지켜주어야 할것
1.어떤 단어의 의미는 주변의 문맥에 의해서 결정
2.벡터 안에 단어의 의미가 녹아 있어야 하며
3.벡터가 너무 커지면 안된다.
count vs. prediction

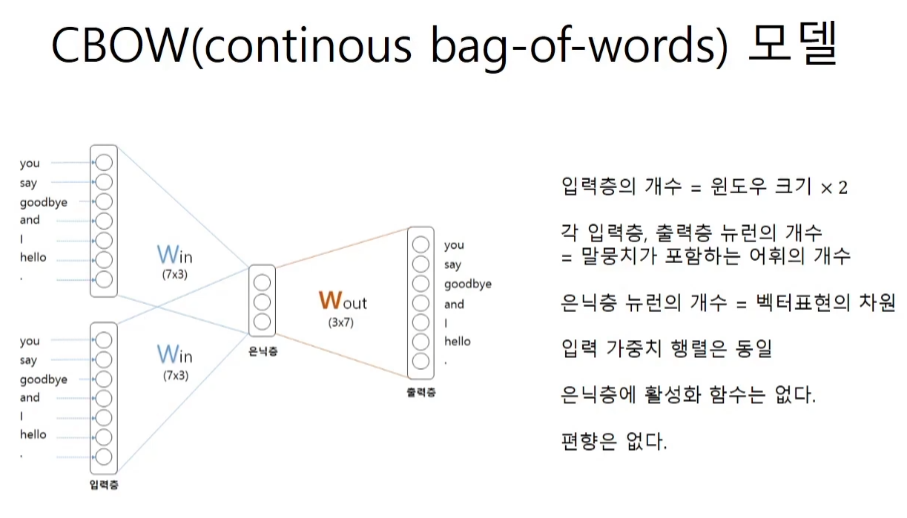
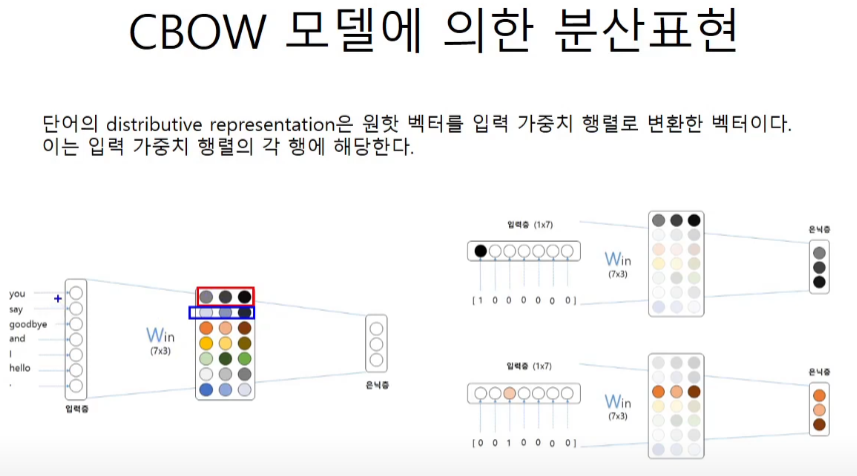
CBOW모델
conv까지는 입력이 1개였지만 이제는 window size에 맞춰서 입력을 넣는다.
you와 goodbye를 넣으면 사이의 say를 예측해줘야 한다.
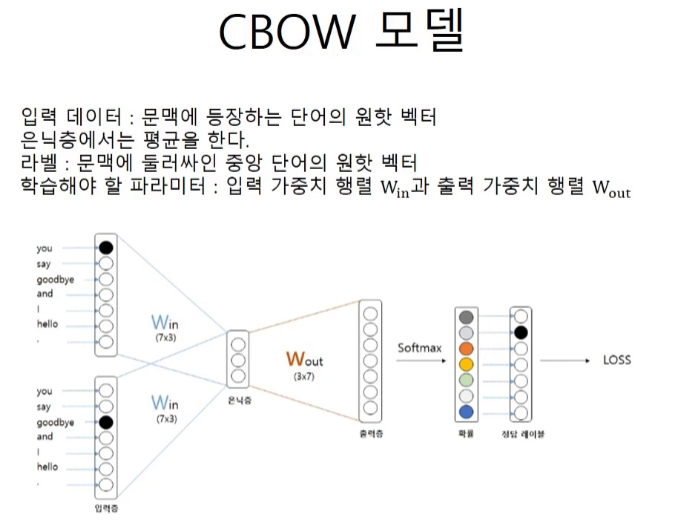
은닉층에서 3차원의 벡터는 x1w + x2w / 2로 평균을 해준다.
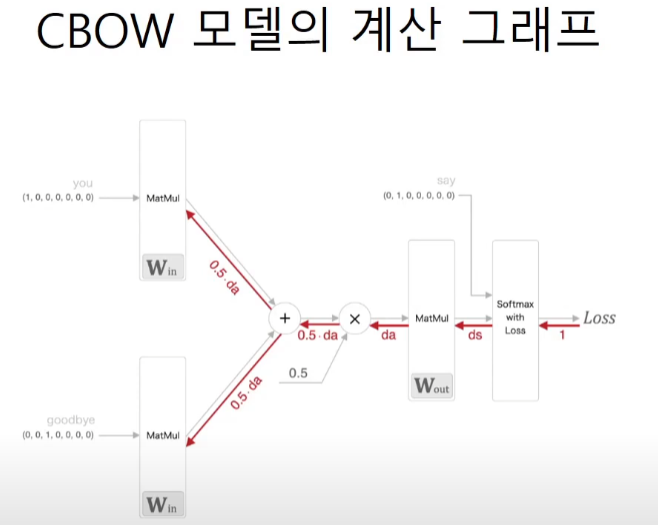
gradient의 반대방향으로 움직인다는 것을 잘 보여준다.
softmax with loss의 역전파값인 y - t 또한 마찬가지이다.
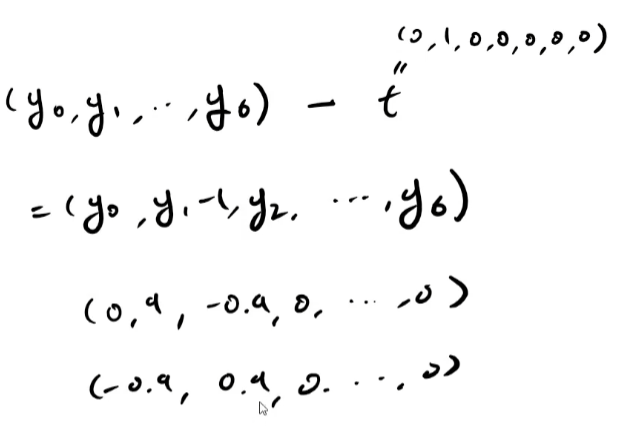
CBOW모델에 의한 분산표현
코드 구현
# 샘플 맥락 데이터
c0 = np.array([[1, 0, 0, 0, 0, 0, 0]])
c1 = np.array([[0, 0, 1, 0, 0, 0, 0]])
# 가중치 초기화
W_in = np.random.randn(7, 3)
W_out = np.random.randn(3, 7)
# 계층 생성
in_layer0 = MatMul(W_in)
in_layer1 = MatMul(W_in)
out_layer = MatMul(W_out)
# 순전파
h0 = in_layer0.forward(c0)
h1 = in_layer1.forward(c1)
h = 0.5 * (h0 + h1)
s = out_layer.forward(h)
print(s)
# [[-0.51567904 -0.30089453 -0.56750226 -1.67136134 -0.16865318 -0.7496344
-1.35269193]]class SimpleCBOW:
def __init__(self, vocab_size, hidden_size):
V, H = vocab_size, hidden_size
# 가중치 초기화
W_in = 0.01 * np.random.randn(V, H).astype('f')
W_out = 0.01 * np.random.randn(H, V).astype('f')
# 계층생성
self.in_layer0 = MatMul(W_in)
self.in_layer1 = MatMul(W_in)
self.out_layer = MatMul(W_out)
self.loss_layer = SoftmaxWithLoss()
# 모든 가중치와 기울기를 리스트에 모은다.
layers = [self.in_layer0, self.in_layer1, self.out_layer0]
self.params, self.grads = [], []
for layer in layers:
self.params += layer.params
self.grads += layer.grads
# 인스턴스 변수에 단어의 분산 표현을 저장한다.
self.word_vecs = W_in
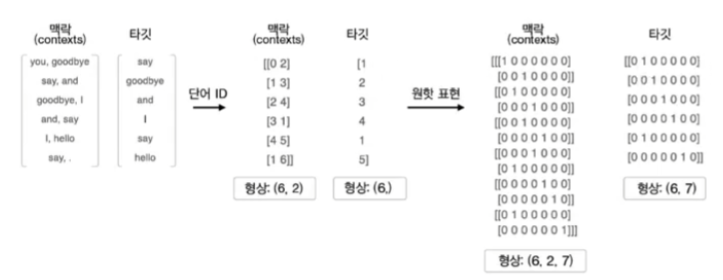
# context는 양쪽의 단어들의 배치, window, one-hot의 3차원, target은 중간의 단어들의 배치
# CBOW 강의에 맥락과 타깃 이미지를 참고
def forward(self, contexts, target):
h0 = self.in_layer0.forward(contexts[:, 0])
h1 = self.in_layer1.forward(contexts[:, 1])
h = (h0 + h1) * 0.5
score = self.out_layer.forward(h)
loss = self.loss_layer.forward(score, target)
return loss
def backward(self, dout=1):
ds = self.loss_layer.backward(dout)
da = self.out_layer.backward(ds)
da *= 0.5
self.in_layer1.backward(da)
self.in_layer1.backward(da)
return None코드 구체적인 설명
갈수록 코드가 어려워지고 양 자체가 많아진다. 그래도 가능하면 다 설명해주려고 하시는 한경훈 교수님... 최고시다.
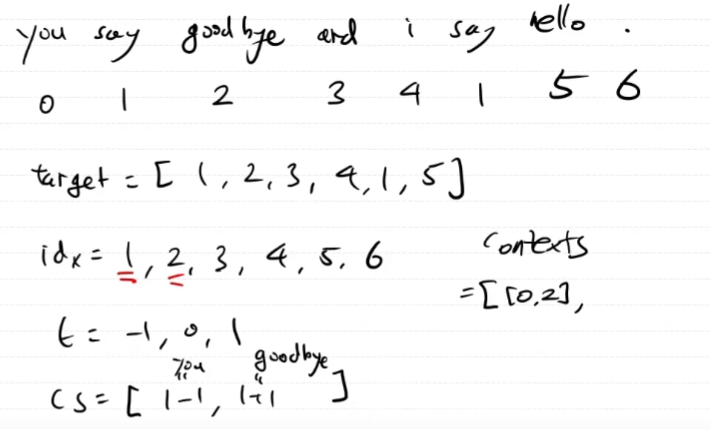
def create_contexts_target(corpus, window_size=1):
'''맥락과 타깃 생성
:param corpus: 말뭉치(단어 ID 목록)
:param window_size: 윈도우 크기(윈도우 크기가 1이면 타깃 단어 좌우 한 단어씩이 맥락에 포함)
:return:
'''
# 타깃은 corpus의 사이 값들을 순서대로 모은 모임이다.
target = corpus[window_size:-window_size]
contexts = []
for idx in range(window_size, len(corpus)-window_size):
cs = []
for t in range(-window_size, window_size + 1):
if t == 0:
continue
cs.append(corpus[idx + t])
contexts.append(cs)
return np.array(contexts), np.array(target)def convert_one_hot(corpus, vocab_size):
'''원핫 표현으로 변환
:param corpus: 단어 ID 목록(타깃, 1차원 또는 맥락, 2차원 넘파이 배열)
:param vocab_size: 어휘 수
:return: 원핫 표현(2차원 또는 3차원 넘파이 배열)
'''
N = corpus.shape[0]
if corpus.ndim == 1:
one_hot = np.zeros((N, vocab_size), dtype=np.int32)
for idx, word_id in enumerate(corpus):
one_hot[idx, word_id] = 1
elif corpus.ndim == 2:
C = corpus.shape[1]
one_hot = np.zeros((N, C, vocab_size), dtype=np.int32)
for idx_0, word_ids in enumerate(corpus):
for idx_1, word_id in enumerate(word_ids):
one_hot[idx_0, idx_1, word_id] = 1
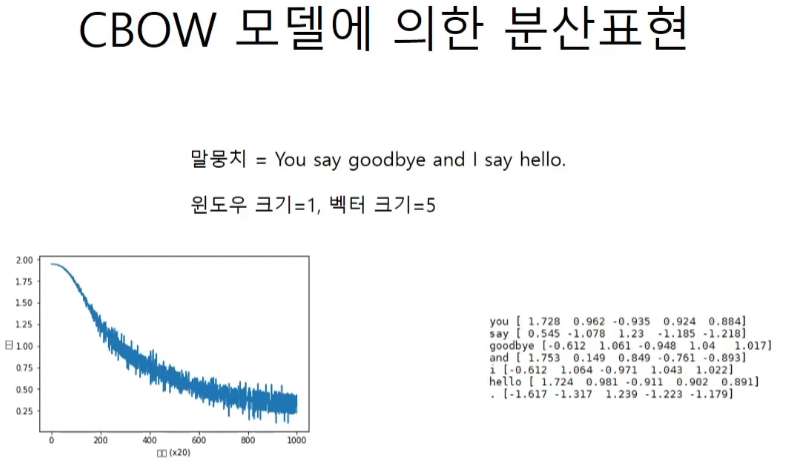
return one_hot분산표현 코드실행
window_size = 1
hidden_size = 5
batch_size = 3
max_epoch = 1000
text = 'You say goodbye and I say hello.'
corpus, wi, iw = preprocess(text)
vocab_size = len(wi)
contexts, target = create_contexts_target(corpus, window_size)
target = convert_one_hot(target, vocab_size)
contexts = convert_one_hot(contexts, vocab_size)
model = SimpleCBOW(vocab_size, hidden_size)
optimizer = Adam()
trainer = Trainer(model, optimizer)
trainer.fit(contexts, target, max_epoch, batch_size)
trainer.plot()
word_vecs = model.word_vecs
for word_id, word in iw.items():
print(word, word_vecs[word_id])
#you [-0.0042142 0.00685373 -0.01312936 0.005315 0.01544064]
#say [ 2.756782 2.940101 -2.9381502 -2.5332973 -2.8503218]
#goodbye [-3.0250142 2.8940434 -2.9004219 -3.3253543 3.016829 ]
#and [ 2.822766 2.9648054 -2.9323518 -2.3326855 -2.7550478]
#i [-2.6481018 2.235453 -2.3665164 3.6335626 2.0386212]
#hello [-2.8073537 2.7569518 -2.7506216 -3.709168 2.9120212]
#. [ 2.9455128 -3.1479921 3.1574292 -3.0516212 -2.873749 ]
Skip-gram 모델
단어로부터 맥락을 추측하는 것이 좀더 어려운 프로세스이다.
윈도우가 더 커지면 예측이 더 어려워진다.
입력은 하나인데 출력은 둘이라네~

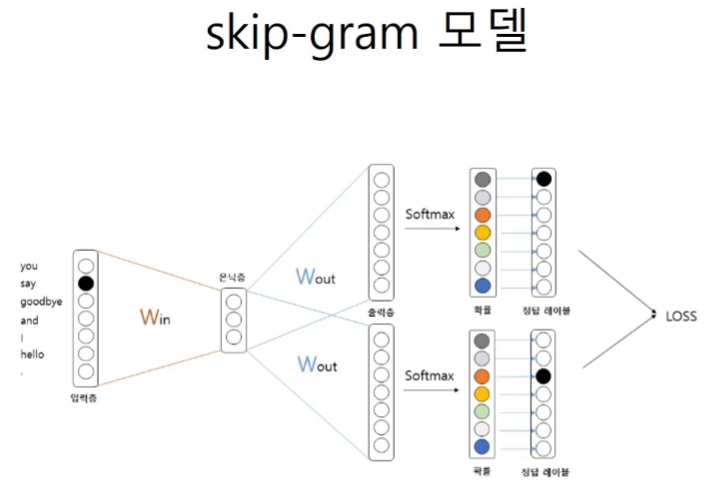
CBOW와 비슷한 구조다.
class SimpleSkipGram:
def __init__(self, vocab_size, hidden_size):
V, H = vocab_size, hidden_size
# 가중치 초기화
W_in = 0.01 * np.random.randn(V, H).astype('f')
W_out = 0.01 * np.random.randn(H, V).astype('f')
# 계층 생성
self.in_layer = MatMul(W_in)
self.out_layer = MatMul(W_out)
self.loss_layer1 = SoftmaxWithLoss()
self.loss_layer2 = SoftmaxWithLoss()
# 모든 가중치와 기울기를 리스트에 모은다.
layers = [self.in_layer, self.out_layer]
self.params, self.grads = [], []
for layer in layers:
self.params += layer.params
self.grads += layer.grads
# 인스턴스 변수에 단어의 분산 표현을 저장한다.
self.word_vecs = W_in
def forward(self, contexts, target):
h = self.in_layer.forward(target)
s = self.out_layer.forward(h)
l1 = self.loss_layer1.forward(s, contexts[:, 0])
l2 = self.loss_layer2.forward(s, contexts[:, 1])
loss = l1 + l2
return loss
def backward(self, dout=1):
dl1 = self.loss_layer1.backward(dout)
dl2 = self.loss_layer2.backward(dout)
ds = dl1 + dl2
dh = self.out_layer.backward(ds)
self.in_layer.backward(dh)
return None
chords & code // harmony with structure