pandas란?
- 데이터 조작 및 분석을 위한 파이썬 라이브러리로, NumPy를 기반으로 하여 처리 속도가 빠르다.
- 데이터 조작을 위한 빠르고 효율적인 데이터 프레임 객체를 사용한다.
- 데이터 구조 정렬, 결손치 처리, 열 데이터 정렬 등의 다양한 데이터 조작 방법을 제공한다.
Series와 DataFrame
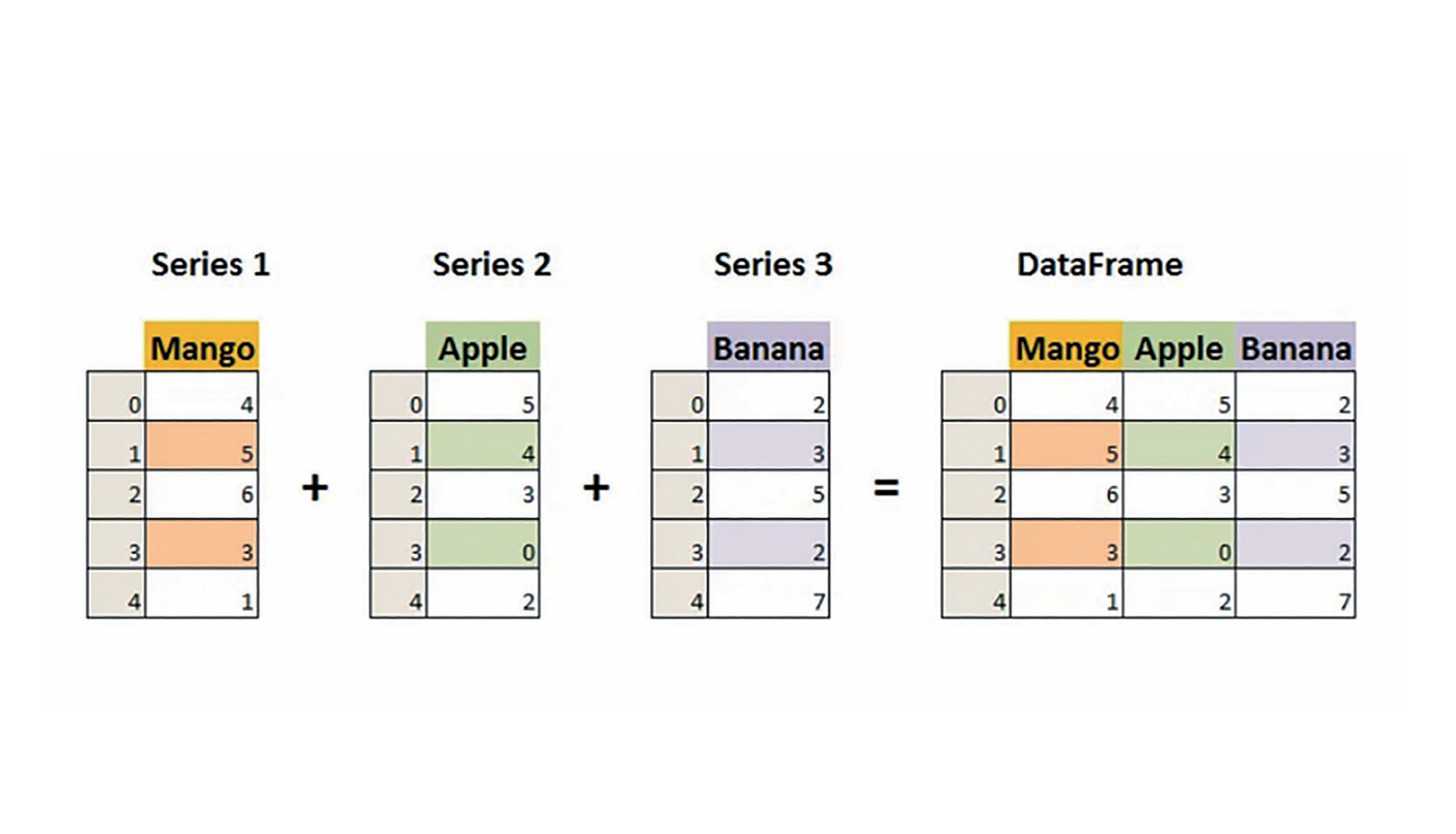
pandas에서는 Series 객체와 DataFrame 객체를 자료구조로 사용한다.
Series
- 1차원 배열 구조를 가지며, 인덱스(index)를 가진다.
- dtype, shape 등의 속성을 가진다.
DataFrame
- 2차원 배열 구조를 가지며, 인덱스(index)를 가진다.
- 행(row)과 열(column)로 구성되며, 각 열은 이름을 가진다.
- 각 열은 각각의 데이터 타입을 가지며, Series 객체로 표현할 수 있다.
- dtype, shape 등의 속성을 가진다.
Series 객체를 생성하기
# pandas는 일반적으로 pd로 alias하여 import한다.
import pandas as pd
sr = pd.Series([1, 2, 3, 4], name='A') # Series의 이름을 설정할 수 있다.
print('type: ', type(sr))
print('dtype: ', sr.dtype)
print(sr)결과
type: <class 'pandas.core.series.Series'> dtype: int64 0 1 1 2 2 3 3 4 Name: A, dtype: int64
Index를 지정해서 Series 생성하기
sr = pd.Series([1, 2, 3, 4], index=['A', 'B', 'C', 'D'])
print('type: ', type(sr))
print('dtype: ', sr.dtype)
print(sr)결과
type: <class 'pandas.core.series.Series'> dtype: int64 A 1 B 2 C 3 D 4 dtype: int64
직접 데이터를 입력해 Dataframe 객체 생성하기
info = {
'Name':['Jackson', 'Emma', 'Noah', 'James'],
'Weight':[68, 74, 77, 78],
'Option':[True, True, False, False],
'Rate':[0.21, 1.1, 0.89, 0.91],
'Type':['A','A','C','C']
}
df = pd.DataFrame(info)
df결과
Name Weight Option Rate Type 0 Jackson 68 True 0.21 A 1 Emma 74 True 1.10 A 2 Noah 77 False 0.89 C 3 James 78 False 0.91 C
csv 파일을 읽어 DataFrame 생성하기
titanic = pd.read_csv('./datasets/titanic.csv')
print('type: ', type(titanic))
print('shape: ', titanic.shape)결과
type : <class 'pandas.core.frame.DataFrame'> shape : (891, 12)
DataFrame의 속성
shape: 데이터의 행과 열의 수를 튜플로 얻는다.dtypes: 각 열의 데이터 타입을 나타낸다.columns: 각 열의 이름을 나타낸다.index: 행의 인덱스를 나타낸다.
DataFrame 함수
head(): 데이터 프레임의 처음부터 설정 개수만큼 표시tail(): 데이터 프레임의 끝에서 설정 개수만큼 표시info(): 데이터 프레임의 정보 표시describe(): 각 열의 통계 정보 표시
결측치(Missing Value) 확인 및 처리
결측치는 데이터가 없는 경우를 나타내며, 이러한 값은 데이터 분석에 악영향을 끼치므로 이를 처리할 필요가 있다.
isna() 함수를 사용하여 결측치를 확인할 수 있다.
import numpy as np
# DataFrame 생성
z = [['Jackson', 68, True, np.NaN, 'A'],
['Liam', 74, True, 1.1, 'A'],
['Emma', np.NaN, False, 0.89, 'C'],
['James', 78, np.NaN, 0.91, 'C'],
['Ava', 54, False, 0.73, 'C'],
['Henry', 69, True, np.NaN, 'C']]
df = pd.DataFrame(data= z, columns=['Name', 'Weight', 'Option', 'Rate', 'Type'])
df.isna().sum(axis=0) # axis=0은 x축에 걸쳐 합을 구하는 것을 나타낸다결과
Rank 0 Name 0 Platform 0 Year 271 Genre 0 Publisher 58 NA Sales 0 EU Sales 0 JP Sales 0 Other Sales 0 Global Sales 0 dtype: int64
dropna() 함수를 사용하면 결측치가 포함된 행을 삭제할 수 있다.
df.dropna()결과
Name Weight Option Rate Type 1 Liam 74.0 True 1.10 A 4 Ava 54.0 False 0.73 C
fillna() 함수를 사용하면 결측치를 특정 값으로 변경할 수 있다.
df.fillna(0)결과
Name Weight Option Rate Type 0 Jackson 68.0 True 0.00 A 1 Liam 74.0 True 1.10 A 2 Emma 0.0 False 0.89 C 3 James 78.0 0 0.91 C 4 Ava 54.0 False 0.73 C 5 Henry 69.0 True 0.00 C
다만 단순히 이렇게 수행하면 기존 데이터 프레임의 값은 변경되지 않고 남아있다.
값을 변경하고 반영하고 싶다면 함수 내에서 inplace=True 설정을 하거나, df = df.dropna()와 같이 작성하여야 한다.
결측치를 무작정 대체하거나 삭제하면 안 되고, 각 column 데이터의 특성을 고려해야 한다.
인덱싱과 슬라이싱
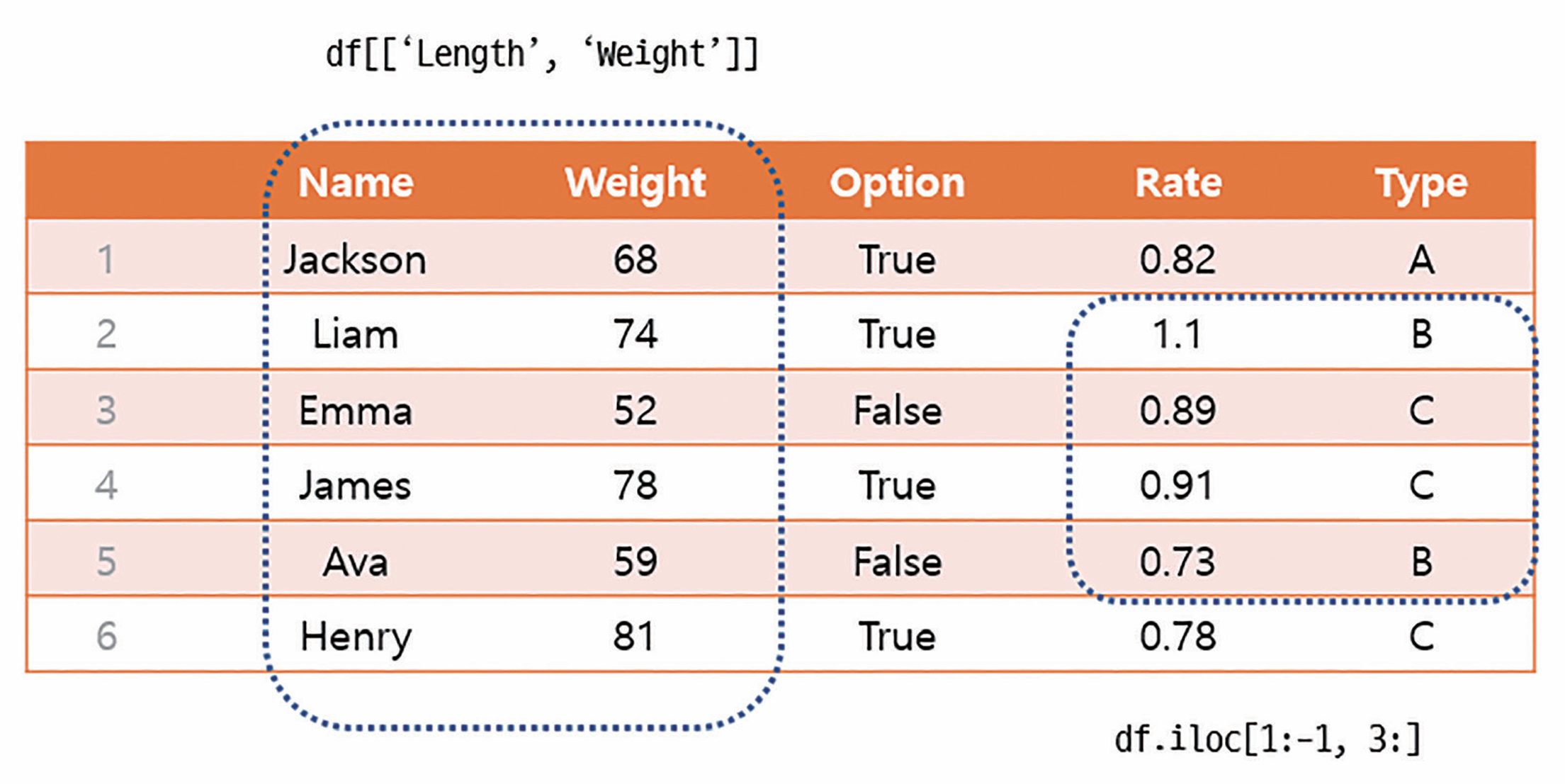
인덱싱: 데이터 프레임의 특정 원소에 접근
슬라이싱: 특정 부분의 데이터를 추출
슬라이싱은 loc과 iloc를 이용하여 수행할 수 있다.
loc:loc[행 인덱싱, 열 인덱싱]또는loc[행 인덱싱]의 형태로 사용한다. 여기서 열은 컬럼명을 의미한다.iloc:loc과 유사하지만 행과 열의 이름이 아닌 위치 정수 인덱스를 사용한다(파이썬 리스트와 같다고 생각하면 됨). 따라서 fancy indexing에 활용할 수 있다.
loc을 사용하면 특정 조건에 맞는 행만 추출할 수 있다.
x = [['Jackson', 68, True, 0.82, 'A'],
['Liam', 74, True, 1.1, 'B'],
['Emma', 52, False, 0.89, 'C'],
['James', 78, True, 0.91, 'C'],
['Ava', 54, False, 0.73, 'B'],
['Henry', 69, True, 0.78, 'C']]
df = pd.DataFrame(x, columns=['Name', 'Weight', 'Option', 'Rate', 'Type'])
x = df.loc[df['Rate']>0.8, ['Weight', 'Rate', 'Type']]
print('type : ', type(x))
print(x)결과
type : <class 'pandas.core.frame.DataFrame'> Weight Rate Type 0 68 0.82 A 1 74 1.10 B 2 52 0.89 C 3 78 0.91 C
다중 조건을 사용할 수도 있다. 다만 이때는 각 조건을 괄호로 구분하여야 한다.
x = df.loc[(df['Rate']>0.8) & (df['Option']==True), :]
print(x)결과
Name Weight Option Rate Type 0 Jackson 68 True 0.82 A 1 Liam 74 True 1.10 B 3 James 78 True 0.91 C
select_dtypes() 함수를 사용하여 특정 데이터 타입을 갖는 column만 추출할 수 있다.
# 숫자로 된 column만 가져오기
x = df.select_dtypes(include=['number'])
print(x)결과
Weight Rate 0 68 0.82 1 74 1.10 2 52 0.89 3 78 0.91 4 54 0.73 5 69 0.78
데이터 프레임 변경
데이터 프레임 변경에는 column 추가 및 삭제, column 이름 변경, 특정 부분 값 변경, 인덱스 변경이 있다.
# 데이터 프레임 생성
x = [['Jackson', 68, True],
['Liam', 74, True],
['Emma', 52, False],
['James', 78, True],
['Ava', 54, False],
['Henry', 69, True]]
df = pd.DataFrame(x, columns=['Name', 'Weight', 'Option'])
# 컬럼 추가
# 새로운 column 이름을 설정하면 추가된다.
df['Type'] = 'A' # 'Type' 컬럼을 추가하고 모든 값을 'A'로 설정
# 컬럼명 변경
df.rename(columns={'Type': 'Grade'}, inplace=True)
# 전체 컬럼명 변경
df.columns = ['A', 'B', 'C', 'D']
# 특정 값 변경
df.loc[1, 'B'] = 100
# 특정 부분 값 수정
df.loc[df['C'] == False, 'D'] = np.nan
# 컬럼 삭제
# axis=1를 설정해 column을 삭제함을 명시적으로 적어야 한다.
df.drop(['C', 'D'], axis=1, inplace=True)통계 데이터 계산
통계 데이터를 계산하는 다음과 같은 함수가 있다.
mean(): 평균값 계산var(): 분산 계산std(): 표준편차 계산sum(): 합계count(): 전체 개수values_count(): 범주형 데이터의 종류별 데이터 개수unique(): 범주형 데이터 종류의 개수
values_count()를 사용하는 예시
# 데이터셋 불러오기
titanic = pd.read_csv('./datasets/titanic.csv')
x = titanic['Sex'].value_counts()
print(x)결과
male 577 female 314 Name: Sex, dtype: int64
