
개요
분류 평가지표의 이해,
데이터 전처리(피처엔지니어링) 작업 변화에 따른 예측 결과값 비교
📌 문제
신용카드 서비스를 떠나는 고객 찾기
-
나이, 급여, 결혼 상태, 신용 카드 한도, 신용 카드 카테고리 등의 컬럼이 있음
-
평가: ROC-AUC, 정확도(Accuracy), F1, 정밀도(Precision), 재현율(Recall)을 구하시오
-
target : Attrition_Flag (1:이탈, 0:유지)
-
csv파일 생성 : 수험번호.csv
# 파일 예시
CLIENTNUM,Attrition_Flag
788544108,0.633
719356008,0.123
712142733,0.355평가지표 코드 (분류)
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, roc_auc_score# 정확도
print(accuracy_score(y_test, pred))# 정밀도
print(precision_score(y_test, pred))# 재현율 (민감도)
print(recall_score(y_test, pred))# F1
print(f1_score(y_test , pred))# roc-auc
print(roc_auc_score(y_test, pred_proba))📌 데이터 불러오기
import pandas as pd train = pd.read_csv("/content/drive/MyDrive/Colab Notebooks/MLpractice/ceredit card/train.csv") test = pd.read_csv("/content/drive/MyDrive/Colab Notebooks/MLpractice/ceredit card/test.csv") print(train.shape, test.shape) # 항상 데이터 크기 확인하기 !

# target 컬럼인 Attrition_Flag 존재 (칼럼 수 +1) train.head(3)

# 테스트 데이터에는 타겟 컬럼이 없음 ! test.head(3)

train.info()

# 타겟 칼럼의 값을 확인하기 ! # 데이터가 불균형하다는 점 확인 ! train['Attrition_Flag'].value_counts()

# 결측치 없음 ! train.isnull().sum()
# 결측치 없음 ! test.isnull().sum()
📌 데이터 전처리 & 피처 엔지니어링
# baseline cols = train.select_dtypes(include = 'object').columns cols print(train.shape, test.shape) # object 컬럼 삭제 전 train = train.drop(cols, axis = 1) test = test.drop(cols, axis = 1) # train.drop(cols, axis = 1, inplace = True) # 변수 대입하지 않고 바로 적용 print(train.shape, test.shape) # object 컬럼 삭제 전

# 예측해야하는 칼럼인 CLIENTNUM 을 제외하고 모델을 학습시켜야 함. # 그렇지 않으면 오버피팅으로 부정확한 결과가 나옴. # 훈련용 데이터는 칼럼을 제거 train = train.drop('CLIENTNUM', axis = 1) # 시험용 데이터는 나중에 칼럼이 필요하기 때문에 pop 함수로 따로 빼두기 test_id = test.pop('CLIENTNUM')


📌 검증 데이터 분리
# 분리된 같은 데이터셋을 활용하기 위해 random_state 사용! from sklearn.model_selection import train_test_split X_tr, X_val, y_tr, y_val = train_test_split( train.drop('Attrition_Flag', axis = 1), train['Attrition_Flag'], test_size = 0.2, random_state = 1214 )

📌 모델 & 평가
# 모델 불러오기 # 학습하기 (.fit) # 예측하기 (.predict) from sklearn.ensemble import RandomForestClassifier model = RandomForestClassifier(random_state = 1214) model.fit(X_tr, y_tr) pred = model.predict(X_val)

from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, roc_auc_score # 정확도 print(accuracy_score(y_val, pred)) # 정밀도 print(precision_score(y_val, pred)) # 재현율 (민감도) print(recall_score(y_val, pred)) # F1 print(f1_score(y_val , pred))

# roc-auc pred_proba = model.predict_proba(X_val) print(roc_auc_score(y_val, pred_proba[:,1]))

📌 피처 엔지니어링
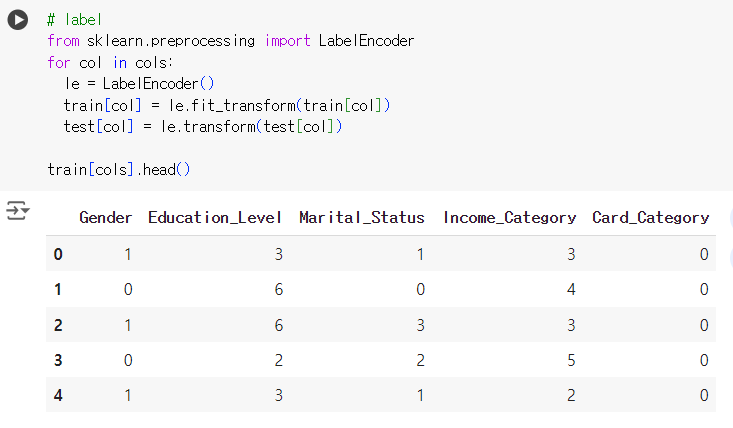
- 레이블 인코딩
# 칼럼별로 하나씩 레이블 인코딩 실행! # label from sklearn.preprocessing import LabelEncoder for col in cols: le = LabelEncoder() train[col] = le.fit_transform(train[col]) test[col] = le.transform(test[col]) train[cols].head()

- 원 핫 인코딩
# one - hot train = pd.get_dummies(train, columns = cols) test = pd.get_dummies(test, columns = cols)


📌 결과 확인


📌 예측 및 csv 제출
pred = model.predict_proba(test) pred

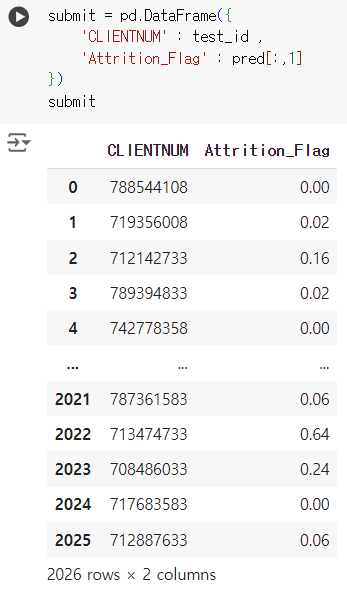
submit = pd.DataFrame({ 'CLIENTNUM' : test_id , 'Attrition_Flag' : pred[:,1] }) submit
# csv 파일로 저장 (인덱스 없이!) submit.to_csv('00004.csv', index = False) # csv 파일 불러오기 (파일이 제대로 저장되었는지 확인!) pd.read_csv('00004.csv')
📌 결과

# 아래 코드는 실제 시험에서는 확인할 수 없는 부분입니다.
y_test = pd.read_csv("/content/drive/MyDrive/Colab Notebooks/MLpractice/ceredit card/y_test.csv")
print(roc_auc_score(y_test, pred[:,1]))
커피 좋아하는 데이터 꿈나무