2️⃣ 2. AlexNet (2012, ImageNet 챌린지 우승)
목표: 고해상도 이미지 분류 (ImageNet 데이터셋, 1000종 분류)
입력 크기: 227×227×3 (RGB 이미지)
구성:: Conv (ReLU 포함) → Pool → Conv... → FC → FC → FC
특징
-
ReLU 활성화 함수 사용 (Sigmoid보다 빠르고 성능 좋음)
-
Dropout 도입 (과적합 방지)
-
GPU 2개 사용해서 학습
-
커널 사이즈가 큼 (예: 첫 Conv는 11x11 필터)
-
총 8개 레이어 (Conv 5개 + FC 3개)
🧠 핵심 개선: CNN이 대규모 이미지에도 통할 수 있음을 증명한 첫 모델
PyTorch 기반 AlexNet 실험 코드 설명
AlexNet을 사용해 CIFAR-10 데이터셋을 학습하고, 그 결과를 시각화하는 전체 파이프라인은 총 6단계로 구성
1단계: 라이브러리 설치 및 환경 설정
# 1. 라이브러리 설치 및 임포트
!pip install torch torchvision --quiet
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
from torch.utils.data import DataLoader
from torchvision import datasets, models
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"사용 디바이스: {device}")2단계: 데이터셋 준비
# 2. 데이터셋 준비 (CIFAR-10)
transform = transforms.Compose([
transforms.Resize(224), # AlexNet input size
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
train_set = datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
test_set = datasets.CIFAR10(root='./data', train=False, download=True, transform=transform)
train_loader = DataLoader(train_set, batch_size=64, shuffle=True)
test_loader = DataLoader(test_set, batch_size=64, shuffle=False)
classes = train_set.classes3단계: AlexNet 모델 구성
# 3. AlexNet 모델 로드 (사전 학습 X)
class CustomAlexNet(nn.Module):
def __init__(self, num_classes=10):
super(CustomAlexNet, self).__init__()
self.features = models.alexnet(pretrained=False).features
self.avgpool = nn.AdaptiveAvgPool2d((6, 6))
self.classifier = nn.Sequential(
nn.Dropout(), # 기본값 p = 0.5
nn.Linear(256 * 6 * 6, 4096),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Linear(4096, num_classes)
)
def forward(self, x):
x = self.features(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x
model = CustomAlexNet(num_classes=10).to(device)
-
self.features = models.alexnet(pretrained=False).features
PyTorch에서 제공하는 AlexNet 모델의 "Conv 블록" 부분만 가져옴
Conv → ReLU → MaxPool → Conv → ReLU → MaxPool → ... 포함 -
self.avgpool = nn.AdaptiveAvgPool2d((6, 6))
마지막 Conv 출력의 크기를 항상 (6,6)으로 고정
입력 이미지 크기에 관계없이 FC층에 일정한 크기를 보장하기 위한 장치 -
self.classifier = nn.Sequential(...)
Fully Connected (완전 연결) 계층들을 순차적으로 쌓은 부분- nn.Dropout() -> 과적합을 막기 위해 일부 뉴런을 학습 중 무작위로 끔
- nn.Linear(256 6 6, 4096) -> 입력 크기 = 256개의 채널 × 6 × 6 이미지,
출력 = 4096차원의 특징 벡터 - nn.ReLU(inplace=True) -> 📌 활성화 함수: 음수는 0으로, 양수는 그대로 → 비선형성 추가
- nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True) -> Dropout과 FC + ReLU 조합을 한 번 더 → 모델의 표현력을 더 키움 - nn.Linear(4096, num_classes) -> 마지막 분류 계층 → 클래스 개수만큼의 출력값 생성 (예: 10개 클래스 → [0.1, 0.2, ..., 0.05])
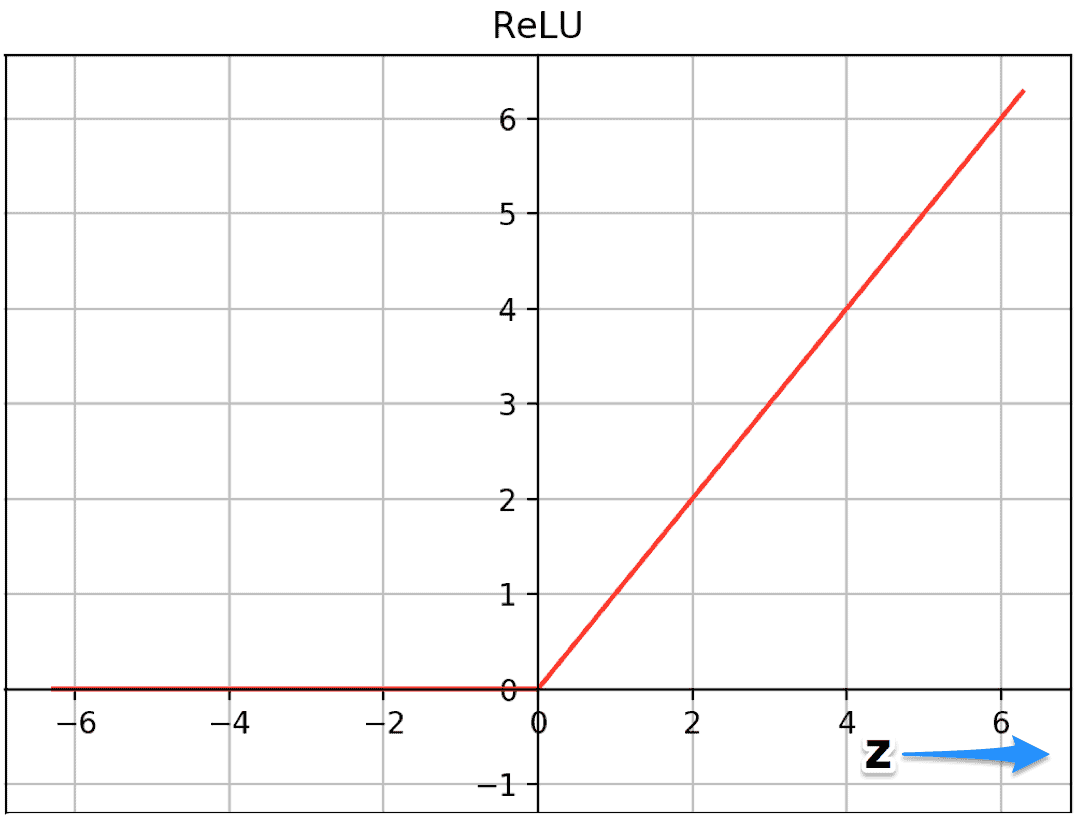
☑️ ReLu 함수
🔎 AlexNet에서는 기존의 tanh, sigmoid 활성화 함수 대신 ReLU 함수를 사용
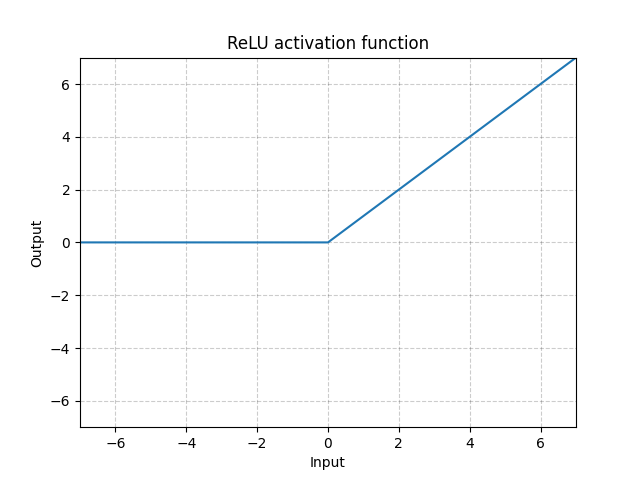
=> 음수 입력값에 대해서는 0을 출력하고, 양수 입력값에 대해서는 그대로 값 사용
🔎 ReLU는 기존의 sigmoid나 tanh 함수와 달리, 양수 영역에서 기울기가 1로 유지되어 gradient vanishing 문제를 해결하고 학습 속도를 크게 향상시킵니다. 실제로 ReLU는 tanh보다 약 6배 빠르게 수렴한다는 연구 결과도 있습니다.
🔍 ReLU 도입의 필요성
| 이유 | 설명 |
|---|---|
| 🚀 학습 속도 향상 | sigmoid, tanh는 기울기 소실(gradient vanishing)이 심함 |
| 💡 계산 간단 | 곱셈, 지수 없이 max(0, x)만 수행 |
| 🔥 비선형성 보장 | 선형 조합만으로는 복잡한 패턴 학습 불가하므로 비선형 함수가 필요 |
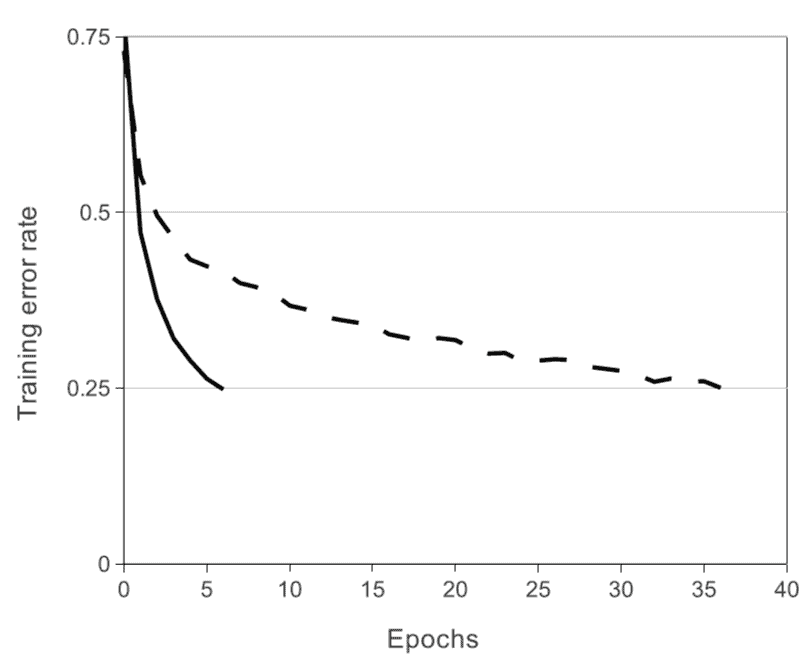
💡 위 그래프는 Dropout을 사용했을 때와 사용하지 않았을 때의 학습 오류율 변화를 비교한 것, Dropout을 사용한 경우 학습 오류율은 더 천천히 감소하지만, 이는 과적합을 방지하고 모델이 테스트 데이터에 더 잘 일반화되도록 도와준다는 것을 의미합니다.
☑️ Dropout - 과적합 방지
Dropout은 신경망 학습 시 일부 뉴런을 무작위로 꺼버리는(비활성화하는) 정규화 기법으로, 훈련 중 특정 뉴런이 너무 지배적으로 작동하는 것을 막아주어, 과적합(overfitting)을 줄이는 데 사용됩니다.
⚙️ 어떻게 작동?
🧠 학습 시:
각 forward pass마다 뉴런을 일정 확률(p)로 제거 (출력 0 처리)
예를 들어 Dropout(p=0.5)이면 절반 정도의 뉴런이 랜덤으로 꺼짐
🧠 추론(테스트) 시:
모든 뉴런을 사용하지만, 학습 때 꺼졌던 확률만큼 출력을 줄여서 보정
(예: 학습 때 절반만 썼다면, 테스트 시 출력 × 0.5로 보정)
Dropout 사용시 장점
| 문제 | Dropout이 주는 효과 |
|---|---|
| 과적합 | 여러 작은 모델을 무작위로 훈련시켜 앙상블 효과 발생 |
| 특정 뉴런에 의존 | 랜덤하게 뉴런을 꺼버려 다양한 뉴런 조합을 학습하게 함 |
| 일반화 부족 | 테스트 데이터에서도 잘 동작하는 범용 모델 생성 |
(4) 손실 함수 및 최적화 설정
# 4. 학습 설정
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.0001)
num_epochs = 10
train_loss_list = []
test_loss_list = []
train_acc_list = []
test_acc_list = []- CrossEntropyLoss: 다중 클래스 분류 문제에서 사용
- Adam Optimizer: 빠른 수렴을 위한 최적화 알고리즘
- CrossEntropy는 softmax + log-loss 조합으로 AlexNet 출력과 잘 맞음
(5) 모델 학습 및 평가 루프
# 5. 학습 및 검증
for epoch in range(num_epochs):
model.train()
running_loss = 0.0
correct = 0
total = 0
for images, labels in train_loader:
images, labels = images.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
_, predicted = outputs.max(1)
total += labels.size(0)
correct += predicted.eq(labels).sum().item()
train_loss = running_loss / len(train_loader)
train_acc = 100. * correct / total
train_loss_list.append(train_loss)
train_acc_list.append(train_acc)
# 검증
model.eval()
test_loss = 0.0
correct = 0
total = 0
with torch.no_grad():
for images, labels in test_loader:
images, labels = images.to(device), labels.to(device)
outputs = model(images)
loss = criterion(outputs, labels)
test_loss += loss.item()
_, predicted = outputs.max(1)
total += labels.size(0)
correct += predicted.eq(labels).sum().item()
test_loss /= len(test_loader)
test_acc = 100. * correct / total
test_loss_list.append(test_loss)
test_acc_list.append(test_acc)
print(f"[Epoch {epoch+1}] Train Loss: {train_loss:.4f}, Acc: {train_acc:.2f}% | Test Loss: {test_loss:.4f}, Acc: {test_acc:.2f}%")[Epoch 1] Train Loss: 1.5316, Acc: 43.35% | Test Loss: 1.1921, Acc: 57.31%
[Epoch 2] Train Loss: 1.0598, Acc: 62.21% | Test Loss: 0.9721, Acc: 66.14%
[Epoch 3] Train Loss: 0.8356, Acc: 70.44% | Test Loss: 0.7642, Acc: 73.95%
[Epoch 4] Train Loss: 0.6897, Acc: 75.70% | Test Loss: 0.7281, Acc: 75.05%
[Epoch 5] Train Loss: 0.5917, Acc: 79.41% | Test Loss: 0.6162, Acc: 78.77%
[Epoch 6] Train Loss: 0.5055, Acc: 82.31% | Test Loss: 0.5878, Acc: 79.99%
[Epoch 7] Train Loss: 0.4278, Acc: 85.09% | Test Loss: 0.5402, Acc: 81.58%
[Epoch 8] Train Loss: 0.3693, Acc: 86.98% | Test Loss: 0.5407, Acc: 81.69%
[Epoch 9] Train Loss: 0.3095, Acc: 89.21% | Test Loss: 0.6052, Acc: 80.79%
[Epoch 10] Train Loss: 0.2625, Acc: 90.81% | Test Loss: 0.5418, Acc: 83.06%
(6) 학습 결과 시각화
# 6. 결과 시각화
epochs = range(1, num_epochs + 1)
plt.figure(figsize=(12, 5))
plt.subplot(1, 2, 1)
plt.plot(epochs, train_loss_list, label='Train Loss')
plt.plot(epochs, test_loss_list, label='Test Loss')
plt.title('Loss per Epoch')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(epochs, train_acc_list, label='Train Acc')
plt.plot(epochs, test_acc_list, label='Test Acc')
plt.title('Accuracy per Epoch')
plt.xlabel('Epoch')
plt.ylabel('Accuracy (%)')
plt.legend()
plt.tight_layout()
plt.show()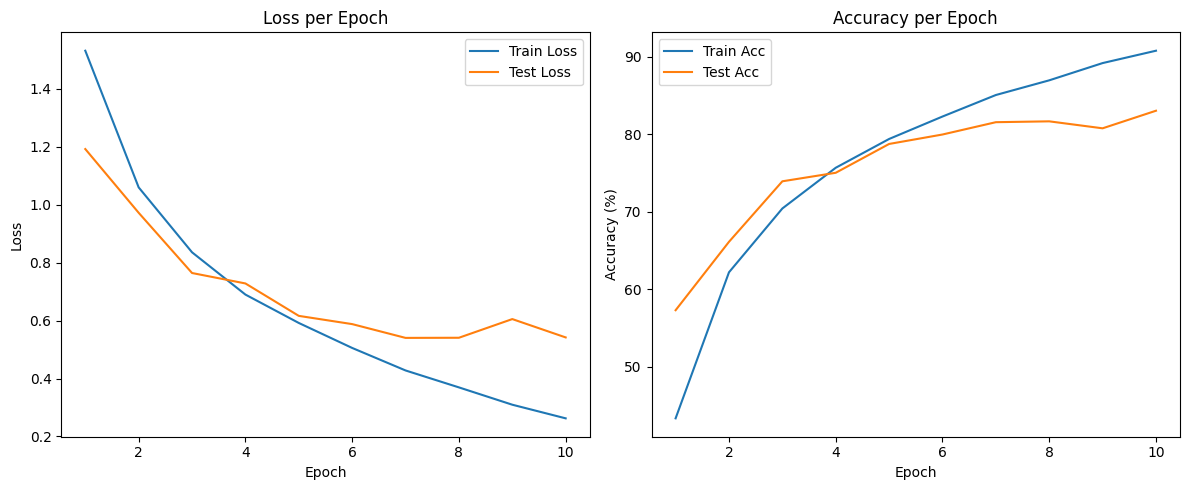
[정리]
| Epoch | Train Acc | Test Acc | Overfitting 여부 |
|---|---|---|---|
| 1 → 5 | 43% → 79% | 57% → 78% | ❌ 거의 없음 (잘 학습됨) |
| 6 → 8 | 82% → 87% | 79% → 81% | ⚠ 미세한 과적합 조짐 |
| 9 →10 | 89% → 91% | 80% → 83% | ⚠ 과적합 가능성 있음 (test loss ↑) |
