Deep Convolutional GAN (DCGAN)
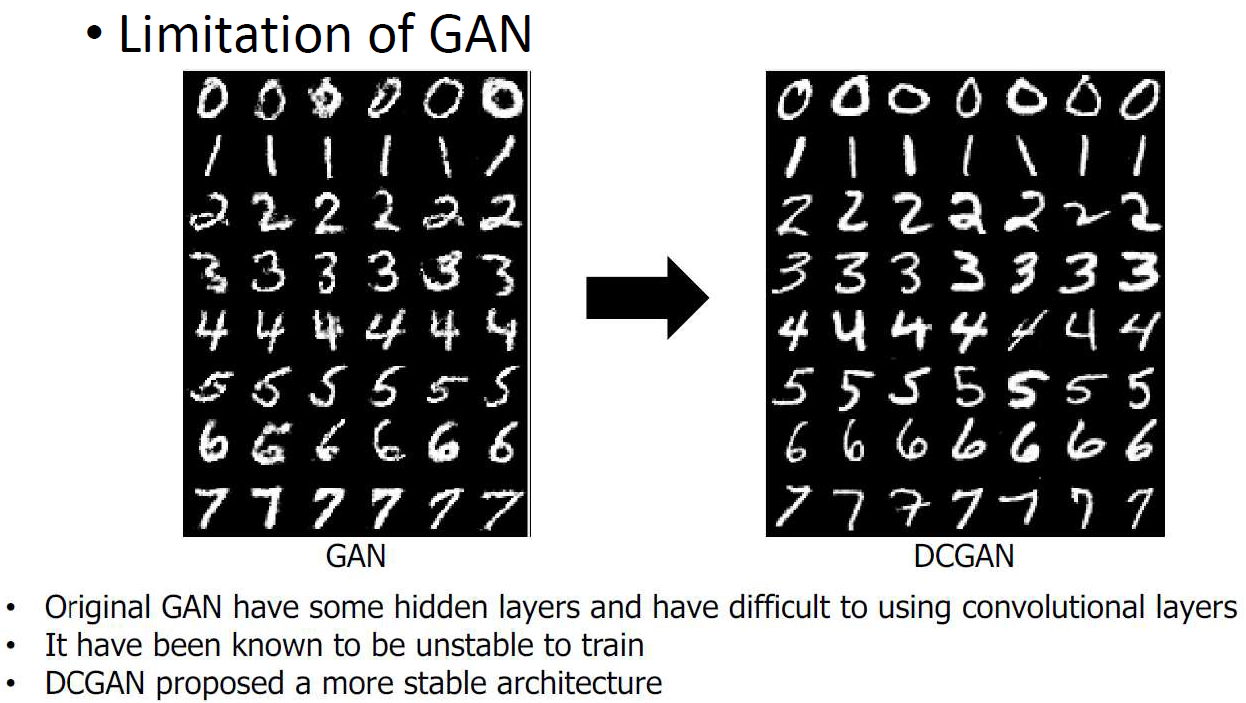
GAN의 improve된 버전. 그림을 다룰 때는 CNN이 효율적임. 그림을 만드는 데에도 convolution을 쓰면 좋지 않을까? 해서 생겨난 것

Generator는 random logic으로 점점 크기를 키워서 image를 만듦. resolution을 키워가는 것 (transposed convolution).
Stride convolution을 쓰면 resolution이 작아졌는데 여기서는 resolution이 커짐. 이런걸 transposed convolution이라고 함.
Discriminator은 strided convolution을 사용함.
generator에는 ReLU, discriminator에는 Leaky ReLU씀. 정해진건 아니지만 그게 성능이 좋다고 알려져있음.

DCGAN을 만든 결과인데 왼쪽으로부터 오른쪽까지 부드럽게 변함.
z1과 z2가 interpolation된 결과인데 0.1z1 + 0.9z2 이런거임..
굉장히 부드럽게 변하고 있는데 어떻게 이렇게 천천히 변하는 그림을 만들어냈을까..?
원래는 random noise z를 만들어서 여러 image를 생성해내는데 우연히 random noise 10개를 만들어서 image만들었다고 이렇게 부드럽게 만들어지지는 않을거아냐.
noise 2개를 만들어서 z1, z2의 image를 각각 구하고 각 noise를 섞어서 image를 만드는거임. 그럼 엄청 smooth하게 변해감.
z가 0.1일 때 할머니가 나오는데 z가 0.1000000001일 때 갓난아기가 나오지는 않을거아냐. 그래서 z를 조금 조정해서 결과값을 만드는거임.
입력이 조금 바뀌면 결과도 조금밖에 바뀌지 않음.

Image를 엄청 많이 만들어놓고 비슷한 것 2개를 골랐다고 하면 z1과 z2를 골라냈을 때.. 이 result를 interpolation하면, image 자체를 interpolation하기보다 z space에서 interpolation하면 점점 변하는 결과를 만들 수 있다.
180도 정면이랑 90도 측면을 보고 있는걸 가져다가 image space에서 interpolation하면 결과를 만들 수 없지만 z space에서 interpolation하면 그 사이의 결과를 얻어낼 수 있다.

image를 10000장을 만들어서 그 중 웃고있는 여자를 다 골라서 각각의 z의 평균을 구함.
그리고 그냥 여자 사진을 다 골라서 각각의 image를 만든 noise z의 평균을 구함.
그리고 남자 사진을 다 골라서 z의 평균을 구함.
웃는 여자의 평균 z에서 여자 z를 빼고 남자 z를 더하면 웃는 남자 사진을 만들 수 있다는 것임!
Conditional GAN
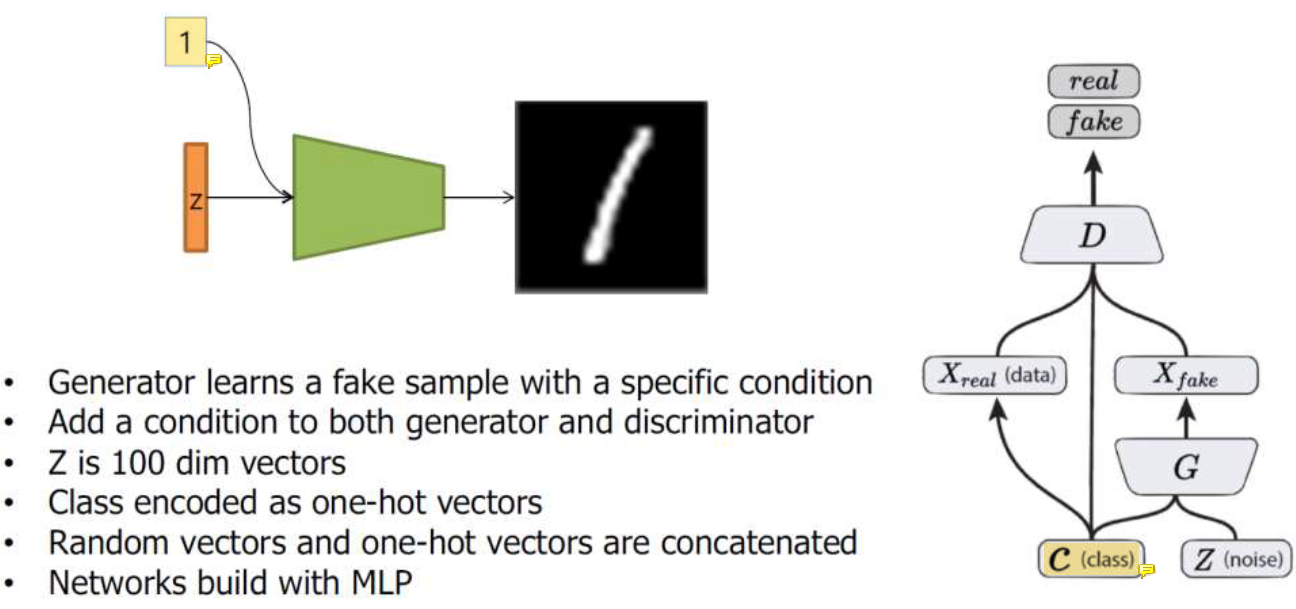
그림만 넣는게 아니라 추가정보를 넣어주는거임. 우리가 원하는 그림의 label일 수도 있고 뭐든..
할 수 있는게 더 많아짐. 이 정보를 generator에만 주는게 아니라 discriminator에도 주기 때문에 할 수 있는게 더 많음.
5를 input으로 주고 G로 만든 결과를 5를 같이 보면서 D가 비교를 하는거임.
G가 5를 보면서 그림을 만들었고 D도 5을 보면서 결과를 비교하는 그런 느낌임..
맨날 7만 만들던 애한테 다른 숫자를 만들 수 있게 만들어주는 장점이 있음. 하지만 1이 들어왔을 때 다양한 1 image가 만들어져야하는데 계속 비슷한 1만 만들어질 수 있다는 단점이 있긴 함.

Condition이라는 additional 정보가 들어감. D에는 input만 들어가지 않게 되고 G에도 random noise만 들어가지 않게 됨.
Pix2Pix Image to Image Translation
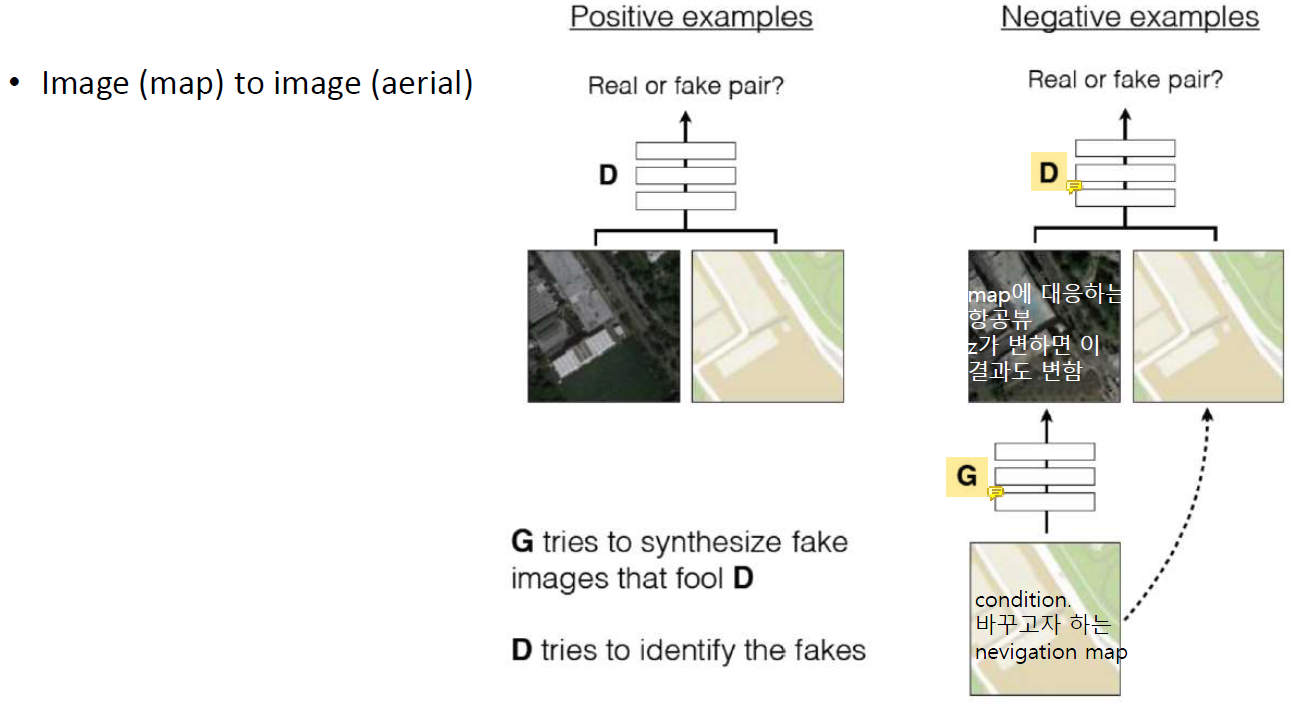
G에는 random z가 있고 바꾸고자 하는 nevigation map을 condition으로 G와 D에게 모두 준다.
D는 condition과 비교해서 G의 결과를 평가한다.
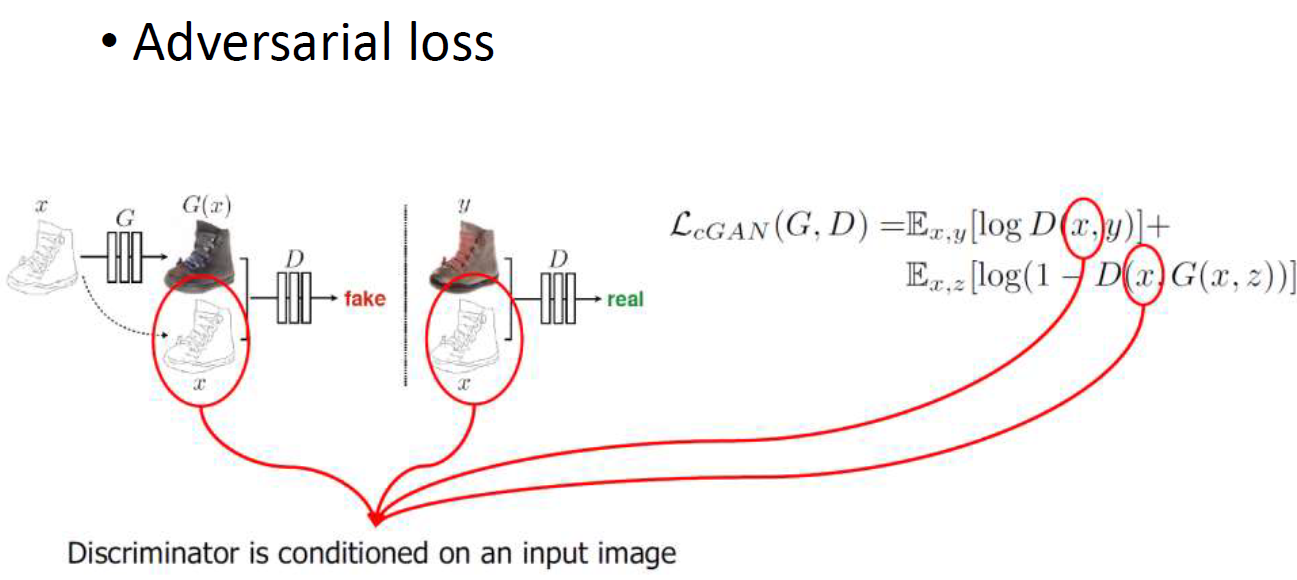
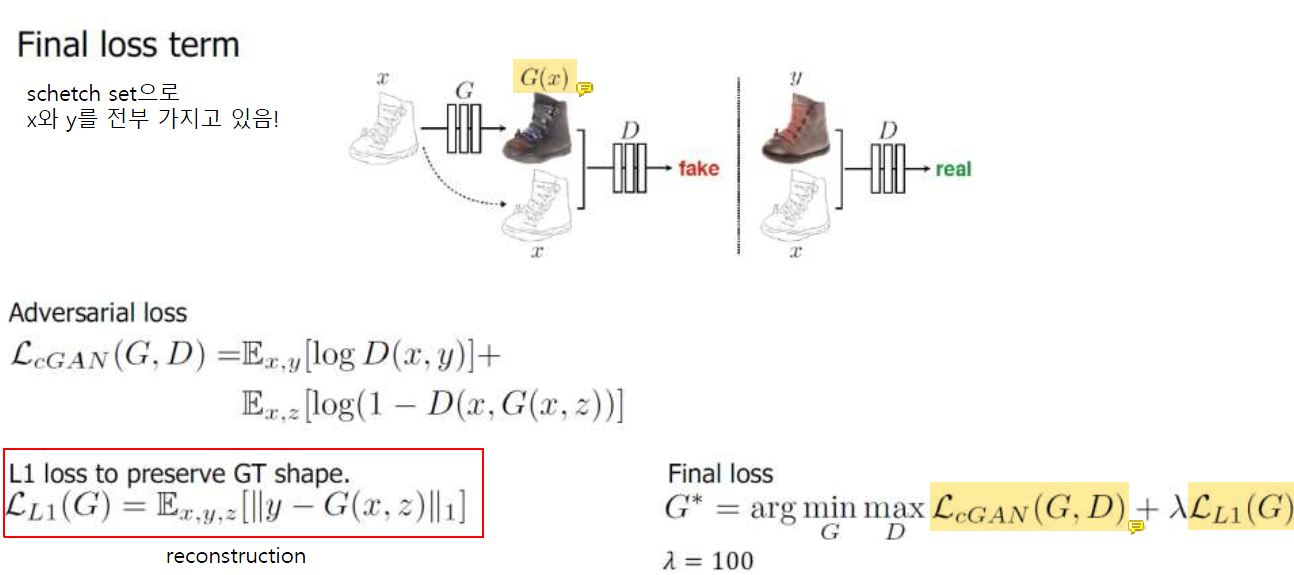
D는 G의 output으로 나온 G(x)와 실제 input x를 함께 가지고 이를 비교한다.
Final loss는 original GAN의 loss에 reconstruction loss를 더한 형태이다.
Pix2Pix의 문제점은 y도 있어야하기 때문에 낮->밤을 만들기 위해서는 같은 장소에서 낮에 찍은 사진과 밤에 찍은 사진이 모두 있어야 함.
Best result를 얻으려면 paired dataset이 필요하다는 점.
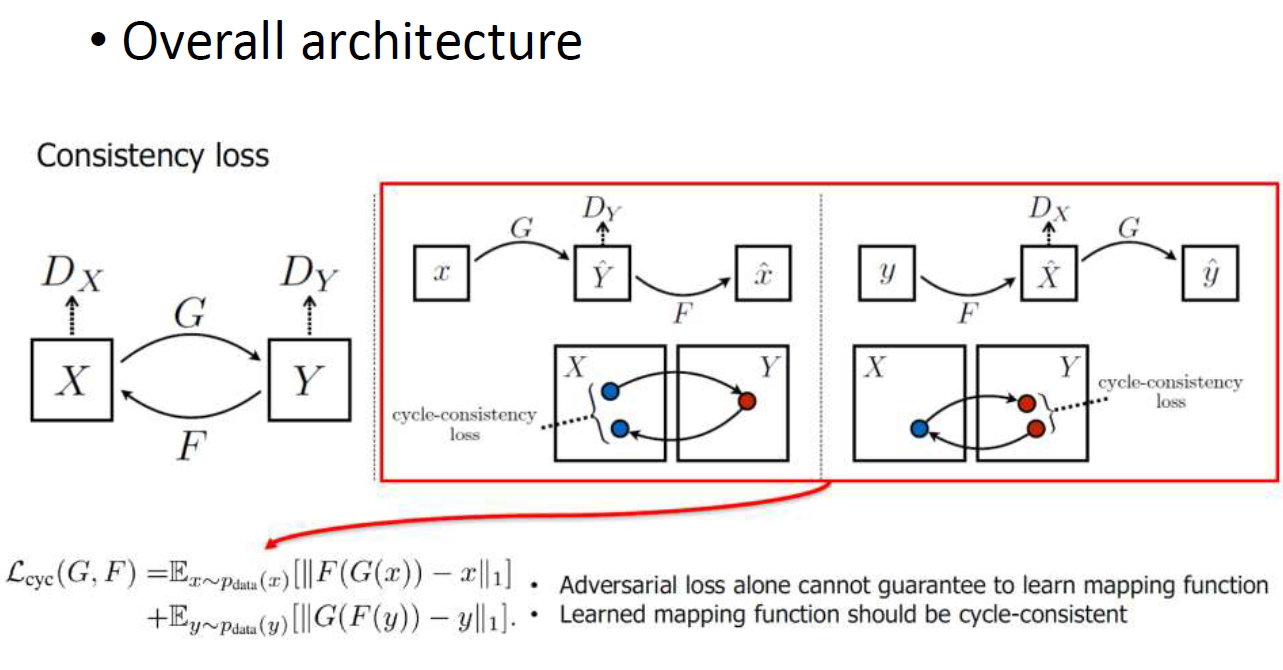
Cycle GAN

Paired training dataset을 필요로 하긴 하지만 되도록 paired 안쓰려고 함..
P2P로도 되긴 하지만 P2P로는 성능이 별로 안좋으니까. 더 좋은 퀄리티를 내놓는 아키텍처를 원함.
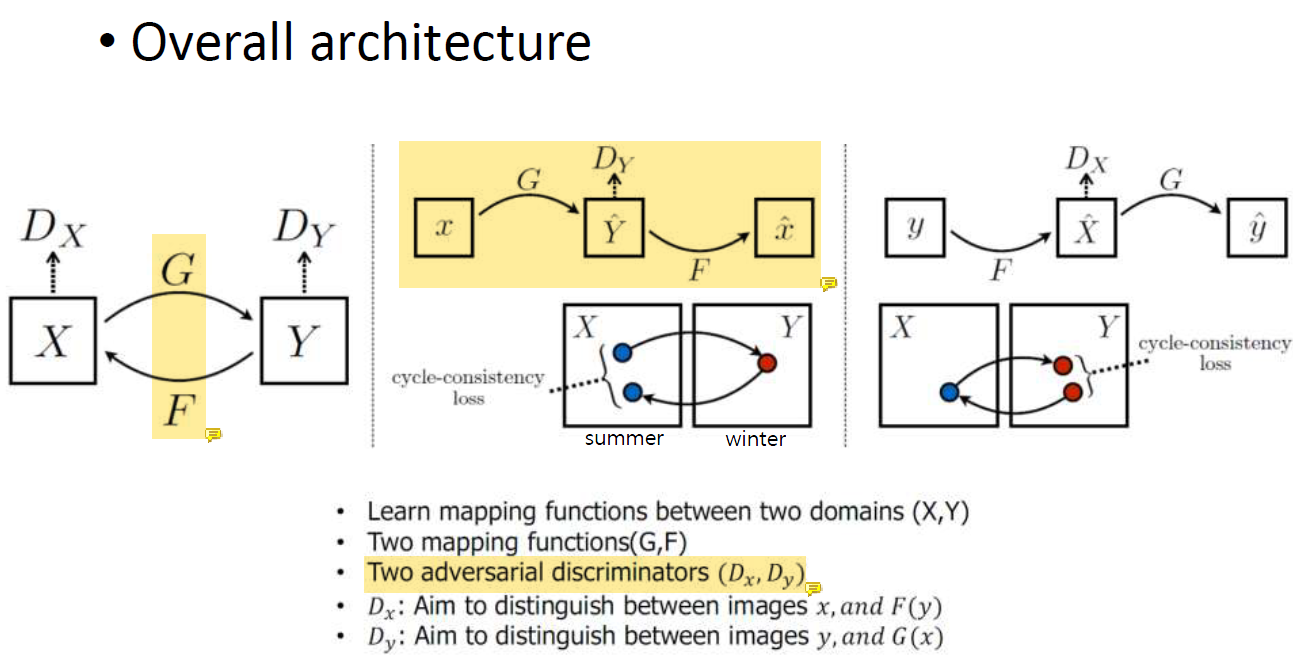
G, F의 generator 2개를 쓴다.
한번만 바꾸는게 아니라, 여름이 겨울이 됐다가 다시 여름이 됐을 때 두 여름이 비슷했으면 좋겠다.. 이렇게 된거임!
여름->겨울로 바꾸는 generator와 겨울->여름으로 바꾸는 generator가 동시에 얻어짐!! 개이득 ㅋㅋ
Discriminator도 2개가 필요하다.