지만 이는 static mask를 이룹니다. same mask를 사용하지 안히 위해서, training data를 10번 복사하여 각각의 sequence에 다른 mask가 배치되게 설정하여 학습을 하게 합니다. 이런 전략을 dynamic Masking이라고 칭합니다.
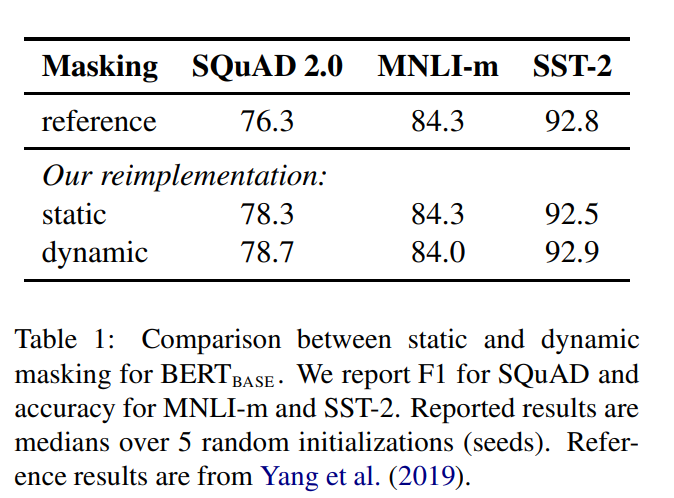
결과는 위와 같습니다. 확실히 dynamic을 사용한 구조가 근소하게나마 높게 나오는 것을 확인할 수 있었습니다.
4.2 Model Input Format and Next Sentence Prediction
original BERT를 pretraining 하는 과정에서는, 모델들은 2개의 document를 붙여서 학습을 진행합니다. 게다가 masked language modeling 과정에서, 모델들은 두번째 문장이 첫번째 문장이 나오게 하는 구조로 학습을 시킵니다.
그래서 NSP Loss를 제거하게 되면 성능이 확실히 떨어지는 것을 2019년에 발견했지만, 동일 년도에, NSP loss를 없애는 것에 대한 necessity가 강조되었습니다.
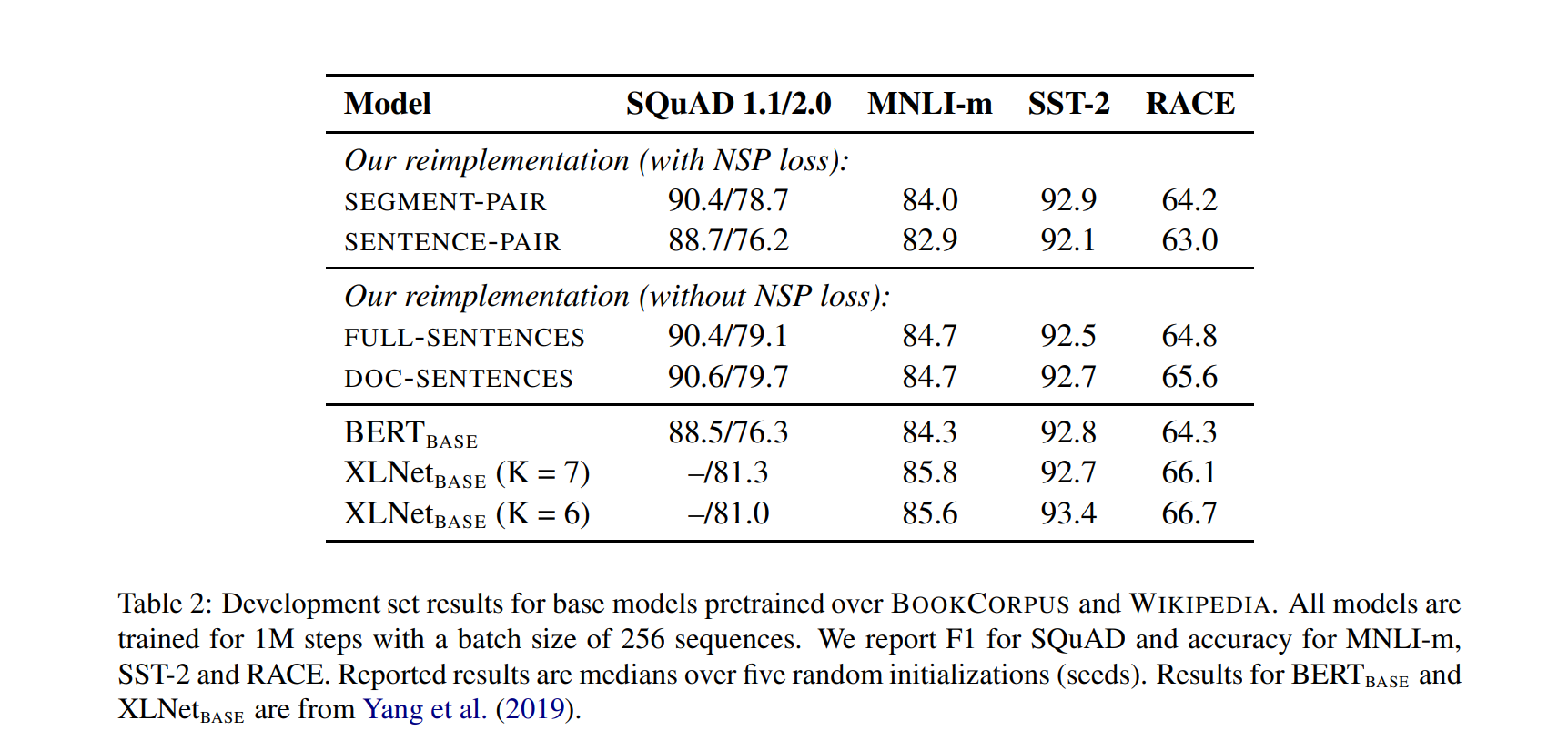
위 결과에 따르면 NSP loss를 넣든 말든, 결과 자체는 크게 달라지지 않는 결과를 볼 수 있었고, 결과적으로, 개개별의 문장들을 사용하면 다운스트림 태스크의 퍼포먼스 저하를 일으킬 수 있다는 것을 알게 되었습니다.
그리고 한 개의 문서에서 가져온 문장들로만 학습을 하게 되는 것을 비교해보았을 때, NSP loss를 없애는 것이 downstream task에 더 좋은 성능을 보여줄 수 있게 되었습니다.
4.3 Training with large batches
Ott et al 에서는 NMT 당시, mini-batch size를 크게 하면, 최적화 속도와 end task performance의 성능이 오르는 것을 알 수 있었습니다. 최근 연구에서도 BERT도 batch training을 large 하게 할 수 있습니다.
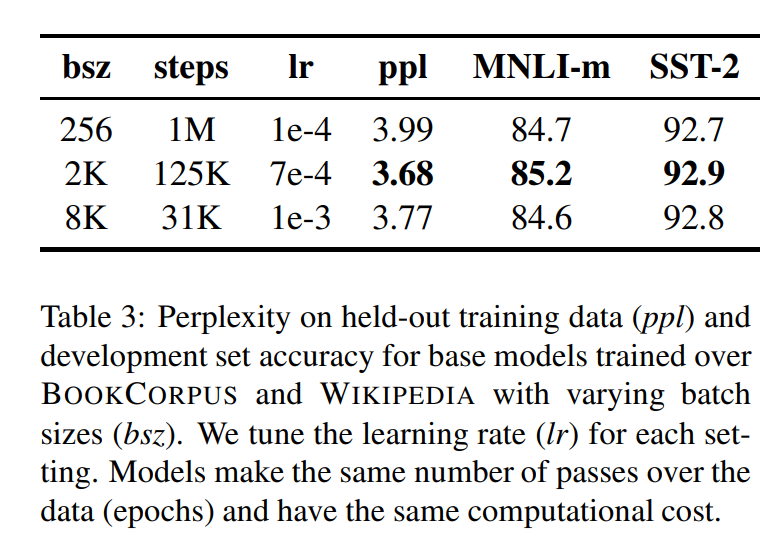
4.4 Text Encoding
BPE는 기본적으로 subword 단위로 이루어져서 training 하는 corpus에서 통계적으로 분석을 해서 뽑은 것입니다.
BPE vocab size는 일반적으로 10000~100000 사이의 subword로 이루어져 있지만, unicode은 vocab의 큰 부분을 차지하고 있었습니다 . Radford et al은 clever 한 BPE 방식을 소개했는데, 이는 unicode 대신에 bytes를 활용하여 BPE를 쓰는 것입니다. bytes를 사용하면 subword 학습을 적은 size에도 가능하게 되며, UNK를 쓰지 않고도 encode가 가능해집니다.
기존의 BERT는 30k 크기의 BPE 사전을 사용했습니다. 하지만 저자는 Radford et al 방식을 따라서, 50K로 이루어진 larger byte level BPE vocab을 활용하는 것입니다. BERTBASE 모델에는 약 15백만 개, BERTLARGE 모델에는 약 20백만 개의 추가 파라미터가 생겼습니다 저자는 보편적인 인코딩 체계의 장점이 성능의 소폭 저하를 상쇄한다고 믿고, 나머지 실험에서 이 인코딩 방식을 사용하기로 결정했습니다
5. RoBERTa
RoBERTa는 dynamic masking, FULL-SENTENCE without NSP loss, large mini batches, larger byte level BPE로 학습되었습니다. 추가로 pretraining이 진행되었습니다.
학습 구조는 BERT_LARGE와 똑같은 파라미터로 구성이 되었으며, 100만의 데이터로 pretrain을 진행했습니다.
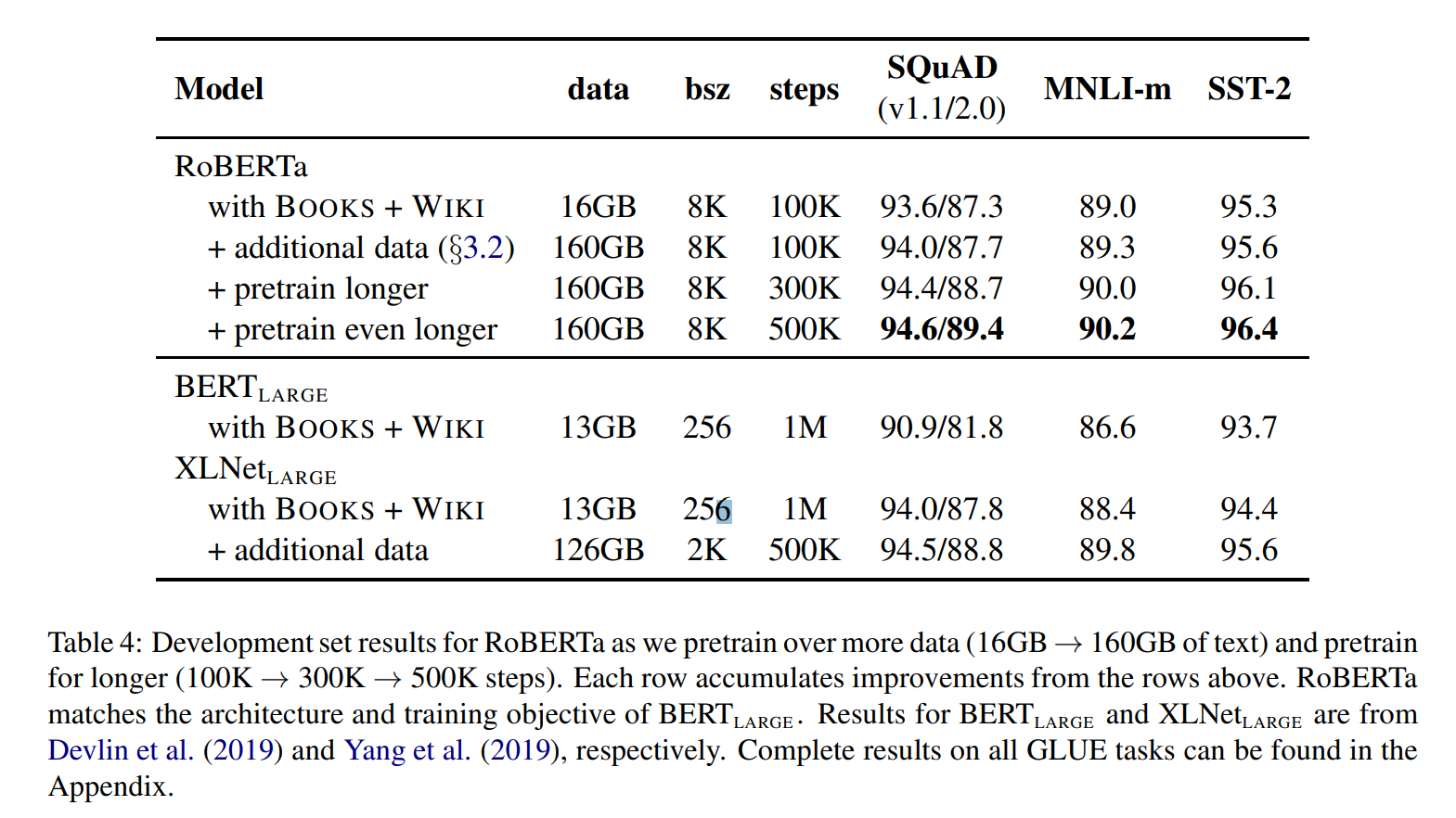
결과는 pretrain을 더 길게 했을 경우, 성능이 제일 높았고, XLNet와 BERT_LARGE 보다 더 높은 성능을 보이는 것을 알 수 있었습니다.
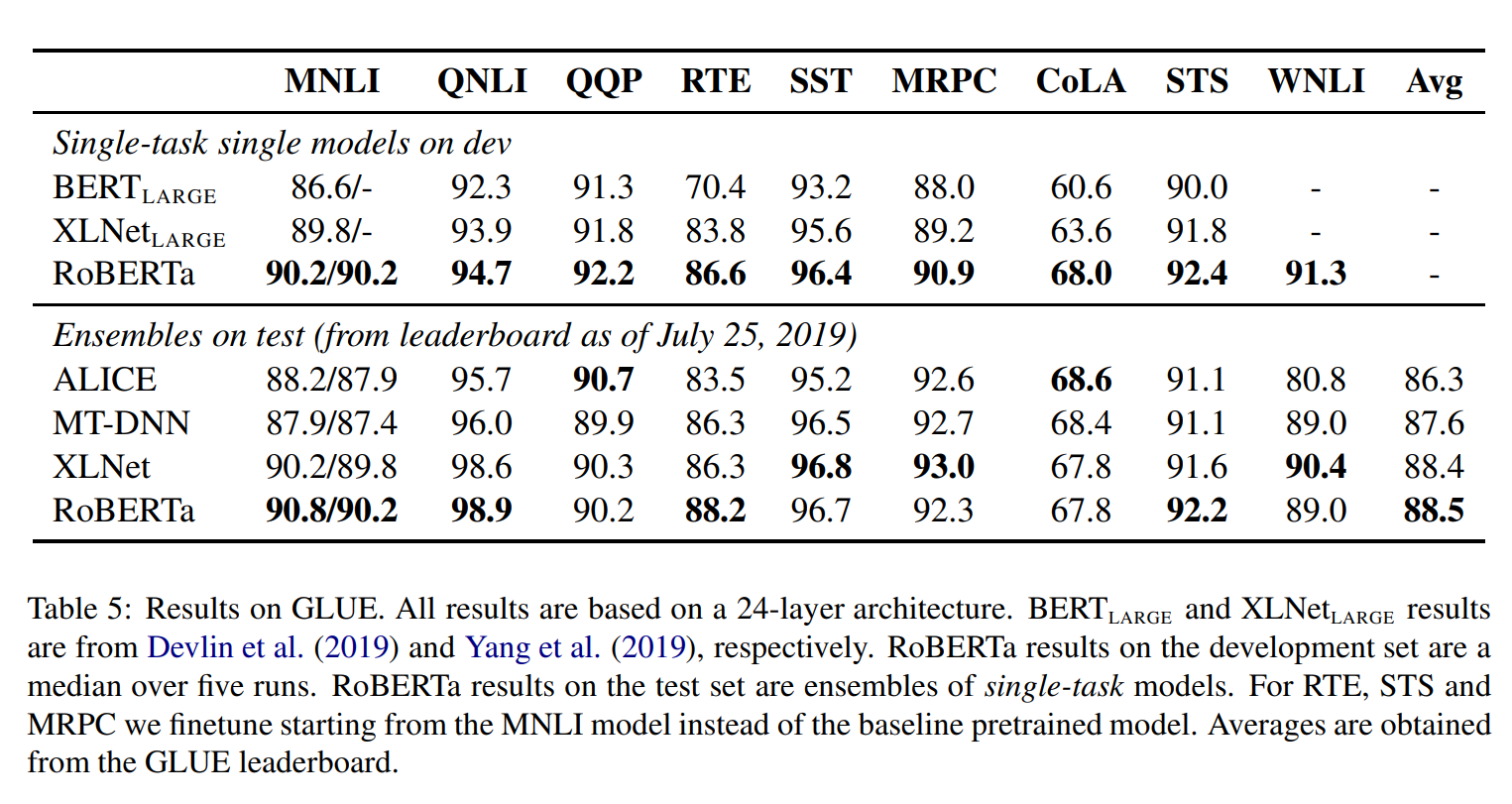
이는 밴치마크인 GLUE 데이터로 학습을 한 경우인데, RoBERTa가 꾸준히 높은 성능을 보이는 것을 알 수 있었습니다.
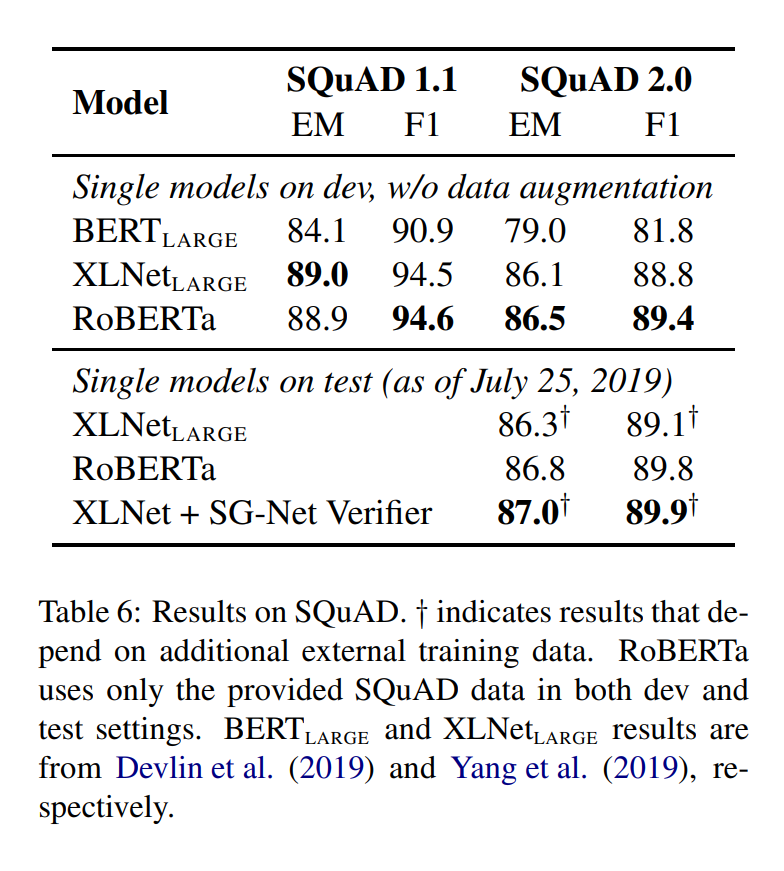
SQuAD에서도 높은 성능을 보이는 것을 알 수 있었습니다.
7. Conclusion
모델을 더 크게 하고, batch를 더 크게 하고, 데이터를 더 많이 사용하면 모델의 성능이 오르는 것을 확인할 수 있습니다. NSP를 없애고, sequence를 더 길게 하며, dynamic한 설정으로 masking pattern 변화를 주게 해서 성능을 더 올리기도 했습니다. RoBERTa는 multi fine tuing 없이 SOTA에 오르는 것을 보였습니다.
한 줄로 요약하면?
RoBERTa는 masking pattern을 randomly 하게 바꾸고, BERT의 NSP 구조를 없애고, batch를 늘리며, sequence를 늘리고, pretrain의 양을 늘려서 바꾼 BERT다.
