서론
기계학습 수업중에, K평균알고리즘이란것을 배웠다.
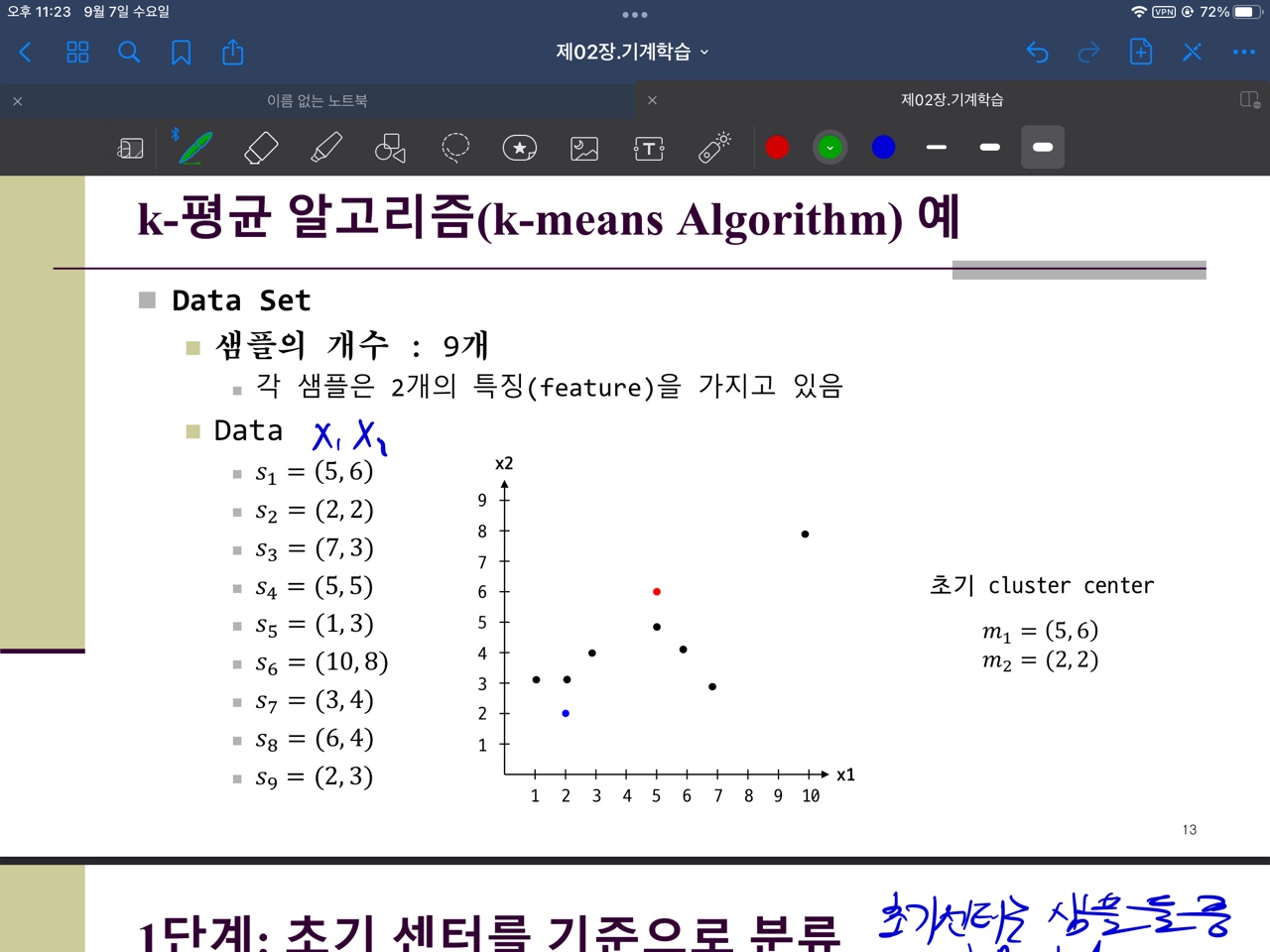
되게 직관적이고, 단순한 알고리즘이라 직접구현 해볼만하다는 생각에 C언어로 도전해봤다.
알고리즘
먼저 알고리즘의 작동 순서는 아래와같다.
- 각샘플들을 입력받는다.(필자는 2개의 특징벡터를 가지고 이를 각각 x, y로 제한하였다.)
- K개의 클러스터 중심점을 입력받은 샘플중에서 정한다.
(이 또한 필자는 K=2로 2개의 중심점이될 샘플을 임의 로정하였다.)- 모든 샘플을 K개의 클러스터중심점과의 거리를 구하여, 더 가까운 클러스터에 속하도록 그룹핑한다.
- 그룹핑된 클러스터내의 샘플들간의 평균을 구하여 해당 클러스터의 중심점을 다시 구해본다.
- 만약 3번과정후에 중심점의 좌표가 ε보다 충분히 작을때까지 1~ 3과정을 반복한다.
(필자는 중심점좌표값이 변하지않으면 반복을 종료 하였다.)
위 과정을 거치는 동안, 각 클러스터에 속하는 점임을 시각화하기위해 빨간색, 파란색으로 (x, y) 2차원좌표상에 출력해보았다.
과정을 거치다보면 하나의 샘플이 다른 클러스터로 속해지는(색이 변하는) 경우도 있을것이기에, 이것이 궁금하여 프로그램을 짜보았다. (되게 많은 빈도를 가질 줄 알았다.)
그리고 각 클러스터의 중심점좌표인 m1, m2의값을 갱신할때마다 출력해주어
비교 해보았다.
실행후..
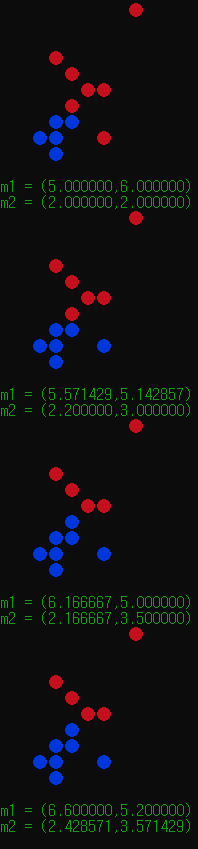
생각보다 많은 단계를 거치지않고 알고리즘이 종료되었다.
아마 모든 좌표값이 2차원 평면상의 정수값이기에... 계산이 쉽게 떨어지는것 같다.
여기서 만약 K값을 늘린다면??? 더 복잡해지지 않을까 하는 생각이 들었다.
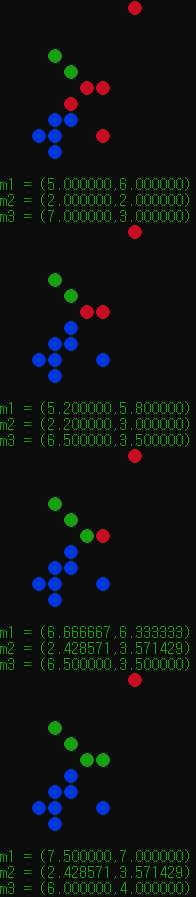
K = 3 이라면?
초기 중심점을 S0 S1 S2로 설정해보고 위와 같은 데이터를 사용해보았다.
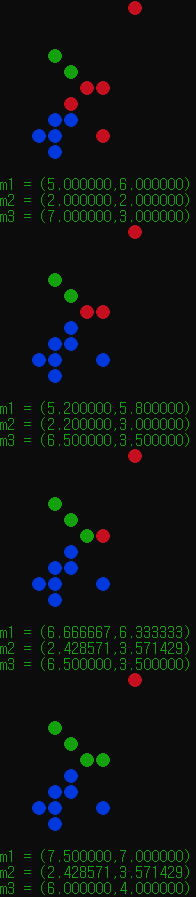
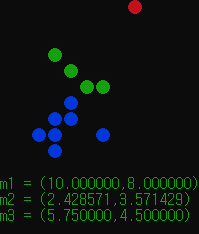
보면 알고리즘이 진행될때마다 파란색, 초록색이 커지고, 이후 중심점이 수렴하면서 종료하게된다.
K를 원하는 만큼 입력받아서 알고리즘을 실행하도록 변형해보아도 괜찮을 것같다. 보통 이런 인공지능관련 알고리즘은 파이썬이 훌륭한 라이브러리를 여럿 지원하기에 접근하기 더 편한것으로 알고있다.
이번에는 가볍게 처음 배운 알고리즘을 C로 구현하여 샘플들이 시간이 지나면서 서로 다른 그룹에 속하는 과정이 궁금해서 도전해보았다.
시간이나면 K를 늘리도록 코드를 수정해보겠다.
여기까지 소스코드를 올리며 마치겠다...
#define _CRT_SECURE_NO_WARNINGS
#include <bits/stdc++.h>
#include <Windows.h>;
using std::vector; using std::pair; typedef pair<int, int> pii; typedef pair<double, double> pdd;
/*
점 데이터를 입력받고, 이중 K개(현재는 2개)를 선택하여
각각을 클러스터의 중심점 위치로 선정한다.
이후 모든 점에대해 어느 클러스터에 속하는지 분류를 한뒤에
분류가 끝난뒤 각 클러스터 그룹내의 중심점위치를 다시 정한다.
이때 중심점위치를 다시정하면서 각각의 점들이 다른 클러스터로 변화하기도하는데,
이러면 다시 중심점위치를 계산, 다시 모든 점을 재분류하는 과정을 반복한다.
여기서 모든 점이 클러스터의 중심점이 바뀐뒤에서 같은 클러스터에 속한다면
중단한다.
*/
vector<pii> data;
vector<int> cluster;
int graph[11][11];
int size, cnt; //데이터의 총갯수, 중심점 계산횟수
pdd m1, m2, m3; //중심점 위치
void func();
void visualization();
bool calculate();
void makeGraph();
void classification();
void init();
void init() {
while (1) {
int x, y;
printf("S%d 의 x, y(0= < x,y <= 10)값을 띄어쓰기로 입력하세요. (x,y < 0 입력시 종료):\n", size);
scanf("%d%d", &x, &y);
if (x < 0 || y < 0) break;
data.push_back({ x, y });
cluster.push_back(0);
size++;
}
//처음 중심점위치는 데이터중 임의로 골라서 정한다.
int temp1;
while (1) {
printf("초기센터(m1)로 사용할 Si의 i값을 입력하세요. (0 <= i < %d):\n", size);
scanf("%d", &temp1);
if (0 <= temp1 && temp1 < size) break; //정상값이어야 다음단계진행
}
m1 = { data[temp1].first , data[temp1].second };
int temp2;
while (1) {
printf("초기센터(m2)로 사용할 Si의 i값을 입력하세요. (0 <= i < %d):\n", size);
scanf("%d", &temp2);
if (0 <= temp2 && temp2 < size && temp1 != temp2) break;
}
m2 = { data[temp2].first , data[temp2].second };
int temp3;
while (1) {
printf("초기센터(m3)로 사용할 Si의 i값을 입력하세요. (0 <= i < %d):\n", size);
scanf("%d", &temp3);
if (0 <= temp3 && temp3 < size && temp1 != temp2 && temp2 != temp3) break;
}
m3 = { data[temp3].first , data[temp3].second };
//초기분류 실행
classification();
makeGraph();
}
void func() {
while (1) {
visualization();
if (calculate() || cnt >= 50) break;
classification();
makeGraph();
}
printf("\n\n>>>>>>>>>>>>>>>>>>> END\n\n\n\n\n");
}
//중심점을 다시 계산
bool calculate() {
pdd prev_m1 = m1, prev_m2 = m2, prev_m3 = m3;
int m1_sum_x = 0;
int m1_sum_y = 0;
int m2_sum_x = 0;
int m2_sum_y = 0;
int m3_sum_x = 0;
int m3_sum_y = 0;
int m1_cnt = 0;
int m2_cnt = 0;
int m3_cnt = 0;
for (int i = 0; i < size; i++) {
if (cluster[i] == 1) {
m1_sum_x += data[i].first;
m1_sum_y += data[i].second;
m1_cnt++;
}
else if (cluster[i] == 2) {
m2_sum_x += data[i].first;
m2_sum_y += data[i].second;
m2_cnt++;
}
else {
m3_sum_x += data[i].first;
m3_sum_y += data[i].second;
m3_cnt++;
}
}
m1 = { m1_sum_x / (double)m1_cnt, m1_sum_y / (double)m1_cnt };
m2 = { m2_sum_x / (double)m2_cnt, m2_sum_y / (double)m2_cnt };
m3 = { m3_sum_x / (double)m3_cnt, m3_sum_y / (double)m3_cnt };
cnt++;
if (prev_m1 == m1 && prev_m2 == m2 && prev_m3 == m3)
return true;
else
return false;
}
//그래프를 시각화하고 m1, m2값을 출력
void visualization() {
for (int i = 10; i >= 0; i--) {
for (int j = 0; j < 11; j++) {
if (graph[i][j] == 0) {
printf(" ");
}
else if(graph[i][j] == 1) {
SetConsoleTextAttribute(GetStdHandle(STD_OUTPUT_HANDLE), FOREGROUND_RED);
printf("●");
SetConsoleTextAttribute(GetStdHandle(STD_OUTPUT_HANDLE), FOREGROUND_GREEN);
}
else if(graph[i][j] == 2) {
SetConsoleTextAttribute(GetStdHandle(STD_OUTPUT_HANDLE), FOREGROUND_BLUE);
printf("●");
SetConsoleTextAttribute(GetStdHandle(STD_OUTPUT_HANDLE), FOREGROUND_GREEN);
}
else {
SetConsoleTextAttribute(GetStdHandle(STD_OUTPUT_HANDLE), FOREGROUND_GREEN);
printf("●");
SetConsoleTextAttribute(GetStdHandle(STD_OUTPUT_HANDLE), FOREGROUND_GREEN);
}
}
printf("\n");
}
printf("m1 = (%lf,%lf)\nm2 = (%lf,%lf)\nm3 = (%lf,%lf)\n",m1.first, m1.second, m2.first, m2.second, m3.first, m3.second);
}
//실제로 그래프를 데이터화
void makeGraph() {
for (int i = 0; i < 11; i++)
for (int j = 0; j < 11; j++)
graph[i][j] = 0; //초기화
for (int i = 0; i < size; i++) {
int x = data[i].first;
int y = data[i].second;
cluster[i] == 1 ? graph[x][y] = 1 : cluster[i] == 2 ? graph[x][y] = 2 : graph[x][y] = 3;
}
}
//모든점을 어느 클러스터에 속하는지 분류
void classification() {
double d1, d2, d3;
for (int i = 0; i < size; i++) {
d1 = sqrt(pow((m1.first - data[i].first), 2) + pow((m1.second - data[i].second), 2));
d2 = sqrt(pow((m2.first - data[i].first), 2) + pow((m2.second - data[i].second), 2));
d3 = sqrt(pow((m3.first - data[i].first), 2) + pow((m3.second - data[i].second), 2));
if (d1 > d2)
d2 > d3 ? cluster[i] = 3 : cluster[i] = 2;
else
d1 > d3 ? cluster[i] = 3 : cluster[i] = 1;
}
}
int main(void) {
init();
func();
return 0;
}