✨Concurrency (2)
운영체제

Lock-based Concurrent Data Structure
thread structure를 safe하게 만들어주기 위해서 lock을 data structure에 추가한다.
이 data structure는 multiple thread가 접근할 수 있는 data structure이다.
lock이 어떻게 add되었냐가 data structure의 correctness와 performance를 결정한다.
Concurrent Counters Without Locks
 shared variable에 접근하는 code segment가 critical section이 된다.
shared variable에 접근하는 code segment가 critical section이 된다.
Coucurrent Counters With Locks
Single lock을 추가한다.
data structure를 manipulate하는 routine을 call할 때 lock이 acquire된다.


The Performance Cost of the Simple Approach
각 thread는 single shared counter를 update할 때
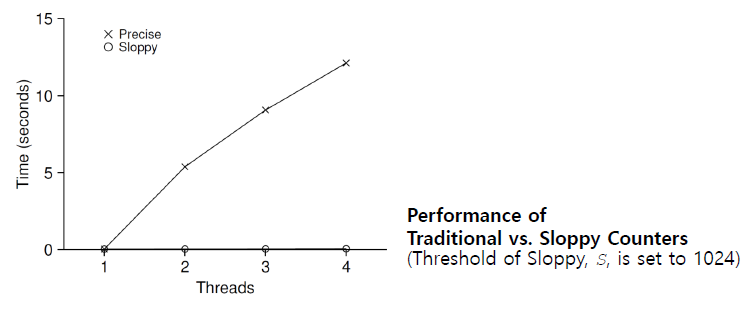 variable에 access할 때마다 lock을 acquire하기 때문에 performance가 guarantee되지 않고 오히려 점점 worse해진다.
variable에 access할 때마다 lock을 acquire하기 때문에 performance가 guarantee되지 않고 오히려 점점 worse해진다.
thread의 수가 늘어날수록 counting operation을 끝내기 위한 시간이 길어진다. 많은 thread가 lock variable을 competing하기 때문이다.
한 thread가 lock을 acquire하면 그 variable을 사용하고자 하는 남은 모든 thread는 block된다.
이런걸 giant lock variable이라고 한다.
impact가 크다는 것임. 크기가 크다는 것이 아니라.
Synchronized counter scales poorly.
Perfect Scaling
더 많은 작업이 수행되더라도 병렬적으로 처리된다.
task를 완료하는 데에 드는 시간은 증가하지 않는다.
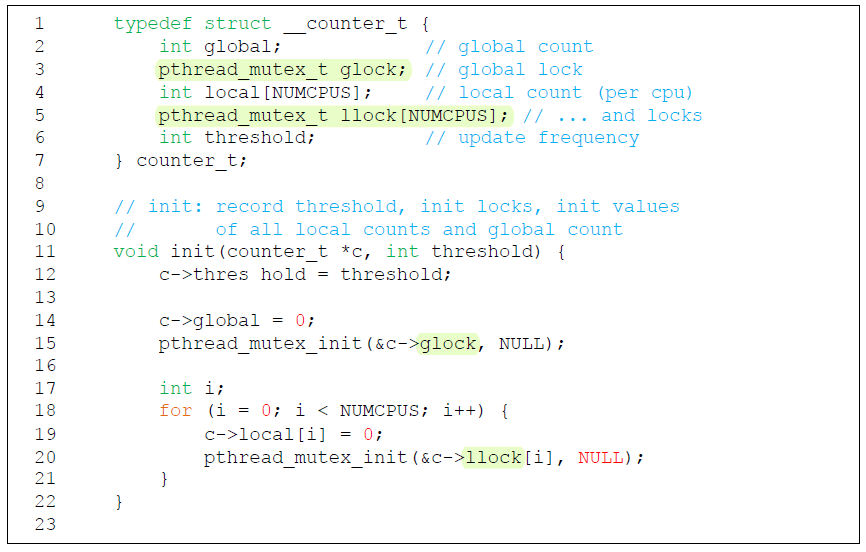
Sloppy Counter
sloppy는 lazy, loose하다는 뜻이다.
sloppy counter는
- 각 CPU core마다 갖고 있는 local physical counter를 통해 나타내는 single local counter
- 하나의 global counter
- lock (각 local counter들에 대한 것 하나, global counter에 대한 것 하나)
을 통해 표현된다.
예를 들면, CPU가 4개인 컴퓨터에 대해 4 개의 local counter, 1 개의 global counter를 갖는다.
Sloppy counter는 shared variable에 접근할 때 항상 lock을 획득하는 것이 아니다.
Shared variable에 접근할 때마다 giant lock을 획득하는 것이 아니라 global variable의 local copy를 가지고 그 local counter로 작업을 한다. 그렇게 하면 자신의 local counter를 사용하는거라 다른 thread와 경쟁할 필요가 없다!
하지만 local counter만 사용한다면 global counter를 maintain하는 의미가 없다.
누군가가 counter의 정확한 값을 읽기를 바란다면 그 사람은 global counter의 값을 읽어야 한다.
Local counter를 관리하다가 주기적으로 global counter의 값을 update하고 그 때만 global lock을 acquire하는 것이다.
그러면 global lock을 획득하는 횟수가 줄어들면서 performance 문제를 해결할 수 있다.
The Basic Idea of Sloppy Counting
Core에서 running하는 thread는 counter를 update하고 싶어한다.
이 때 sloppy counter에서는 자신의 local counter를 증가시킨다.
각 CPU는 자신의 own local counter를 가지고 있다.
CPU의 각 thread는 자신의 local counter를 contention없이 update할 수 있다! local counter에 access하는 것이기 때문에 waiting하지 않는다는 것이다.
그러므로 (local) counter update는 scalable하다.
그리고 각 local value는 periodically하게 global counter로 transfer된다.
Global lock을 획득하고 global counter의 값을 local counter의 값만큼 증가시킨 뒤 local counter를 0으로 리셋시킨다.
얼마나 자주 local-to-global transfer가 발생하는지는 threshold S(sloppiness)가 결정한다.
S가 작을 수록 counter는 non-scalable counter처럼 동작한다.
S가 클 수록 counter는 scalable해지고 global counter의 값이 실제 count의 값과 달라진다.
Sloppy counter에서 performance와 accuracy 사이에는 trade-off이 존재한다.
Global counter의 값을 매우 정확하게 유지하려면 local counter의 값을 update할 때마다 global counter의 값을 update 해야하고 그것이 performance를 저하시킨다.
하지만 sloppiness를 높게 만들면 accuracy가 감소한다. 바뀐 값이 global counter에 낮은 주기로 반영되기 때문이다.
Sloppy Counter Example
Threshold S는 5로 set 되어있다.
4개의 CPU에 각각 thread가 존재한다.
각 thread는 자신의 local counter L1, ..., L4를 update한다.
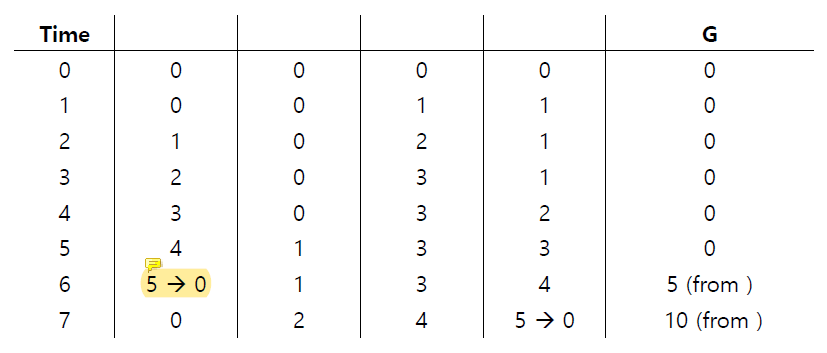 각 local counter에서
각 local counter에서 S에 도달할 때마다 lock을 획득해 global counter에 값을 반영하고 있다.
매우 작은 sloppiness를 사용하면 global counter가 매우 정확하지만 global lock을 acquire하고 release하는 빈도가 증가하면서 performance가 매우 낮아진다.
Low performance -> accurate counter
High performance -> inaccurate counter
각 4개의 thread가 counter의 값을 4개의 CPU에 대해 1 million times 증가시킬 때
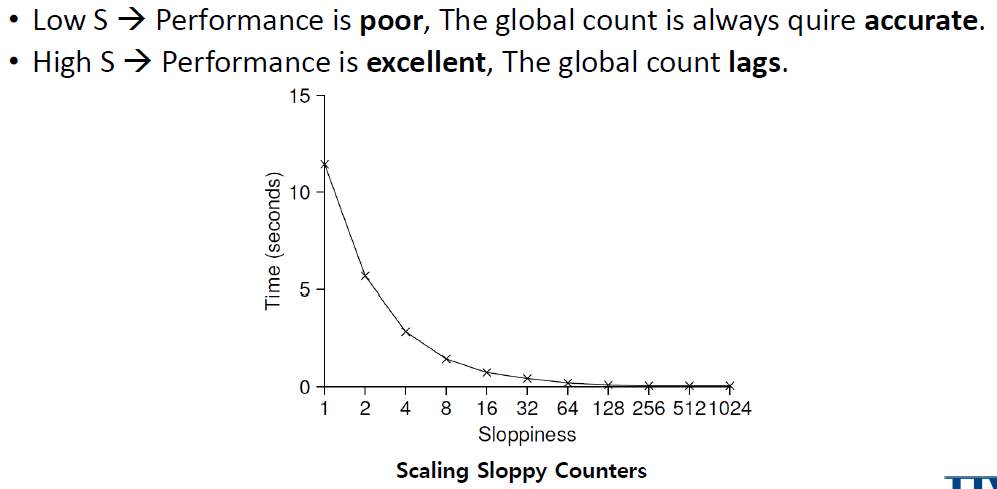
Sloppy Counter Implementation
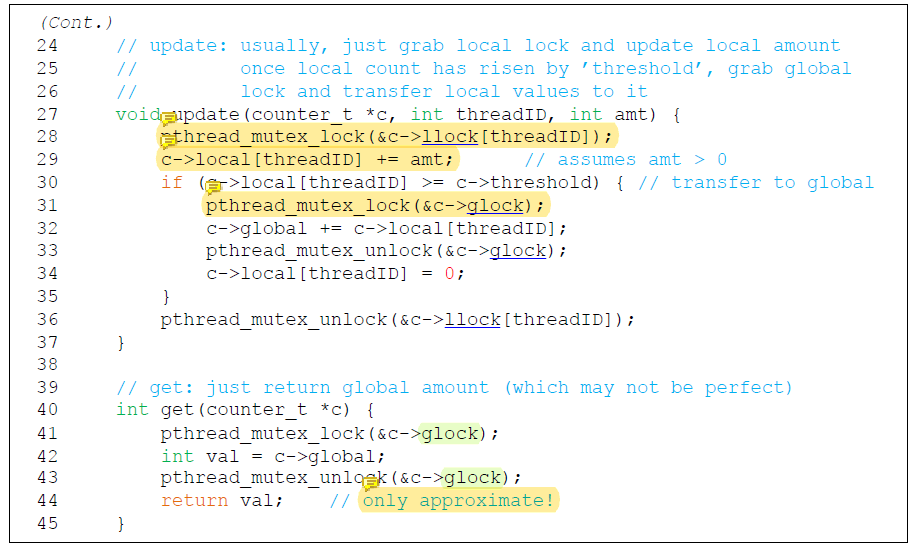
Core의 local counter에 대해 lock을 획득한 후 counter의 값을 증가시키지만 성능에는 영향을 미치지 않는다.
하지만 global lock을 획득할 때에는 같은 상황에 직면한 다른 thread들과 경쟁하게 된다. 이 때 성능저하가 발생한다.
Global counter의 값은 정확한 값이 아닐 수 있다. global counter를 항상 update하는 것이 아니기 때문이다.
Concurrent Linked Lists
Concurrent linked list는 여러 thred가 동시에 linked list에 접근할 수 있도록 하는 것이 목표이다.

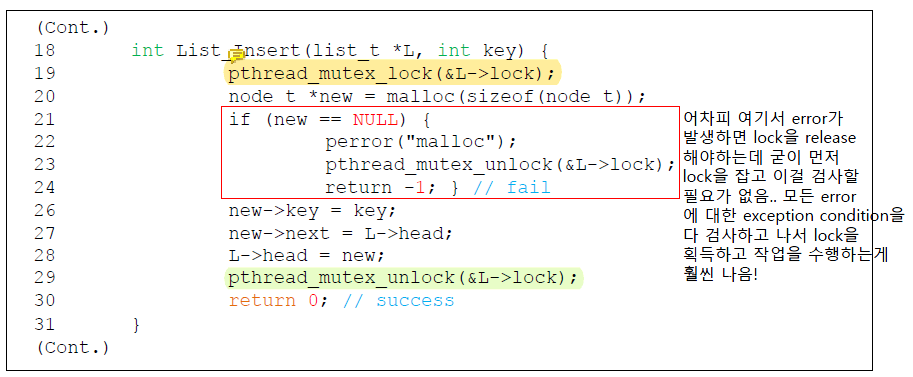

Concurrent linked list에 새로운 node를 insert할 때에는 linked list 전체를 protect하는 global lock을 획득해야한다.
위의 코드는 insert의 entry부터 lock을 acquire했지만 malloc()이 실패할 경우 insert에 fail하기 전에 lock을 release 해야하므로 비효율적이다.
이 때 lock을 획득하려면 경쟁을 해야하므로 최대한 lock을 덜 잡기 위해 exception condition을 다 검사한 뒤에 lock을 획득하고, actual critical section만 lock으로 둘러싸야한다.
이에 따라 코드를 수정하면 다음과 같이 된다.
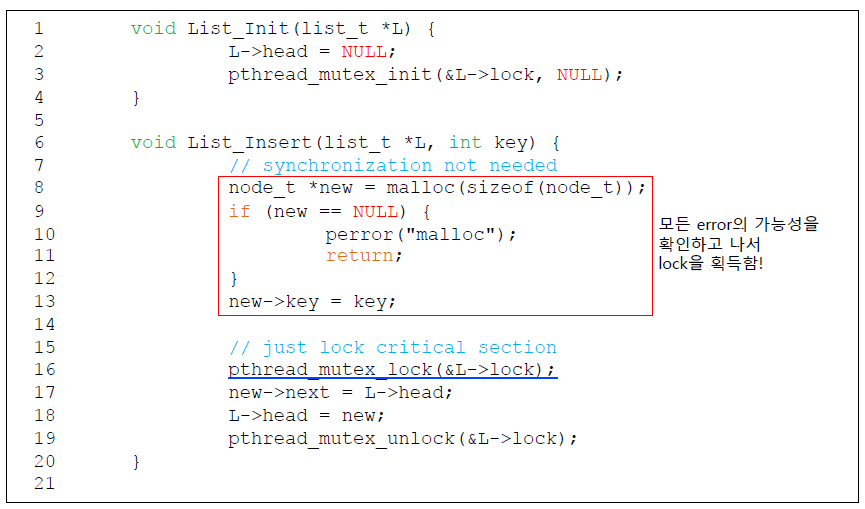

Scaling Linked List
Scaling linked list는 hand-over-hand locking(lock coupling)을 사용한다.
Hand-over-hand locking은 hand shaking을 한다는 뜻으로, 전체 list에 대한 global lock을 사용하지 않고 각 node마다 lock varible을 갖는다. 특정 node에 lock을 먼저 걸어서 key를 확인하고 내가 찾던 key가 아니면 다음 key를 확인하기 위해 다음 node에 lock을 건다.
특정 node에 lock을 먼저 걸어서 key를 확인하고 내가 찾던 key가 아니면 다음 key를 확인하기 위해 다음 node에 lock을 건다.
그럼 두 개의 lock을 hold한 상태가 되는데 그 때 첫 번째 node의 lock을 release한다.
정리하자면 다음 node의 lock을 잡은 뒤 현재 node의 lock을 relese하는 것이다.
그래서 hand-over-hand이다. lock crabbing이라고 하기도 한다.
내가 항상 보고 있는 애의 lock을 holding하기 때문에 concurrency가 증가한다.
다른 node의 lock은 holding하지 않지만 linked list 구조이기 때문에 다른 thread들은 내가 lock을 holding하고 있는 node를 bypass할 수 없다.
실제로는 list를 traversal할 때 각 node의 lock을 acquire하고 release하는 overhead는 prohibitive하다.
Michael and Scott Concurrent Queues
이 queue에는 두 개의 lock이 있다.
- queue의 head에 대한 lock
- queue의 tail에 대한 lock
이 두 lock의 목표는 enqueue와 dequeue operation에서 concurrency가 가능하게끔 하는 것이다.
queue에서 element가 추가되거나 제거되는 것은 head와 tail에서 뿐이고 아무도 queue의 중간은 접근할 수 없기 때문에 lock을 2개만 사용해도 된다.



enqueue를 할 때 원래 null이었던 q->tail->next가 tmp를 가리키게 하고 tail pointer가 새로운 node를 가리키게 한다.
📌 이 부분을 mutex를 제거하고 TAS(test-and-set)으로 구현할 수 있다!
TAS(&tail, tmp);를 쓰면 atomically하게 pointer(tail)이 가리키고 있던 값을 tmp로 바꿔주고, old_tail을 return한다.
그럼 그 old_tail을 tmp에 연결시켜 주면 됨!
정리하자면
// pthread_mutex_lock(&q->tailLock);
old_tail = TAS(&tail, my_node);
old_tail->next = my_node;
// pthread_mutex_unlock(&q->tailLock);이렇게 된다.
만약 세 thread가 있다고 가정해보자.
세 thread가 동시에 TAS만 실행하고 나면 tail이 가장 늦게 TAS를 실행한 node를 가리키게 된다.
그리고 각 thread는 각자 자신이 생각하는 unique한 old_tail을 가지고 있다. TAS는 atomic하게 동작하기 때문에 각각의 old_tail은 unique하다.
이것을 통해 implicit한 linked list structure가 만들어지고 두 번째 instruction을 통해 explicit으로 만들어준다.
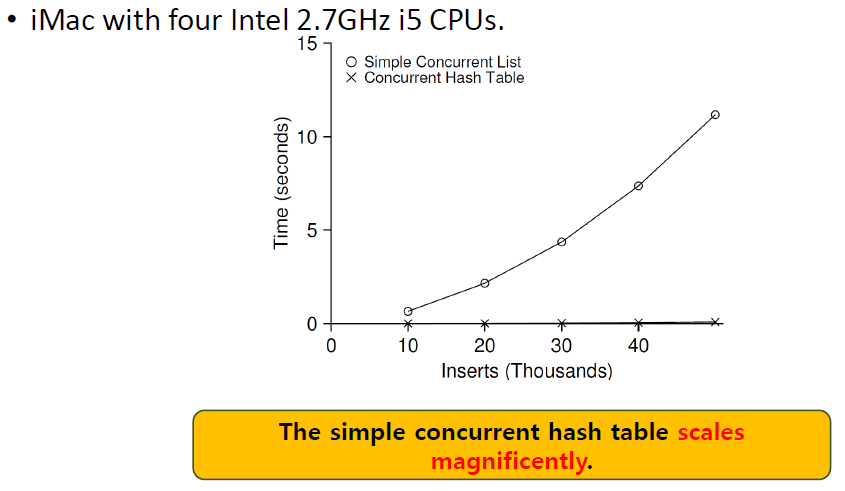
Concurrent Hash Table
Hash table은 resize할 수 없다.
Concurrent list를 사용해 build하고 list로 표현되는 각 hash bucket마다 lock을 가지고 있다.
즉, 각 bucket마다 concurrent linked list가 존재한다.
 4개의 thread가 각각 10000~50000번의 update를 할 때 성능은 다음과 같다.
4개의 thread가 각각 10000~50000번의 update를 할 때 성능은 다음과 같다.
Condition Variables
정말 많은 경우에 thread는 실행을 계속하기 전에 condition이 true인지 확인하고 싶어한다.
예를 들면, parent thread는 join()을 호출했을 때 child thread가 complete되었는지 확인하고 싶어한다.
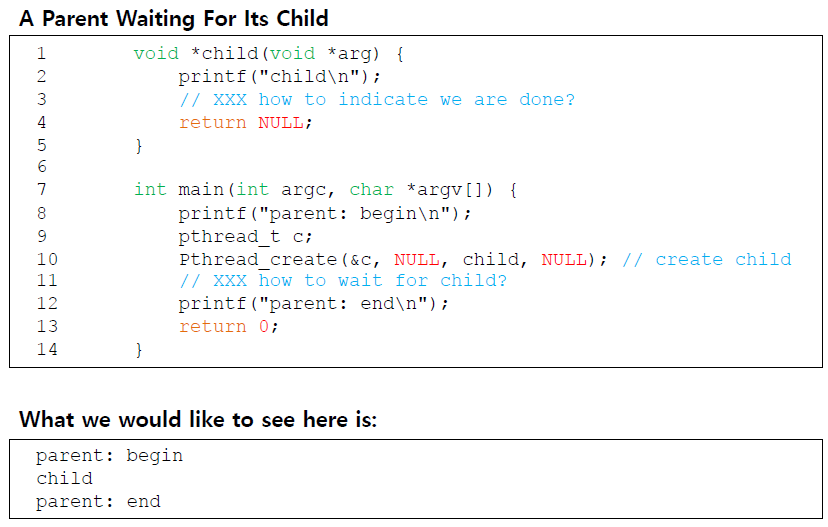 이 상황에서 parent는 어떻게 child thread를 기다리고 child는 어떻게 자신의 실행이 끝났다는 것을 parent에게 나타낼 수 있을까?
이 상황에서 parent는 어떻게 child thread를 기다리고 child는 어떻게 자신의 실행이 끝났다는 것을 parent에게 나타낼 수 있을까?
Parent Waiting For Child: Spin-Based Approach
 이 방법은 global variable인
이 방법은 global variable인 done이 flag로 쓰여서 이 값이 1이 될 때까지 parent가 spin한다.
이 방법은 parent가 spin하면서 CPU time을 낭비하기 때문에 굉장히 비효율적이다.
How to Wait for a Condition
Condition variable을 사용하면 된다!
Condition variable은
-
Waiting on the condition
calling thread를 sleep하게 만든다.
실행의 어떤 상태가 자신이 원하는 것이 아닌 경우 thread가 자기 자신을 sleep 상태로 만들 수 있는 explicit queue가 있다. -
Signaling on the condition
꿀잠자고 있던 thread를 wake up하는 것이다.
다른 thread가 state를 바꾸었을 때 꿀잠자며 기다리고 있던 thread를 깨워서 실행을 재개하도록 할 수 있다.
Definition and Routines
먼저 condition variable을 declare한다.
Pthread_cond_t c;적절한 initialization이 필요하다.
POSIX call에서의 operation은 다음과 같다.
pthread_cond_wait(pthread_cond_t *c, pthread_mutex_t *m); // wait()
pthread_cond_signal(pthread_cond_t *c); // signal()wait()은 parameter로 mutex를 필요로 한다.
wait()은 lock을 release하고 자신을 call한 thread를 sleep 상태로 바꾼다.
만약 thread가 꿀잠자다가 일어날 경우, thread는 반드시 lock을 re-acquire 해야한다.
sleep할 때 lock을 잡고 sleep 했으니까 OS가 thread를 깨우면서 다시 lock을 잡아준다.
Parent Waiting for Child: Use a Condition Variable
 여기서
여기서 c는 parent와 child가 share 하고있는 condition variable이다.
sleep할 때는 lock을 holding하고 있지 않아서 child가 critical section을 실행할 수 있고 wakeup할 때 다시 lock을 잡아준다.
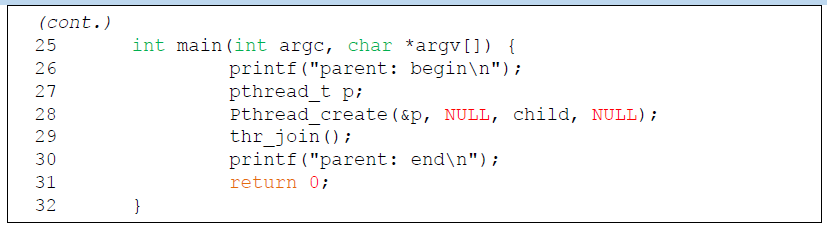
main()에서는 다음과 같은 실행 순서를 가진다.
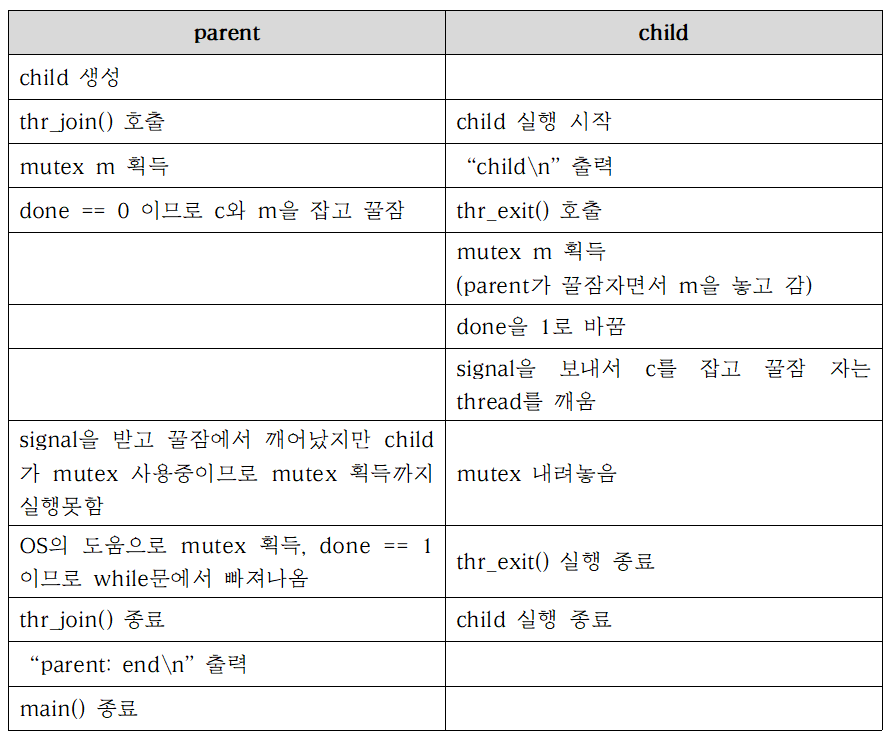
The Importance of the State Variable done
 위의 예제에서 만약
위의 예제에서 만약 done이 없었다고 생각해보자.
child가 즉시 실행돼서 thr_exit()이 먼저 mutex m을 잡으면 signal을 보내지만, condition c를 가지고 잠을 자고 있는 thread는 아무도 없다.
그 이후에 parent가 실행되면 wait()을 호출하게 된다.
하지만 parent를 깨워줄 thread가 없으므로 영원히 wake up 할 수 없다.
parent 영면...
위의 예제에서는 done이 있기 때문에 thr_exit()가 먼저 실행되면 thr_join()에서는 꿀잠을 자지 않았다.
Another Poor Implementation
 이 예제에서는 race condition이 일어날 수 있다.
이 예제에서는 race condition이 일어날 수 있다.
parent가 thr_join()을 call하면 parent는 done의 값을 확인할 것이다. 그리고 done이 0인 것을 보고 꿀잠을 자려고 할 것이다.
parent가 꿀잠을 자기 직전에 interrupt가 발생해서 child가 실행된다.
child는 state variable done의 값을 1로 바꾸고 signal을 보낼 것이다.
하지만 현재 꿀잠자고 있는 thread가 없기 때문에 아무 thread도 깨어나지 않을 것이다.
이후 다시 interrupt가 발생해 parent가 실행되고 꿀잠을 자면, parent는 영면이다.
아무도 깨워줄 수 없다.
The Producer / Consumer (Bound Buffer) Problem
-
Producer
data item을 produce한다.
data item을 buffer에 넣고 싶어한다. -
Consumer
data item을 버퍼에서 꺼내서 어떤 방식이든 consume하고 싶어한다.
multi-thread의 web server가 위의 경우에 해당한다.
producer은 work space에 HTTP request를 놓는다.
consumer은 queue에서 request를 빼내 그것들을 처리한다.
Bounded Buffer
Bounded buffer는 한 프로그램의 output을 다른 프로그램으로 pipe하고 싶을 때 사용한다.
grep foo file.txt | wc -lgrep process는 producer이다.
wc process는 consumer이다.
그들 사이에는 in-kernel bounded buffer가 있다.
bounded buffer은 shared resource이기 때문에 synchronized access가 필요하다.
The Put and Get Routines (Version 1)

count가 0일 때만 buffer에 data를 넣고 count가 1일 때만 buffer에서 data를 가져온다.
Producer / Consumer Threads (Version 1)
 ㅖroducer는 shared buffer에
ㅖroducer는 shared buffer에 loops번 integer를 넣는다.
Consumer은 shared buffer에서 data를 가져온다.
Producer / Consumer: Single CV and if Statement
하나의 condition variable cond를 사용하고 associated lock mutex를 사용한다.

Pthread_cond_wait()을 호출한다는 것은 spin waiting을 하지 않겠다는 뜻이다.

consumer가 깨어난다는 것은 data가 buffer에 있다는 뜻이다! 그런데 만약 나 말고 다른 애가 먼저 깨어나서 그 data를 사용해버린다면???
위의 코드는 single produer, single consumer일 때는 제대로 동작한다.
하지만 그 이상의 producer, consumer일 때는 제대로 동작하지 않는다.
누군가가 consumer를 깨웠을 때 그 consumer가 data를 grab할 수 있다는 보장이 없다.
꿀잠을 잘 때 mutex를 놔버렸기 때문에 깨어나자마자 mutex를 re-acquire해야 하는데 그 사이의 gap이 존재한다.
내가 꿀잠자고 일어나서 mutex를 acquire하기 전에 다른 애가 그 data를 써버릴 수 있는 것이다.
그러면 꿀잠자고 일어나서 get()을 호출했을 때 count의 값이 0이어서 에러가 난다.
이 문제는 꿀잠자고 일어난 것과 lock을 다시 획득하는 것이 atomic하지 않아서 race condition이 발생하는 것이다.
내가 lock을 잡고 잠을 잤고 일어나서 lock을 다시 잡았다고 하더라도 그것은 내가 lock을 계속 잡고 있었던 것이 아니기 때문에 내가 잠깐 놨다가 다시 lock을 잡는 순간에 다른 thread가 개입할 여지가 있다.
이 문제는 queue를 producer와 consumer가 동시에 access하지 못하도록 만들어서 해결한다.
Thread Trace: Broken Solution (Version 1)
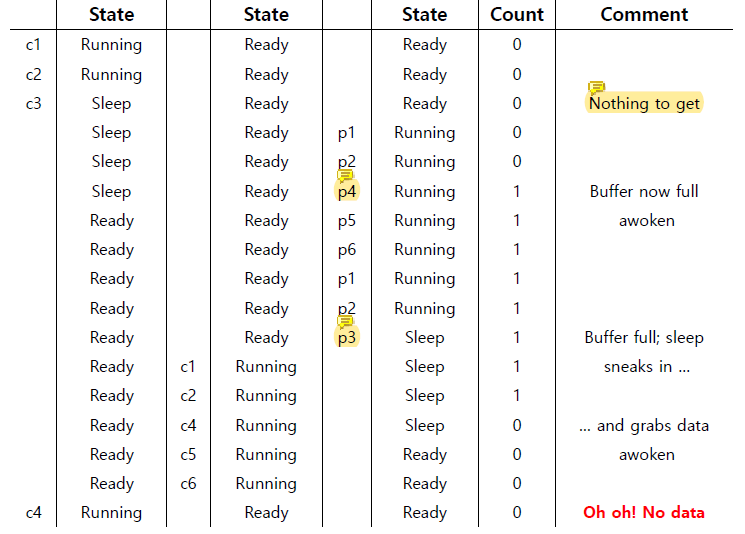
consumer1이 running하다가 count가 0이니까 get할 data가 없어서 꿀잠을 자기 시작했다.
그 이후 parent가 실행되어 queue가 비어있는 것을 확인하고 put()으로 data를 넣고 꿀잠자는 애들한테 signal을 보내서 consumer1이 깨어났다.
그리고 parent가 실행을 계속 하다가 count가 1이 된 것을 확인하고 더 data를 넣고 싶은데 queue가 꽉 차서 더 이상 넣을 수가 없으니 꿀잠을 자기 시작했다.
그러면 Ready상태에 있던 thread가 순차적으로 실행될 것이다.
먼저 consumer2가 실행되면서 buffer에 있는 data를 get()으로 가져갔다. 그리고 signal을 줘서 parent가 깨어났다.
그런데 이 다음에 운나쁘게 parent가 아닌 consumer1이 실행되면 queue가 비어있는 상태에서 깨어났기 때문에 get()을 할 data가 없다 (error)!
문제는 간단한 이유로 인해 발생했다.
consumer1이 깨어난 이후 consumer1이 실행되기 전에 bounded buffer의 state가 consumer2에 의해 바뀌었기 때문이다.
깨어난 thread가 실행이 될 때 bounded buffer의 상태가 desired라는 보장이 없다. 이를 Mesa semantics 라고 한다.
내가 일어났는데 내가 일어나도 되는 상태가 아닌 것이다. lock을 항상 들고 있었던 것이 아니라 잠들 때 lock을 잠깐 놨었기 때문에 발생한다.
Hoare semantics는 thread가 깨어났으면 즉시 실행해도 괜찮다는 더 확실한 보장을 해준다.
야 너 일어났어? 그럼 네가 이거 가져가면 돼! 할 수 있도록 잠을 자도 lock을 끝까지 hold하는 것이다.
내가 내내 lock을 hold하고 있었기 때문에 일어나면 걱정 없이 직진할 수 있다.
Producer / Consumer: Single CV and While

consumer1이 깨어나고도 shared variable의 상태를 다시 확인하는 것이다.
잠에서 깨어났는데 buffer가 비어있다면, 다시 자러가면 그만이다.

Condition variable에 대해 기억해야 할 간단한 rule은, 항상 while loop을 사용한다는 것이다!
하지만 이 code 또한 아직도 문제가 있다.
Thread Trace: Broken Solution (Version 2)
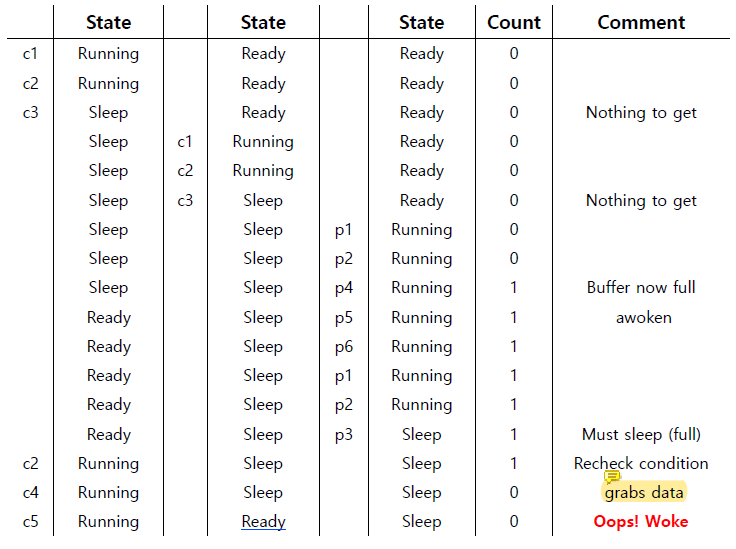
consumer1이 while loop을 실행하며 조건을 한 번 더 확인한 이후 get()으로 data를 가져갔다.
condition variable을 통해 꿀잠을 잘 때는, queue에 들어가는 것이기 때문에 잠이 든 순서대로 wake하게 된다.
현재 queue에는 consumer2 -> producer 순으로 잠들어있다.
consumer1이 data를 grab하고 난 뒤, parent를 깨우려고 signal을 보냈다. 그런데 queue에 들어간 순서 때문에 consumer2가 일어나는 불상사가 발생했다.
그래서 consumer2는 일어났는데 grab할 data가 없으니 나중에 자기 순서가 오면 다시 잠들어버릴 것이다.
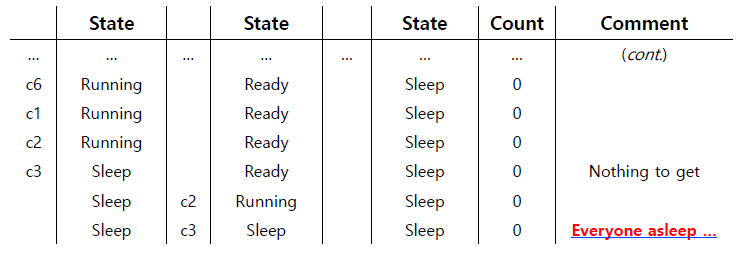
consumer1이 실행을 계속하다가 count가 0이 되었으므로 꿀잠을 자기 시작한다.
consumer1이 잠들었으므로 유일하게 Ready상태였던 consumer2가 일어났는데, queue가 비어있으므로 다시 잠들어버렸다.
그러면 모든 producer와 consumer가 잠들었지만 아무도 깨울 수 없다.
이 문제가 발생한 원인은 producer와 consumer가 same condition variable을 share하는 것이다.
모든 애들이 같은 condition variable을 사용하니까 깨우고 싶은 상대를 제대로 깨우지 못하는 것이다.
내가 누군가를 지정해서 깨우기 위해서는 condition variable을 다르게 사용해야한다.
즉, 이 상태를 해결하기 위해서는 same condition variable을 share하지 못하도록 만들어야 한다.
The Single Buffer Producer / Consumer Solution
두 개의 condition variable과 while문을 사용하면 된다!
producer thread는 condition empty에서 wait하고, fill에 signal을 보낸다.
consumer thread는 condition fill에서 wait하고, empty에 signal을 보낸다.


