
RNN
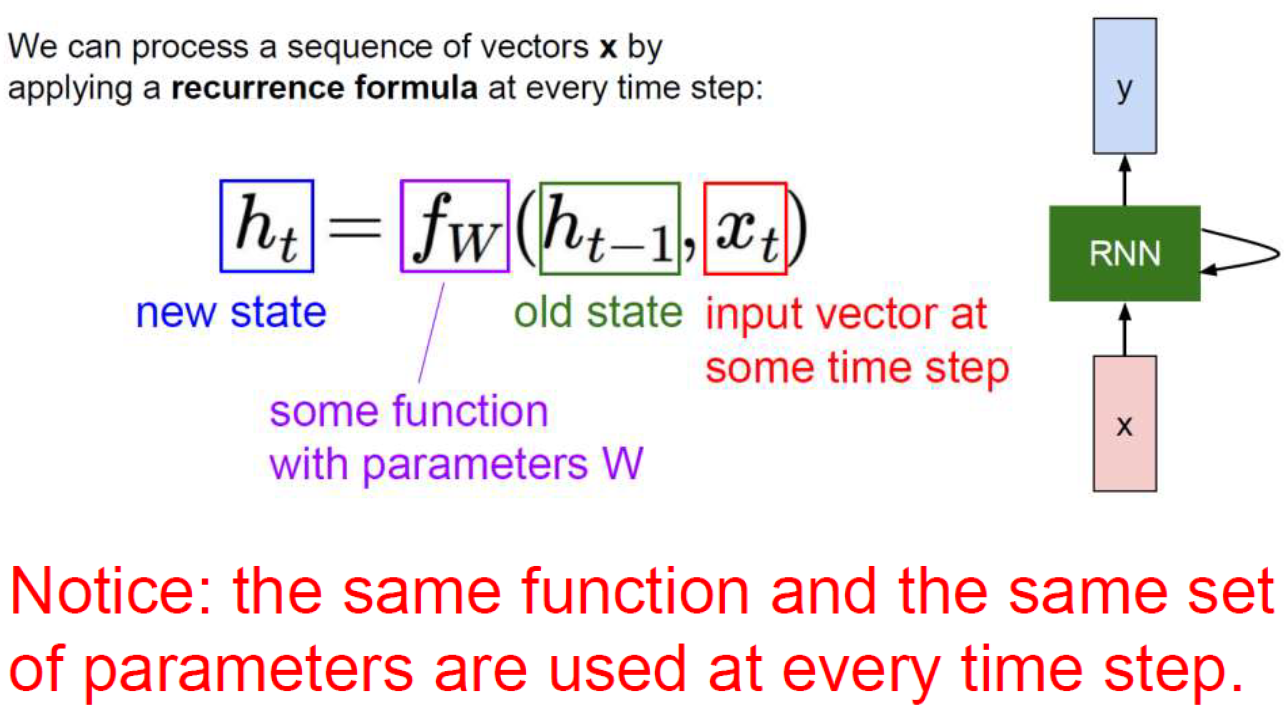
임의의 입력을 다룰 수 있는 시스템이 RNN임. 한번에 하나의 input만 받음. 단어가 7개이든 9개이든.
근데 전부 같은 weight를 사용하는데 맨 마지막 단어를 받아서 우리가 필요로 하는 output을 return할 수 있음.
첫 단어의 결과가 마지막까지 전달됨.
Feature가 계속 반복해서 똑같은 network에 들어가고 w가 share되기 때문에 recursive하게 반복되기 때문에 recurrent neural network임.
핵심은 임의의 길이의 input을 다룰 수 있고 weight가 share된다는 것.
각 단어마다 weight가 share되지 않는다면 input으로 1000개의 단어가 들어오면 weight가 1000개가 되면서 network가 너무 커짐. 하나의 system으로 길이가 100이되든 1000이 되든 다룰 수 있어야하기 때문에 weight가 share되는 것이 굉장히 중요함.
Vanilla RNN: Graphical Model
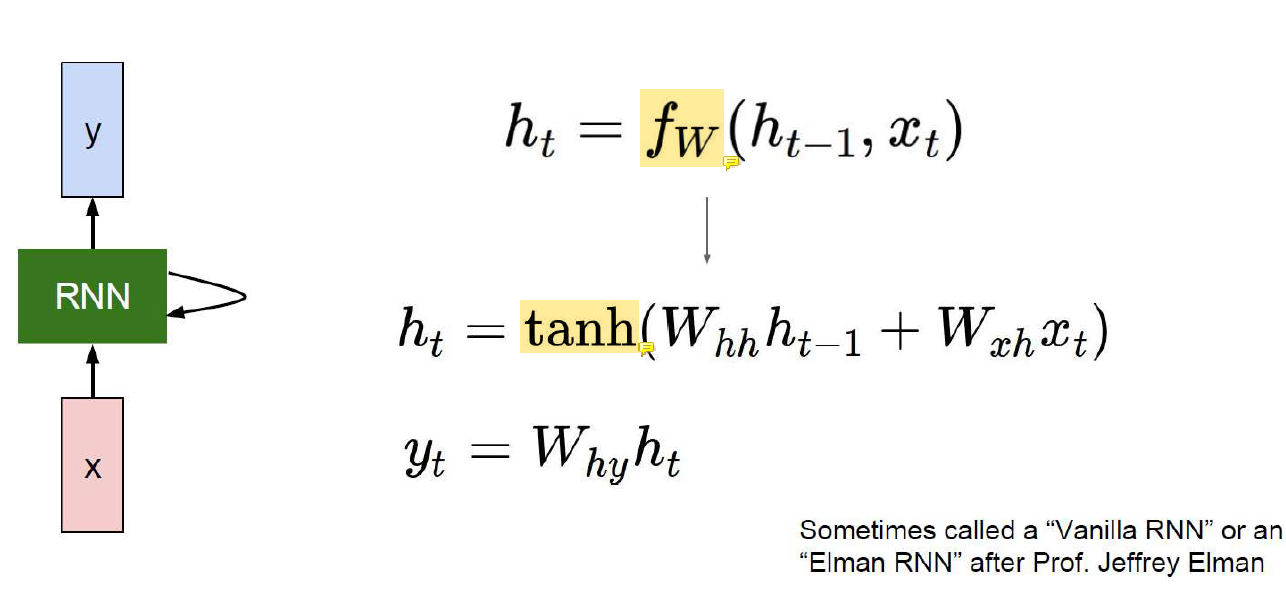
Function이 반복되는데 별건 아니고 그냥 선형변환 비선형변환이 반복된다.
입력 각각을 선형변환하고 그 선형변환 결과를 nonlinear activation function에 넣음.
Activation은 다른걸 써도 되는데 original RNN에서는 activation으로 tanh를 사용한다.
RNN: Computational Graph
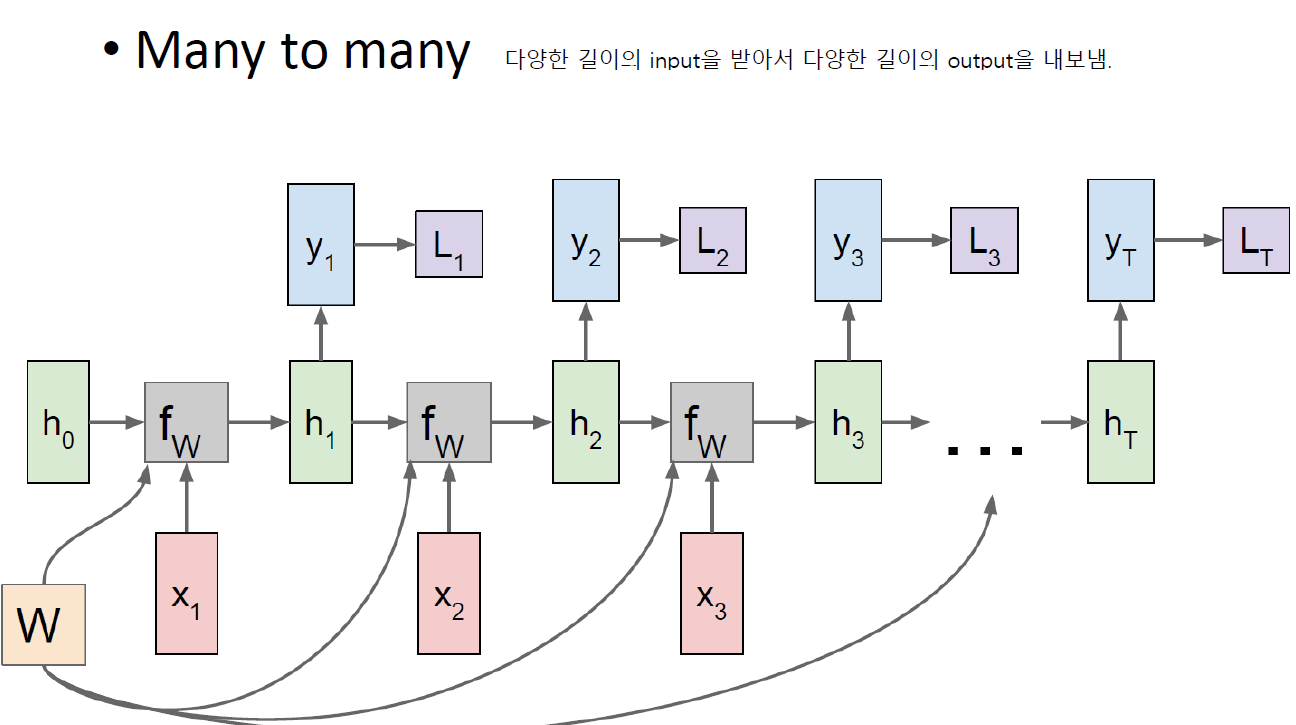
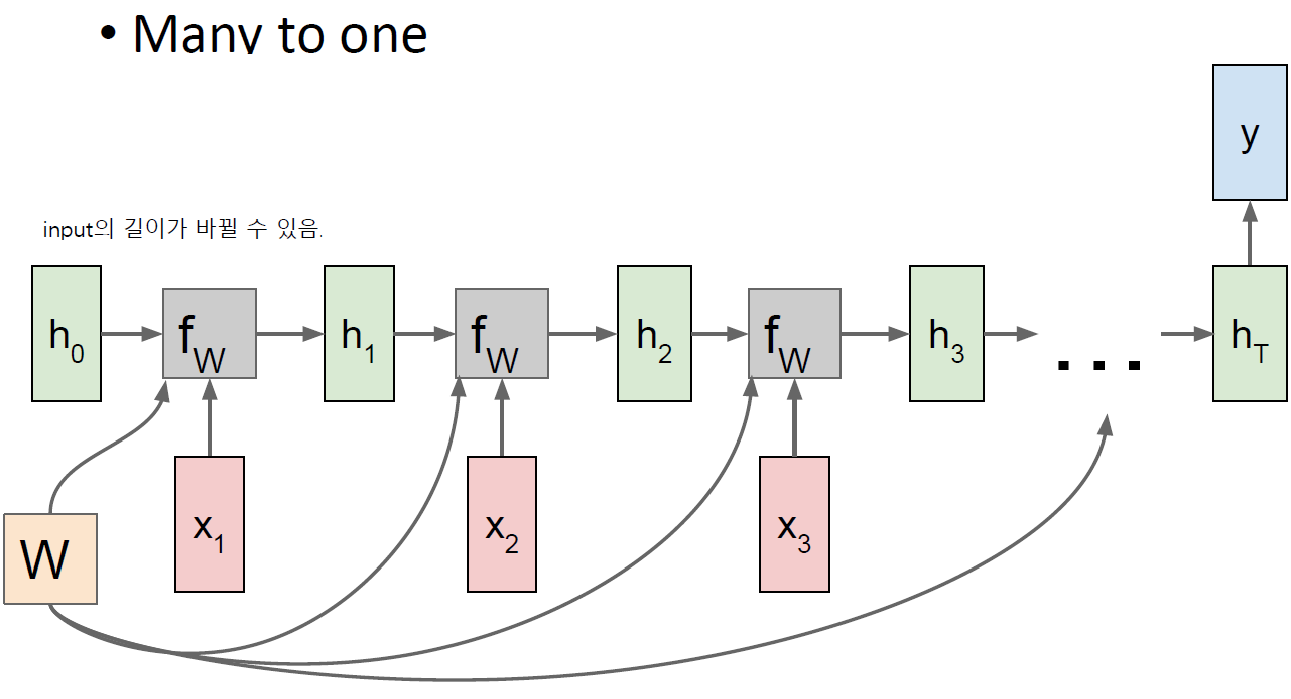
Image Captioning With RNN
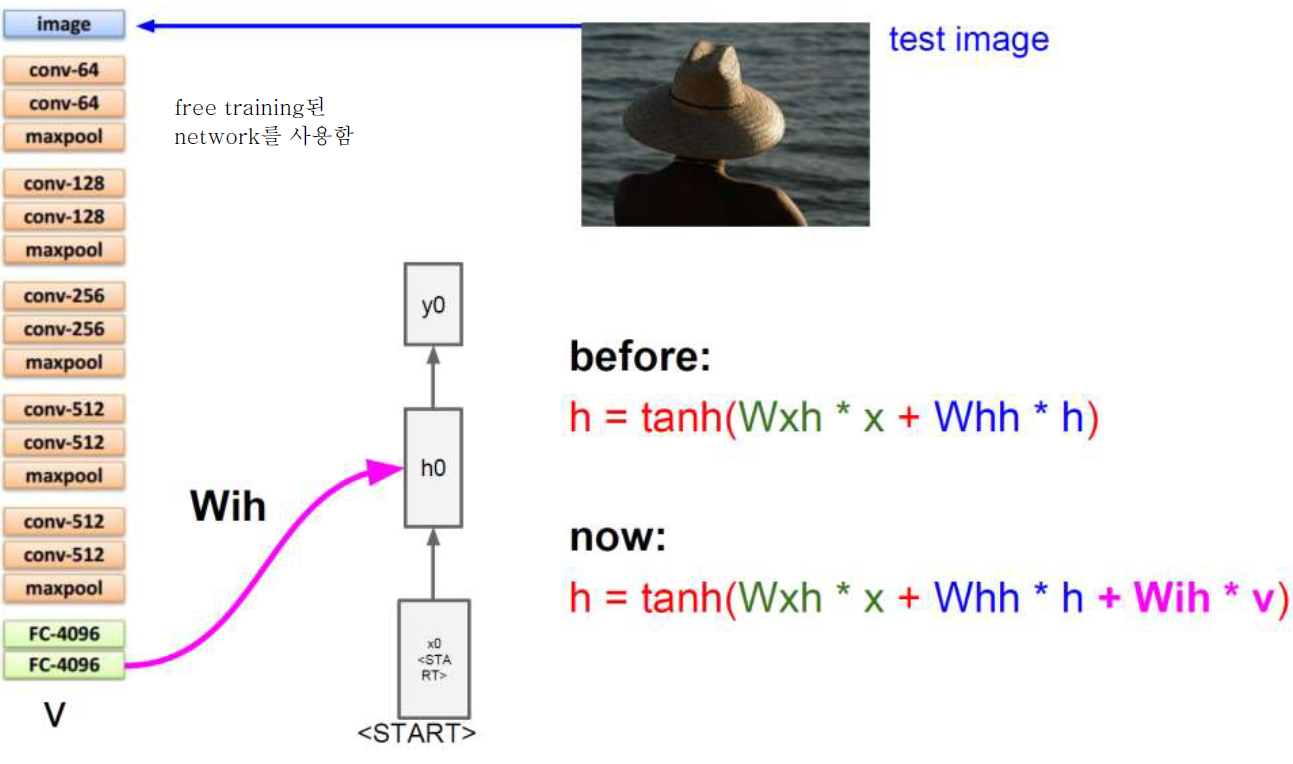
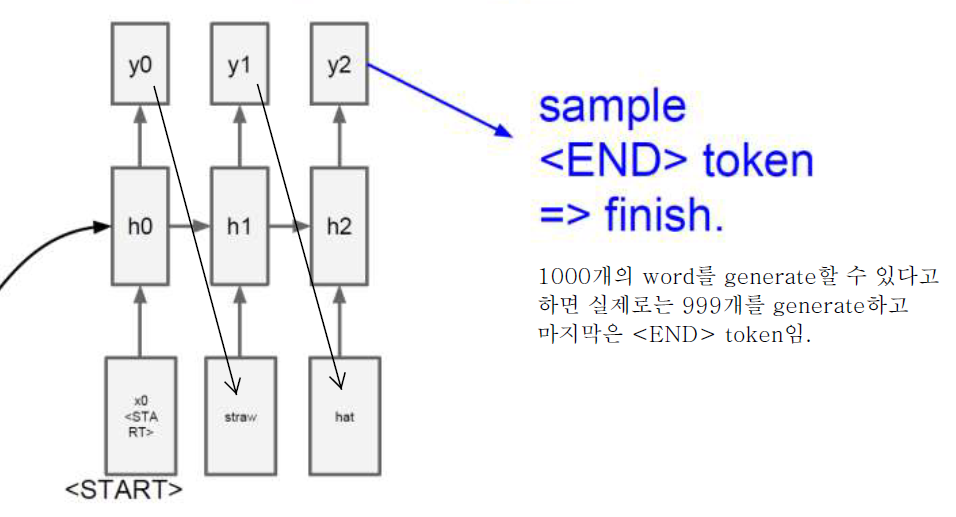
RNN으로 image를 generate할 수는 없지만 captioning 문제는 풀 수 있고 결과도 좋은 편이다!
Problem of RNN
Backpropagation Through Time (BPTT)
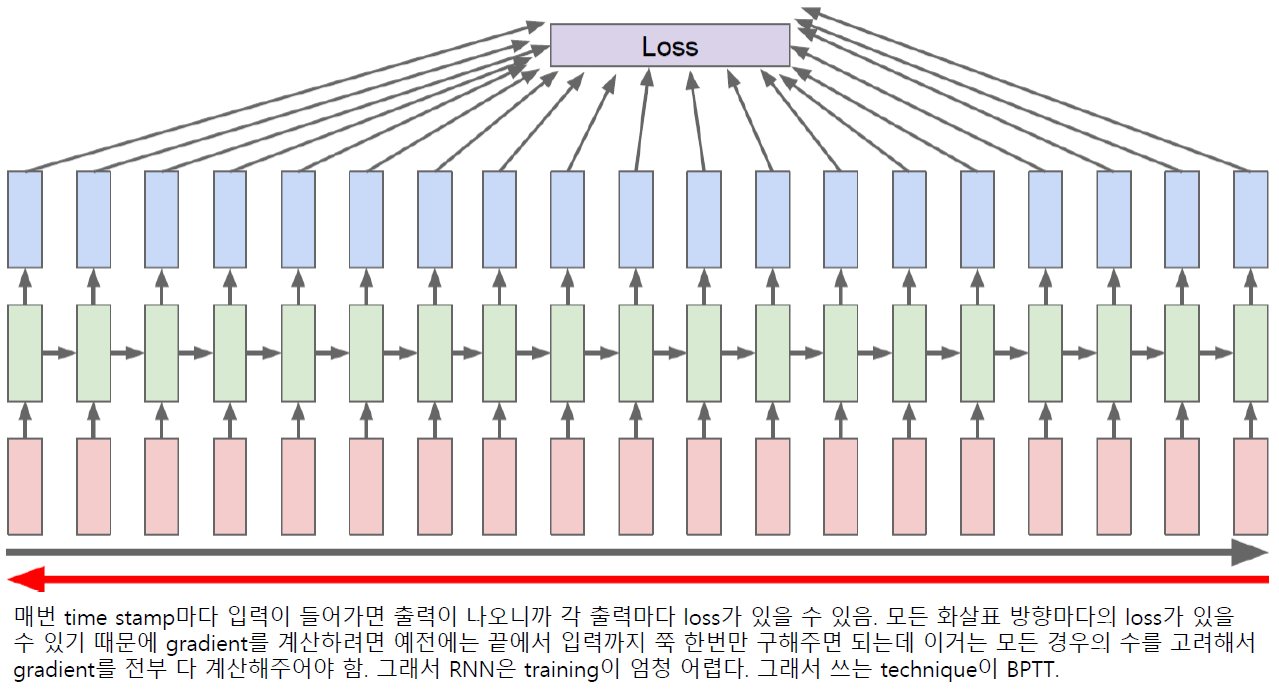
Truncated BPTT
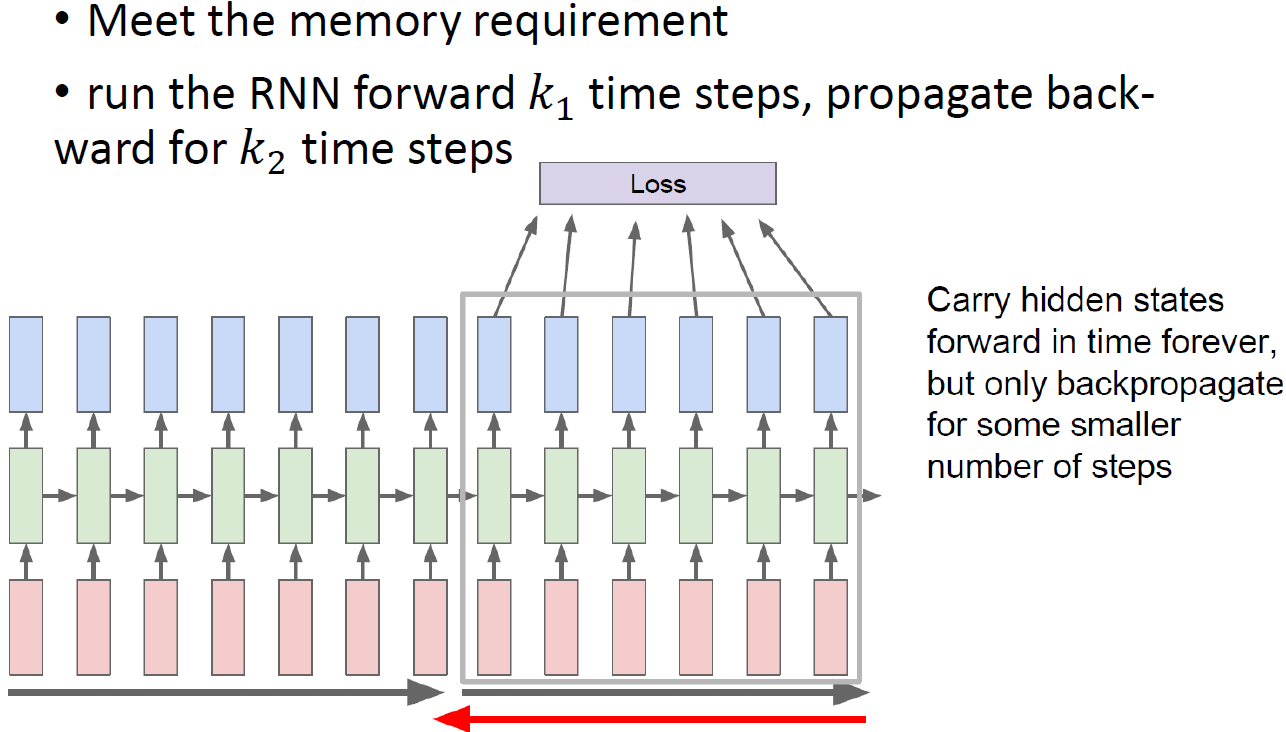
모든 timestamp(화살표)를 고려하는건 거의 불가능이라 일부만 고려한다.
108단어를 가지고 사용하지만 끝에 10단어만 사용해서 loss를 계산한다던가..
Time dimension에서 window를 사용해 그 만큼의 gradient만 계산하는 방식. 정확하지는 않지만 선택의 여지가 없다..
근데 사실 맨 끝의 정보가 처음까지 흘러와야 그 정보가 끝에 영향을 줄 수 있는데 이걸 잘라버리면 엄청나게 긴 양단의 정보를 쓰고 싶어도 training에서 그걸 막아버리게 된다... 그래서 정보를 fully 못쓴다.
Vanishing/Exploding Gradients

w가 1보다 작으면 w가 겁나 작은 수가 되고 w가 1보다 크면 겁나 큰 숫자가 되어버린다.
그래서 gradient가 거의 0가 되거나 너무 커지는 문제가 빈번하게 발생한다.
time stamp를 줄여서 20개만 쓰더라도 gradient가 굉장히 커지거나 작아질 수 있음... gradient quality가 좋지 않다.
그래서 w가 1 근처의 값으로 굉장히 잘 정해져야 함. 그래서 RNN이 어려운 문제임....
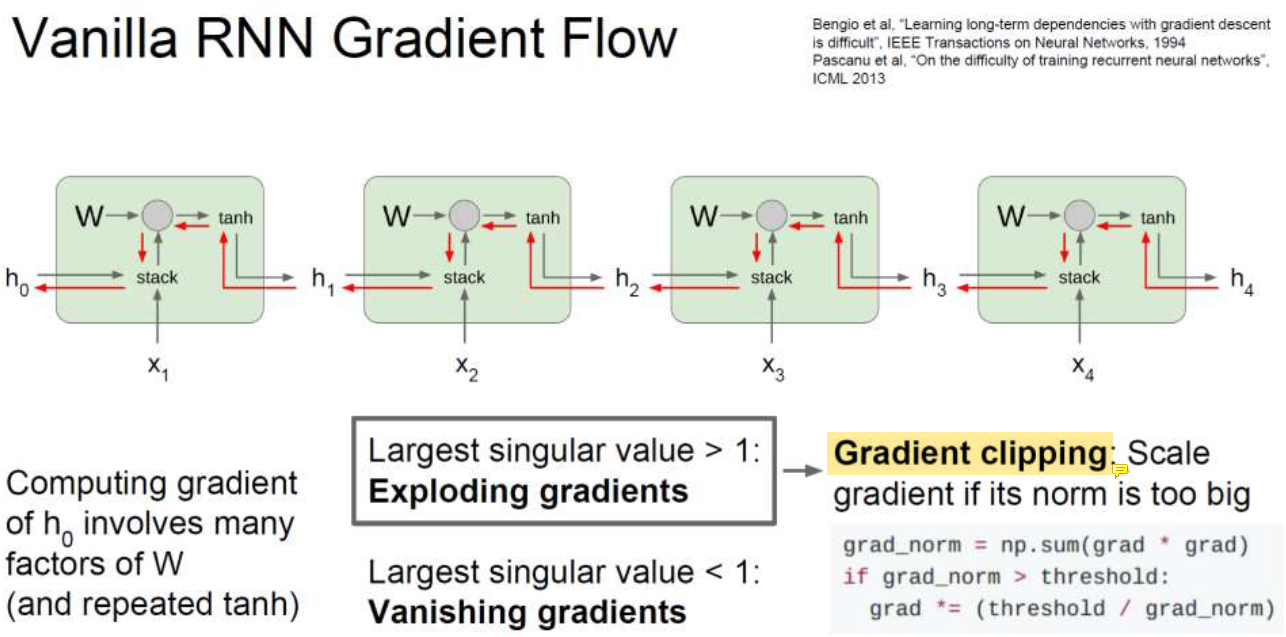
gradient가 크면 문제를 쉽게 해결할 수 있다. 그냥 잘라내면 됨(gardient clipping)!
크기만 건들고 방향은 그래도 두면 된다. 오른쪽 방향인지 왼쪽 방향인지 남겨두고 크기만 clipping하면 됨.
하지만 w가 1보다 작으면 이 문제는 풀 수가 없다...........
gradient를 키우기에는 얼마나 키워야하는지 멈출 데를 알 수가 없다.
그래서 RNN architecture를 바꿔야 함 (LSTM).
Problems With Naive RNN

핵심은 옛날 정보를 담아줄 수 있는 memory가 필요하다는 것임.
거창해보이지만 실제로 그렇게 복잡하진 않다.
근데 memory를 쓸 수 있게 해줬더니 gradient문제도 해결됐다고 함. 개이득
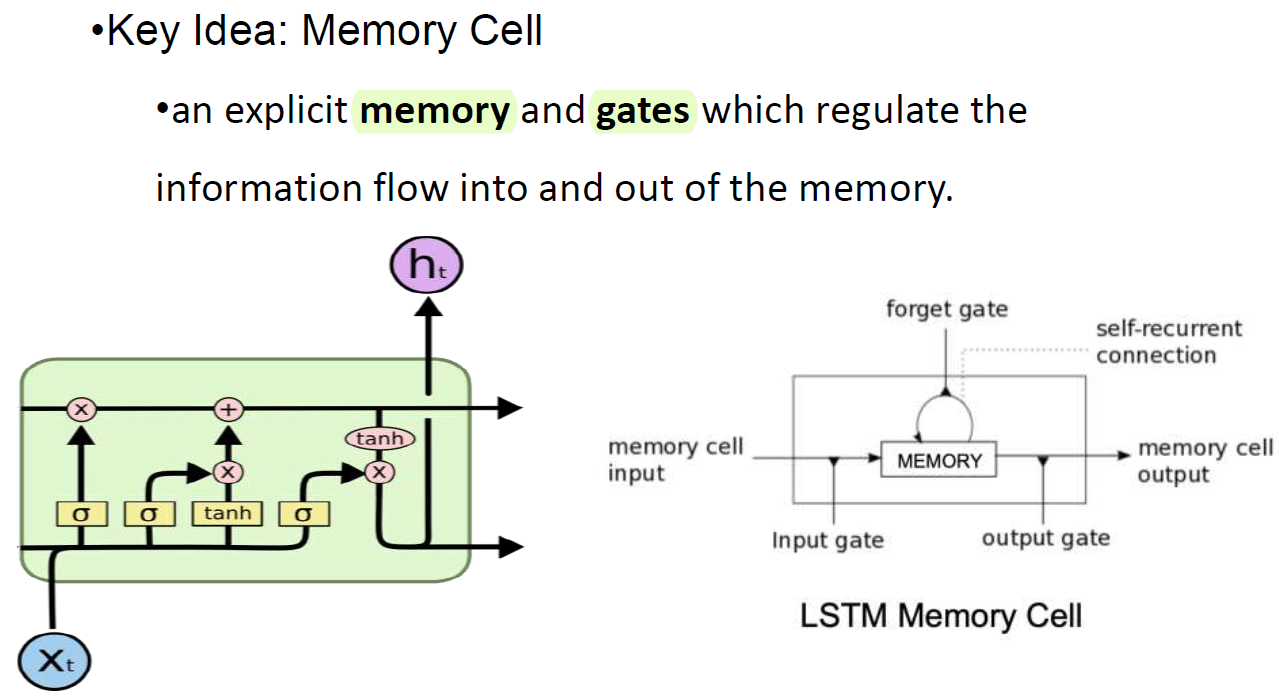
Long Short-Term Memory Networks (LSTM)
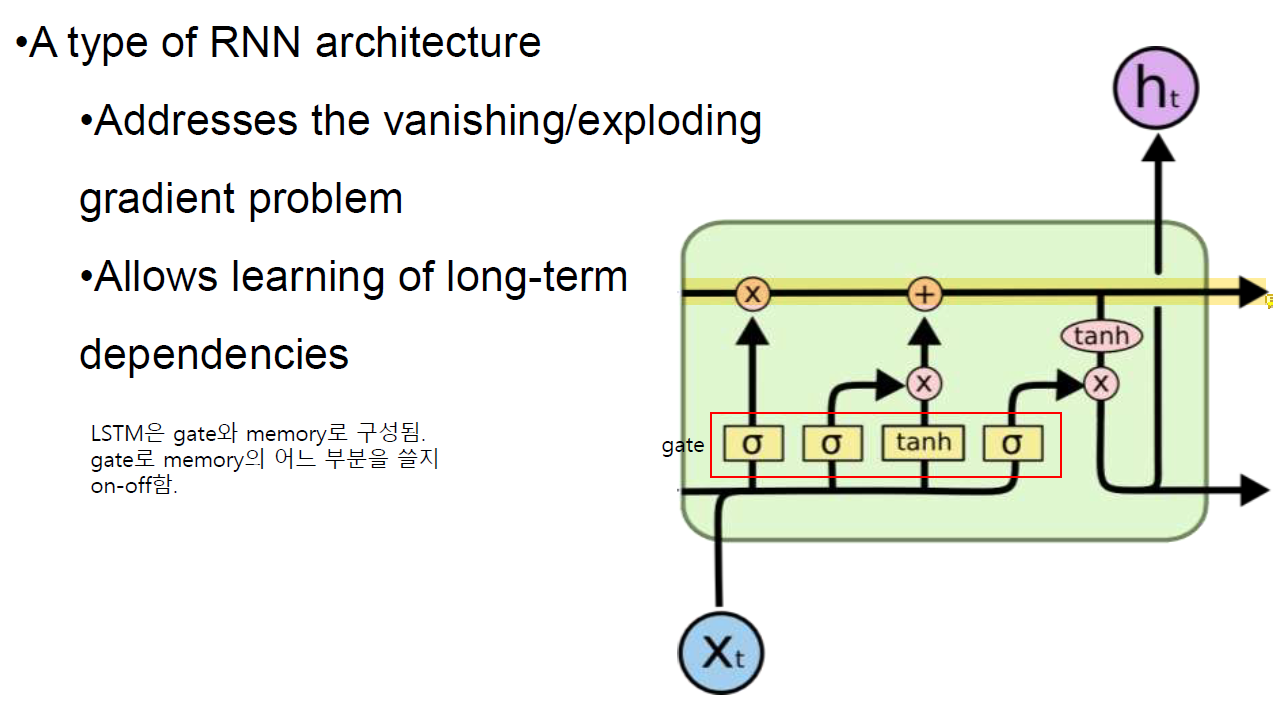
원래는 x랑 h만 있는데 하나의 line이 더 있는게 memory임.
memory는 옛날 정보를 담고 있다.
꽤 큰 module이지만 memory를 가지고 있어서 옛날 정보를 담아둘 수 있다.
계산할 때 w에 의존하지 않는다.
Time stamp가 길어서 생기는 vanishing, exploding gradient 문제에서 자유롭다. 정보가 아주 길게 흘러도 괜찮다는 얘기.. gradient로 인한 문제가 적음.
유일한 단점? 비싸다.
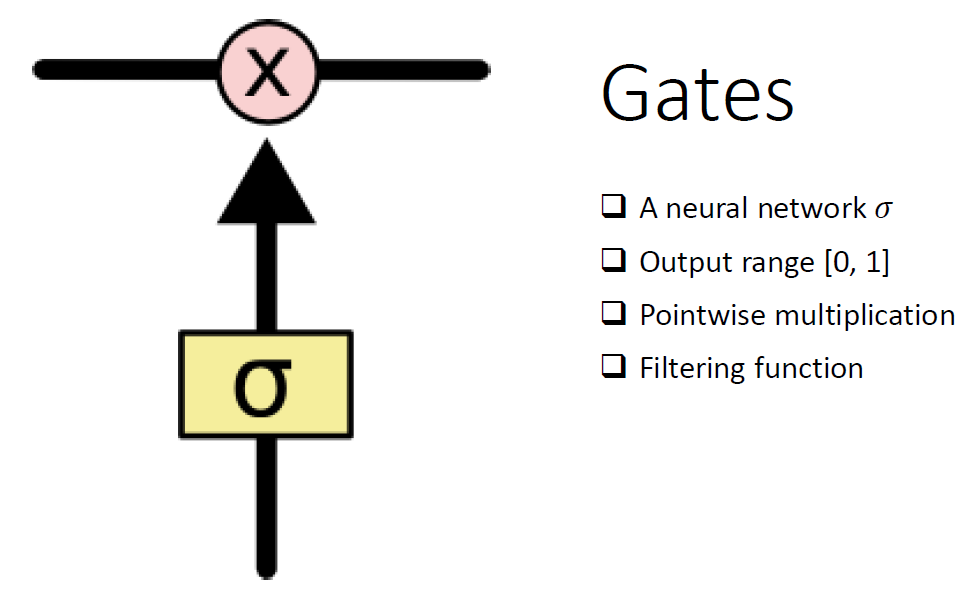
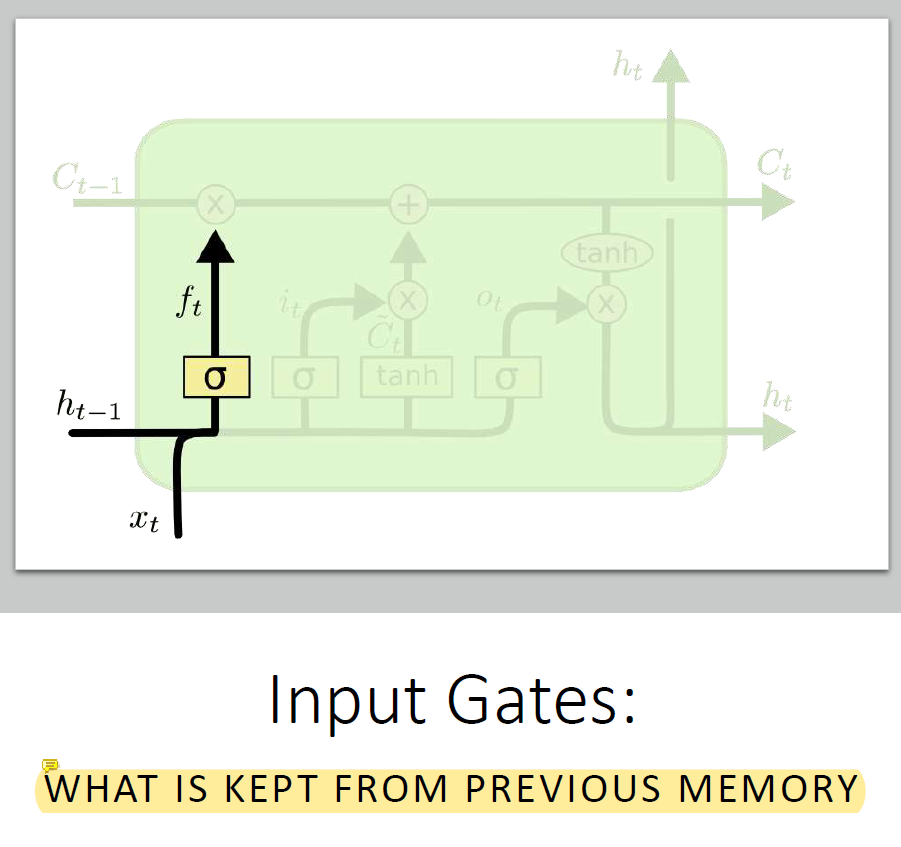 memory의 어느 부분을 가져다 쓸지 결정한다. 0에 가까운 부분은 안쓰고 1에 가까운 부분은 쓴다.
memory의 어느 부분을 가져다 쓸지 결정한다. 0에 가까운 부분은 안쓰고 1에 가까운 부분은 쓴다.
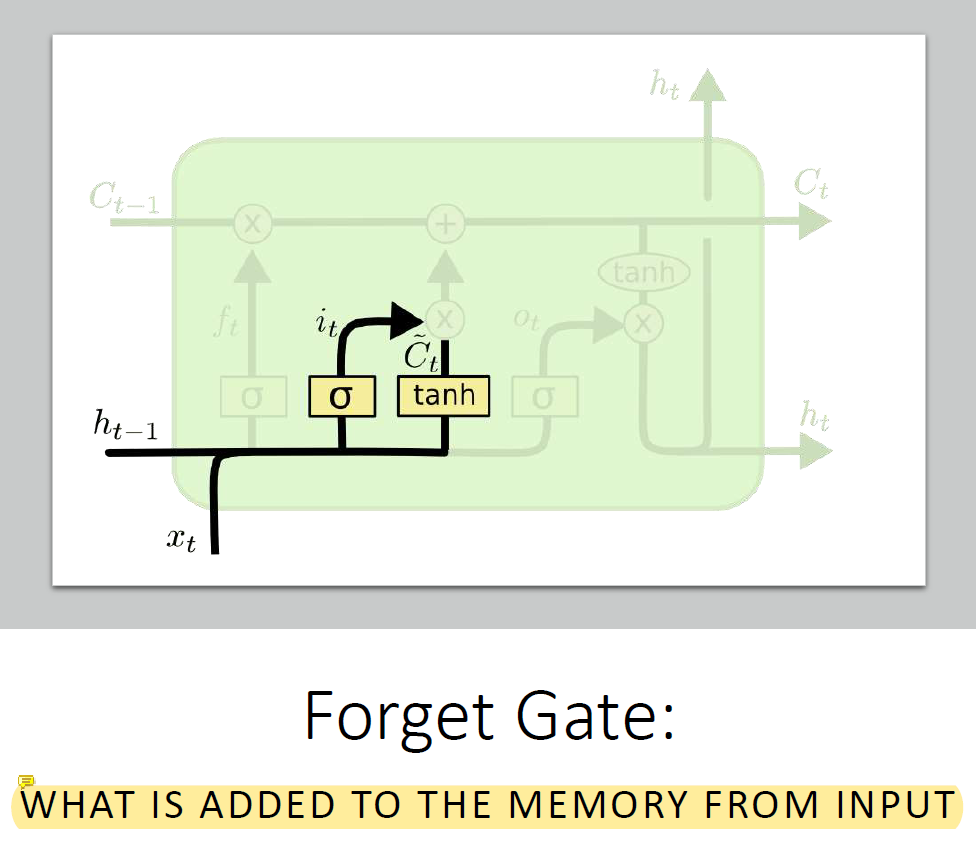 새로운 content를 넣거나 안좋은 content를 죽여서 memory를 update함. 현재 정보와 과거의 정보를 함께 사용함.
새로운 content를 넣거나 안좋은 content를 죽여서 memory를 update함. 현재 정보와 과거의 정보를 함께 사용함.
tanh가 원래는 원하는 content인데 그냥 넣으면 memory가 싹 다 갈아엎어지니까 σ를 통해 update를 할지 안할지 결정함. 곱해지니깐.....
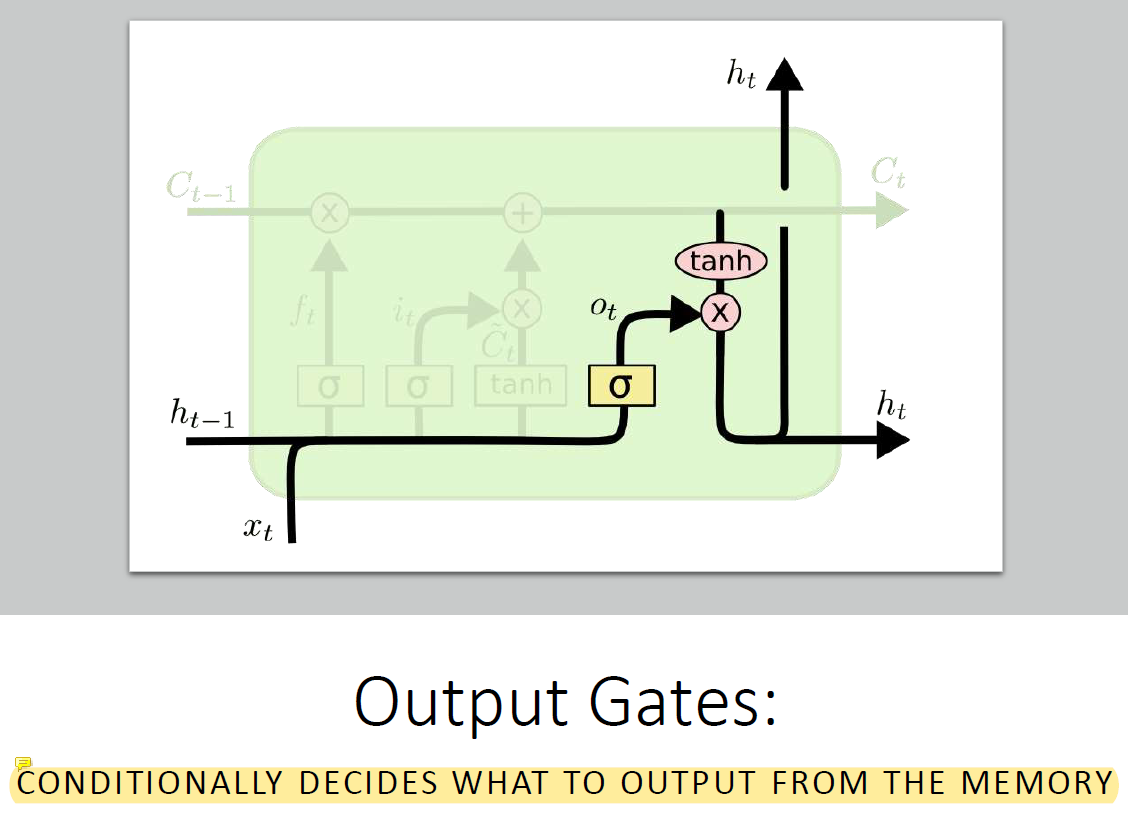 Memory를 통해 일을 하는 부분이다.
Memory를 통해 일을 하는 부분이다.
다음 stage로 결과를 내보내는 feature도 있고 h를 upgrade하는 데에 memory를 반영함.
LSTM: Gradient Flow
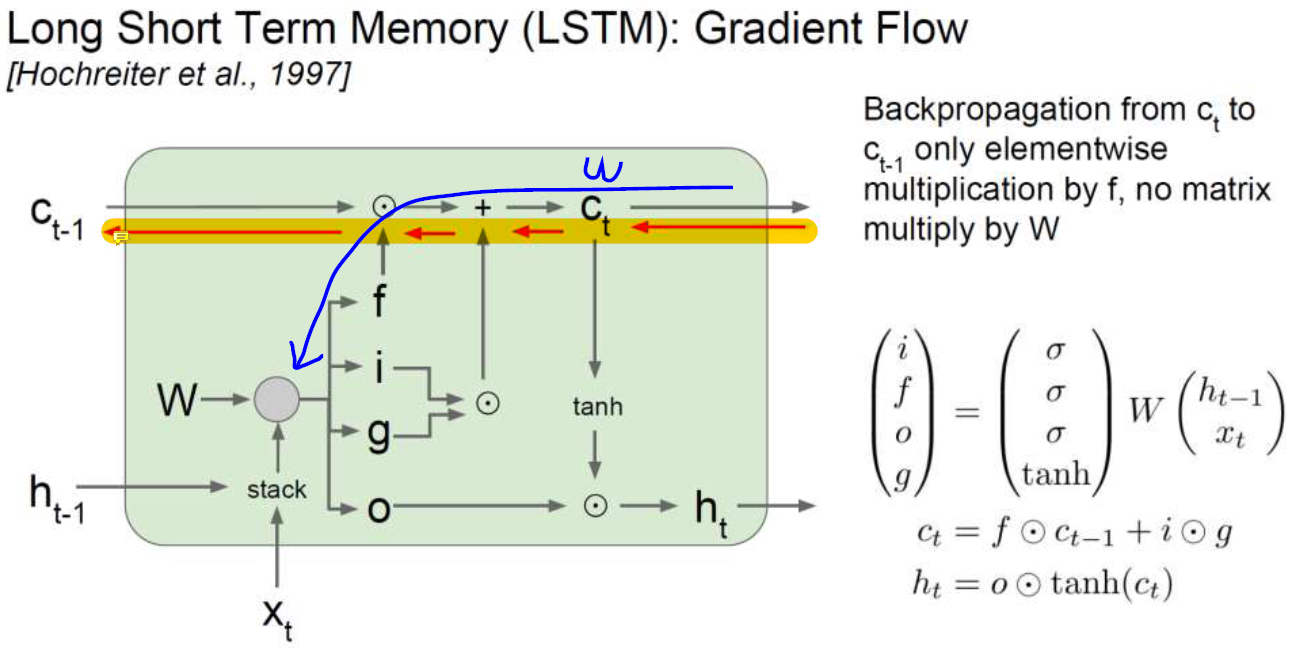
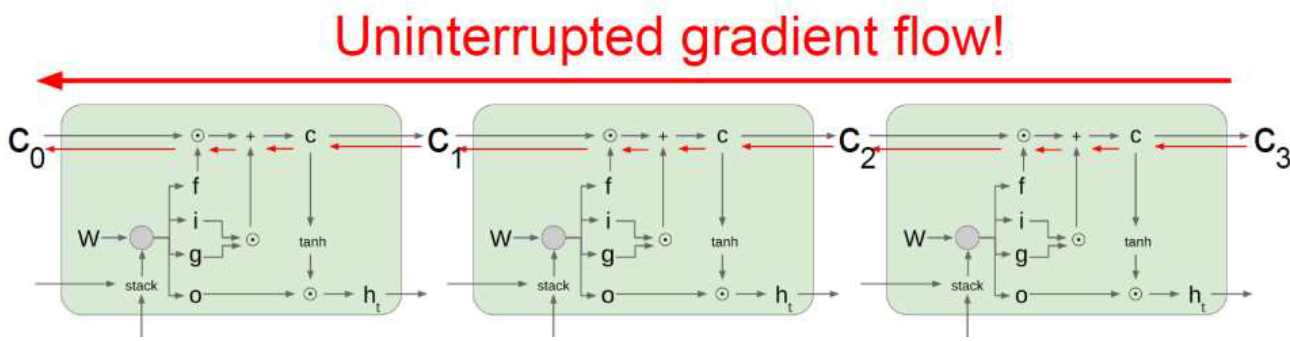
memory는 굉장히 오랫동안 정보를 담고 있어야해서 잘 변하지 않고 엄청 오래 전의 값이 현재에도 잘 남아있음.
그럼 gradient가 저 앞쪽까지 갈 수 있다는 뜻임. 그렇게 학습을 하다보면 엄청 오랫동안 정보가 남아서 마치 ... 이 전체 module을 쭉 이어서 엄청 길게 사용하는 것 같은 효과가 나는 것임. 엄청 오랫동안 값이 안바뀌니까 엄청 앞쪽까지 강력한 gradient가 갈 수 있다.
원래는 gradient가 여러번 곱해지면서 w가 1언저리의 값이어야했는데 LSTM은 w랑 backpropagation에 dependency가 없어서 옛날 정보를 오랫동안 간직하는 특징이 있고 gradient를 계산할 때만 w를 씀.
GRU: Gated Recurrent Unit
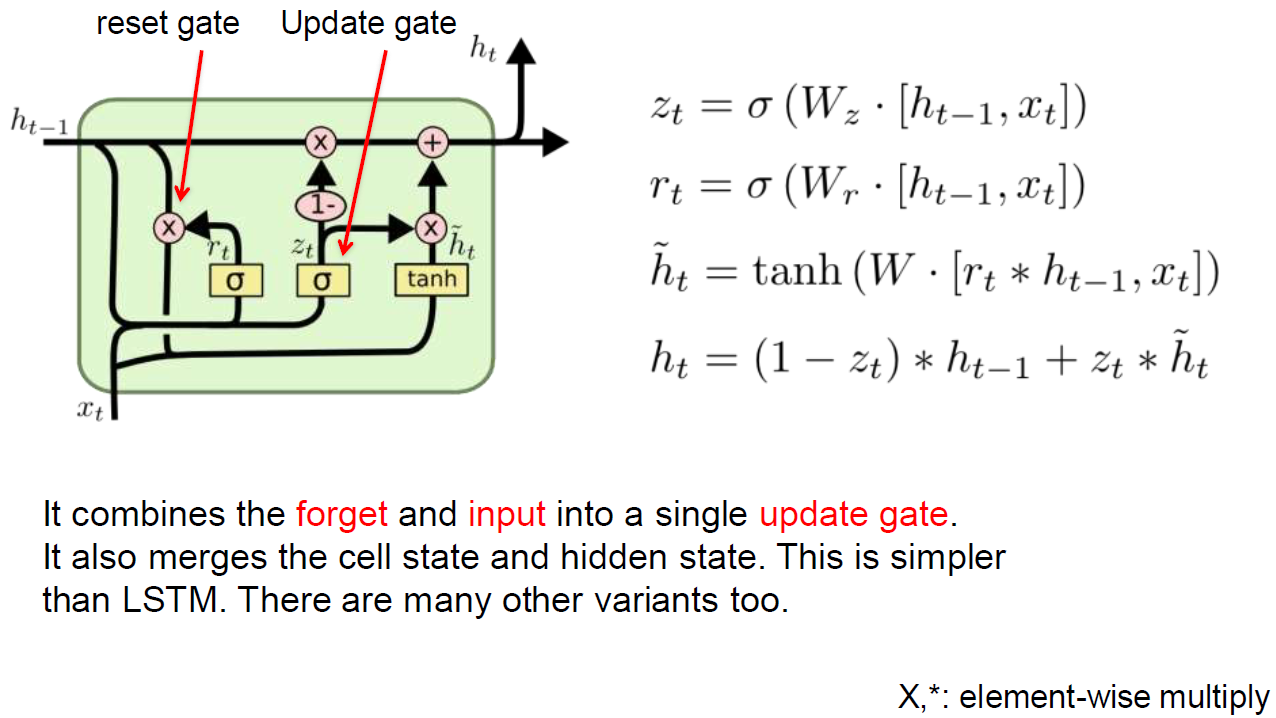
GRU는 LSTM의 simple한 version이다.
cost가 LSTM의 절반밖에 안되고 어떤 부분은 update하고 어떤 부분은 update를 하지 않는다. advanced된 모델. 컨셉만 알고있으면 돼.
memory가 feature map같은 거라 이전에 갖고 있었던 문제점이 memory를 통해 자동으로 해결되었다는 점.
