✨GAN (2)
딥러닝

Image Generation


- 샘플링하기 쉬운, distribute하기 쉬운 random noise를 뽑아냄.
- Noise한 벡터를 그림으로 바꿈. 이거 굉장히 어렵겠는데;
function으로 따지면 엄청 어려운 function이겠지. 그래서 그걸 neural network으로 구현!
Neural network로 generator를 implementation함.
이 parameter를 학습하면 됨!
그런데 sample noise가 하나만 있으면 학습이 안됨. label이 없기 때문임.. 뭐가 어디에 있을 확률을 다 알아야 image를 만드는데..Neural network는 unsupervised 방식으로 학습이 되어야 하기 때문에..
이걸 학습시키기 위해서 등장하는게 generative adversarial model.
Generative Adversarial Networks

Discriminator은 그림을 입력으로 받는 분류기이다.
진짜 그림인지 만들어낸 그림인지 분류하는 것임. 진짜면 1, 가짜면 0을 return하는 역할임.
Image를 실제로 generation하는 부분, generator의 training이 가능하도록 등장한게 discriminator임.
Generator은 weight parameter가 처음에는 랜덤값일거임. 그래서 걔가 만든 initial quality가 매우 안좋을거임.
그 때 discriminator는 실제 그림과 generator가 만든 그림을 구분하기가 매우 쉬움. 그래서 처음엔 discriminator가 이것들을 구별하도록 학습이 됨.
Generator에게 realistic한 image를 만들게 하고 싶은데 그렇게만 하면 학습이 안되니까 discriminator의 output이 1이 나오는 image를 나오도록 학습을 시키는거임.
Generator에서는 이 image가 좋은지 안좋은지 판단할 수 없으니 discriminator까지 와서 0 또는 1의 결과를 내는 것임.
그래서 그걸 위해 G를 upgrade하고 그래서 그 G를 구분하기 위해 D를 upgrade하고 그럼 그 D를 속이기 위해 G가 upgrade되고.. 이러면서 굉장히 realistic한 결과가 나옴.
Adversarial Learning
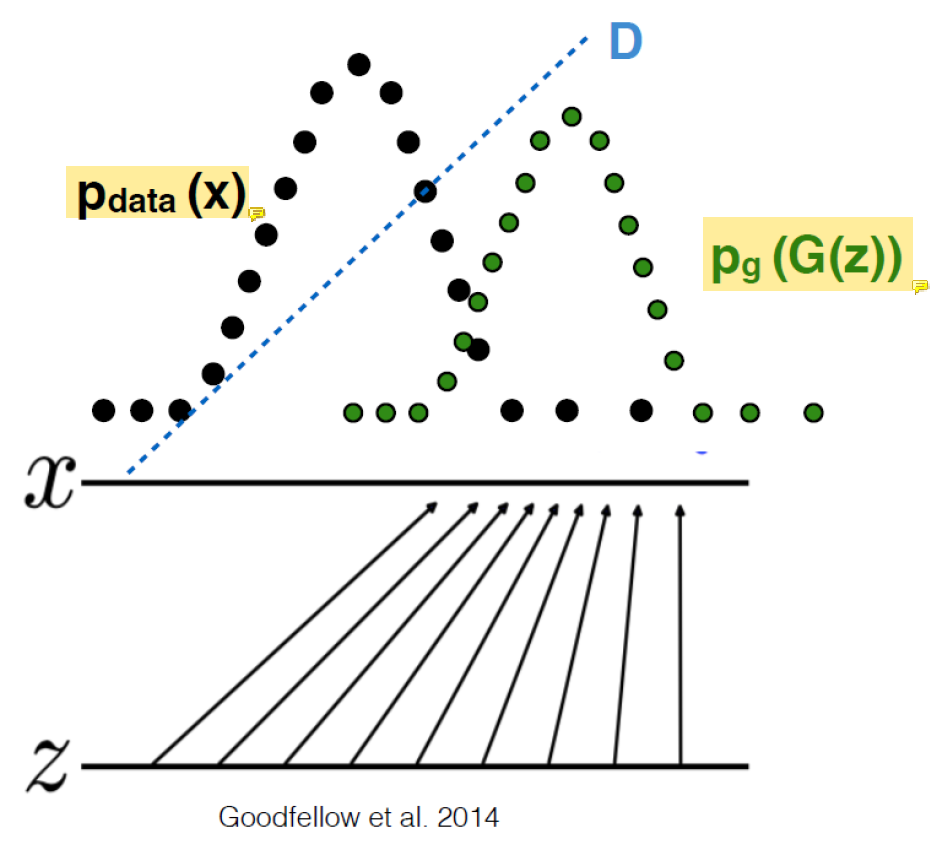
처음에 만든 image들과 실제 image들의 distribution이 완전히 다름. 실제 이미지는 왼쪽에 있는데 만들어낸건 오른쪽에 위치.
p(x)는 실제 image의 distribution이고 p(G(z))는 처음에 만든 image의 안좋은 distribution이다.
그리고 D는 이 둘을 구별해내기가 무척 쉽다.
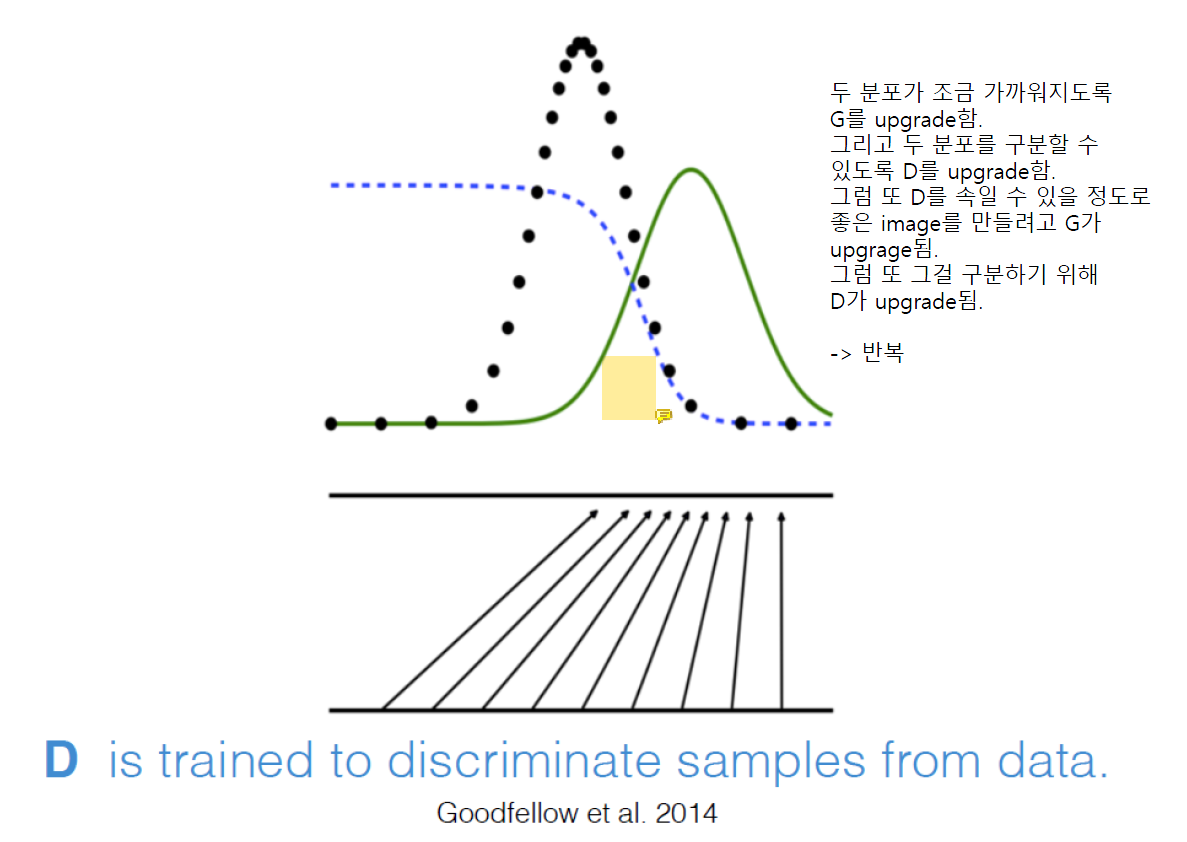
두 분포가 조금 더 비슷해지도록 G를 upgrade하면 그것을 구분하기 위해 D가 upgrade된다.
D 아래쪽에 겹치는 부분은 D가 진짜인지 가짜인지 헷갈이는 애들이다.
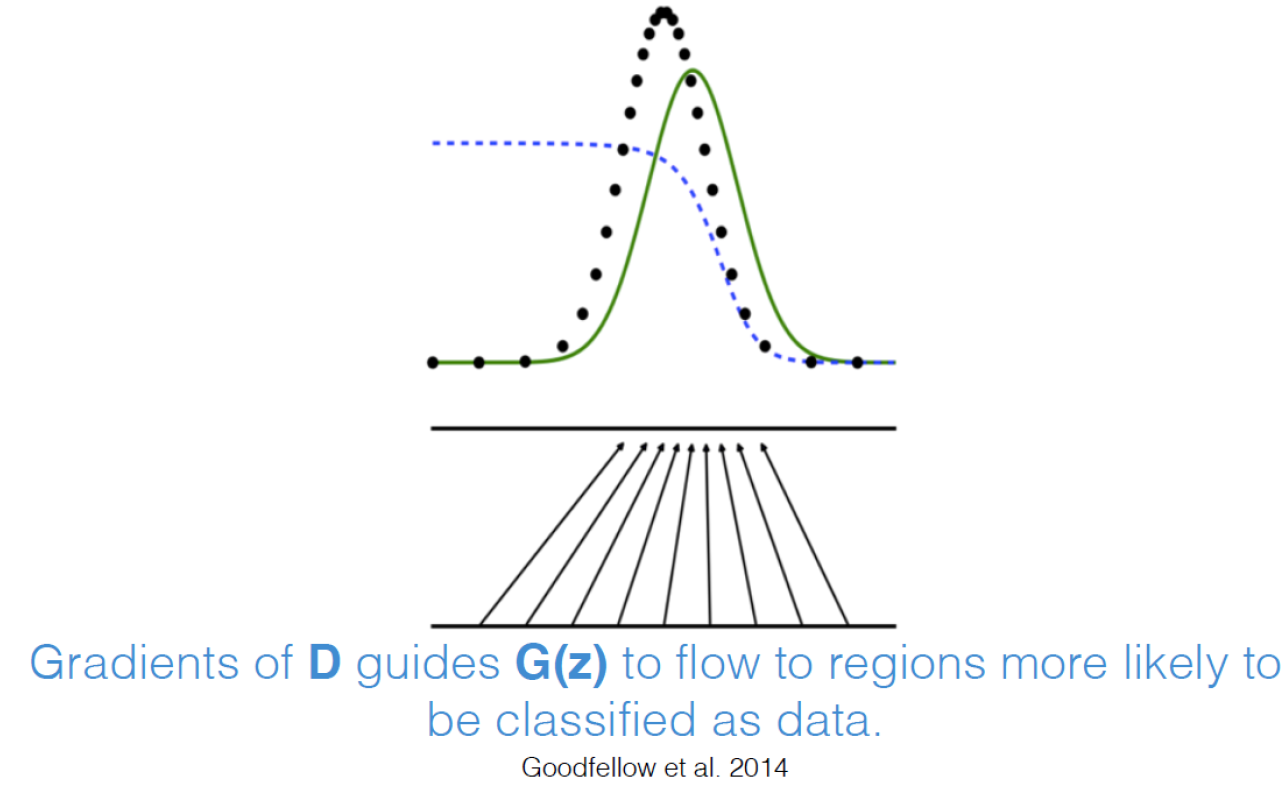
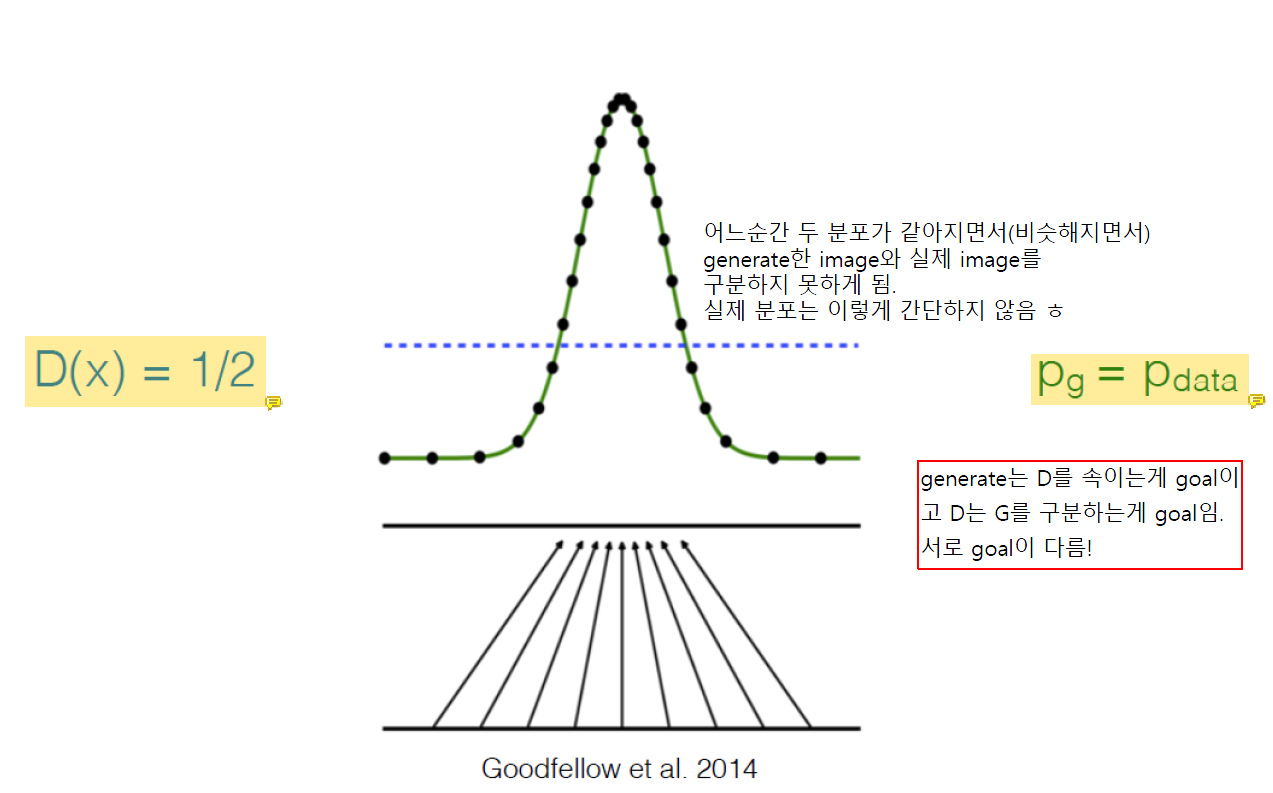
Learning의 끝까지 가면 D(x)는 1/2이 됨.
Generate한 image인지 실제 image인지 구분하지 못하기 때문에 때려맞춰서 확률이 1/2이 되는 것..
이상적인 경우임. 실제로는 이렇게 간단하지 않음.
그리고 generate한 sample들의 분포와 real image의 분포가 같아지게 됨.
Generator은 discriminator를 속이는게 goal이고 discriminator은 generator를 구분하는게 goal이다.
서로 goal이 다름!
How GAN Works
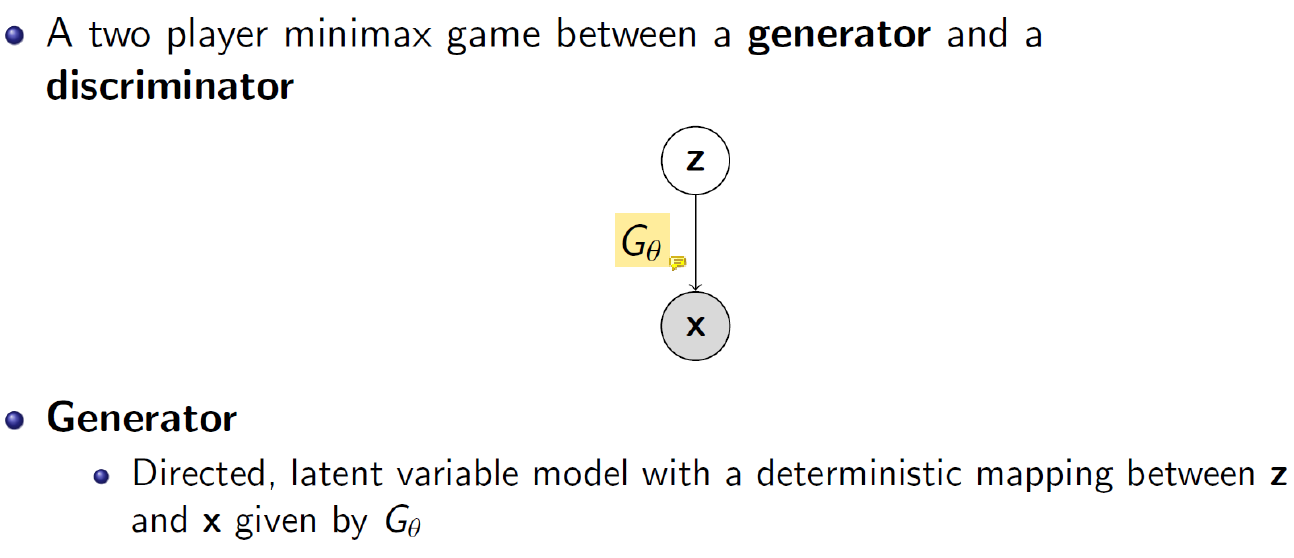
Input z를 image x로 만드는 generator function G이다.
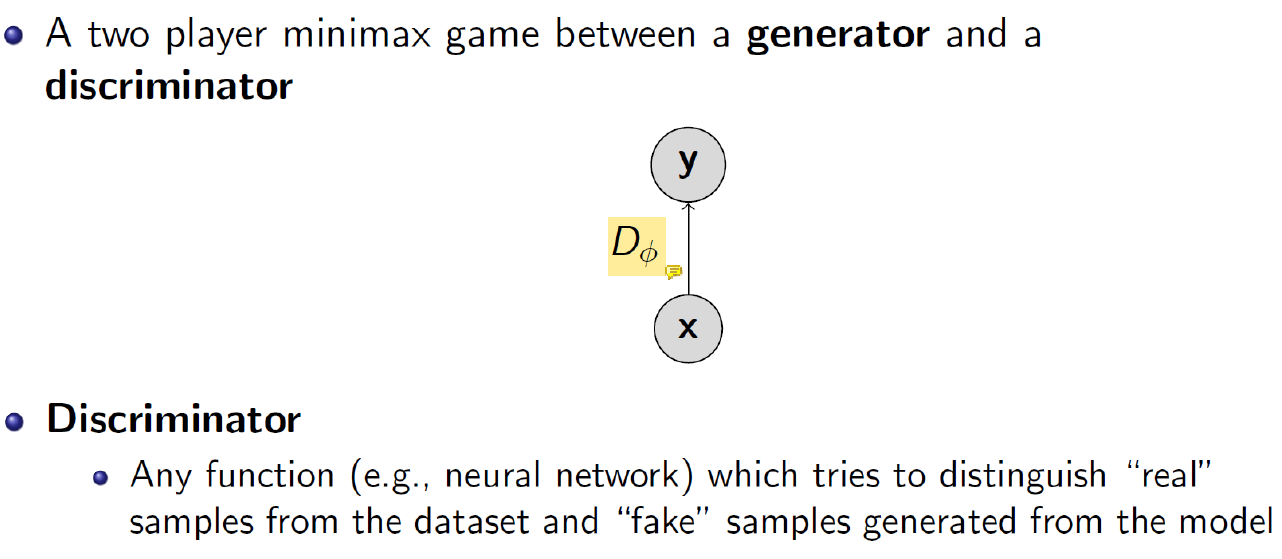
Real image와 G가 generate한 x를 구분해내는 discriminator function D이다.

Neural network를 학습하려면 loss function이 있어야하는데 label이 없음.. target이 없고 real image밖에 없음.
근데 학습을 하려면 뭔가 목적지 function이 있어야하는데 기존의 방법으로는 그걸 설계할 수 없음.
Loss function은 말 그대로 안좋은거라 loss function을 낮춰야하는데 discriminator입장에서는 그걸 키워야함! 그래서 loss function이라는 말을 안쓰고 objective function이라고 하는 것임.
맨 처음엔 G의 parameter는 상수라고 생각하고 D의 parameter를 학습함.
D의 값이 커지도록 학습(max). gradient ascent이든 gradient descent이든.
-
① : Real image에서 뽑아낸
x가 discriminator에 들어갔을 때 1이 나왔으면 좋겠다.
진짜 imagex -
② :
D(x)가 1에 가까울 수록 값이 커짐. 최대한 1에 가깝도록 만드는 것임. -
③ : 가짜 image
x -
④ : 가짜 image가 들어갔을 때
D(x)가 작을 수록 이 값이 커짐. 가짜 image가 들어갔을 때 최대한 0에 가깝게 나오도록 학습하는 것임.
고정된 generator G에 대해서 discriminator은 binary classification을 수행.
진짜가 들어오면 1, 가짜가 드러오면 0이 나오도록 학습시키는 함수.
이때부터는 D를 고정하고 학습함.
- ⑤ : Generator는 최대한 이 값을 -∞에 가깝게 만들고 싶어함. minimize 시켜서 구분을 못하게 만드려고.
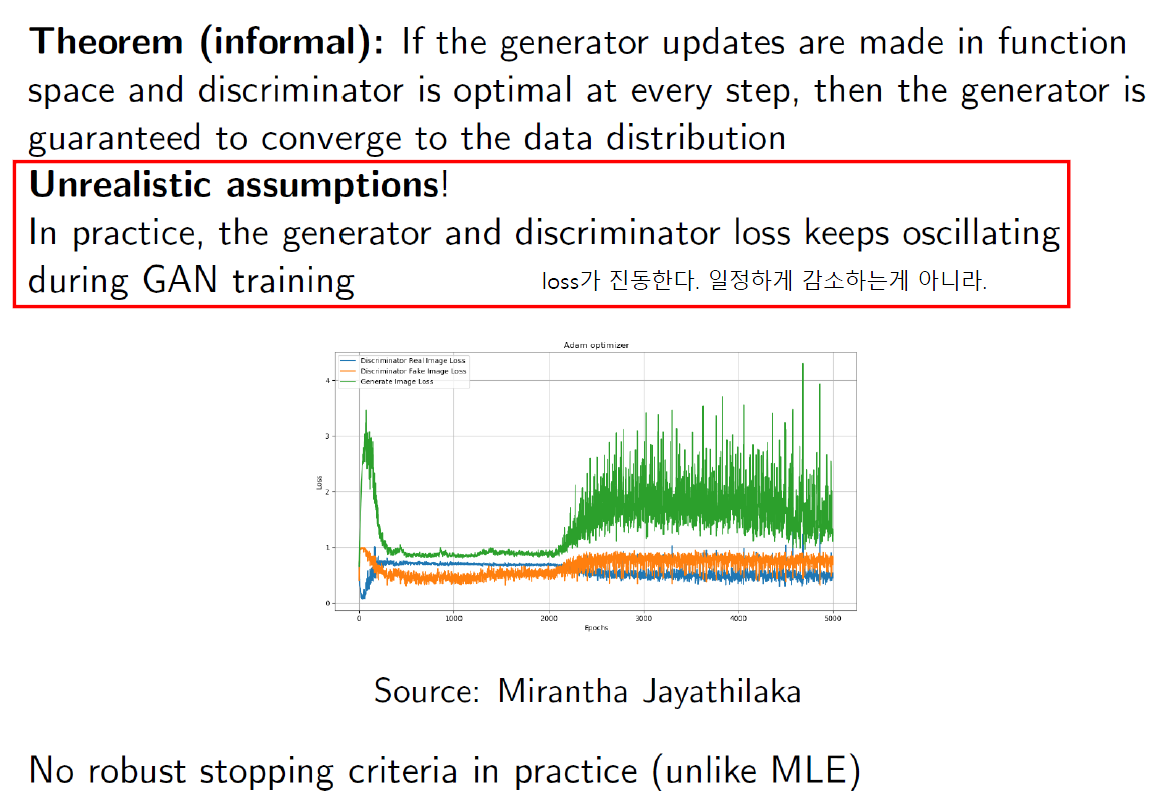
Optimization Challenges
Mode Collapse Problem

Generate해서 만든 sample이 다 비슷함.... 백만개를 만들었을 때 다 서로 달랐으면 좋겠는데 서로 비슷하다는거임.
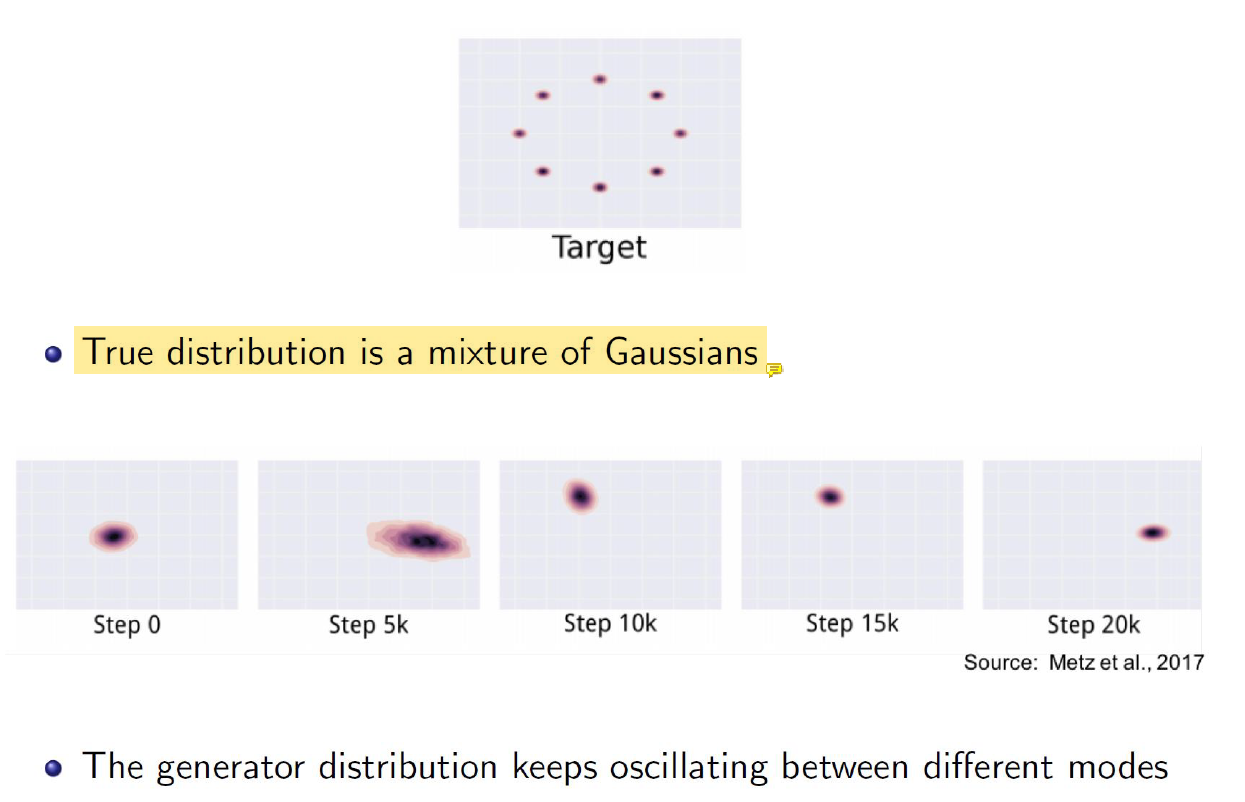
초반에 뭐 숫자같지 않은거만 만들어지다가 우연찮게 4랑 비슷해지면 그 때 objective function의 값이 확 좋아짐.
그럼 무조건 4만 만들려고 함... 학습하다가 우연찮게 하나 좋은게 만들어지면 거기에 머물러있음.
우리는 1, 2, 3, 4, 5.. 이렇게 다양하게 만들었으면 좋겠는데 하나만 만드는거임. 그렇게 해도 모델 입장에서는 값이 좋기 때문임. 이 문제는 해결이 안됐음. 시도는 많지만..
