NumPy란?
- 다차원 배열을 효율적으로 처리하고 쉽게 사용할 수 있는 파이썬 라이브러리
- 데이터 구조 및 수치 계산을 위한 효율적 기능 제공
- Numpy의 ndarray는 파이썬의 list에 비해 빠르고, 메모리를 효율적으로 사용한다.
파이썬 리스트와 처리 속도 비교
1. 파이썬 리스트
import random, statistics
# 무작위 숫자 1,000,000개를 생성
my_arr = [random.random() for i in range(1_000_000)]
print(my_arr)결과: list
%timeit
statistics.mean(my_arr)결과: 633 ms ± 9.8 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
2. 넘파이 배열
# numpy는 보통 np라는 이름으로 alias하여 import한다
import numpy as np
# list를 ndarray로 변환
arr = np.array(my_arr)
print(type(arr))결과: numpy.ndarray
%timeit
np.mean(arr)결과: 536 µs ± 105 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
numpy ndarray가 list보다 훨씬 빠르다.
빠른 이유는 여러 가지가 있다고 하는데, 그 중 하나는 하나의 자료형으로만 구성되기 때문에 메모리를 연속적으로 사용할 수 있어 효율적이라는 점이다.
배열 생성

numpy의 배열은 기본적으로 np.array() 함수를 사용하여 생성할 수 있다.
1d_arr = np.array([1, 2, 3, 4, 5])
2d_arr = np.array([[1, 2, 3]
[4, 5, 6]])
3d_arr = np.array([[[1, 2, 3, 4], [5, 6, 7, 8]],
[[9, 10, 11, 12], [13, 14, 15, 16]],
[[17, 18, 19, 20], [21, 22, 23, 24]]])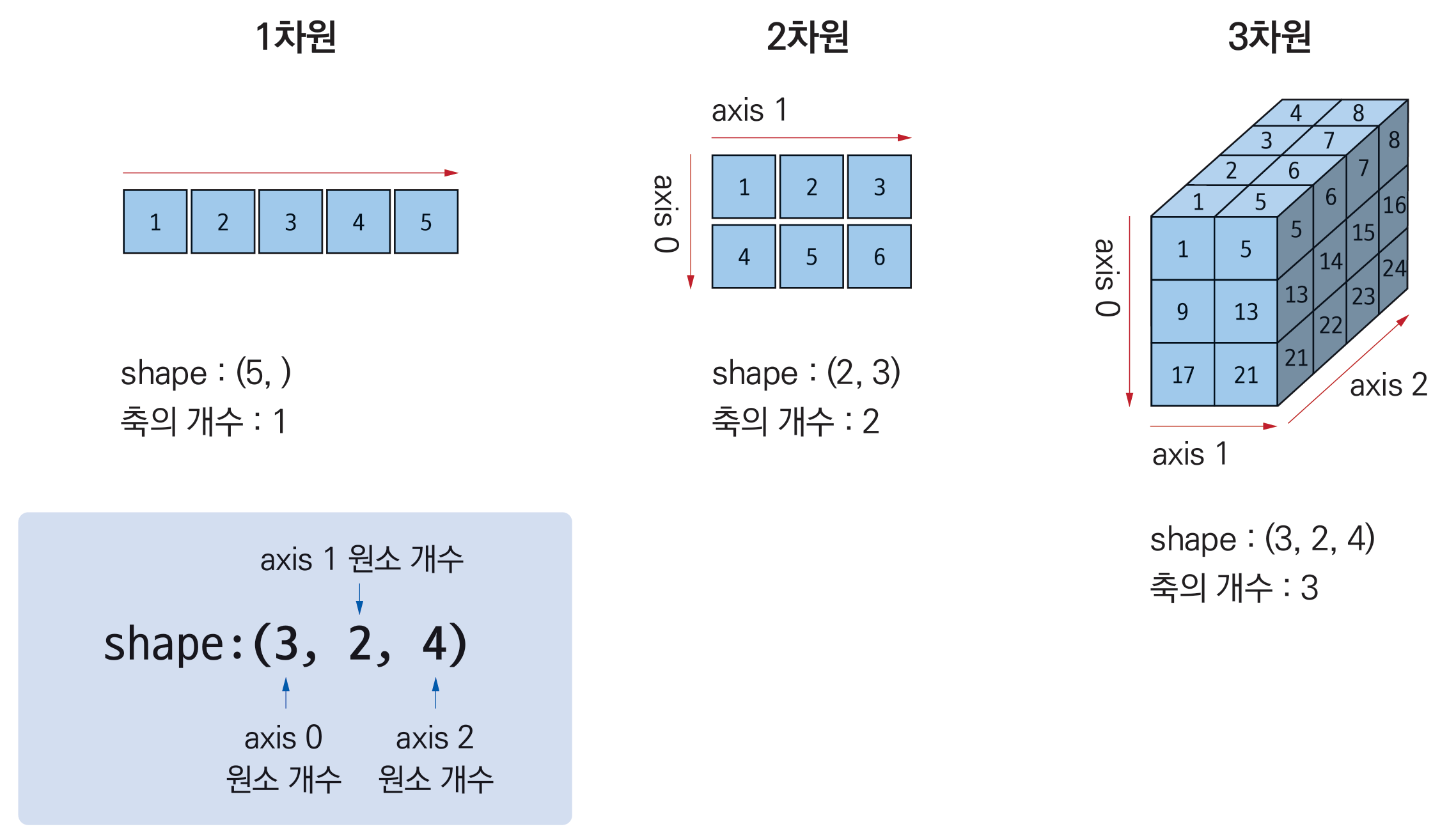
numpy 배열은 다음과 같은 여러 속성을 가지고 있다.
shape: 배열의 형태를 튜플(Tuple) 자료형으로 표현한다.ndim: 몇 차원 배열인지 축의 개수를 나타낸다.size: 전체 원소(element)의 개수를 나타낸다.dtype: 배열 원소의 자료형을 나타낸다. (모든 원소가 같은 자료형으로 구성되기 때문에 존재할 수 있다)
2d_arr = np.array([[1, 2, 3]
[4, 5, 6]])
print(2d_arr.shape) # 출력: (3, 5)
print(2d_arr.ndim) # 출력: 2
print(2d_arr.size) # 출력: 6
print(2d_arr.dtype) # 출력: int64특정 함수를 사용하면 배열을 생성하면서 값을 초기화할 수 있다.
np.zeros() 함수를 사용하면 모든 원소가 0으로 구성되는 배열이 생성된다.
np.ones() 함수를 사용하면 모든 원소가 1로 구성되는 배열이 생성된다.
np.full() 함수를 사용하면 모든 원소가 지정값으로 구성되는 배열이 생성된다.
np.zeros_like() 함수를 사용하면 지정 배열과 똑같은 크기로 np.zeros()를 수행하는 결과를 얻는다.
np.arrage() 함수를 사용하면 지정 범위에 지정 간격의 값으로 구성되는 배열을 얻는다.
arr1 = np.zeros((3, 2))
'''
결과: array([[0., 0.],
[0., 0.],
[0., 0.]])
'''
arr2 = np.ones((2, 4))
'''
결과: array([[1., 1., 1., 1.],
[1., 1., 1., 1.]])
'''
arr3 = np.full((2, 3), -1)
'''
결과: array([[-1, -1, -1],
[-1, -1, -1]])
'''
arr_temp = np.array([[[1, 2], [3, 4]],
[[5, 6], [7, 8]]])
arr4 = np.zeros_like(arr_temp)
'''
결과: array([[[0., 0.],
[0., 0.]],
[[0., 0.],
[0., 0.]]])
'''
arr5 = np.arange(0, 10, 1)
'''
결과: array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
'''인덱싱(indexing)과 슬라이싱(slicing)
배열에서 인덱싱을 통해 특정 인덱스의 값을 얻을 수 있으며, 슬라이싱을 통해 특정 인덱스 범위의 값을 얻을 수 있다.
이때, 슬라이싱의 마지막 인덱스는 포함하지 않는다.
여기서 음수 인덱스는 뒤에서부터의 인덱스를 나타내며, -1이 마지막 인덱스를 나타낸다.
arr = np.array([1, 2, 3, 4, 5, 6, 7])
print(arr[3]) # 4
print(arr[3:]) # [4 5 6 7]
print(arr[-1]) # 7
print(arr[3:-1]) # [4 5 6]
print(arr[-3:]) # [5 6 7]Boolean Indexing
각 인덱스에 대응되는 boolean 배열을 사용하여 원하는 값만 가져올 수 있다.
arr = np.array([1, 2, 3, 4, 5])
idx = np.array([True, False, True, False, True])
# 인덱스가 True인 경우만 가져온다
print(arr[idx]) # [1 3 5]
# 따로 배열을 사용하지 않고 조건으로도 boolean indexing이 가능하다
print(arr[arr > 3]) # [4, 5]Fancy Indexing
인덱스 값을 나타내는 배열을 사용하여 원하는 값만 가져올 수 있다.
arr = np.array([1, 2, 3, 4, 5])
idx = np.array([1, 3])
# 지정된 인덱스만 가져옴
print(arr[idx]) # [2 4]배열 형태 변환
reshape() 함수를 사용하여 배열의 형태를 변환할 수 있다.
배열의 나머지 크기를 모두 설정하고, 남은 하나의 축에 -1을 설정하면 설정된 크기에 맞춰 남은 축의 크기를 알아서 설정해준다.
arr = np.array([1, 2, 3, 4, 5, 6])
arr1 = arr.reshape((2, 3))
'''
결과: array([[1, 2, 3],
[4, 5, 6]])
'''
arr2 = arr1.reshape(6) # flatten(), ravel() 함수로도 동일한 결과 얻기 가능
'''
결과: array([1, 2, 3, 4, 5, 6])
'''
arr3 = arr.reshape((1, 2, -1)) # arr.reshape((1, 2, 3))과 동일
'''
결과: array([[[1, 2, 3],
[4, 5, 6]]])
'''Axis를 고려한 연산
합 구하기, 평균 구하기 등의 다양한 연산을 특정 축에 대해서 수행할 수 있다.
arr = np.array([[1, 2, 3]
[4, 5, 6]])
print(np.sum(arr)) # 21
print(np.sum(arr, axis=0)) # [5 7 9]
print(np.sum(arr, axis=1)) # [6 15]배열을 파일로 저장하고 불러오기
np.savez()를 사용하여 배열을 파일로 저장하고, np.load()를 사용하여 불러올 수 있다.
arr = np.array([1, 2, 3, 4, 5, 6])
# 파일로 저장하기
np.savez(`my_data.npz', train=arr)
# 파일 불러오기
data = np.load('my_data.npz')
print(data['train']) # [1 2 3 4 5 6]