Keras 모델 성능 개선
Model 학습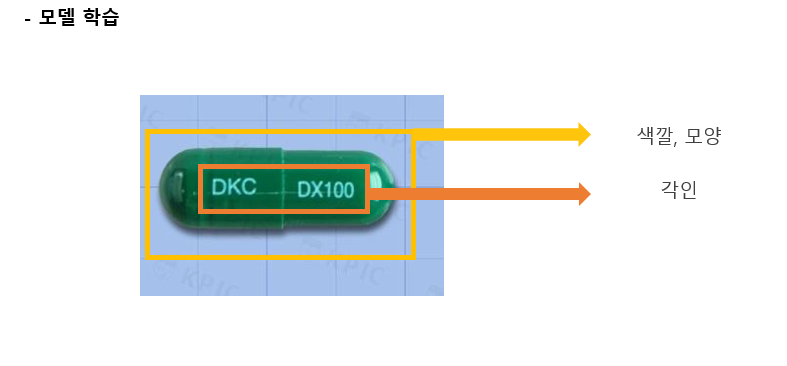
- Tensorflow Version : 2.4.0
- Python Version : 3.8.4
- 원본 데이터 개수 : Label당 1,000개
Goals
- Model 성능을 개선하여 Detecting에 대한 성능 향상
- 30개 Label Classify 정확도를 50% 이상으로 향상시키기
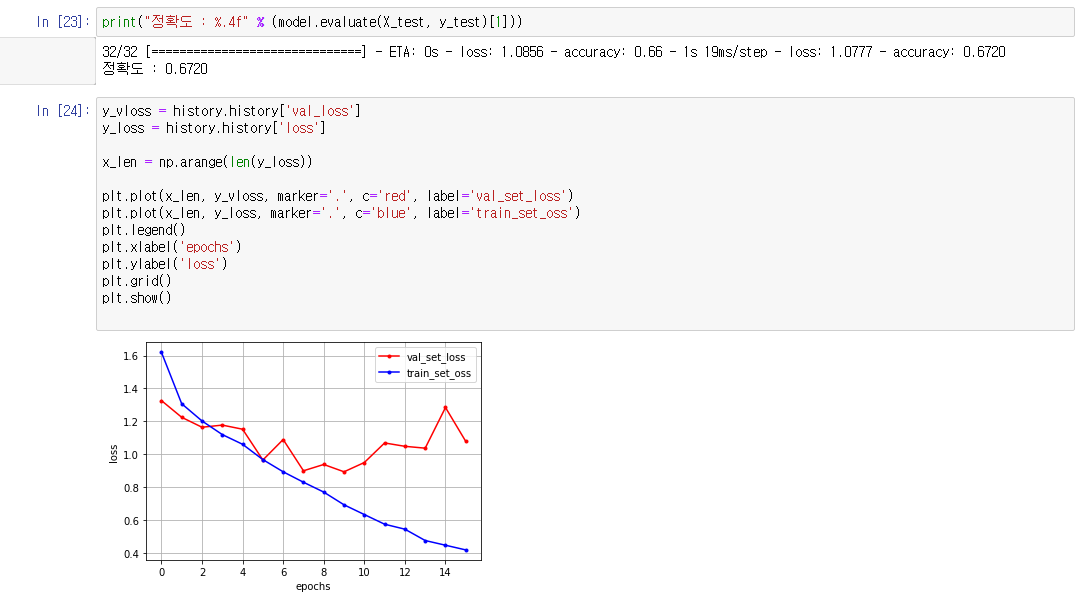
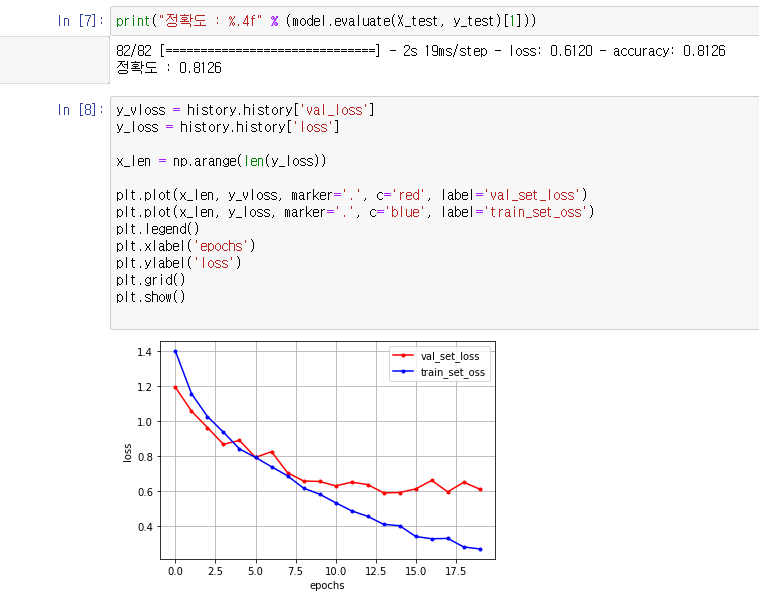
1차 학습 모델 ( 정확도 23.5 % )
- 데이터 개수 : 30개 Class Label x 1,000 = 30,000 Image
- 기초적인 CNN 구성
- Optimizer : adam
1차 모델 구성
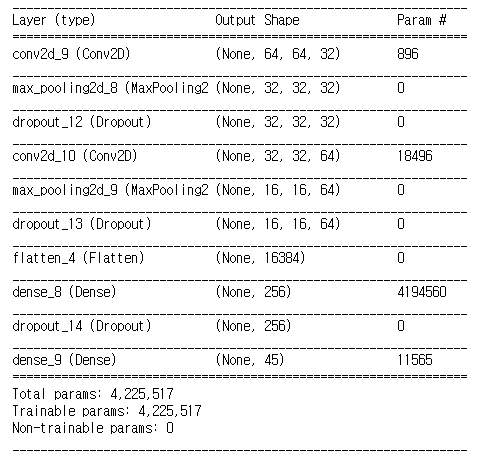
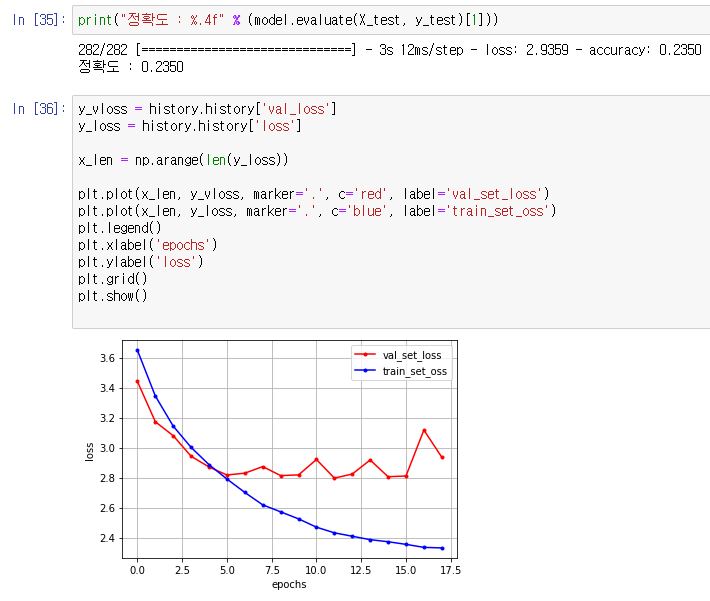
1차 모델 테스트 결과
1차 모델 테스트 결과 분석
- Class Label에 비하여 데이터 개수가 너무 적음 ( label 당 1,000개 이미지 )
- Label 개수에 비해 CNN 모델이 너무 얕아 특성을 분리하기에 너무 적은 측면이 존재
- validation set에 대한 loss가 너무 커서 이를 줄이기 위한 방법이 필요
2차 모델링 설계를 위한 Mini-Class-Test
1. 단순하게 Class 수만 줄여서 테스트 ( 30 → 6 )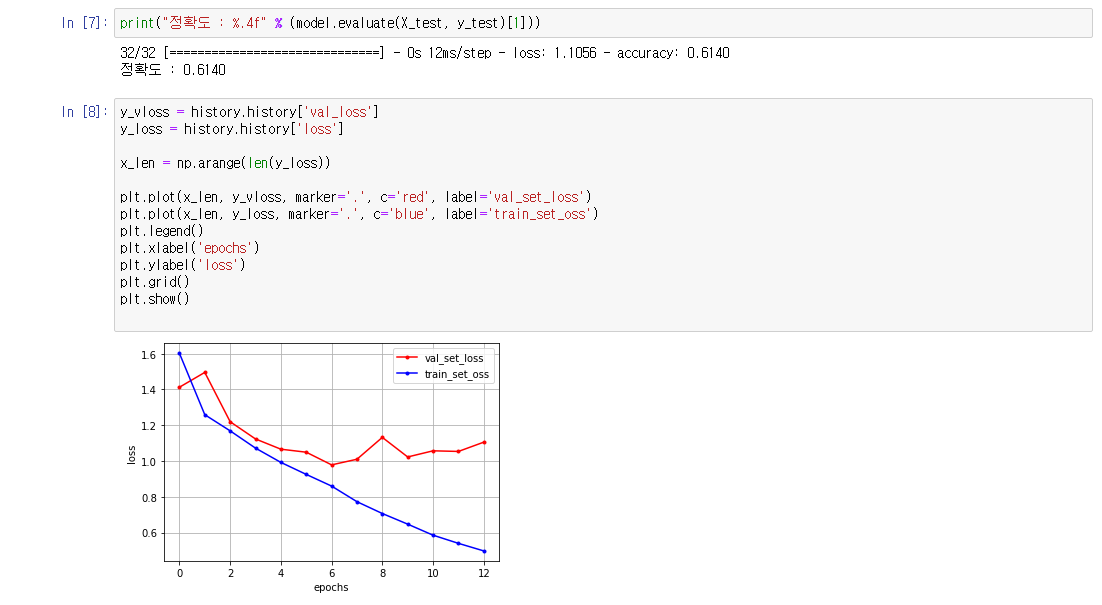
- 단순히 Class 개수만 줄여도, 분류해야할 Class가 적어져 정확도가 올라가는 효과가 발생
- 하지만 validation loss 문제는 해결되지 않음
2. CNN 구조 개선 작업
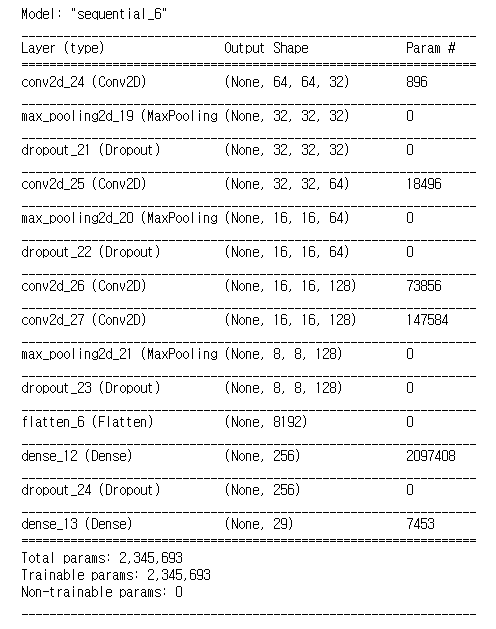
- 중간 Layer의 개수, Node의 개수, Dense 증가 등 많은 방법을 사용
- Layer를 깊게만 쌓는다고 성능 향상으로 직결되진 않았음
- 적당한 Layer를 넣어줘야 정확도가 증가되는 양상을 보임
3. Input Image Resizing
- 기본 이미지 데이터셋들이 모두 580 x 420 pixel의 사이즈를 가진다
- 지금까지는 128 x 128으로 resizing한 이미지만 사용함
- 이를 64 x 64 또는 256 x 256 으로 resizing 하여 일어나는 변화를 관측
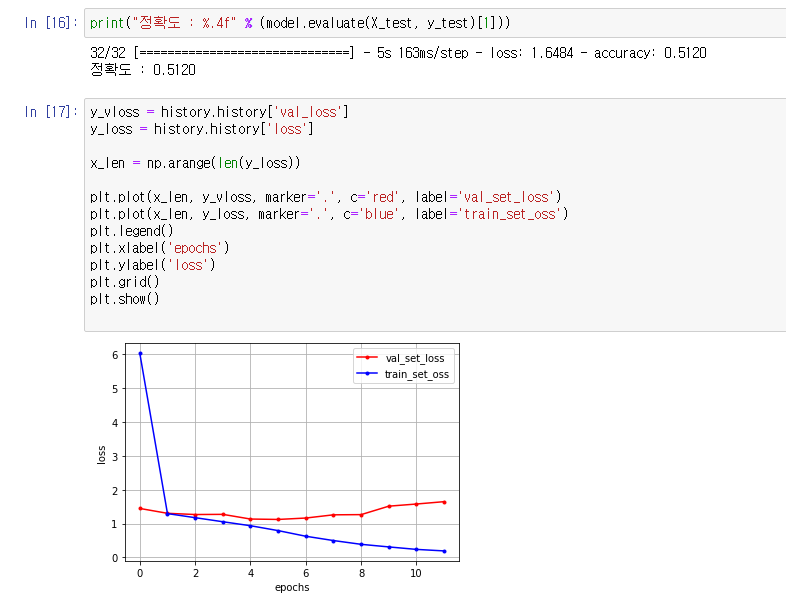
- 이미지를 256 x 256으로 사용했을 때, 초기 epoch에서의 loss가 큰 폭으로 감소하지만 결론적으로 정확도에는 영향을 끼치지 않았으며, 오히려 64 x 64 이미지를 사용했을 때 안정적으로 loss가 줄어드는 양상을 보였음
- 따라서 64 x 64 의 Image Resizing을 적용하기로 함
4. Optimizer 와 Learning Rate 조정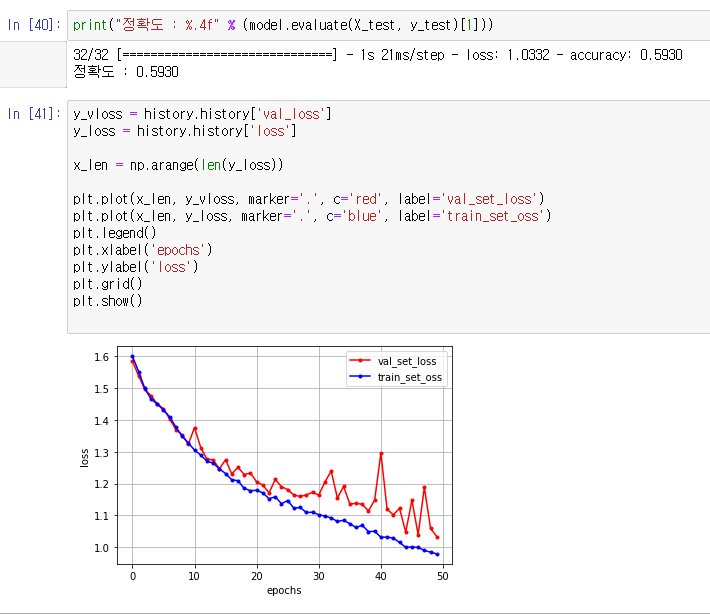
- 기존에 사용하던 rmsprop optimizer를 사용하지 않고, sgd와 adam Optimizer를 사용함
- sgd의 경우 점진적으로 validation loss가 개선되었지만, epoch이 증가할수록 심하게 변동폭이 큰 validation loss를 보여 sgd 대신 adam을 사용
5. Image Augmentation을 통한 데이터 증폭

- keras의 ImageDataGenerator 함수를 사용하여 데이터를 증폭
- Class당 1,000장의 데이터를 약 3,000장으로 늘려서 테스트
- 6개 Class, 각각 약 3,000장의 데이터를 사용했을 때 정확도가 크게 개선됨
- 실제 모델 적용에서는 데이터의 개수를 더 늘려서 적용
2차 학습 모델링 ( 정확도 55.1 % )
- Optimizer 변경 : Rmsprop → Adam
- Augmentation을 통한 Data 증폭 : Class당 1,000장 → 약 6,000장 ( Class별 약간의 차이 생김 )
- CNN Layer 개선 : Layer 추가, Dense값 증가
- 이미지 리사이징 : 128 x 128 이미지에서 64 x 64 사용 ( 학습속도 및 안정성 개선 )
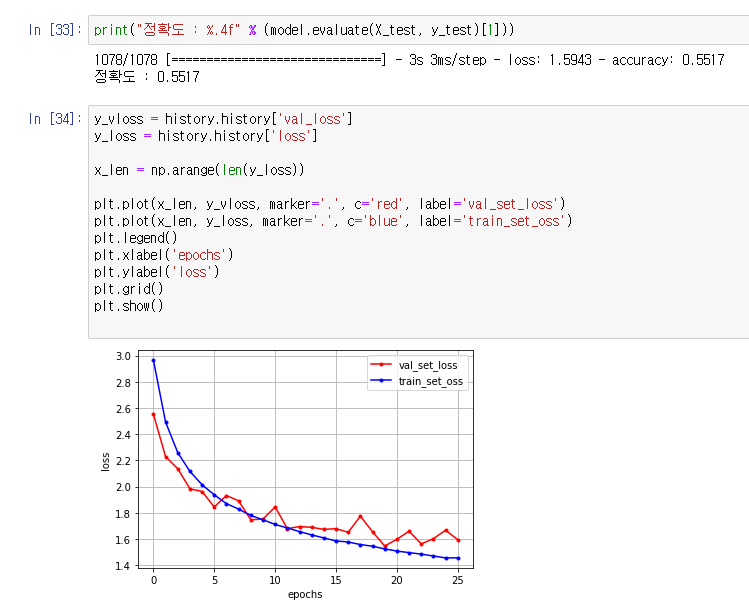
- 위 : Class Label을 20개로 축소했을 때, 아래 : Class Label : 30개
- 20개일때 정확도가 크게 달라진다면 20개로 줄이고자 했으나, 3%밖에 차이가 나지 않아 30개짜리 Class를 사용하기로 결정
- 안정적 궤도로 validation loss가 진입했고, train에 대한 효율도 증가됨
정리
- 55%는 만족스러운 정확도는 아니지만, 원본 이미지 수 자체가 너무 적었기에 낮은 정확도는 어느정도는 감안해야할 부분
- CNN 구조를 널리 알려진 구조로 사용하거나 하는 방식으로 추가적인 개선 방향 탐색
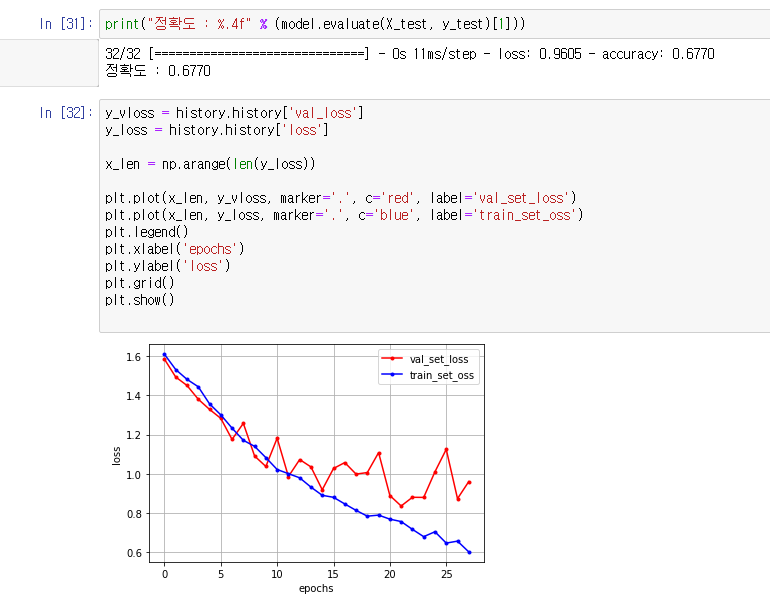
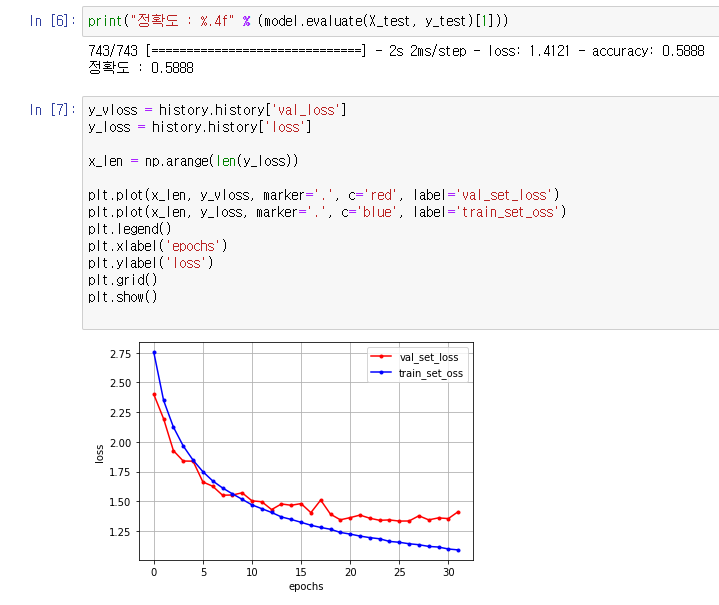
3차 학습 모델링 ( 정확도 62.9% )
- Optimizer 변경 : Adam → Nadam
- BatchNormalization Layer를 추가하여 배치 정규화 레이어를 구성
- He_Initialization 을 도입하여 가중치 초기화

- Parameter 수는 오히려 감소함 → 데이터수가 적은데 Parameter 수가 증가하면 학습률이 오히려 더 떨어지는 효과를 불러일으키기 때문
- batch_normalization 레이어를 drop_out 전에 배치하여 배치 정규화 실행 (학습 효율 증가)
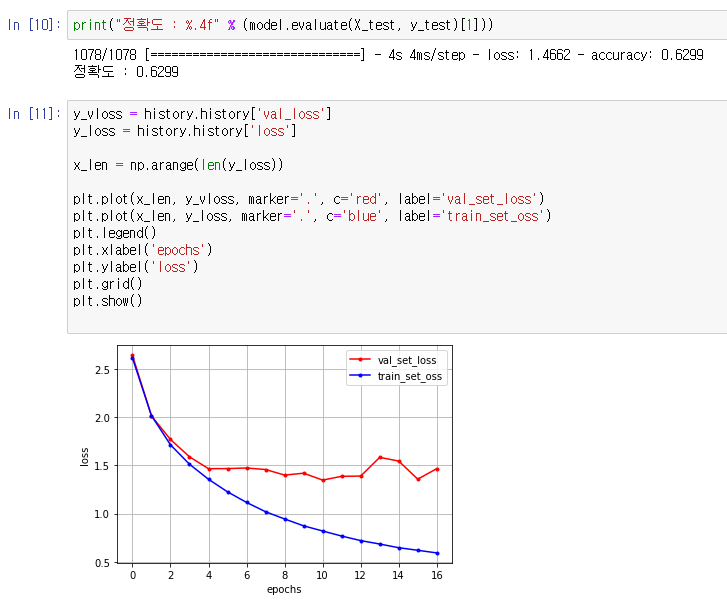
- 3차 결과 약 62.9%정도로 7~8%의 정확도 향상을 보임
- 그래프상으로 validation loss값이 증가한 것처럼 보이지만 실제로는 validation loss값은 감소하거나 유지되었으며, train의 효율이 올라가서 저러한 그래프의 모습을 보임
- validation loss값의 그래프가 전형적으로 overfiting 혹은 dataSet이 부족한 그래프의 양상을 보이는데, overfiting은 발생하지 않았으므로 Data의 부족때문에 발생하는 그래프 모양이라고 유추할 수 있음
최종 모델 학습 결과 ( 정확도 93.88% )


SW developer