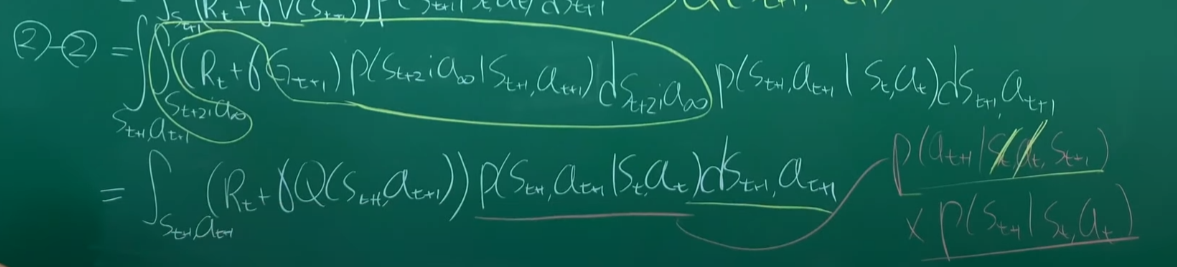상태 가치함수, 행동 가치함수, Optimal Policy
강화학습은 expected return을 최대화 하는 것이 목표이고, 그 목표를 달성하는 action을 뱉어주는 policy들을 찾아나가게 된다.
expected return을 잘 표현하는 2가지 방법인 state value function, action value function을 알아보자.
State Value Function
지금 이 state에서 기대되는 Return이다.
Action Value Function
지금 이 state에서의 어떤 행동으로부터 기대되는 Return이다.
Optimal Policy
return을 최대한으로 키워줄 수 있는 action
수식
State Value Function
행동 하나하나는 이산적인 과정이지만 그 경우의 수는 셀 수 없을 만큼 많기 때문에 기대값 E를 계산할 때에 적분을 한다.
지금 상태에서의 at행동의 경우의 수 중에 하나를 뽑고, 그 다음 st+1상태에서 가능한 at+1경우의 수 중에서 하나를 뽑고... 이것을 무한대로 이어나가는 경우의 수들 각각의 확률을 구해서 리턴과 곱한 뒤 적분해주면 svf가 나온다.

Action Value Function
현재 state에서 어떤 행동을 했을때부터 쭉 진행한 기대되는 return

Optimal Policy
V(St)를 maximize하는 action들의 모임
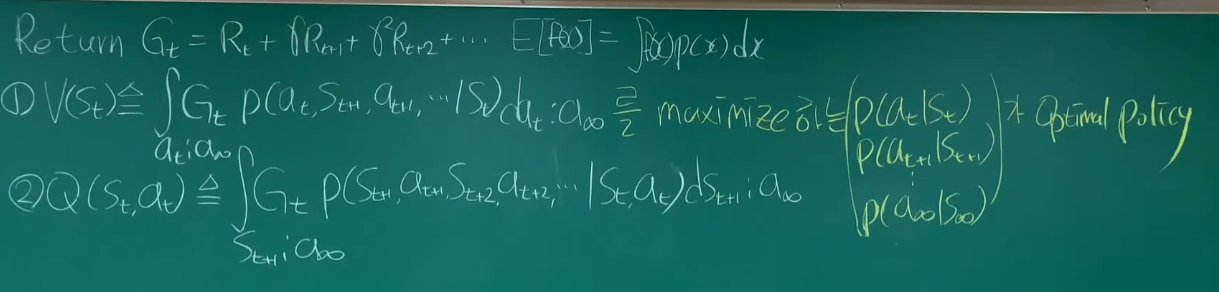
Bellman equation
V라는 것을 Q라고도 표현할 수 있고, 이를 바꿔서도 가능하고
다음 t+1로도 표현할 수 있게 해주는 방정식이다.
V value Bellman equation
Bayes rule 적용하기
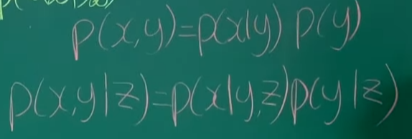
V to Q
State에서 기대되는 return 값은 이렇게 이해해볼 수 있다.
state안의 action들의 Q값을 평균을 내는 것.
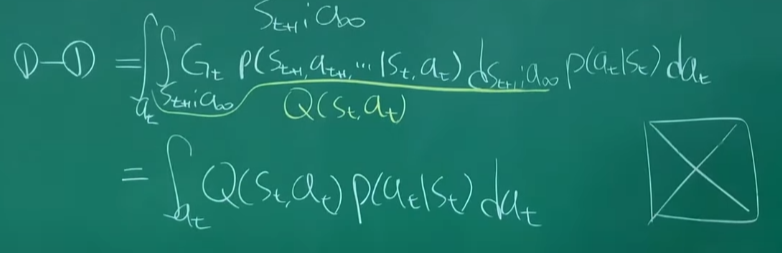
st+1을 꺼내보기
Markov Decision process에 따라 St+1은 st at모두의 값을 가지고 있으므로 이 둘을 생략이 가능하다.

Vst+1로 표현하기
Gt를 아래와 같이 다르게 표현할 수 있다.

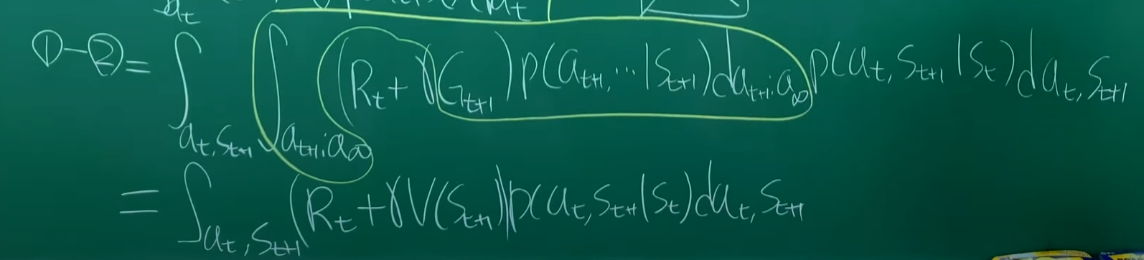
풀어쓰기, 적분할 거리를 줄여준다.
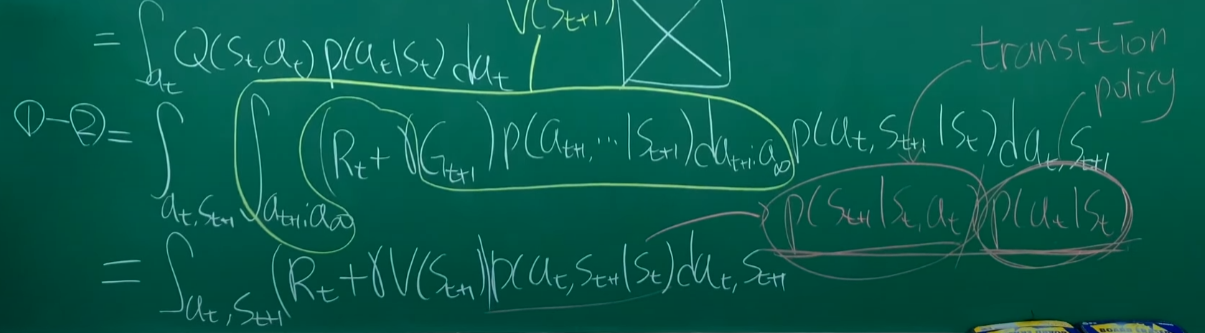
Q value Bellman equation
Q to Vst+1
Q를 next V로 표현이 가능하다. 숨어있는 V를 찾자.
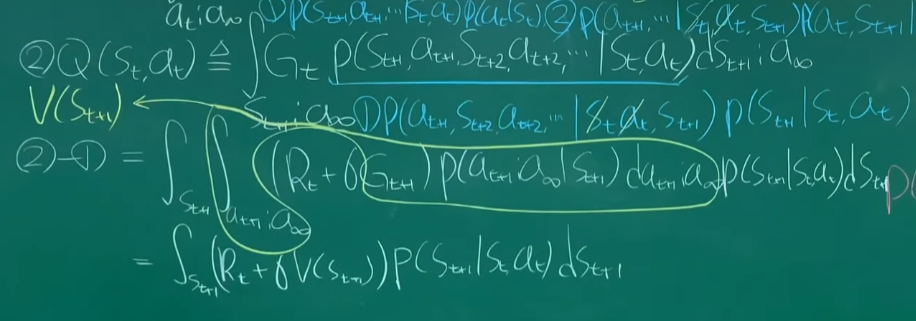
Qst+1로 표현하기
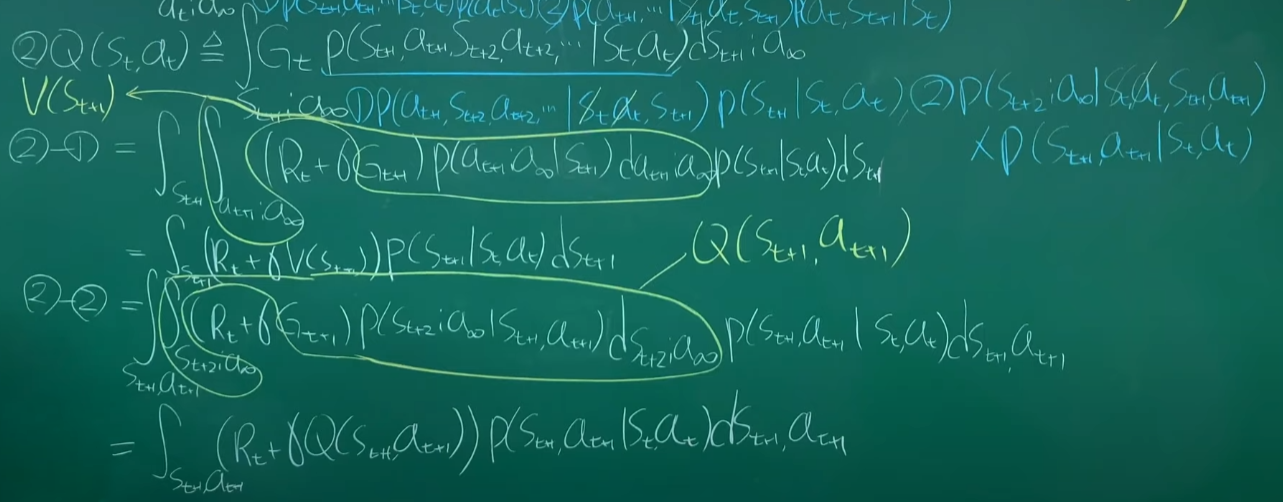
풀어쓰기, 적분할 거리를 줄여준다.
transition과 policy