
#INTRO
RAINY DAY

오늘도 화이팅 !
#데이터 수집 - 웹 크롤링 (정리)
-
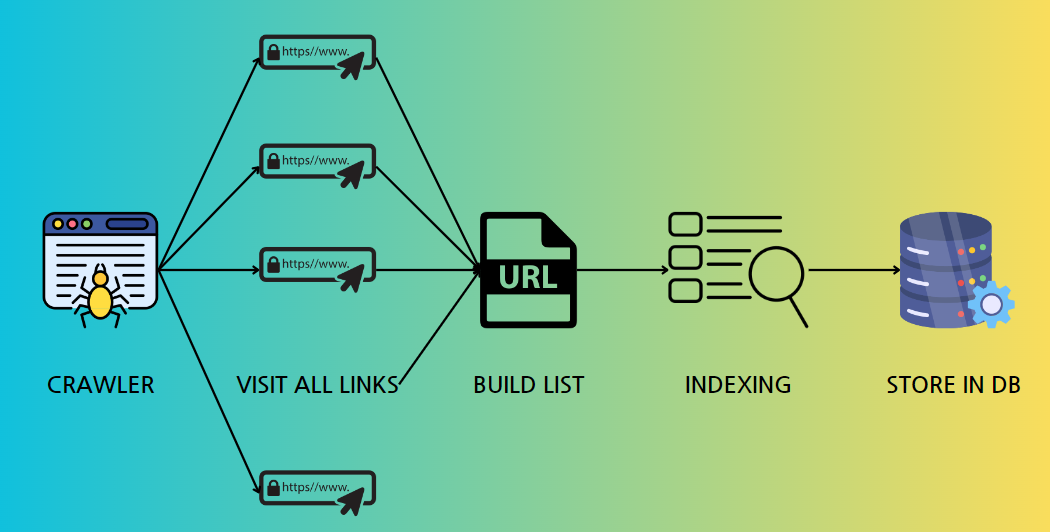
웹 크롤링
인터넷 상의 모든 웹 페이지를 방문하며,
각 페이지의 링크를 따라가면서 데이터를 자동으로 수집하는 방법.
-
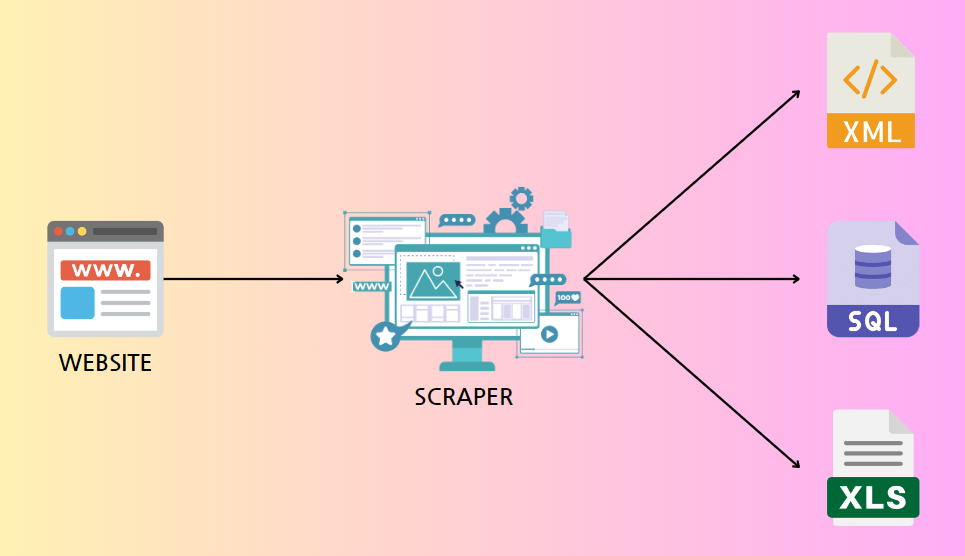
웹 스크래핑
특정 웹 사이트나 페이지에서 필요한 데이터를 자동으로 추출하는 것을 의미
HTTP GET요청을 보내고, 정상 응답을 받으면 HTML 코드를 분석하여 데이터를 추출한다.
주로 특정 정보나 데이터를 수집하기 위해 사용
-
웹의 구성요소
웹 사이트를 구현하기 위해 사용되는 주요 기술 : HTML, CSS, JavaScript
- HTML은 웹 페이지의 구조를 정의하고,
CSS는 시각적 스타일을 적용하며,
JavaScript는 웹 페이지에 동적인 기능을 추가한다.
- HTML은 웹 페이지의 구조를 정의하고,
-
HTML의 구조 & XPATH
요약
HTML의 구조와 XPath의 역할
HTML의 구조 :
문서 형식 선언(Doctype) : 문서의 버전을 정의
루트 요소(html) : HTML 문서의 최상위 요소
헤드(Head) : 메타데이터와 외부 리소스를 포함
본문(Body) : 웹 페이지의 실제 콘텐츠를 포함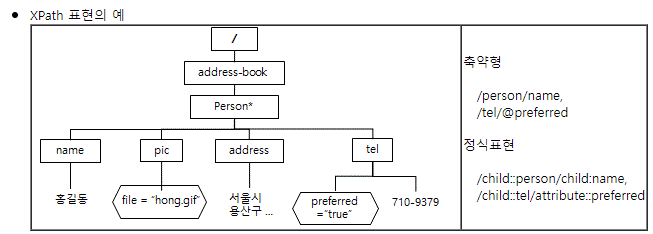
XPath의 역할 :
HTML 및 XML 문서에서 특정 요소를 선택하고 검색하는 언어
절대 경로와 상대 경로를 사용하여 요소를 찾음
속성과 텍스트 내용을 기반으로 요소를 선택
-
XPath 예시
CGV 메인 페이지 > 예매 화면F12 키를 활용해서 HTML 구조 확인
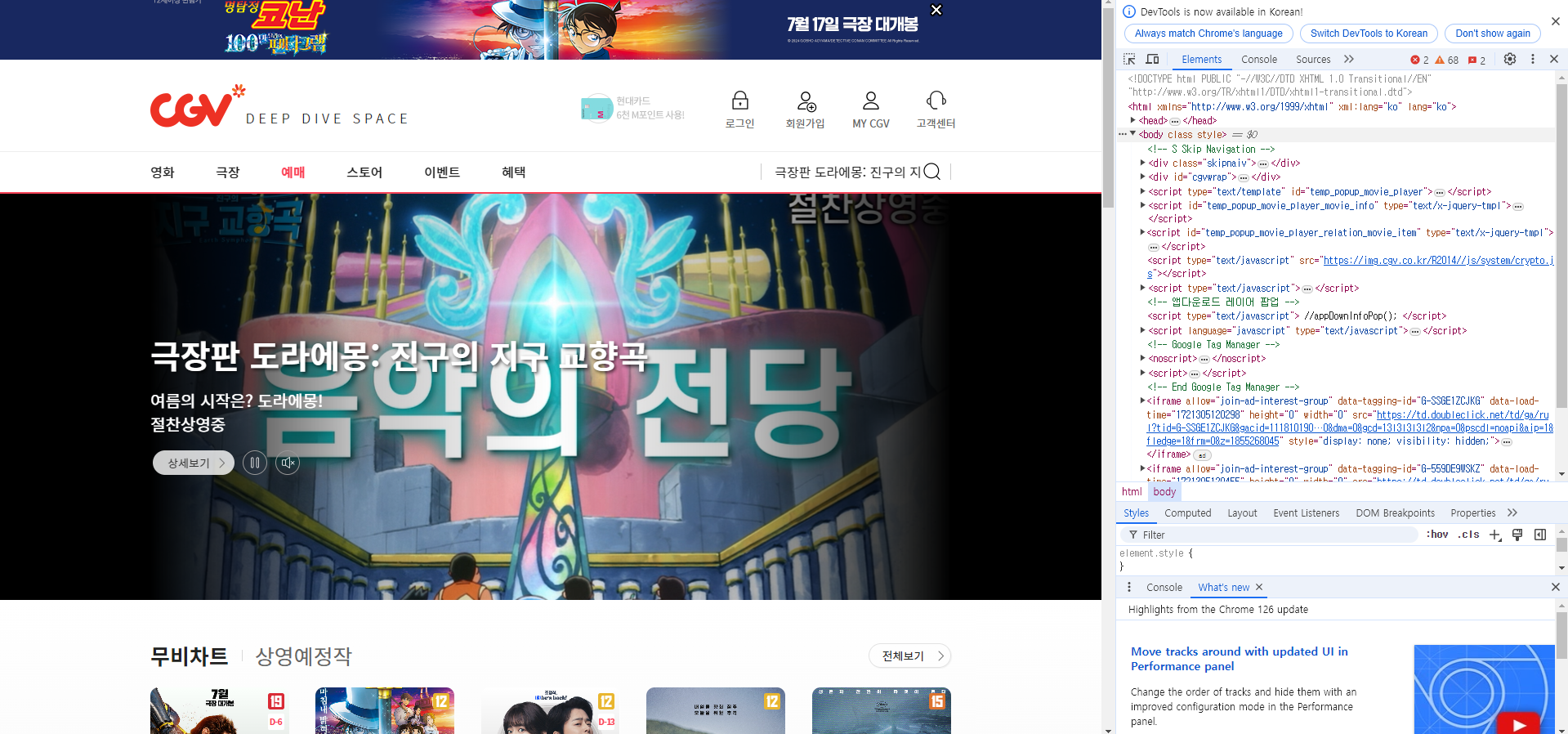
예시 : CGV 메인 페이지 > 예매 화면 > 상단 혜택 메뉴의 XPath
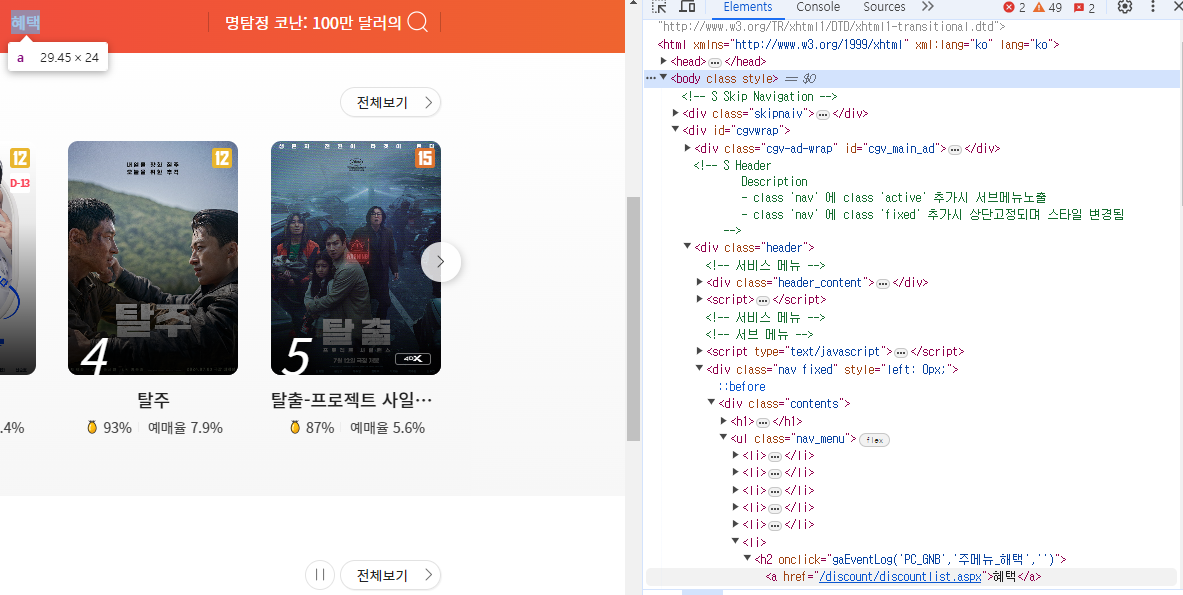
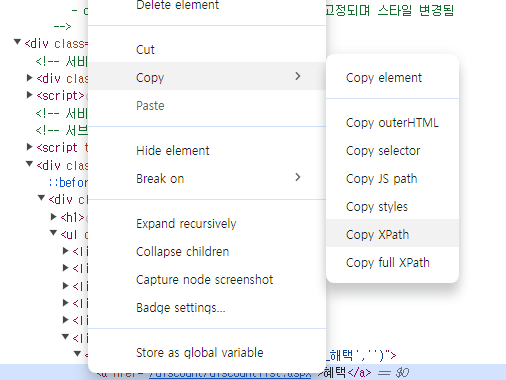
XPath 복사 결과 ://*[@id="cgvwrap"]/div[2]/div[2]/div/ul/li[6]/h2/a
#데이터 수집 - 웹 크롤링 (실습)
BeautifulSoup
- 예제 : 가비아 라이브러리 사이트의 게시글 제목 확인
F12 키로 게시물 제목의 HTML 구조 확인
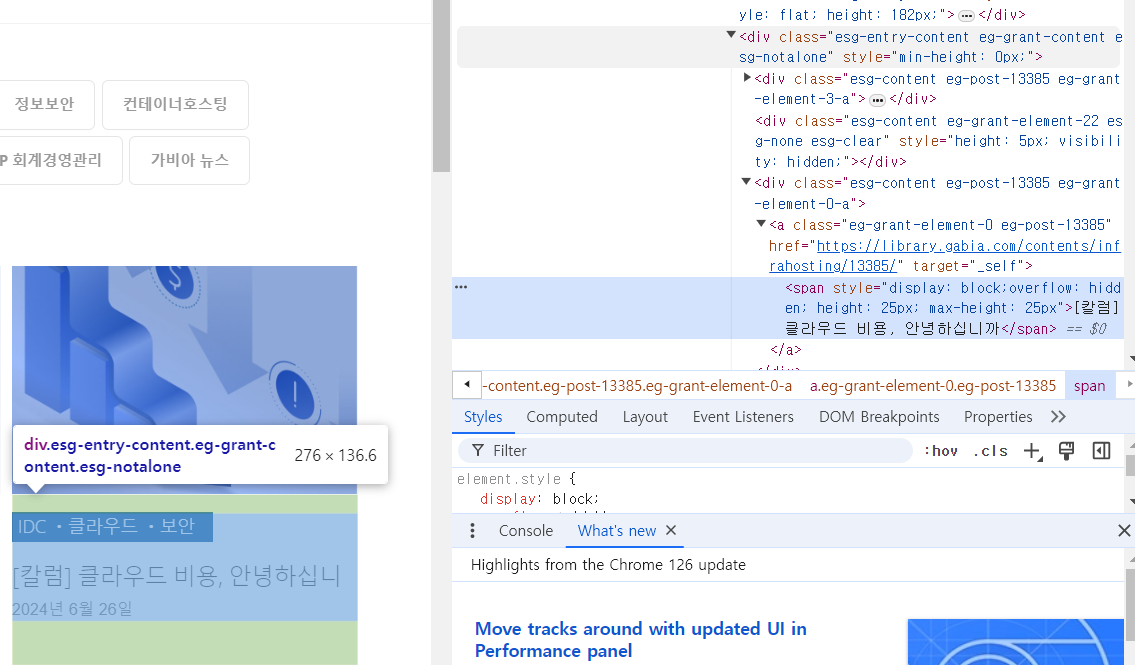
선택자 확인
div.esg-entry-content a > span

선택자 경로에 대한 자세한 설명 :
elements = soup.select('div.esg-entry-content a > span')
-
div.esg-entry-content
div 요소 중 class 속성이 esg-entry-content인 요소를 선택
여기서 .은 클래스(class)를 나타낸다. -
a
div.esg-entry-content 요소 내부의 모든 a 요소를 선택
a 요소는 HTML에서 하이퍼링크를 나타낸다. -
> span
a 요소의 직계 자식 요소인 span 요소를 선택
>는 직계 자식 요소를 의미한다. 즉, a 요소 바로 아래에 있는 span 요소를 선택
+) 선택자 경로를 div.esg-entry-content > a > span 이렇게 하지 않는 이유 ?
-
elements = soup.select('div.esg-entry-content > a > span')
: 이 선택자는 div 요소의 직계 자식으로 a 요소가 있어야 하고,
그 a 요소의 직계 자식으로 span 요소가 있어야 한다.
즉, div → a → span 구조 -
elements = soup.select('div.esg-entry-content a > span')
: 이 선택자는 div 요소 내부의 모든 a 요소를 찾고,
그 a 요소의 직계 자식으로 span 요소가 있는 경우를 선택한다.
즉, div 요소 내에 a 요소가 중첩되어 있어도 그 a 요소의 직계 자식 span을 선택
HTML 구조가 복잡해졌을 경우에도 유연하게 작동시키기 위해
div.esg-entry-content a > span선택자를 사용한다.
예시)
<div class="esg-entry-content">
<!-- 다른 내용들 -->
<div>
<a class="...">
<span style="...">클라우드 비용, 안녕하십니까?</span>
</a>
</div>
</div>위와 같은 구조에서 div.esg-entry-content > a > span은 작동하지 않지만,
div.esg-entry-content a > span 은 작동한다.
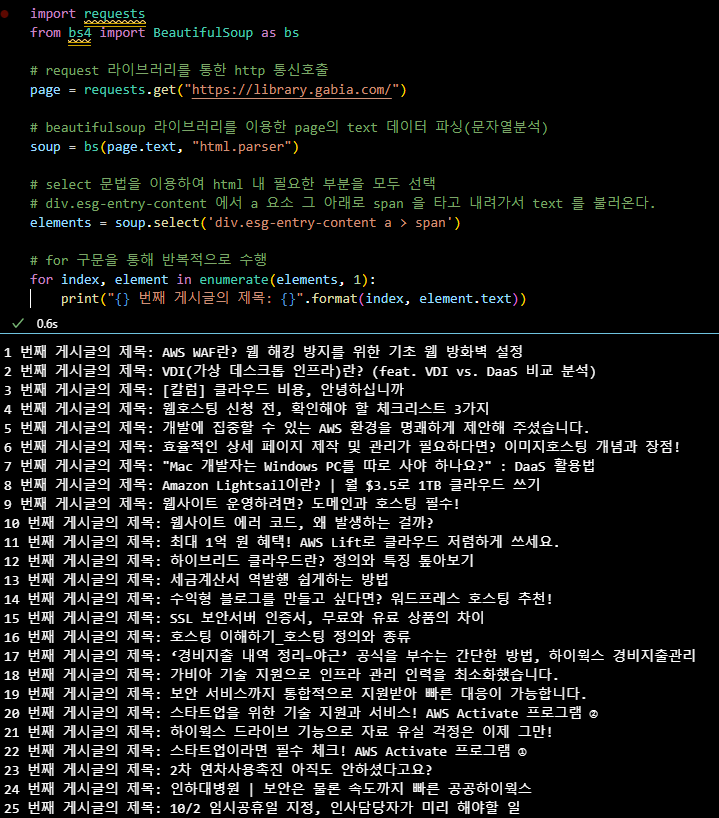
import requests
from bs4 import BeautifulSoup as bs
# request 라이브러리를 통한 http 통신호출
page = requests.get("https://library.gabia.com/")
# beautifulsoup 라이브러리를 이용한 page의 text 데이터 파싱(문자열분석)
soup = bs(page.text, "html.parser")
# select 문법을 이용하여 html 내 필요한 부분을 모두 선택
# div.esg-entry-content 에서 a 요소 그 아래로 span 을 타고 내려가서 text 를 불러온다.
elements = soup.select('div.esg-entry-content a > span')
# for 구문을 통해 반복적으로 수행
for index, element in enumerate(elements, 1):
print("{} 번째 게시글의 제목: {}".format(index, element.text))Selenium
- 라이브러리 불러오기
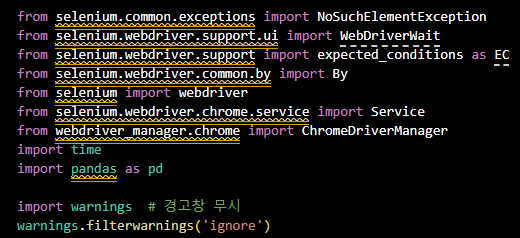
from selenium.common.exceptions import NoSuchElementException
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
import time
import pandas as pd
import warnings # 경고창 무시
warnings.filterwarnings('ignore')- 함수 구현
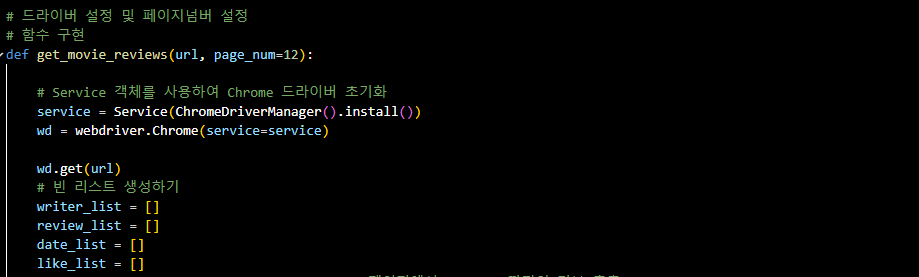
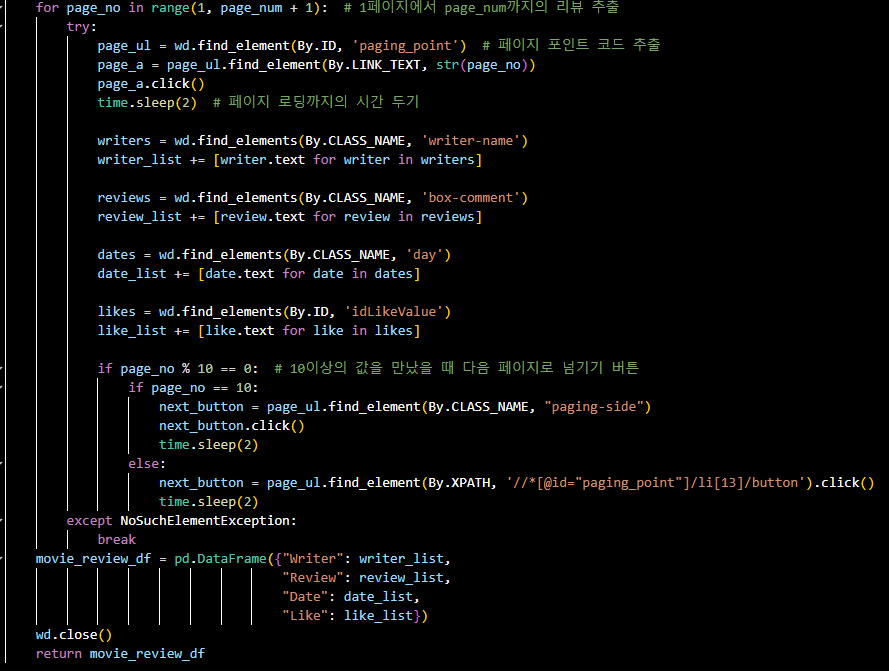

- 결과
# 3배속
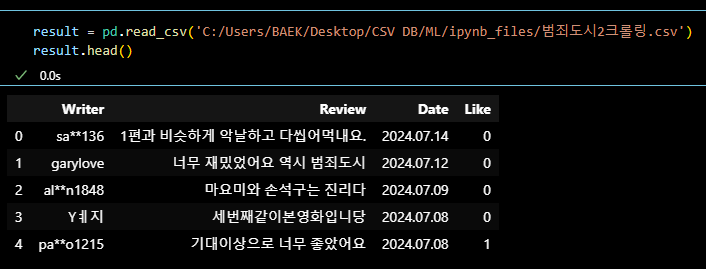
- 전체적인 흐름과 코드에 대한 이해를 할 수 있었다.
이제 다른 사이트에서 원하는 데이터를 크롤링해보는 연습을 해봐야지.
#커머스 데이터 분석 실무 (라이브 세션)
#가설설정 및 문제정의 (라이브 세션)
#OUTRO
오늘의 한 줄.
시간이 녹네.. 녹아..
