
📌 실습
📌 BeautifulSoup
- 예제 : 가비아 라이브러리 사이트의 게시글 제목 확인
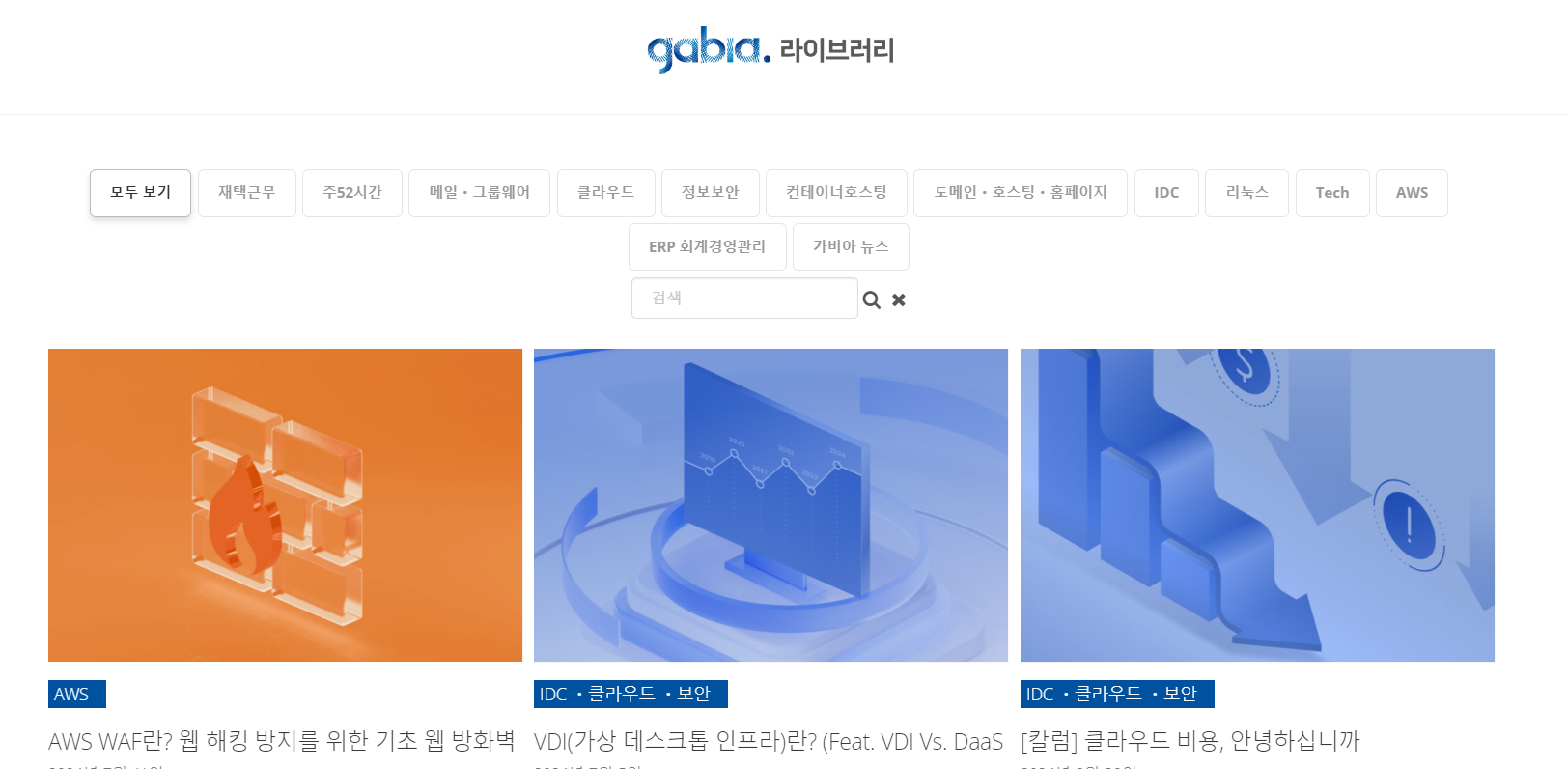
F12 키로 게시물 제목의 HTML 구조 확인
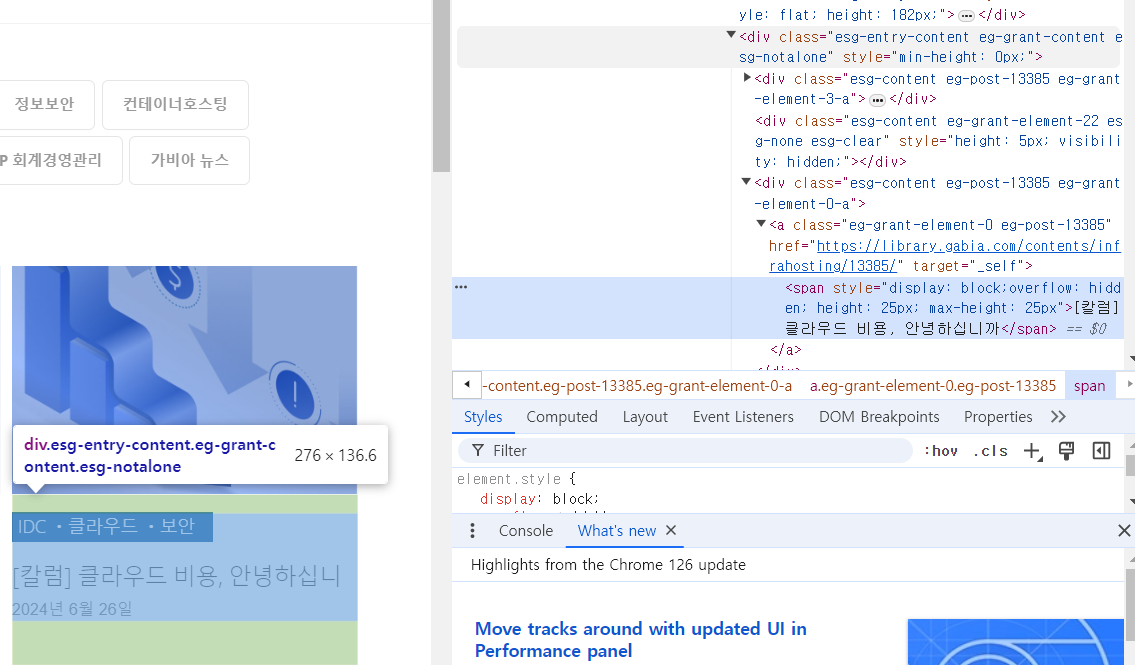
선택자 확인
div.esg-entry-content a > span

선택자 경로에 대한 자세한 설명 :
elements = soup.select('div.esg-entry-content a > span')
-
div.esg-entry-content
div 요소 중 class 속성이 esg-entry-content인 요소를 선택
여기서 .은 클래스(class)를 나타낸다. -
a
div.esg-entry-content 요소 내부의 모든 a 요소를 선택
a 요소는 HTML에서 하이퍼링크를 나타낸다. -
> span
a 요소의 직계 자식 요소인 span 요소를 선택
>는 직계 자식 요소를 의미한다. 즉, a 요소 바로 아래에 있는 span 요소를 선택
+) 선택자 경로를 div.esg-entry-content > a > span 이렇게 하지 않는 이유 ?
-
elements = soup.select('div.esg-entry-content > a > span')
: 이 선택자는 div 요소의 직계 자식으로 a 요소가 있어야 하고,
그 a 요소의 직계 자식으로 span 요소가 있어야 한다.
즉, div → a → span 구조 -
elements = soup.select('div.esg-entry-content a > span')
: 이 선택자는 div 요소 내부의 모든 a 요소를 찾고,
그 a 요소의 직계 자식으로 span 요소가 있는 경우를 선택한다.
즉, div 요소 내에 a 요소가 중첩되어 있어도 그 a 요소의 직계 자식 span을 선택
HTML 구조가 복잡해졌을 경우에도 유연하게 작동시키기 위해
div.esg-entry-content a > span선택자를 사용한다.
예시)
<div class="esg-entry-content">
<!-- 다른 내용들 -->
<div>
<a class="...">
<span style="...">클라우드 비용, 안녕하십니까?</span>
</a>
</div>
</div>위와 같은 구조에서 div.esg-entry-content > a > span은 작동하지 않지만,
div.esg-entry-content a > span 은 작동한다.
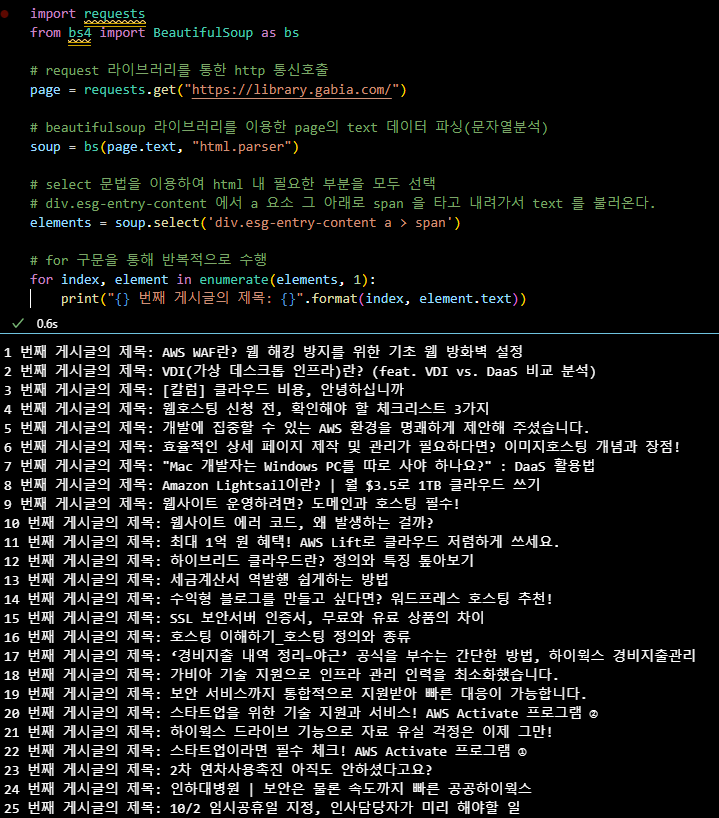
import requests
from bs4 import BeautifulSoup as bs
# request 라이브러리를 통한 http 통신호출
page = requests.get("https://library.gabia.com/")
# beautifulsoup 라이브러리를 이용한 page의 text 데이터 파싱(문자열분석)
soup = bs(page.text, "html.parser")
# select 문법을 이용하여 html 내 필요한 부분을 모두 선택
# div.esg-entry-content 에서 a 요소 그 아래로 span 을 타고 내려가서 text 를 불러온다.
elements = soup.select('div.esg-entry-content a > span')
# for 구문을 통해 반복적으로 수행
for index, element in enumerate(elements, 1):
print("{} 번째 게시글의 제목: {}".format(index, element.text))📌 Selenium
- 영화 리뷰 크롤링 실습
먼저 로봇 배제 표준 확인 : robots.txt
Yeti 봇(네이버 검색 엔진 봇)과 Googlebot이 웹사이트에 완전 접근할 수 있도록 허용중
Disallow 관련 내용은 없다.
# pip install selenium
from selenium.common.exceptions import NoSuchElementException
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from webdriver_manager.chrome import ChromeDriverManager
import time
import pandas as pd
import warnings # 경고창 무시
warnings.filterwarnings('ignore')
# 드라이버 설정 및 페이지넘버 설정
# 함수 구현
def get_movie_reviews(url, page_num=12):
chrome_driver = 'C:/Users/user-pc/Downloads/chromedriver_win32/chromedriver.exe'
wd = webdriver.Chrome(chrome_driver)
wd.get(url)
# 빈 리스트 생성하기
writer_list=[]
review_list=[]
date_list=[]
like_list=[]
for page_no in range(1,page_num+1): # 1페이지에서 page_num까지의 리뷰 추출
try:
page_ul = wd.find_element_by_id('paging_point') # 페이지 포인트 코드 추출
page_a = page_ul.find_element_by_link_text(str(page_no))
page_a.click()
time.sleep(2) # 페이지 로딩까지의 시간 두기
writers = wd.find_elements_by_class_name('writer-name')
writer_list += [writer.text for writer in writers]
reviews = wd.find_elements_by_class_name('box-comment')
review_list += [ review.text for review in reviews ]
dates = wd.find_elements_by_class_name('day')
date_list += [date.text for date in dates]
likes = wd.find_elements_by_id('idLikeValue')
like_list += [like.text for like in likes]
if page_no%10==0: # 10이상의 값을 만났을 때 다음 페이지로 넘기기 버튼
if page_no==10:
next_button = page_ul.find_element_by_class_name("paging-side")
#next_button = page_ul.find_element_by_class_name('btn-paging next')
next_button.click()
time.sleep(2)
else:
next_button = page_ul.find_element_by_xpath('//*[@id="paging_point"]/li[13]/button').click()
time.sleep(2)
except NoSuchElementException:
break
movie_review_df = pd.DataFrame({"Writer" : writer_list,
"Review" : review_list,
"Date" : date_list,
"Like" : like_list})
wd.close()
return movie_review_df
# url 과 pagenum 을 입력하여 작성자, 리뷰내용, 작성날짜, 좋아요 수 요청 및 dataframe 반환
#범죄도시4 movie_review_df = get_movie_reviews("http://www.cgv.co.kr/movies/detail-view/?midx=88104#", page_num=3905)
movie_review_df = get_movie_reviews("http://www.cgv.co.kr/movies/detail-view/?midx=85813", page_num=12)
# dataframe 저장
movie_review_df.to_csv('범죄도시2크롤링.csv', index=False, encoding="utf-8-sig")세션에서 배웠던 위 코드를 실습해보려고 하니 2가지 오류가 발생했다.
- 크롬 버전 맞추기
- 최신 버전의 셀레니움에서
find_element_by_메서드의 제거
-
셀레니움, 웹드라이버, 크롬 버전 맞추기
- 세션에서는 크롬 브라우저를 다운그레이드하여 크롤링 환경을 맞춰줘야 한다고 했으나,
다른 방법이 없을까 싶어서 검색하다 보니
Service 객체 생성을 통한 드라이버 초기화 방법이 있었다. (참고)
- 세션에서는 크롬 브라우저를 다운그레이드하여 크롤링 환경을 맞춰줘야 한다고 했으나,
크롬 드라이버 초기화 방법
# Service 객체를 사용하여 Chrome 드라이버 초기화
service = Service(ChromeDriverManager().install())
wd = webdriver.Chrome(service=service)-
ChromeDriverManager().install():
webdriver_manager.chrome 모듈에서 제공하는 ChromeDriverManager 클래스를 사용하여
Chrome 드라이버를 자동으로 다운로드하고 설치한다.
이 메서드는 Chrome 드라이버의 최신 버전을 다운로드하고 설치 경로를 반환한다. -
Service 객체 생성 :
selenium.webdriver.chrome.service모듈에서 제공하는
Service 클래스를 사용하여 Chrome 드라이버 서비스를 설정한다.Service 클래스의 생성자는 Chrome 드라이버의 실행 파일 경로를 인자로 받고,
service = Service(ChromeDriverManager().install())는
다운로드된 Chrome 드라이버의 경로를 Service 객체에 전달하여 초기화한다. -
webdriver.Chrome 인스턴스 생성:
webdriver.Chrome 클래스의 인스턴스를 생성하여
Chrome 브라우저를 제어할 수 있는 드라이버 객체를 만든다.
생성자 인자로 service 객체를 전달하여 Chrome 드라이버를 사용하도록 설정,
wd = webdriver.Chrome(service=service)는 초기화된 service 객체를 사용하여
Chrome 드라이버를 실행하고, 이를 통해 브라우저를 제어할 수 있는 wd 객체를 생성한다.
find_element_by_메서드 대체
find_element_by_ 메서드가 제거되어, find_element 와 By 클래스로 대체하여
최신 셀레니움에서 코드가 작동하도록 수정했다.
find_element_by_id → find_element(By.ID, ...)
find_element_by_link_text → find_element(By.LINK_TEXT, ...)
find_element_by_class_name → find_element(By.CLASS_NAME, ...)
find_elements_by_class_name → find_elements(By.CLASS_NAME, ...)
find_elements_by_id → find_elements(By.ID, ...)
find_element_by_xpath → find_element(By.XPATH, ...)📌 Selenium 크롤링 결과
- 라이브러리 불러오기
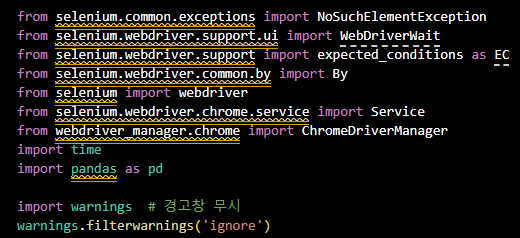
from selenium.common.exceptions import NoSuchElementException
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
import time
import pandas as pd
import warnings # 경고창 무시
warnings.filterwarnings('ignore')- 함수 구현
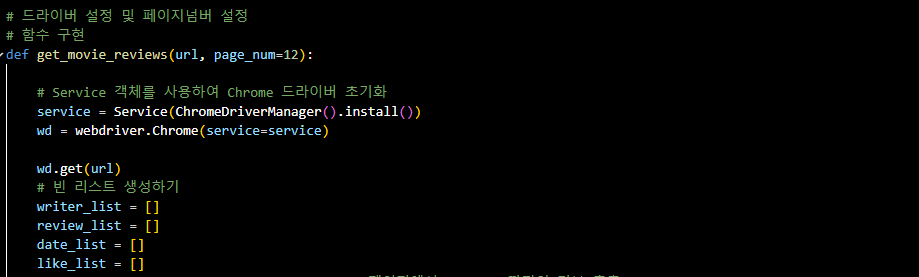
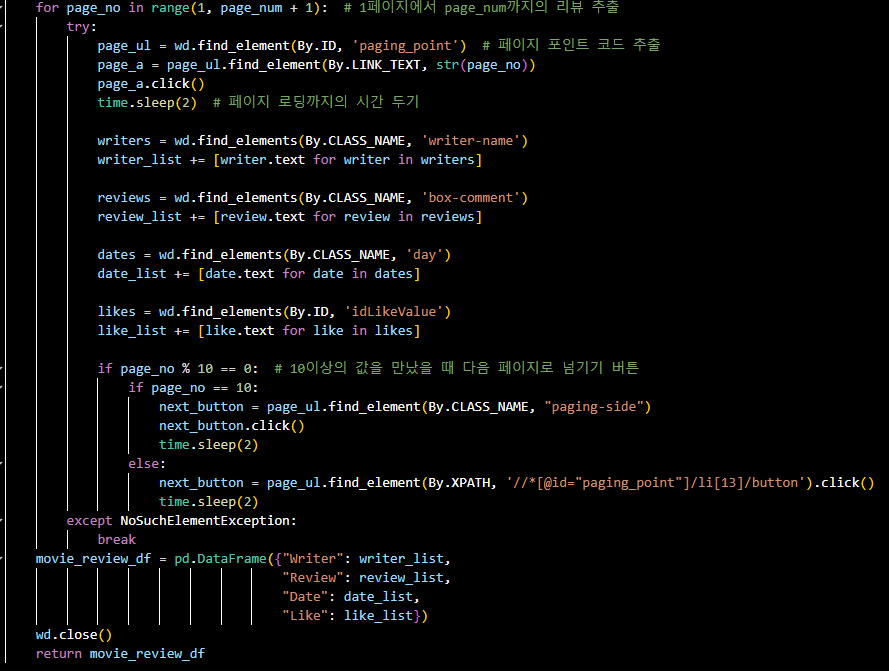

- 결과
# 3배속
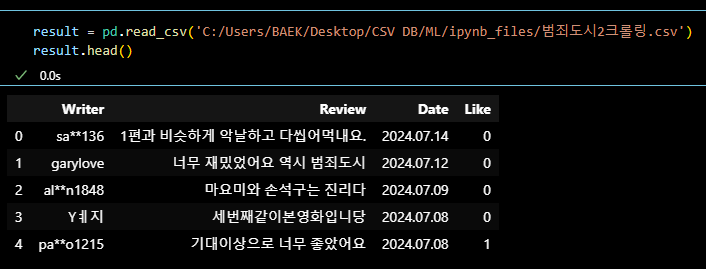
- 전체적인 흐름과 코드에 대한 이해를 할 수 있었다.
이제 다른 사이트에서 원하는 데이터를 크롤링해보는 연습을 해봐야지.
