지금부터는 KKT condition을 사용해서 binary SVM의 solution에 대해서 알아볼 것이다.
Hard Margin Classfier
Max Margin Classifier: Primal Form
Max margin classifier의 primal problem을 다음과 같이 정의할 수 있었다.
Primal Problem:
w,bminJ(w)=21∣∣w∣∣2
subject toyi(wTxi+b)≥1,i=1,…,N
Primal Lagrangian
이에 대해서 primal Lagrangian은 다음과 같이 나타낼 수 있게 된다.
Primal Lagrangian:
L(w,b,α)=21∣∣w∣∣2+i=1∑Nαi(1−yi(wTxi+b))
w,b는 primal variable이고 α는 Lagrangian variable 혹은 multiplier이다. 첫번째 항은 최소로 만들고자 하는 loss function 그대로이고, 두번째 항은 weight가 Lagrangian multiplier인 constraint gi의 weighted summation이다. 이때 primal problem에서의 constraint를 gi(w,b)≤0인 형태로 바꿔주면 1−yi(wTxi+b)≤0이 되고 이 식에 weight를 곱해서 더해주는 형태이다.
Optimal solution w,b를 구하기 위해서 KKT necessary conditon을 사용할 것이다. 첫번째 necessary condition인 stationay condition을 통해서 먼저 variable w,b에 대한 derivative를 구하고 0으로 두고자 한다. 그러면 다음과 같은 결과를 얻을 수 있게 된다.
∂w∂L=0⇒w=i=1∑Nαiyixi
∂b∂L=0⇒i=1∑Nαiyi=0
이렇게 얻은 결과 중 w에 관한 식은 이후에 깔끔하게 식을 정리하는데 사용이 된다. 그래서 이 식을 primal Lagrangian L에 대입시켜주면 다음과 같이 식이 정리가 된다. b에 관한 결과는 이후에 constraint로 사용이 될 것이다.
Primal Lagrangian에서 α가 고정된 값이라면 primal solution이 보장될 것이다. 그래서 constrainted optimization problem을 풀기 위해서 먼저 α에 대한 optimization을 할 필요가 있어서 위와 같이 α에 대한 dual problem이 된 것이다. 그리고 여기서 constraint는 위에서 KKT condition에 따라 b에 관한 식을 정리했을 때 얻은 결과이다.
Duality로부터 우리가 얻을 수 있는 것은 optimal α∗가 dual problem의 solution이고, linearly seperable training sample D={(xi,yi)})i=1N이 주어졌다는 가정에서 stationay condition으로부터 구했던 weight vector w∗=∑i=1Nαi∗yixi가 maximal margin hyperplane이 되어야만 한다.
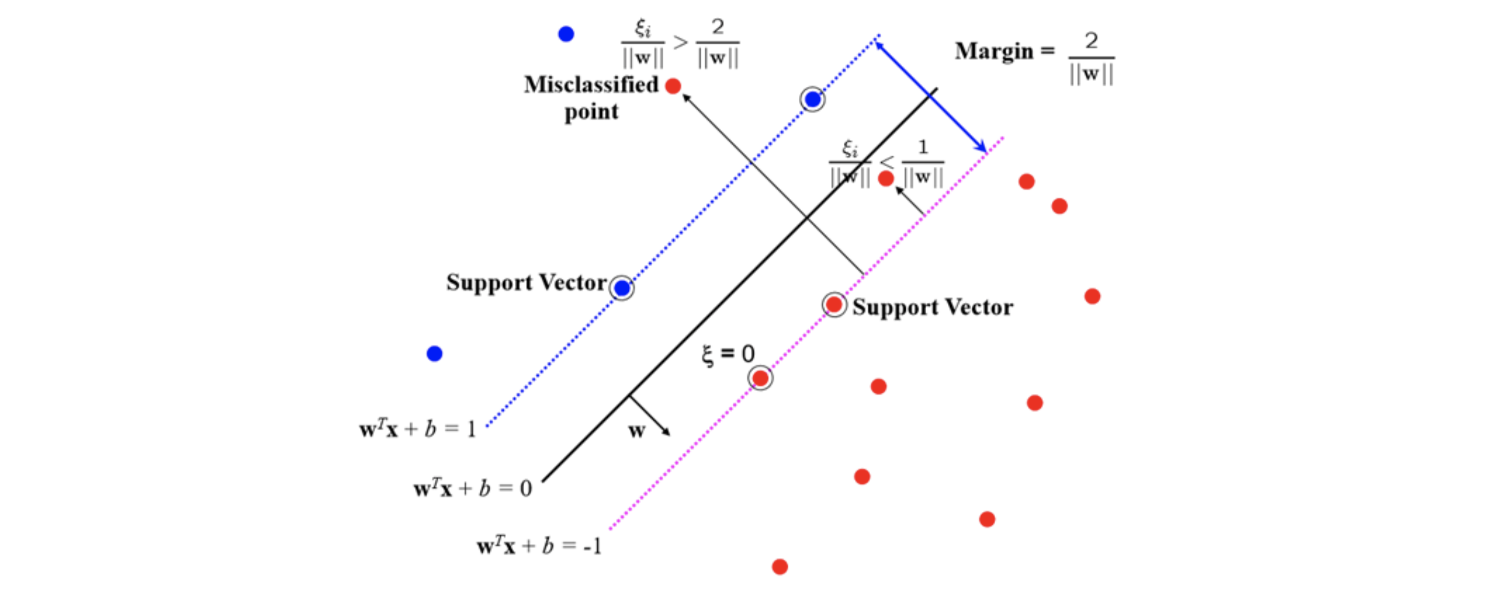
Support Vectors
다시 w의 식을 보면 training data point x들의 linear combination으로 되어 있는 것을 알 수 있다. 그러면 KKT condition 중에서 complimentary slackness condition으로부터 다음과 같은 결과를 얻을 수 있다.
νiαigi(w)[1−yi(wTxi+b)]=0
만약 gi(w)에 slackness가 존재한다면( yi(wTxi+b)=1 ), 이는 xi가 support vector가 아니라는 뜻이라서 이러한 xi는 해당 구역 안에 존재한다는 것이다. 그러면 이 data point는 slackness가 존재하게 되어 이에 대응하는 Lagrangian multiplier αi는 0이 되어야 한다. 또한 α가 0이 아니라는 이야기는 대응되는 data point가 support vector여야 하는 것이다. 그러면 yi(wTxi+b)=1을 만족하게 된다.
이로부터 알 수 있는 사실은 solution w는 오로지 support vector에만 의존한다는 것이다. 그래서 support vector들만이 w의 계산에 영향을 주게 된다. 그래서 우리가 찾고자 하는 것은 support vector들이고, 이러한 point들은 hyperplane을 직접적으로 제공해주게 된다. 대부분의 non-trivial classification 예시에서 우리는 margin을 최대로하는 optimal classifier를 얻을 수 있다.
Soft Margin Classfier
Slack Variables
가장 이상적인 경우는 dataset이 linearly separable한 경우이지만, 대부분의 경우는 data들이 linear하게 나뉘지를 못한다. 이러한 경우를 해결하기 위해서 slack variable을 추가하고자 한다. Slack variable ξ는 hyperplane을 기준으로 반대 방향에 잘못 존재하는 data point를 다루기 위한 것으로 다음과 같이 inequality constraint에 사용된다.
yn(wTxn+b)≥1−ξn
n=1,…,N
Graphical illustration에서 보다시피 반대 방향에 있는 data까지 허용해 줄 수 있는 조건이 추가된 것이고, 이는 constraint를 완화하여 error를 어느정도 허용하는 것이다.
Soft Margin Classfier: Primal-L2
이렇게 slack variable을 추가하게 되면 primal problem이 다음과 같이 정의된다.
Data들이 linearly separable하지 않으면 optimization problem은 풀릴 수 없다. 왜냐하면 primal problem의 경우 비어있는 feasible region을 가지게 되며 dual problem은 unbounded objective function을 가지게 되기 때문이다. 이러한 문제를 해결하고자 slack variable을 사용해서 margin constraint가 어느정도 벗어나도 허용해주고자 하는것이다. 흔히 slack variable ξ의 범위에 따라 classification의 범위가 달라진다.
ξ=0 : 정상적으로 분류
0<ξ≤1 : margin을 위반한 경우(margin 안쪽 지역에 존재)
ξ>1 : 잘못 분류
SVM은 classification을 할 때 일반적으로 margin을 크게 가져가는 방향으로 진행한다. 일반적으로 error가 아예 없지만 margin이 작은 classifier보다 error가 약간 있어도 margin이 큰 classfier를 더 선호하기는 한다. 왜냐하면 margin이 큰 classfier가 새로운 data에 대한 예측의 정확도가 더 높기 때문이다. 우리는 이렇게 margin을 최대로 만드는 것과 error의 개수를 줄이는 것 사이에서 어디에 더 초점을 맞출지를 parameter C로 조절할 수 있다.
여기서 C는 margin과 slackness 사이의 trade-off를 나타내는 parameter이다. C가 크다는 것은 잘못된 data들에 대해서 민감하겠다는 이야기라서 margin을 최대로 만들기 보다는 slackness를 줄이는데 더 집중하겠다는 의미이다. 즉, 허용되는 error의 개수가 작아야 하기에 오로지 margin에 집중하게 되어 margin이 좁아지게 되는 것이다. 반면, C가 작아지게 되면 margin을 최대로 만드는데 집중하게 되어 margin이 넓어져서 error의 허용이 많아지게 된다.
그리고 다시 primal problem에 Lagrangian method를 사용하면 다음과 같다.
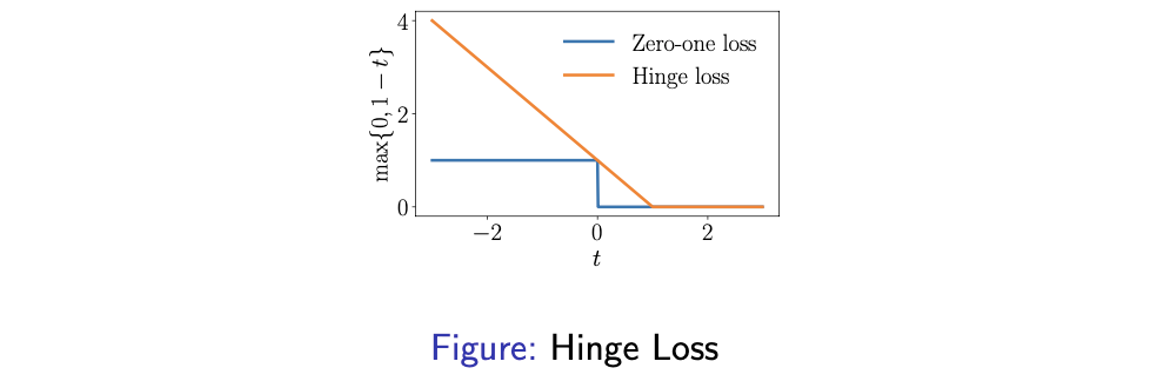
Soft margin SVM 혹은 soft SVM은 다음과 같이 loss의 관점으로 해석할 수도 있다. 여기서의 loss는 hinge loss라고 한다.
Hinge loss는 만약 yi(wTxi+b)>1라면 0일 것이고, 나머지 상황이라면 loss는 (1−yi(wTxi+b))가 될 것이다. 그리고 이를 간단하게 적으면 다음과 같이 나타낼 수 있다.
l(t)=max{0,1−(wTx+b)}
이러한 관점은 soft margin SVM이 하고자하는 것과 동일하다.
Unconstrained Optimization Problem
Hinge loss로부터 soft margin SVM을 unconstraind optimization problem으로 다시 정의할 수 있다.
w,bmin21∣∣w∣∣2+Ci=1∑N max{0,1−yn(⟨w,xn⟩)−b}
첫번째 항은 paramete w에 대한 regularizer이고, 두번째 항은 logistic regression에서와 같이 gradient method 등을 이용해서 optimization 할 수 있다.

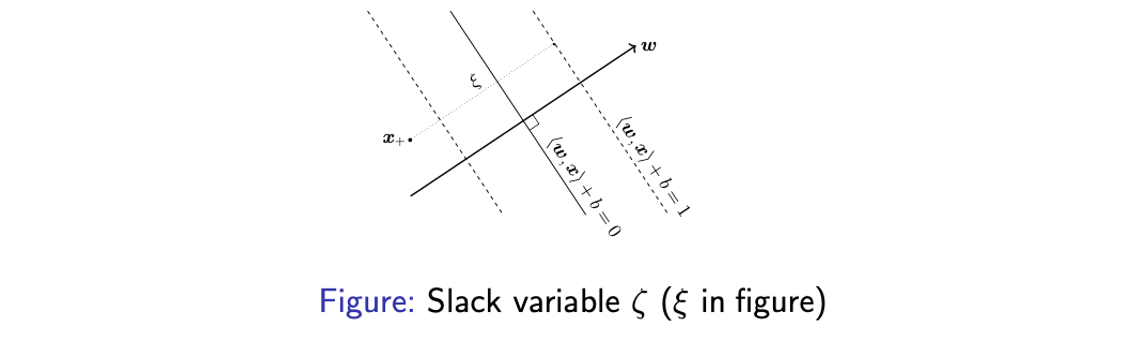 Graphical illustration에서 보다시피 반대 방향에 있는 data까지 허용해 줄 수 있는 조건이 추가된 것이고, 이는 constraint를 완화하여 error를 어느정도 허용하는 것이다.
Graphical illustration에서 보다시피 반대 방향에 있는 data까지 허용해 줄 수 있는 조건이 추가된 것이고, 이는 constraint를 완화하여 error를 어느정도 허용하는 것이다.