
Supervised vs. Unsupervised Learning
Classification
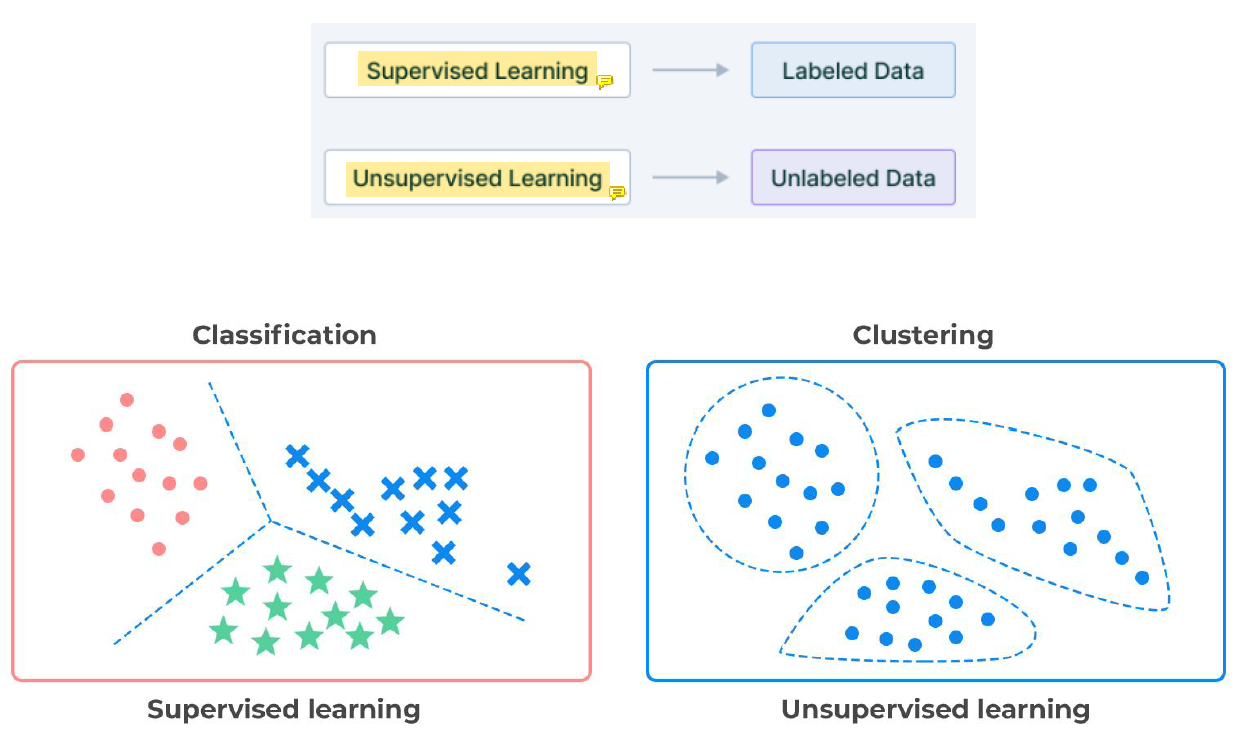
Supervised learning은 정답이 있다. 학습 dataset에 붙은 label을 따라가면 됨.
Unsupervised learning은 정답이 없고 그냥 data만 있어서 비슷한 것끼리 묶어 cluster를 만드는 것이다.

Unsupervised learning에서 data를 취득하는건 매우 쉽지만 그 data를 분석하는 것이 어렵다.
Supervised Learning
 Data set이 label을 갖고 있어서 상대적으로 쉬움.
Data set이 label을 갖고 있어서 상대적으로 쉬움.
Classification은 개다 고양이다 이런식으로 나누는 것. descrete함.
Regression은 온도와 같이 contiguous한 문제임.
현재 체온이 37도인데 classification을 하면 37를 return하면 맞고 36.9를 return하면 틀림.
하지만 regression은 36.9가 37은 아니지만 36.8보다 좋다는건 알 수 있음. 좀 continuous한 값을 찾는 과정임.
Unsupervised Learning
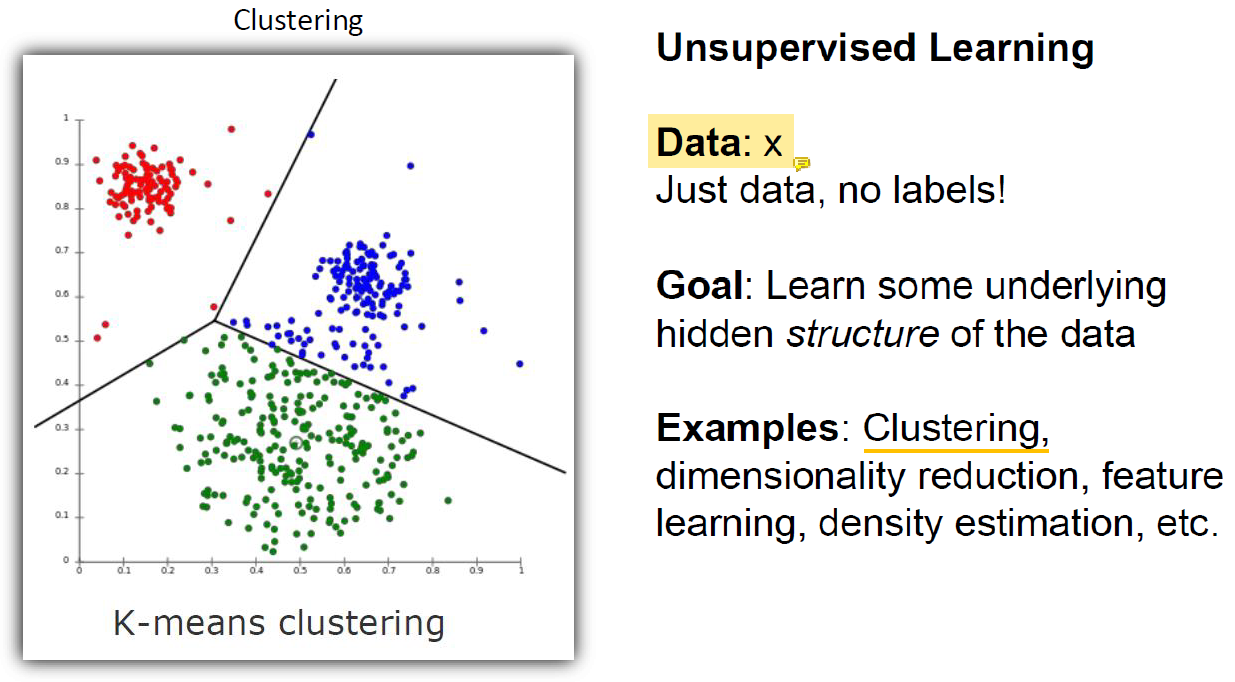
x, y의 pair가 아닌 x만 주어짐!
차원을 줄이는 문제는 unsupervised learning임.
어떤 차원을 없애야 하는지 알 수 없고 data 자체에서 기준을 세우고 찾아야 함.
Generative Models

Image를 generation하는데 학습시킬 때 아무런 label을 주지 않고 인터넷에서 다운받은 이미지만 가지고 내부적으로 네트워크가 뭔가를 배워서 real image처럼 생긴 것을 만들어냄.
Image가 100만장 있는데 사람이 하나 들어있을 확률, 두명 들어있을 확률, 50명 들어있을 확률 이런걸 다 알아내야 함.
사람이 한명 있고 옆에 고양이가 있을 확률, 옆에 고양이가 5마리 있을 확률, 개가 1마리 있을 확률 이런걸 다 알아야함...
정확하게 그 확률을 알면 이 사진을 엄청 쉽게 만들 수 있다. 하지만 그걸 모르기 때문에 어려운 문제.
Neural network가 이 확률값을 알아내는 역할을 한다. 아무런 information없이 확률분포를 알아냄. Unsupervised learning으로 학습함.
왜 굳이 unsupervised로 풀려고 할까? 여기에 label을 붙이는게 너무 어렵기 때문임.
사진이 100만장이라고 해봐 그 사진마다 하늘이 파란색, 검은색, 노란색... 이런걸 일일이 counting해서 그 모든 경우의 수에 맞는 label을 맞출 수가 없음. 돈과 시간을 아무리 들여도 할 수 없는 일임.
generate된 image의 분포가 input으로 들어온 image의 분포와 최대한 비슷하도록 만들어야 함.
Dataset이 많을 수록 learning이 잘 되는데 dataset을 구하는 데에 한계가 있으니까 machine을 통해 dataset을 generation하려고 하는 것임.
몇 백장으로 generative model을 만들어서 몇 만장 몇 십만장 dataset을 만드는거지.
Learning a Generative Model

100만장의 image를 만들어내고 걔네들의 distribution이 있다고 하면 (찾을 수는 없겠지만) 그 distribution 중 real image의 distribution과 제일 비슷한 image들을 만들어내는 parameter가 그중 가장 좋은 것임.
Parameter를 만들어낼 수 있는 여러 조합 중 실제와 가장 비슷한 distribution을 만들어내는 조합이 가장 좋다는 것.

