
개요
데이터 수집에 관한 웹 크롤링 학습
📌 크롤링과 스크래핑
📌 크롤링
-
웹 크롤링
인터넷 상의 모든 웹 페이지를 방문하며,
각 페이지의 링크를 따라가면서 데이터를 자동으로 수집하는 방법.
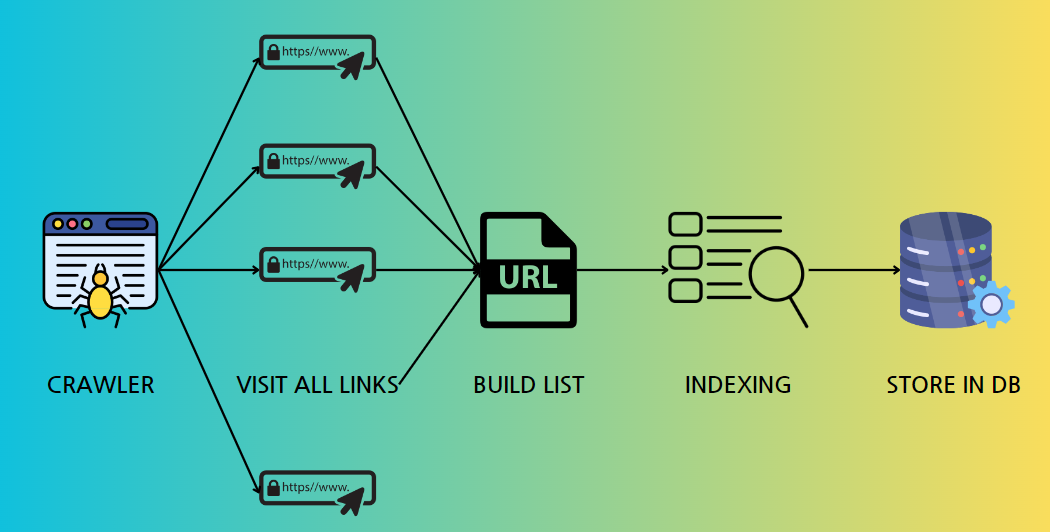
크롤러 또는 스파이더라고 불리는 프로그램이 이를 수행하는데,
주로 검색 엔진에서 사용되어 웹 페이지를 색인화하고
검색 가능한 데이터베이스를 구축하는 데 활용한다. -
주요 특징
- 자동화된 탐색 : 크롤러가 링크를 따라가며 자동으로 웹 페이지를 방문
- 데이터 색인화 : 수집된 데이터를 색인화하여 검색 엔진의 DB에 저장
- 전체 웹 탐색 : 인터넷 상의 모든 웹 페이지를 대상으로 탐색
📌 스크래핑
-
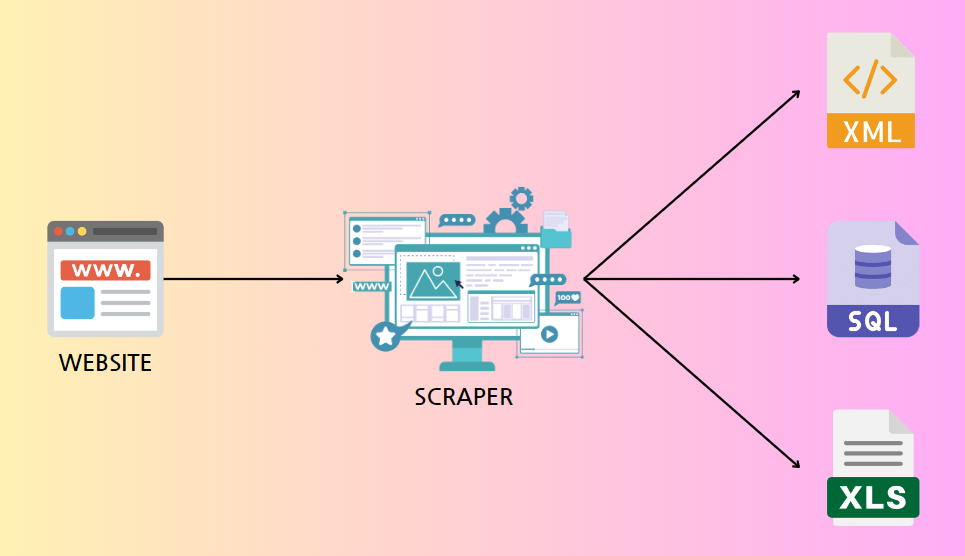
웹 스크래핑
특정 웹 사이트나 페이지에서 필요한 데이터를 자동으로 추출하는 것을 의미
HTTP GET요청을 보내고, 정상 응답을 받으면 HTML 코드를 분석하여 데이터를 추출한다.
주로 특정 정보나 데이터를 수집하기 위해 사용
-
주요 특징
- 특정 데이터 추출 : 특정 웹 페이지에서 필요한 정보만을 추출
- HTML 코드 분석 : 웹 페이지의 HTML 코드를 파싱하여 데이터를 추출
- 목적 지향적 : 특정 목적(분석, 데이터 수집 등)을 위해 설계된 도구에 의해 수행
📌 공통점 및 차이점
-
공통점
- 데이터 수집 : 크롤링과 스크래핑 모두 원하는 데이터를 자동으로 수집할 수 있다.
- 자동화 도구 : 파이썬 등 프로그래밍 언어를 통해 자동화 도구를 작성할 수 있다.
크롤링을 통해 웹에 접근한 후 스크래핑을 통해 특정 데이터를 추출하는 형태로 함께 사용 가능
-
차이점
-
목적의 차이 :
- 웹 크롤링 : 웹사이트에 대한 정보를 색인화하고 저장하는 데 중점
- 웹 스크래핑 : 웹사이트에서 특정 데이터를 추출 > 분석 및 기타 목적으로 사용
-
수행 주체의 차이 :
- 웹 크롤링 : 검색 엔진 및 기타 자동화 도구에 의해 주로 수행
- 웹 스크래핑 : 사람 또는 이 목적을 위해 특별히 설계된 자동화 도구에 의해 수행
-
-
예시
- 웹 크롤링 : 구글 검색 엔진의 크롤러가 인터넷 상의 웹 페이지를 방문 > 색인화
- 웹 스크래핑 : 특정 쇼핑몰 사이트에서 상품 가격 데이터를 자동으로 추출하여 가격 비교 사이트에 제공
-
요약
웹 크롤링과 웹 스크래핑은 데이터 수집을 목적으로 하는 자동화 기술로,
각각의 목적과 사용 사례에 따라 구분되지만, 상호 보완적으로 함께 사용될 수 있다.
이를 통해 우리는 인터넷 상의 방대한 데이터를 효과적으로 수집하고 활용 가능
📌 주의사항
- 합법 여부 확인 ( = 로봇 배제 표준
Robots Exclusion Standard준수 여부)- 로봇 배제 표준은 웹 사이트의 소유자가 로봇에 대한 액세스 권한을 제어하는 프로토콜
- 스크래핑/크롤링을 수행하기 전 해당 웹사이트의
robots.txt파일을 반드시 확인하고,
로봇 배제 표준을 준수하는지 확인하는 과정이 필요하다.
- URL 뒤
robots.txt를 붙여 확인 가능
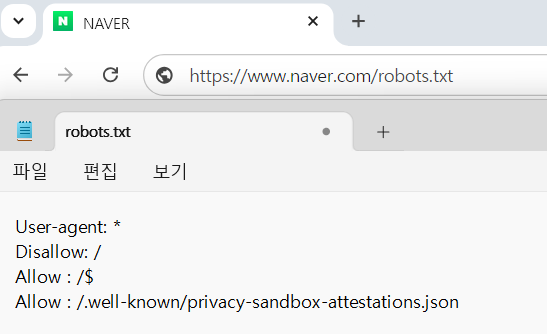
네이버의 로봇 배제 표준 :
기본적으로 모든 봇의 모든 경로 접근을 금지하고, 아래 두 경로에 대해서만 접근을 허용한다.
루트 디렉토리: /$
프라이버시 샌드박스 관련 파일: /.well-known/privacy-sandbox-attestations.json
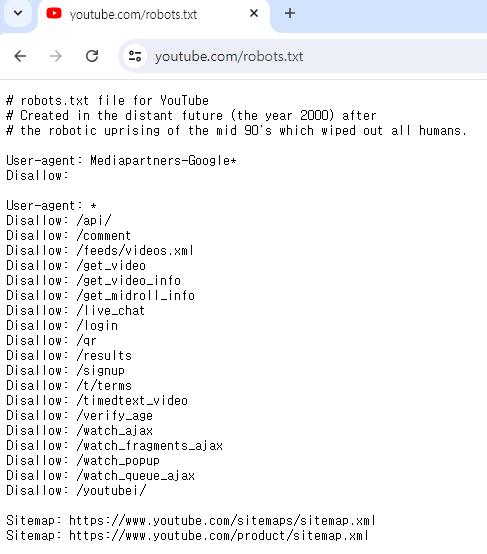
유튜브의 로봇 배제 표준 :
Mediapartners-Google (Google 광고 관련 봇)* 을 제외하고는 모두 접근이 금지되어 있다.
📌 웹(WEB)
📌 웹의 구성요소
웹 사이트를 구현하기 위해 사용되는 주요 기술 : HTML, CSS, JavaScript
-
HTML (Hyper Text Markup Language)
- 역할 : 웹 사이트의 뼈대를 만들어주는 마크업 언어
- 주요 기능 : 콘텐츠 구조 정의, 텍스트, 이미지, 링크 등의 요소 배치
- 예시 :
<h1>,<p>,<div>,<a>등
-
CSS (Cascading Style Sheets)
- 역할 : 웹 사이트를 예쁘게 꾸며주는 스타일 시트 언어
- 주요 기능 : 레이아웃, 색상, 폰트, 간격 등의 시각적 스타일링
- 예시 : color:, font-size:, margin:, padding:
-
JavaScript
- 역할 : 웹 사이트를 동작하게 만들어주는 스크립트 언어
- 주요 기능 : 사용자 인터랙션, 데이터 처리, 동적 콘텐츠 생성
- 예시 : 클릭 이벤트, 폼 검증, AJAX 요청
+) 웹의 구성요소 핵심 내용 추가
-
웹 서버 (Web Server)
- 역할 : 클라이언트(브라우저)의 요청을 처리하고, 요청된 웹 페이지를 제공하는 서버
- 주요 기능 : HTTP 요청 처리, 정적 및 동적 콘텐츠 제공
- 예시 : Apache, Nginx
-
웹 브라우저 (Web Browser)
- 역할 : 웹 페이지를 요청하고, HTML, CSS, JavaScript를 해석하여 사용자에게 보여주는 소프트웨어
- 주요 기능 : HTML 렌더링, CSS 스타일 적용, JavaScript 실행
- 예시 : Google Chrome, Mozilla Firefox, Safari
-
URL (Uniform Resource Locator)
- 역할: 웹에서 자원의 위치를 지정하는 주소
- 주요 기능: 웹 페이지, 이미지, 비디오 등의 자원에 접근할 수 있는 경로 제공
- 예시: https://www.example.com
-
HTTP / HTTPS (HyperText Transfer Protocol/Secure)
- 역할: 클라이언트와 서버 간의 데이터 통신을 위한 프로토콜
- 주요 기능: 요청(Request)과 응답(Response)을 통해 웹 페이지 전송
- 예시: GET, POST, PUT, DELETE 메서드
요약
웹 사이트는 HTML, CSS, JavaScript라는 세 가지 주요 기술로 구성된다.
- HTML은 웹 페이지의 구조를 정의하고,
CSS는 시각적 스타일을 적용하며,
JavaScript는 웹 페이지에 동적인 기능을 추가한다.
📌 HTML의 구조 & XPATH
HTML (HyperText Markup Language) :
프로그래밍 언어가 아닌 문서를 설명하는 정보를 표현하는 마크업 언어,
웹 페이지를 구성하는 골격을 이루며, 문서의 구조나 서식을 포함한다.
HTML의 주요 구성 요소
-
문서 형식 선언 : Doctype
- 역할 : HTML 문서가 어떤 버전의 HTML이나 XHTML로 작성되었는지 웹 브라우저에게 알려준다.
- 예시 :
<!DOCTYPE html>
-
루트 요소 : html
- 역할 : HTML 문서의 최상위 요소, 모든 다른 HTML 요소들을 포함하는 부모 요소이다.
- 예시 :
<html> ... </html>
-
헤드 : Head
- 역할 : HTML 문서의 메타데이터와 외부 리소스에 대한 정보를 포함하는 부분,
화면에 직접적으로 보이지 않지만, 웹 브라우저가 문서를 처리하고 표시하는 데 중요한 역할 - 예시 :
<head> <title>문서 제목</title> <meta charset="UTF-8"> <link rel="stylesheet" href="styles.css"> </head>
- 역할 : HTML 문서의 메타데이터와 외부 리소스에 대한 정보를 포함하는 부분,
-
본문 : Body
- 역할 : HTML 문서의 실제 내용을 담고 있는 부분
웹 페이지를 구성하는 모든 텍스트, 이미지, 링크, 테이블, 폼 등의 콘텐츠가 포함된다. - 예시 :
<body> <h1>제목</h1> <p>문단 텍스트</p> <img src="image.jpg" alt="이미지"> </body>
- 역할 : HTML 문서의 실제 내용을 담고 있는 부분
HTML 태그 및 속성
주요 태그
-
div 태그
- 의미 : 분할하다는 뜻의 Division의 준말
- 역할 : HTML 문서 내 한 개의 가로 공간 (Block)을 만드는 태그
<div>div 태그로 생성된 공간</div>
-
p 태그
- 의미 : 단락, 절이라는 뜻의 Paragraph의 준말
- 역할 : 주로 문장에 대해 사용하는 태그, 한 개의 가로 공간 (Block)을 만듦
<p>p 태그로 생성된 단락</p>
-
class 속성
- 의미 : 여러 요소에 공통적으로 적용할 수 있는 클래스 이름
- 역할 : 여러 태그를 CSS 나 JAVAScript 에서 그룹화하여 스타일링, 조작할 수 있게 함
<div class="common-class"> 이 div는 class 속성을 가짐 </div> <p class="common-class"> 이 p 태그도 같은 class 속성을 가짐 </p>
+) class 부가 설명
- class : Java에서 객체를 만들어내기 위한 틀
HTML에서는 여러 요소에 공통된 스타일이나 동작을 적용하기 위한 그룹화 수단- 예시 해석 :
div class="example"→ '하나의 공간(클래스)를 만들겠다'
- 예시 해석 :
XPATH (XML Path Language) :
XML 문서의 특정 부분을 선택하고 검색하기 위한 언어.
HTML 문서에서도 유용하게 사용되며, 주로 웹 크롤링 및 스크래핑에서 특정 요소를 찾는 데 사용
XPath의 주요 기능
-
절대 경로
- 문서의 루트 요소부터 시작하는 경로
- 예시 :
/html/body/h1(HTML 문서의 h1 요소를 선택)
-
상대 경로
- 현재 노드부터 시작하는 경로
- 예시:
//p(문서 내 모든 p 요소를 선택)
-
속성 선택
- 특정 속성을 가진 요소 선택
- 예시:
//img[@alt='이미지'](alt 속성이 '이미지'인 img 요소를 선택)
-
텍스트 내용 선택
- 특정 텍스트를 포함하는 요소 선택
- 예시 :
//p[text()='문단 텍스트'](텍스트가 '문단 텍스트'인 p 요소를 선택)
-
AND 연산자
- 여러 조건을 모두 만족하는 요소 선택
- 예시 :
//div[@class='content' and @id='main']- class가 'content'이고 id가 'main'인 div 요소를 선택
-
OR 연산자
- 여러 조건 중 하나라도 만족하는 요소 선택
- 예시 :
//a[@href='home.html' or @href='index.html']- href 속성이 'home.html' 또는 'index.html'인 a 요소를 선택
-
위치 지정자
- 요소의 위치를 기반으로 선택
- 예시 :
(//p)[2]- 문서 내 두 번째 p 요소를 선택
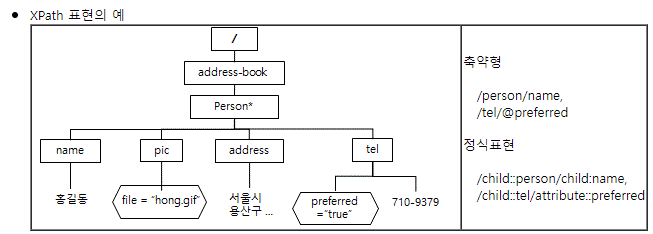
XPath 표현식의 예시
-
단일 요소 선택 :
//h1- 문서 내 모든 h1 요소를 선택
-
특정 클래스 선택 :
//div[@class='header']- class가 'header'인 모든 div 요소를 선택
-
특정 ID 선택 :
//*[@id='main']- id가 'main'인 요소를 선택
-
속성과 텍스트 결합 :
//a[@href='contact.html'][text()='Contact']- href 속성이 'contact.html'이고 텍스트가 'Contact'인 a 요소를 선택
요약
HTML의 구조와 XPath의 역할
HTML의 구조 :
문서 형식 선언(Doctype) : 문서의 버전을 정의
루트 요소(html) : HTML 문서의 최상위 요소
헤드(Head) : 메타데이터와 외부 리소스를 포함
본문(Body) : 웹 페이지의 실제 콘텐츠를 포함

XPath의 역할 :
HTML 및 XML 문서에서 특정 요소를 선택하고 검색하는 언어
절대 경로와 상대 경로를 사용하여 요소를 찾음
속성과 텍스트 내용을 기반으로 요소를 선택
📌 XPath 예시
-
CGV 메인 페이지 > 예매 화면
F12 키를 활용해서 HTML 구조 확인
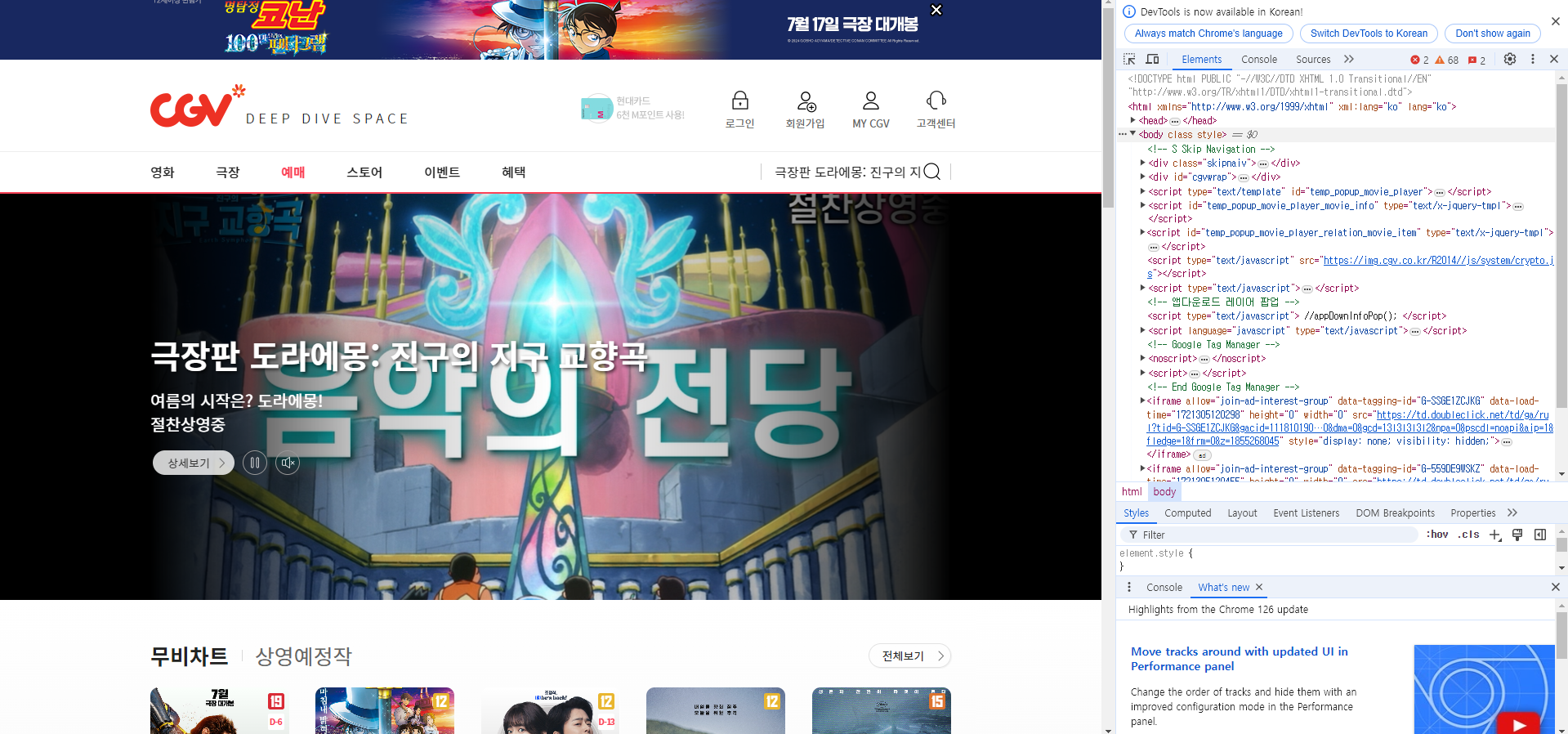
예시 : CGV 메인 페이지 > 예매 화면 > 상단 혜택 메뉴의 XPath
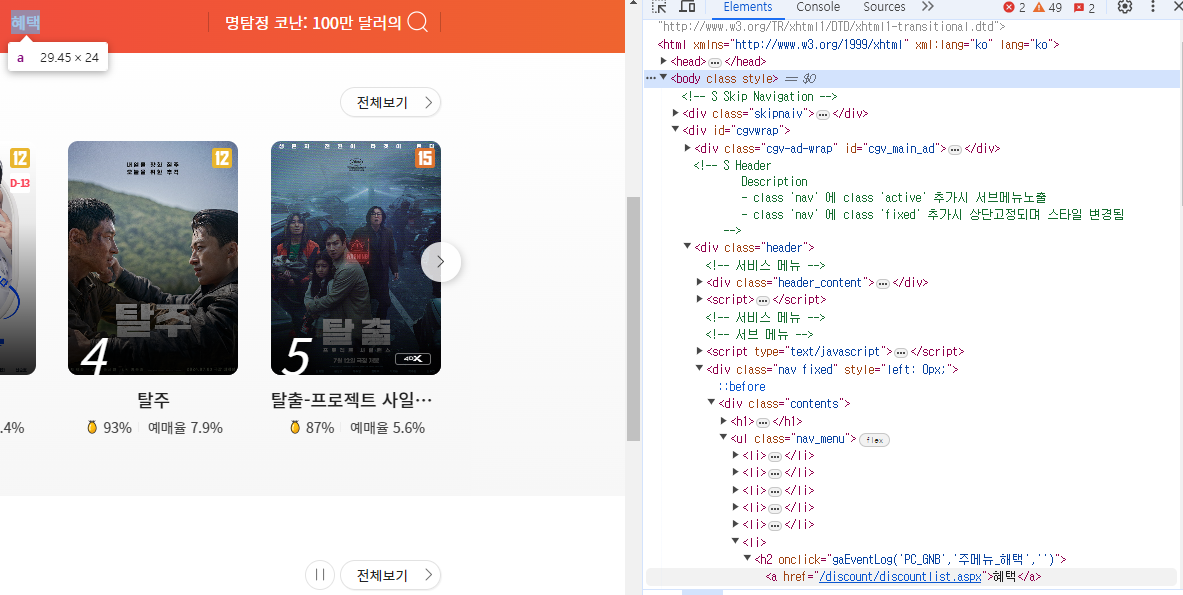
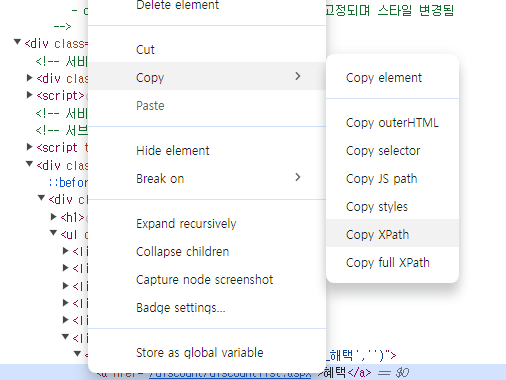
XPath 복사 결과 ://*[@id="cgvwrap"]/div[2]/div[2]/div/ul/li[6]/h2/a
📌 BeautifulSoup, Selenium
📌 BeautifulSoup
-
Python에서 웹 데이터 크롤링을 위한 기초 라이브러리.
- HTML 태그를 기반으로 크롤링을 진행하며, 파싱(parsing) 과정을 통해 데이터를 추출한다.
-
주요 개념
-
requests 라이브러리:
Python에서 HTTP 요청을 보내기 위해 가장 많이 사용되는 라이브러리.
웹 페이지를 호출하여 HTML 내용을 가져온다. -
BeautifulSoup 라이브러리:
HTML 내용을 파싱하여 데이터를 추출하는 라이브러리.
requests와 함께 사용되어 웹 페이지의 데이터를 크롤링하고 파싱하는 데 유용하다. -
파싱 (Parsing):
웹 상의 자연어, 컴퓨터 언어 등의 문자열을 분석하여 유용한 정보를 추출하는 프로세스
-
- 기본 사용 방식
- BeautifulSoup 및 requests 라이브러리 설치
!pip install beautifulsoup4
!pip install requests- BeautifulSoup 및 requests 사용 예제
import requests
from bs4 import BeautifulSoup as bs
url = "크롤링하려는 웹페이지의 주소"
# 웹페이지 요청
response = requests.get(url) # 지정된 url에 HTTP GET 요청을 보내고, 응답 받기
# HTML 파싱
soup = bs(response.content, "html.parser")
# response의 콘텐츠(HTML) 가져오기
# BeautifulSoup 객체를 생성하여 HTML 콘텐츠 파싱📌 Selenium
- 웹 개발자들이 동적 웹 페이지의 작동 여부를 테스트하기 위해 만들어진 모듈
그러나 이 점이 웹 크롤링에서는 '동적 크롤링'이 가능하게 해 주는 장점이 된다.
-
주요 개념
- 동적 웹 페이지 :
자바스크립트로 생성되거나 사용자 인터랙션(예: 스크롤, 화면 이동, 버튼 클릭)으로
변경되는 웹 페이지의 부분 - BeautifulSoup의 한계 :
BeautifulSoup은 정적 HTML 콘텐츠를 파싱하는 데는 유용하지만,
자바스크립트로 동적으로 생성된 콘텐츠는 처리할 수 없다. - Selenium의 역할 :
Selenium은 웹 브라우저를 자동으로 열고 조작할 수 있는 프레임워크로,
동적 웹 페이지의 크롤링이 가능하다.
- 동적 웹 페이지 :
- 기본 사용 방식
- Selenium 및 웹 드라이버 설치
!pip install selenium
!pip install webdriver-manager- Selenium을 사용한 웹 크롤링 예제
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
import time
def main():
url = "http://www.example.com"
# Service 객체를 사용하여 Chrome 드라이버 초기화
service = Service(ChromeDriverManager().install()) # Chrome 드라이버를 자동으로 다운로드하고 설치
driver = webdriver.Chrome(service=service)
driver.get(url)
time.sleep(5) # 웹 페이지 로딩 대기
# 예시: 특정 요소 찾기 및 상호작용
element = driver.find_element(By.ID, 'some_element_id')
element.click()
time.sleep(5) # 동작 후 대기
driver.quit()
if __name__ == '__main__':
main()-
Selenium의 장점
- 동적 콘텐츠 처리:
자바스크립트로 생성되거나 사용자 상호작용에 의해 변경되는 콘텐츠를 크롤링할 수 있다. - 브라우저 제어:
실제 브라우저를 열어 스크롤, 클릭, 입력 등의 동작을 자동으로 수행할 수 있다.
- 동적 콘텐츠 처리:
📌 실습
위 링크 참고
+) CSS 구조 확인하기 (링크) : 선택한 영역의 코드 확인 가능
