AdaGrad
x축 y축으로 생각하면 다음의 gradient방향이 수평이라면 x는 큰 lr을 y는 작은 lr로 대응하는 방법이다.

Hadamard product

element-wise product이다. 따라서 점화식에서는 각 원소를 제곱한 값이다.
hn은 누적이다. 따라서 시간이 갈수록 역수를 곱해준 lr의 값은 작아진다. 또한 큰 변화가 있었던 변수일 수록 lr은 작아진다. 누적으로 생각하면 제자리에 머물고 있던 친구는 더 크게 바꿔줘야하고 많이 움직인 친구는 더 적게 움직여야 한다.
예제 풀이
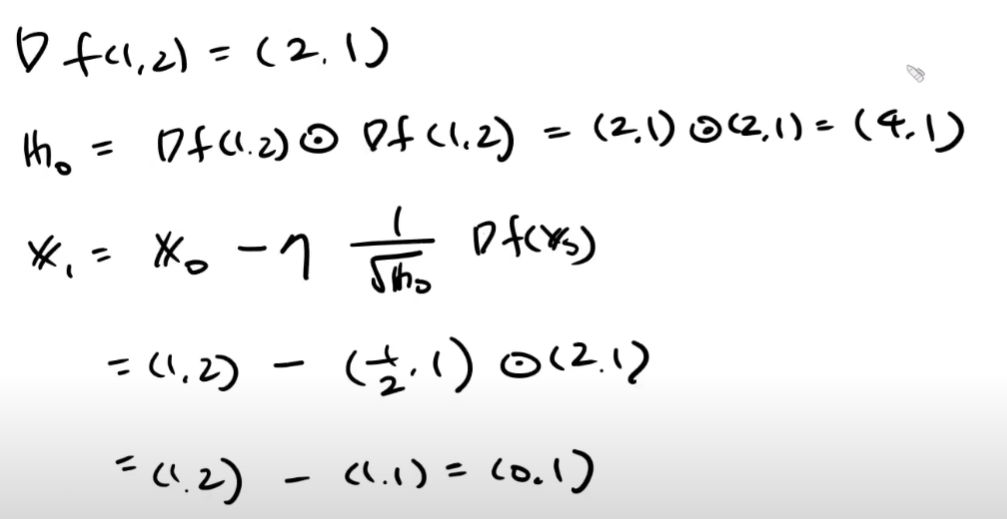
코드 구현
class AdaGrad:
def __init__(self, lr=0.01):
self.lr = lr
self.h = None
def update(self, params, grads):
if self.h in None:
for key, val in params.items():
self.h[key] = np.zeros_like(val)
for key in params.keys():
self.h[key] += grads[key] * grads[key]
parmas[key] -= self.lr * grads[key] / (np.sqrt(self.h[key]) + 1e-7)RMSProp
hn이 시간이 갈수록 커져서 lr이 결국에 엄청나게 작아진다. 이 문제를 해결하기 위해서 RMSProp이 등장한다.

hn에 제곱을 계속 더하는 것이 아니라 감마 값을 도입함으로써 내분을 해서 더한다. 가령 감마값이 1/2라면 평균값이 될 것이다. 따라서 감마를 forgetting factor라고도 부른다. 감마값이 커지면 과거값의 비중이 더 커진다. 내분을 수학적으로 convex combination이라고도 부른다.
예제 풀이
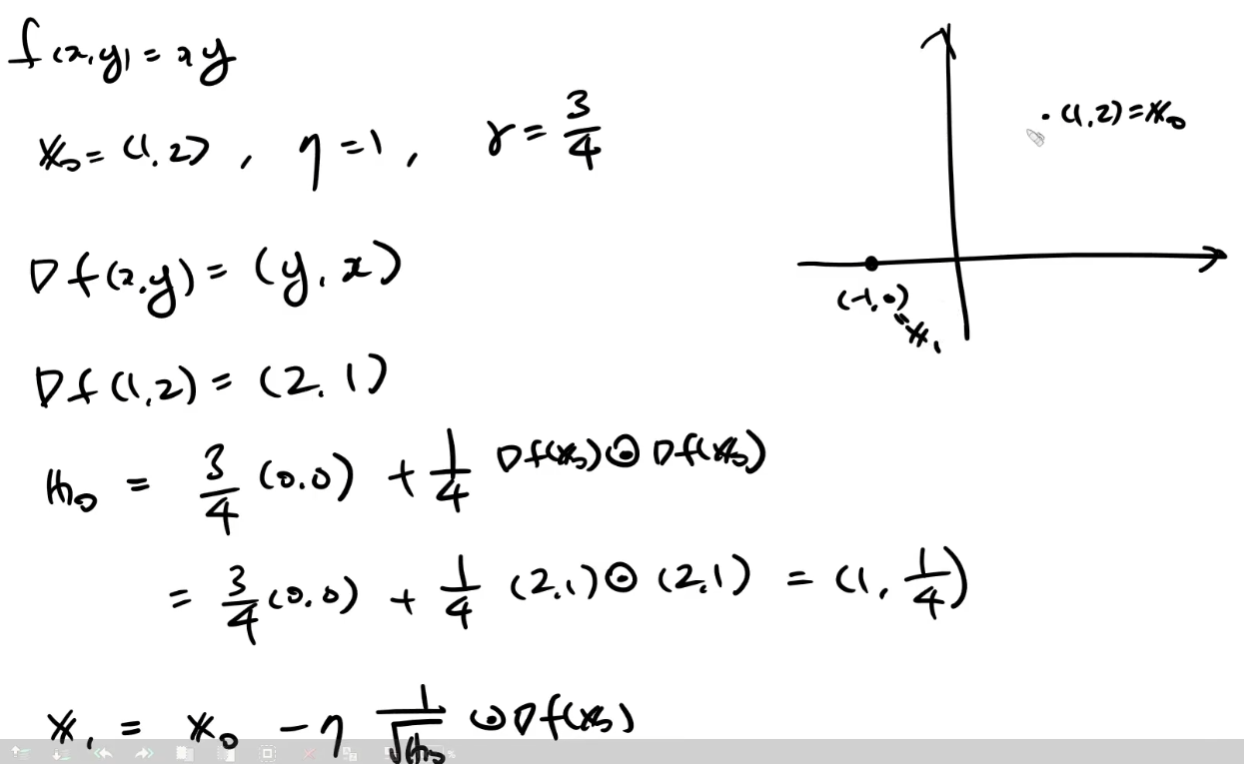
코드 구현
class RMSProp:
def __init__(self, lr=0.01, decay_rate = 0.99):
self.lr = lr
self.decay_rate = decay_rate
self.h = None
def update(self, params, grads):
if self.h is None:
self.h = {}
for key, val in params.items():
self.h[key] = np.zeros_like(val)
for key in params.keys():
self.h[key] *= self.decay_rate
self.h[key] += (1 - self.decay_rate) * grads[key] * grads[key]
parmas[key] -= self.lr * grads[key] / (np.sqrt(self.h[key]) + 1e-7)Adam
지금까지 배운 optimizer를 정리해보자. Momentum은 새로운 값인 관성 v를 가져왔고, NAG는 값을 계산하는 방식을 바꿔주었다. Adagrad는 learning rate를 보정하는 새로운 값인 h를 가져왔고, RMSProp은 여기에 직전값을 더 참고하기 위해 내분이라는 조정방식을 가져왔다.
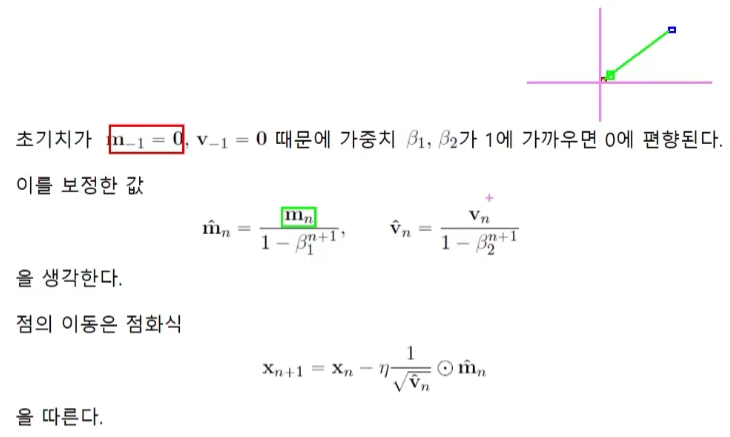
Adam에서 m이 momentum값이고, v가 learning rate조정 값이다.

내분의 문제점을 극복하기 위해서 보정한 값을 사용한다. 횟수가 반복되어 n의 값이 커지게 되면 분모의 값은 (0.9)^n이 0에 가까워지며 1이 되게 된다.
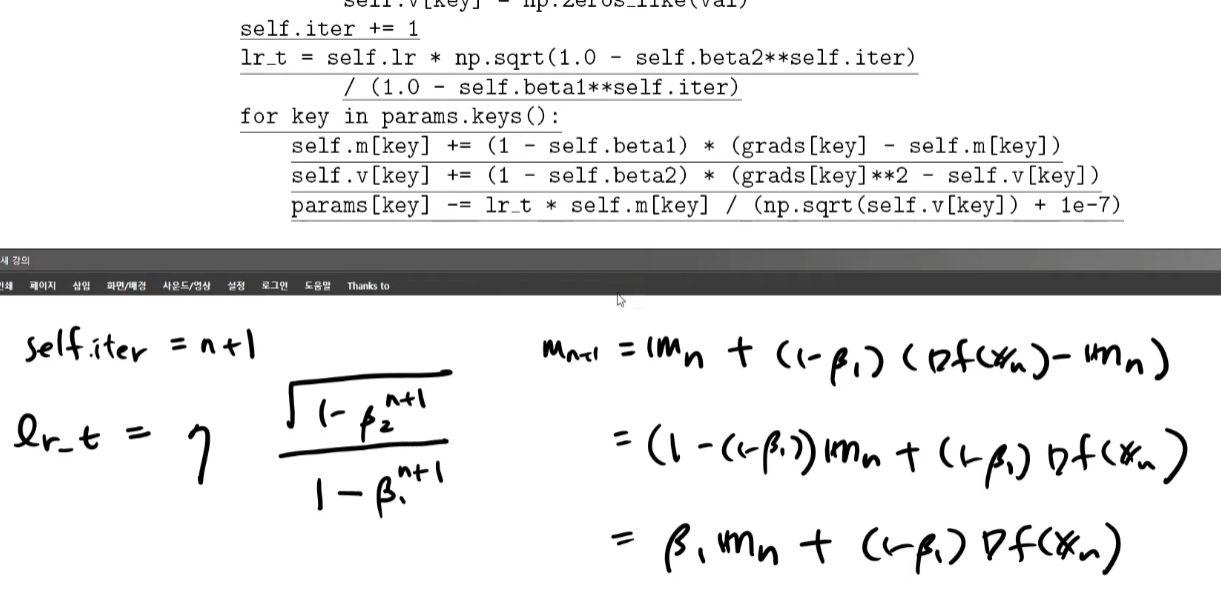
코드 구현
m, v의 점화식을 코드로 만드는게 까다롭다.
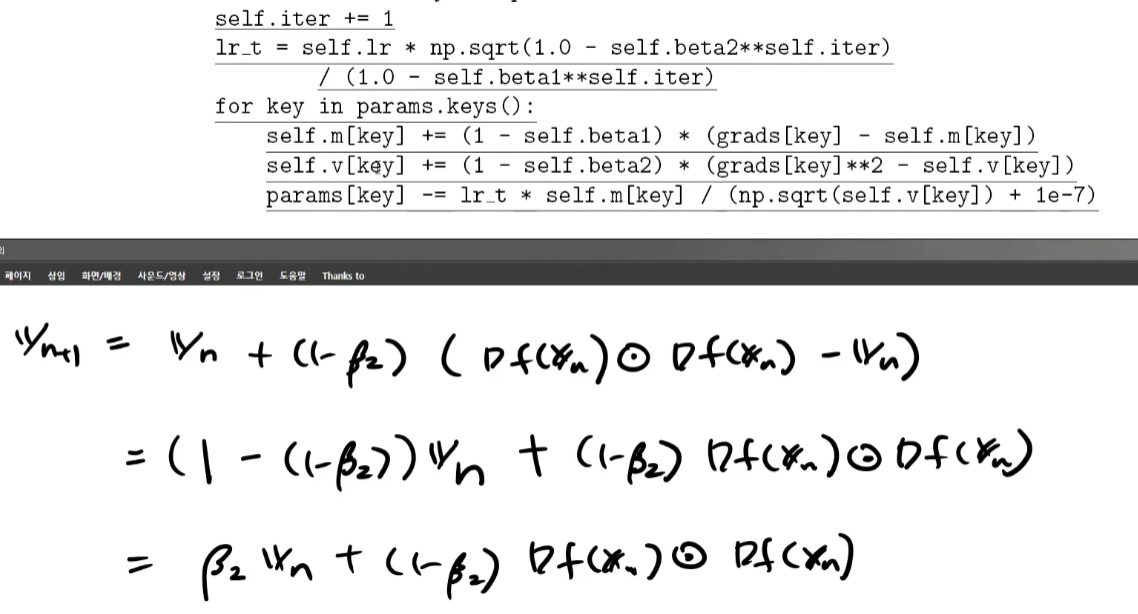
마지막으로 보정된 값을 통한 점의 이동도 직접 수식을 풀어봐야 한다.

class Adam:
def __init__(self, lr=0.01, beta1=0.9, beta2=0.999):
self.lr = lr
self.beta1 = beta1
self.beta2 = beta2
self.iter = 0
self.m = None
self.v = None
def update(self, params, grads):
if self.m is None:
self.m, self.v = {}, {}
for key, val in params.items():
self.m[key] = np.zeros_like(val)
self.v[key] = np.zeros_like(val)
self.iter += 1
lr_t = self.lr * np.sqrt(1.0 - self.beta2**self.iter) / (1.0 - self.beta1**self.iter)
for key in params..keys():
self.m[key] += (1 - self.beta1) * (grads[key] - self.m[key])
self.v[key] += (1 - self.beta2) * (grads[key]**2 - self.v[key])
params[key] -= lr_t * self.m[key] / (np.sqrt(self.v[key]) + 1e-7)