SimpleConvNet
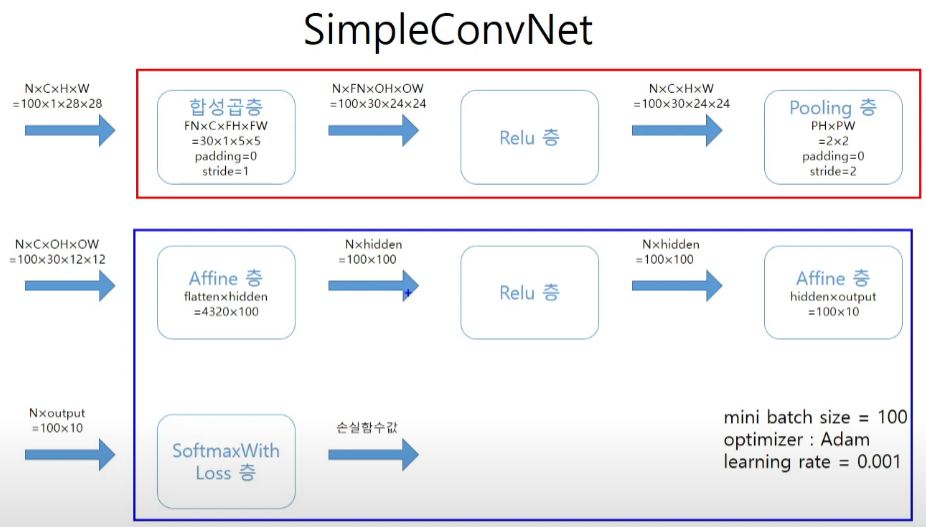
코드구현
class SimpleConvNet:
'''
conv - relu - pool - affine - relu - affine - softmax
'''
def __init__(self, input_dim=(1,28,28),
conv_param={'filter_num':30, 'filter_size':5, 'pad':0, 'stride':1},
hidden_size=100, output_size=10, weight_init_std=0.01):
filter_num = conv_param['filter_num']
filter_size = conv_param['filter_size']
filter_pad = conv_param['pad']
filter_stride = conv_param['stride']
input_size = input_dim[1]
conv_output_size = (input_size - filter_size + 2*filter_pad) / filter_stride +1
# affine층에 넣어주기 위해서 flatten한 크기
pool_output_size = int(filter_num * (conv_output_size/2) * (conv_output_size/2))
# 가중치 초기화
# Conv, Affine, Affine에서 사용된다.
self.params = {}
self.params['W1'] = weight_init_std * np.random.randn(filter_num, input_dim[0], filter_size, filter_size)
self.params['b1'] = np.zeros(filter_num)
self.params['W2'] = weight_init_std * np.random.randn(pool_output_size, hidden_size)
self.params['b2'] = np.zeros(hidden_size)
self.params['W3'] = weight_init_std * np.random.randn(hidden_size, output_size)
self.params['b3'] = np.zeros(output_size)
# 계층 생성
self.layers = OrderedDict()
self.layers['Conv1'] = Convolution(self.params['W1'], self.params['b1'], conv_param['stride'], conv_param['pad'])
self.layers['Relu1'] = Relu()
self.layers['Pool1'] = Pooling(pool_h=2, pool_w=2, stride=2)
self.layers['Affine1'] = Affine(self.params['W2'], self.params['b2'])
self.layers['Relu2'] = Relu()
self.layers['Affine2'] = Affine(self.params['W3'], self.params['b3'])
self.last_layer = SoftmaxwithLoss()
def predict(self, x):
for layer in self.layers.values():
x = layer.forward(x)
return x
def loss(self, x, t):
y = self.predict(x)
return self.last_layer.forward(y, t)
def accuracy(self, x, t, batch_size=100):
if t.ndim != 1:
t = np.argmax(t, axis=1)
acc = 0.0
for i in range(int(x.shape[0] / batch_size)):
tx = x[i*batch_size : (i+1)*batch_size]
tt = t[i*batch_size : (i+1)*batch_size]
y = self.predict(tx)
y = np.argmax(y, axis=1)
acc += np.sum(y == tt)
return acc / x.shape[0]
def numerical_gradient(self, x, t):
# 수치미분
loss_w = lambda w : self.loss(x, t)
grads = {}
for idx in (1, 2, 3):
grads['W' + str(idx)] = numerical_gradient(loss_w, self.params['W' + str(idx)])
grads['b' + str(idx)] = numerical_gradient(loss_w, self.params['b' + str(idx)])
return grads
def gradient(self, x, t):
# 오차역전파법
# forward
self.loss(x, t)
# backward
dout = 1
dout = self.last_layer.backward(dout)
layers = list(self.layers.values())
layers.reverse()
for layer in layers:
dout = layer.backward(dout)
# 결과저장
grads = {}
grads['W1'], grads['b1'] = self.layers['Conv1'].dW, self.layers['Conv1'].db
grads['W2'], grads['b2'] = self.layers['Affine1'].dW, self.layers['Affine1'].db
grads['W3'], grads['b3'] = self.layers['Affine2'].dW, self.layers['Affine2'].db
return grads
def save_params(self, file_name='params.pkl'):
params = {}
for key, val in self.params.items():
params[key] = val
with open(file_name, 'wb') as f:
pickle.dump(params, f)
def load_params(self, file_name='params.pkl'):
with open(file_name, 'rb') as f:
params = pickle.load(f)
for key, val in params.items():
self.params[key] = val
for i, key in enumerate(['Conv1', 'Affine1', 'Affine2']):
self.layers[key].W = self.params['W' + str(i+1)]
self.layers[key].b = self.params['b' + str(i+1)]학습
max_epochs = 20
network = SimpleConvNet(input_dim=(1, 28, 28),
conv_param = {'filter_num':30, 'filter_size':5, 'pad':0, 'stride':1},
hidden_size=100, output_size=10, weight_init_std=0.01)
trainer = Trainer(network, x_train, t_train, x_test, t_test,
epochs=max_epochs, mini_batch_size=100,
optimizer='Adam', optimizer_param={'lr':0.001},
evaluate_sample_num_per_epoch=1000)
trainer.train()markers = {'train':'o', 'test':'s'}
x = np.arange(4)
plt.plot(x, trainer.train_acc_list, marker='o', label='train', markevery=2)
plt.plot(x, trainer.test_acc_list, marker='s', label='test', markevery=2)
plt.xlabel("epochs")
plt.ylabel("accuracy")
plt.ylim(0, 1.0)
plt.legend(loc='lower right')
plt.show()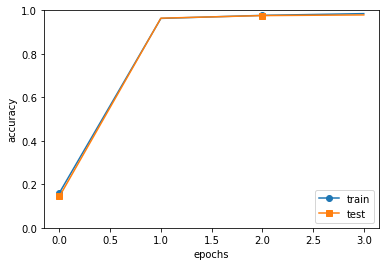
추가 내용
https://youtu.be/iqtzKGI3evU
conv network를 통과한 이미지의 size를 다시금 체크해보기
학습한 network의 conv에서 필터가 찾아낸 이미지를 보는법
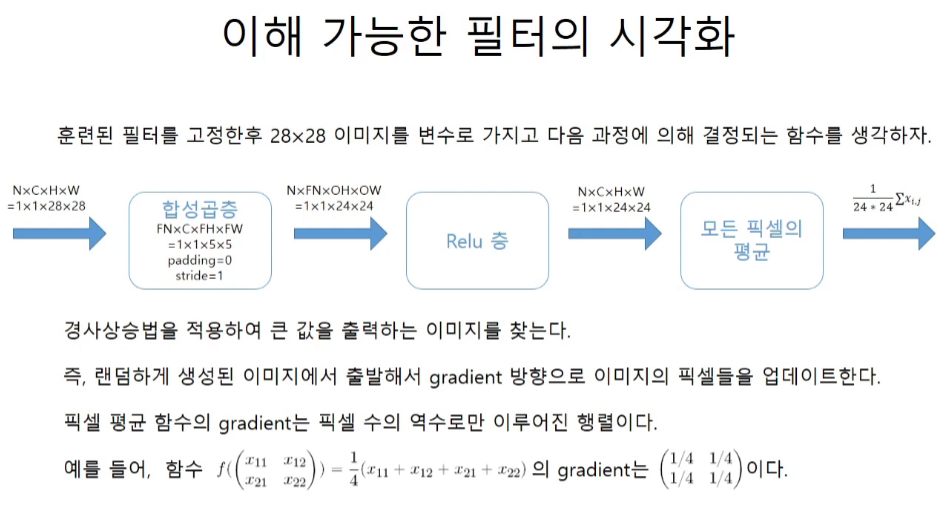

chords & code // harmony with structure