✨Concurrency (3)
운영체제

Semaphore
Semaphore은 integer value를 가진 object이다.
Semaphore에는 sem_wait()과 sem_post()의 두 가지 routine이 있다.
Semaphore는 다음과 같은 방법으로 initialize한다.
#include <semaphore.h>
sem_t s;
sem_init(&s, 0, 1); // initialize s to the value 1Semaphore s를 declare하고 이를 1로 initialize한다.
두 번째 argument 0은 semaphore가 한 process 내의 thread 사이에서 share 됨을 나타낸다.
Semaphore은 sleeping mechanism을 제공한다. 만약 내가 lock같은 것을 acquire하는 것에 실패한다면 스스로를 sleep 상태로 만들어야 한다.
같은 상황이 condition variable에서도 필요하다. condition variable은 user condition과 그 user condition을 보호하는 mutex와 함께 사용된다.
critical section을 보호하기 위한 mechanism을 사용하고 싶은 모든 애들은 만약 critical section에 들어가는 것에 실패했다면 semaphore를 hold하고 있던 애들이 acquire했던 것을 release하기 전까지 sleep 해야한다.
semaphore는 condition variable의 엄청 간략화된 버전이다.
semaphore은 user condition이나 user condition을 보호하기 위한 별도의 mutex를 필요로 하지 않는다.
semaphore의 내부에는 waiting mechanism이 구현되어 있지 않다.
spin wait을 사용하지 않고 queue를 manage한다.
lock은 내부적으로 spin waiting을 하고, spin waiting을 피하고 싶으면 condition variable을 쓰고, user defined condition과 mutex가 필요 없다면 간단히 semaphore를 쓰면 된다.
Semaphore: Interact With Semaphore
 만약
만약 sem_wait()을 call 했을 때 semaphore의 value가 0이면 즉시 return한다.
sem_wait()은 이를 호출한 caller가 이후에 sem_post()를 기다리면서 실행을 미루도록 한다.
만약 semaphore의 value가 negative이면 semaphore value는 waiting하고 있는 thread의 수와 같다.
타이밍 안좋게 lost wakeup 될 수 있기 때문에 이를 해결하기 위해 영원히 sleep시키지 말고 누군가가 주기적으로 자는 애들을 깨워줘야 한다. timeout 필요...
 간단히 semaphore value의 값을 증가시킨다.
간단히 semaphore value의 값을 증가시킨다.
만약 queue에 깨워야 할 threade들이 있다면 그 중 한 thread를 깨운다.
sem_post()는 logically하게는 lock을 release해주는 건데 실제로 lock을 사용하는 것은 아니다.
integer variable을 보고 그 value를 1 증가시킨다. 만약 그 value가 positive하다면 critical section에 나 혼자 있다는 뜻이다.
원래 1로 시작해서 0이 됐던걸 다시 1로 만든 걸테니까. 다른 애가 있다면 1이 나올 수가 없다.
근데 만약 그 value가 positive하지 않다면 누군가가 queue에서 기다리고 있다는 뜻이다.
이 경우에 나는 queue에서 기다리고 있던 다른 애들을 깨워줘야 한다.
semaphore는 다음과 같은 방법으로 사용한다.
sem_wait();
// ... critical section
sem_post();Binary Semaphores (Locks)
 critical section에 한 thread만 들어갈 수 있게 하려면, initial value
critical section에 한 thread만 들어갈 수 있게 하려면, initial value x는 1이 되어야 한다.
Thread Trace: Single Thread Using a Semaphore
 한 thread만 semaphore를 이용한다면 평범하게 동작한다.
한 thread만 semaphore를 이용한다면 평범하게 동작한다.
사실 semaphore가 필요하지도 않음.
Thread Trace: Two Thread Using a Semaphore

Thread0이 critical section을 실행하는 도중 interrupt가 발생해서 critical section의 실행이 끝나지 않았는데 Thread1이 실행되었다.
Thread1에서도 sem_wait()을 호출해서 semaphore value를 1 감소시키고 semaphore value가 음수가 되었기 때문에 꿀잠을 잔다.
그 상태로 다시 Thread0으로 switch된다.
Thread0은 critical section 실행을 마치고 sem_post()를 호출하였다.
sem_post()에서는 semaphore value를 1 증가시키고 그 값이 1이 아니므로 queue에서 꿀잠자고 있는 thread가 있다는 것을 확인하고 queue의 가장 앞에서 자고 있는 Thread1을 깨운다.
그리고 sem_post()는 return되고 interrupt가 발생하면 Thread1로 switch될 것이다.
Thread1이 잠에서 깨면 return되고 critical section을 실행하게 된다.
Reader-Writer Locks
Reader-writer lock은 current thread가 read operation을 하는지 write operation을 하는지를 구분하는 lock의 종류이다.
DB를 생각해보면 data를 읽기만 하는 reader는 malicious datababase를 만들지 않기 때문에 DB의 같은 부분에 동시에 access해도 아무런 문제가 생기지 않는다.
그래서 reader와 writer를 구분할 수 있는 lock을 만든 것이다.
특정 function이 data를 읽기만 한다는 것을 보장할 수 있다면 mutex를 사용하는 대신 reader-writer lock을 사용하면 된다.
mutex는 coarse-grained로 얼마나 많은 reader가 있든 그 영역을 사용하는 모든 reader를 block 시켜야 하지만 reader-writer lock을 사용하면 reader는 reader lock만 사용하면 되고, writer lock을 사용하는 writer만 다른 모든 애들을 block 시키면 된다.
Reader-writer lock에서는 하나의 single writer만 lock을 acquire할 수 있다.
만약 한 reader가 read lock을 acquire한다면, 다른 reader들은 read lock을 공유하며 writer는 모든 reader의 실행이 끝날 때까지 기다려야 한다.

lock은 internal information인 readers를 보호하기 위한 것이다.
readers는 얼마나 많은 reader가 critical section 내에 존재하는지 나타낸다.
reader는 data를 바꾸지 않기 때문에 benign하고 동시에 critical section에 접근해도 상관없다.
writelock은 mutual exclusion을 보장하기 위해 사용되는 lock이다.
writelock을 통해 한 writer만 critical section에 들어가거나 여러 reader가 critical section에 들어갈 수 있다.
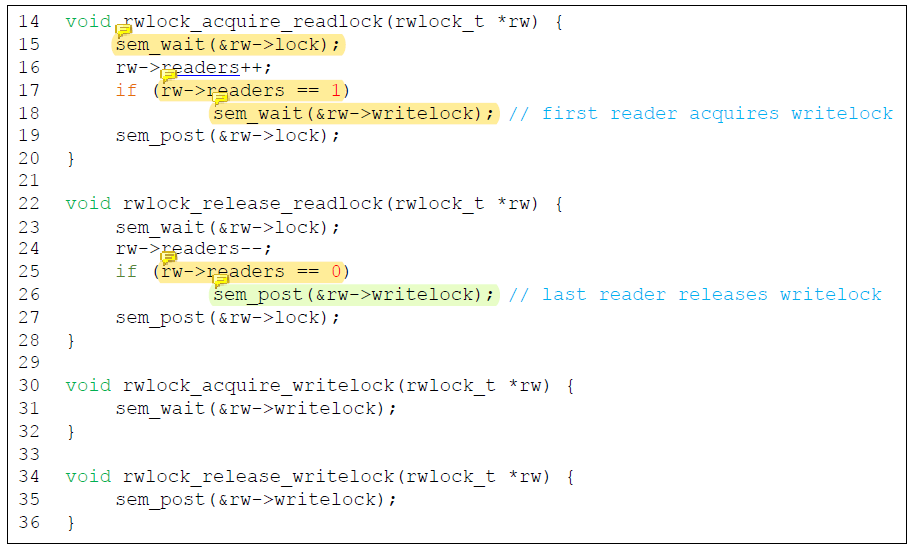
rwlock_acquire_readlock()에서는 가장 먼저 readers를 보호하는 lock에 대한 semaphore를 획득한다.
이후 readers를 증가시켰을 때 값이 1이면 현재 내가 첫 번째 reader라는 뜻이므로 sem_wait()을 통해 writelock을 획득한다.
성공적으로 read lock을 acquire한 첫 번째 reader는 다른 writer가 critical section에 있는지 없는지 확인해야한다.
writelock을 hold한 애가 있다면 writer가 critical section에 존재하므로 기다리게 된다.
readers를 보호해야 하므로 lock은 release하지 않고 hold한 채로 꿀잠을 자며 기다린다.
첫 번째 reader가 writelock을 획득하면 그 이후에 read lock을 acquire하고자 하는 다른 reader가 들어왔을 때 writelock을 획득하는 조건문을 통과한다.
첫 번째 reader(thread)가 이미 writelock을 hold하고 있기 때문에 두 번째 reader까지 writelock을 hold할 필요는 없다.
첫 번째 reader가 hold한 writelock이 모든 reader group을 writer로부터 보호해주기 때문이다.
reader는 writelock을 share한다.
rwlock_release_readlock()에서도 가장 먼저 readers를 보호하기 위해 lock을 획득한다.
획득에 성공하면 조건문을 통해 해당 reader가 마지막 reader인지 검사한다.
마지막 reader이면 writelock을 release한다.
writelock을 release해주는 것은writelock을 acquire했던 reader가 아니라 reader 중 마지막 reader이다!
Critical section에 다른 reader가 있다면 writelock을 share해서 그냥 critical section을 실행할 수 있기 때문에 mutex를 그냥 사용하는 것보다 훨씬 성능이 좋다.
하지만 reader-writer lock은 fairness problem이 있다.
Reader가 상대적으로 writer를 starve하게 만들기 쉽기 때문이다.
많은 reader가 계속해서 critical section에 들어온다면 readers variable이 계속해서 0이 되지 않으면서 모든 reader의 실행이 끝날 때까지 writer가 기다려야 한다.
영원히 writer가 기다리게 될지도 모른다.
writer가 기다리고 있을 때 다른 reader가 lock에 더 들어오는 것을 어떻게 막을 수 있을까?
Common Concurrency Problems
Non-Deadlock Bugs
Non-deadlock bug는 대부분의 concurrency bug를 만든다.
Non-deadlock bug에는 두 종류가 있다.
-
Atomicity violation
mutual exclusion을 보장하지 못하는 것이다. same code를 여러 thread가 실행하도록 그냥 내버려 둔 것. -
Order violation
Atomicity-Violation Bugs
여러 memory access에 대해 원했던 serializability가 violate된 것이다.
mutual exclusion이 violate된 것과 같은 의미이다.
MySQL에서 간단한 예제를 찾을 수 있다.
두 thread가 thd struct의 proc_info 접근하고자 한다.

Thread1에서 접근중인 proc_info를 Thread2에서 reset해버렸다.
둘 다 write를 해버린 것이다.
이 문제를 해결하기 위해서는 간단히 shared-variable을 참조하는 곳을 lock으로 둘러싸면 된다.
 실제 상황이면 mutex를 사용하는 것에 굉장히 신중해야한다.
실제 상황이면 mutex를 사용하는 것에 굉장히 신중해야한다.
mutex를 막 쓰다보면 mutex가 여러 곳에서 쓰이게 되면서 giant mutex가 되어버린다.
처음에 a 변수로 문제가 생겨서 이 부분만 해결해야지 하고 쓴 mutex를 a변수와 b변수가 동시에 접근돼서 문제가 발생했을 때 경향성에 의해 가져다쓰는 상황이 반복되면서 mutex의 protection coverage가 커지고 giant lock이 될 확률이 높다.
최대한 invariance를 확보하려고 노력하다가 정 안되면 mutex에 명확한 이름을 붙여야 한다. 그 부분만 protect하는 condition variable의 이름을.
Order-Violation Bugs
두 memory 사이에 desire된 order가 있는데 그것이 지켜지지 않은 것이다.
예를 들면, A가 항상 B보다 먼저 실행되어야 하는데 실행 도중에 그 순서가 지켜지지 않은 것이다.

Thread2는 mThread가 이미 initialize 되었고 NULL이 아니라고 가정하고 있다.
만약 Thread1보다 Thread2가 먼저 실행된다면 문제가 생긴다.
Atomicity-violation bug는 thread 중 누가 먼저 실행됐는지는 상관이 없지만 order-violation bug는 무조건 thread 간의 순서가 있다.
Order-violation의 solution은 condition을 사용하면 된다.
어떤 program을 시작할 때 variable을 initialize하려고 하는데 그 때 이런 상황이 많이 나온다.
initialize가 끝날 때까지 기다려야하는 경우이면 condition variable을 사용한다.
code에 strict ordering이 있다면 condition vriable로 이를 보장하는 것이다.
Order-violation bug를 해결하기 위해서는 condition variable을 통해 ordering을 강제한다.

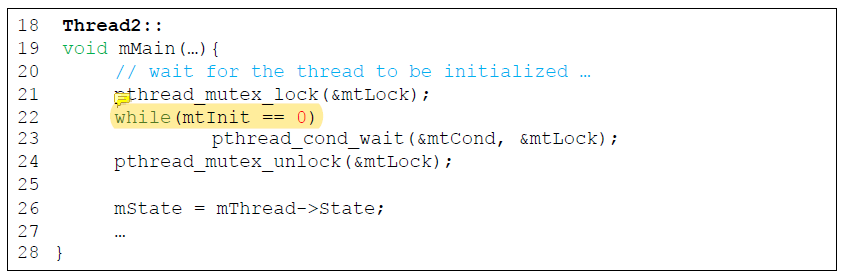 예전에 보았던 상황과 동일하게 만약 누군가가
예전에 보았던 상황과 동일하게 만약 누군가가 Thread2를 깨웠을 때 무조건 go해도 된다는 보장이 있으면 while문을 쓰지 않아도 괜찮다.
굳이 이 부분을 while을 사용하는 이유는 혹시라도 깨어났는데 다른 thread에 의해 mtInit이 1이 아닐 경우를 대비하기 위해서이다.
Order-violation bug는 order, 즉 initialize가 됐냐 안됐냐가 중요한거라 thread를 protect 하냐 안하냐와는 관계가 없다! 순서만 보장이 되면 된다.
Deadlock Bugs
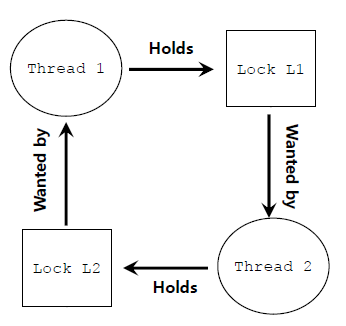
Deadlock은 아래와 같은 상황이다.
 lock의 cycle이 존재하게 된다.
lock의 cycle이 존재하게 된다.
Thread1은 lock L1을 hold하고서 L2를 기다리고, Thread2는 lock L2를 hold하고서 L1을 기다린다.
Why Do Deadlock Occur?
-
Code가 커지면 component 사이에 복잡한 dependency가 생긴다.
-
Encapsulation의 본질로 인한 것이다.
Encapsulation은 구현의 detail을 숨겨서 software가 modular way로 build되기 쉽도록 만들어준다.
그런데 이 modularity가 locking과 잘 들어맞지 않는다.
예를 들면, Java의 Vector class와 AddAll() method의 경우를 보자.
 위의 경우
위의 경우 v1과 v2에 추가된 모든 lock을 acquire 해야한다.
그리고 그 lock을 임의의 순서로 acquire한다 (v1 -> v2).
그런데 만약 다른 thread가 거의 동시에 v2.AddAll(v1)을 호출한다면 deadlock이 생길 가능성이 있다.
Conditional for Deadlock
Deadlock이 생기기 위해서는 4가지 조건이 필요하다.
다시 말하면, 이 4 조건 중 하나만 물리면 deadlock을 미연에 방지하거나 없앨 수 있다.
 Mutual exclusion이 보장되고, lock을 hold하고는 기다리고, preemption을 허용하지 않고, circular 구조가 생기는 것이다.
Mutual exclusion이 보장되고, lock을 hold하고는 기다리고, preemption을 허용하지 않고, circular 구조가 생기는 것이다.
여기서 preemption은 내가 어떤 resource를 가지고 있을 때 시스템이 그것을 강제로 뺏어서 다른 애한테 줄 수 있는 것이다. DB의 경우에는 이를 절대 허용하지 않는다.
DB에서는 만약 내가 들어갔을 때 circular 구조가 생길 것 같다면 내 transaction을 abort 시키는 것이 가장 쉬운 해결방법이다.
내가 abort 당하면 DBSM에서 roll back을 시키고 내가 들고 있던 lock을 다 풀게 만들면서 hold-and-wait를 안하고 resource preemption이 allow되고 circular wait도 만들지 않게 된다.
Prevention - Circular Wait
Lock을 acquire하는 데에 total ordering을 제공한다.
순서대로 lock에 ordering을 주니까 lock에 circular 구조가 생길 일이 없다.
하지만 이 방식은 global locking strategy의 신중한 design을 필요로 한다.
만약 system에 L1과 L2의 두 lock이 있을 때 언제나 L1을 먼저 acquire하고 그 다음 L2를 acquire하도록 강제해서 deadlock을 방지하는 것이다.
그런데 DBSM에서는 이거 안쓴다. 성능이 안나오거든..ㅎ
DBSM에서 lock ordering을 사용하는 경우는 btree를 protect하는 mutex가 있을 때 큰 것을 먼저 잡고 그 다음 것을 잡고 이런 식의 ordering은 있다.
개수가 다른 a few mutex에 대해 거꾸로 mutex를 잡아서 생기는 것을 DB에서는 dead latch라고 한다.
Deadlock은 해결이 되지만 DB의 dead latch는 해결이 되지 않기 때문에 그것을 방지하기 위해 큰 resource부터 작은 resource 단위로 mutex를 잡도록 ordering을 사용한다.
mutex는 big resource를 먼저 acquire하고 점점 작은 단위로 acquire한다.
Prevention - Hold-and-wait
모든 lock을 한번에 atomically하게 잡는다.
 이 code는 lock을 획득하고 있는 중에 시기적으로 적절하지 않은 thread switch가 일어나지 않도록 보장한다.
이 code는 lock을 획득하고 있는 중에 시기적으로 적절하지 않은 thread switch가 일어나지 않도록 보장한다.
prevection을 먼저 잡고 그 이후에 필요한 다른 것들을 다 잡는 것이다.
Lock을 잡는 것 자체를 atomic하게 만들어버린 것이다. lock hold를 atomic하게.
그런데 이 방법은 잡아야 할 lock이 많으면 많을 수록 giant mutex가 되기 때문에 추천하지 않는다.
이 방법을 매번 쓸 방에는 그냥 giant mutex를 하나 쓰고 말지..
그리고 저 많은 lock 중 한 두개만 필요한 thread도 저 전체 lock의 사용이 다 끝나고 release 될 때까지 기다려야 한다는 문제점이 있다.
이 방법은 routine을 call할 때 정확히 어떤 lock을 hold 해야할지 알고 미리 acquire해야 하는 것과 concurrency를 감소시키는 문제점이 있다.
Prevention - No Preemption
Multiple lock acquisition은 종종 다른 데에서 holding하고 있는 lock을 기다려야 하기 때문에 문제가 생긴다.
trylock()
trylock()은 deadlock-free, ordering-robust lock acquisition protocol을 만들기 위해 사용된다.
 lock을 잡을 수 있으면 잡고, 잡을 수 없다면 -1 을 return한다. -1 을 return 받으면 나중에 다시 lock을 잡는 것을 시도한다.
lock을 잡을 수 있으면 잡고, 잡을 수 없다면 -1 을 return한다. -1 을 return 받으면 나중에 다시 lock을 잡는 것을 시도한다.
trylock()은 field에서 정말 많이 사용된다.
lock을 붙잡고 있는 것이 많은 성능저하를 일으키기 때문에 lock을 try했는데 안되면 그냥 잡고 있던 lock을 전부 다 풀어버린다. 다 풀고 시작하는 것이 더 낫기 때문이다.
lock을 5개 잡아야 실행할 수 있는 thread인데 마지막 1개 lock을 못잡았다고 그 lock을 획득할 때까지 나머지 4개 lock을 hold하고 있는게 비효율적이라는 의미이다.
pthread도 trylock()으로 implement 되어있다. Compare-And-Swap을 시도하고 fail하면 lock을 놓아버린다.
원래는 lock을 획득할 때까지 compare-and-swap을 시도하는데 이제는 fail하면 누군가가 그 lock을 획득하고 있는거니까 lock을 release하고 다른 일을 한다.
이를 opportunistic locking이라고 한다. 내가 wait할 바에는 다른 일 할게!
shared data structure인 event queue가 있고 어떤 일을 하려고 try 했는데 fail하면 나 말고 다른 애들이 일감 주워가고 있구나! 그럼 난 다른거 할게! 이러고 다른 작업을 try한다.
- livelock
livelock은 trylock()과 다르게 fail하면 retry를 바로 하는게 아니라 약간의 random delay를 주고 retry를 하거나 다른 일을 한다.
Prevention - Mutual Exclusion
- Wait-free
powerful hardware instruction을 쓰는 것이다.
explicit locking을 사용하지 않고도 data structure 를 build할 수 있다.
 Atomically하게 value를 특정 양만큼 increment할 때 이 방법을 사용하면 다음과 같다:
Atomically하게 value를 특정 양만큼 increment할 때 이 방법을 사용하면 다음과 같다:
 이 방법을 사용하면 lock을 acquire하지 않고 deadlock도 발생하지 않는다.
이 방법을 사용하면 lock을 acquire하지 않고 deadlock도 발생하지 않는다.
livelock은 사용될 가능성이 남아있다.
더 복잡한 예시를 확인해보자.
 만약 이 코드가 여러 thread에 의해서 동시에 호출된다면 race condition이 발생할 것이다.
만약 이 코드가 여러 thread에 의해서 동시에 호출된다면 race condition이 발생할 것이다.
이 부분을 lock acquire과 release로 감싸서 race condition을 방지할 수 있다.
 또는 wait-free 방법을 사용해
또는 wait-free 방법을 사용해 compare-and-swap instruction을 쓸 수도 있다.

Deadlock Avoidance via Scheduling
몇 가지 상황에서 deadlock avoidance가 선호될 수 있다.
- 여러 thread들이 실행 도중에 잡을지도 모르는 lock들은 무엇인지에 대한 global knowledge가 필요하다.
- 그리고 deadlock이 발생하지 않는 것을 보장하는 방향으로 thread를 scheduling한다.
Example of Deadlock Avoidance via Scheduling
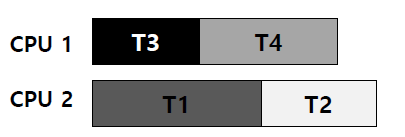
2 processor와 4 thread가 있다고 가정하자.
각 thread에게 요구되는 lock은 다음과 같다.
 Smart scheduler는
Smart scheduler는 T1과 T2가 동시에 실행되는 한, deadlock이 발생할 수 없음을 계산할 수 있다.
google에서는 프로그램이 자신이 필요한 thread의 개수나 resource 같은 것을 적어서 주면 data center의 cluster level에서 서로 다른 resource를 요구하는 program끼리 grouping을 한다. 이것이 gang scheduler이다.
비슷한 일을 하는 애들끼리 group 지어서 한번에 똑같이 돌 수 있도록 하자!
한 group에는 resource가 겹치지 않도록 하자!
하지만 운영체제에서는 이를 지원하기가 힘들다. 실행 정보를 줄 수 있는 방법도 없고 비효율적이다..
하지만 운영체제 상위 레벨에서는 이미 하고 있는 방법이다.
각 thread에게 요구되는 lock은 아래와 같다면
 Deadlock이 발생하지 않는 것이 보장된 가능한 schedule은 다음과 같다.
Deadlock이 발생하지 않는 것이 보장된 가능한 schedule은 다음과 같다.
이 경우에는 job을 완료하는 데에 걸리는 시간이 상당히 길어진다.
Detect and Recover
Deadlock이 가끔 발생하도록 허용한 뒤에 다음 조치를 취하는 방법이다.
마치 OS가 멈췄을 때 재부팅을 하는 것과 비슷하다.
많은 DBSM은 deadlock detection과 recovery technique을 가지고 있다.
- A deadlock detector runs periodically.
- Building a resource graph and checking it for cycles.
- In deadlock, the system need to be restarted.
