✨Case Studies, Practical Advices for Using ConvNets
딥러닝

LeNet-5
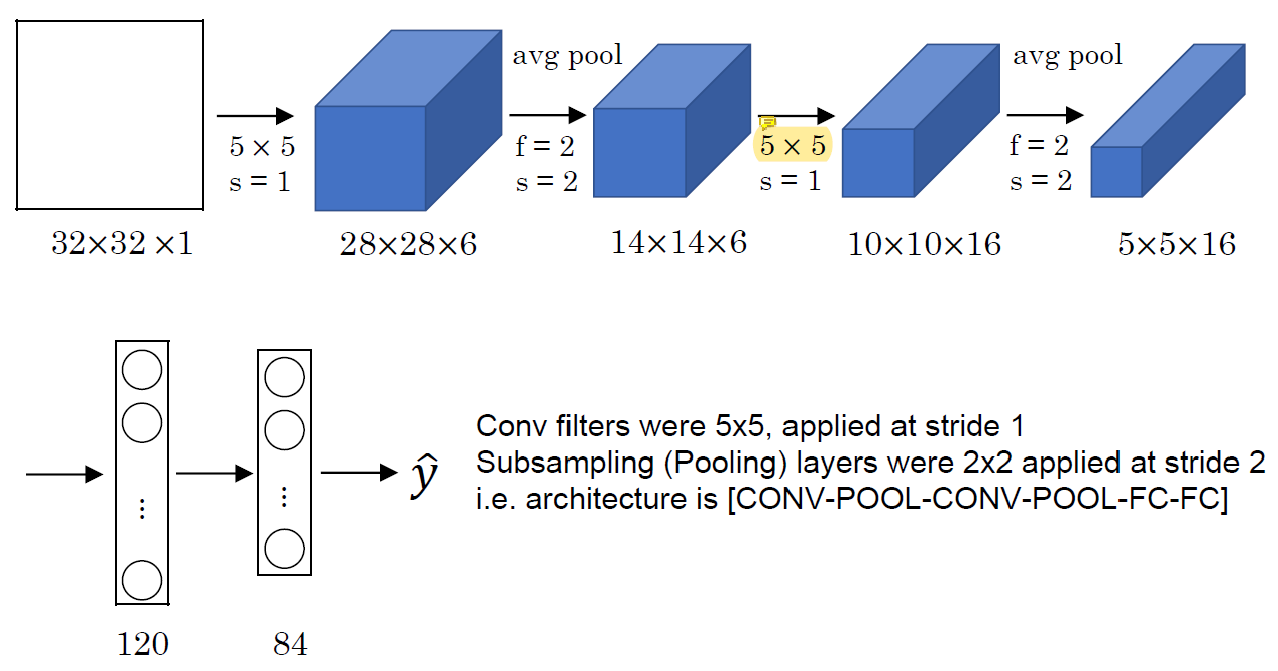 일종의 multi-level convolution.
일종의 multi-level convolution.
AlexNet
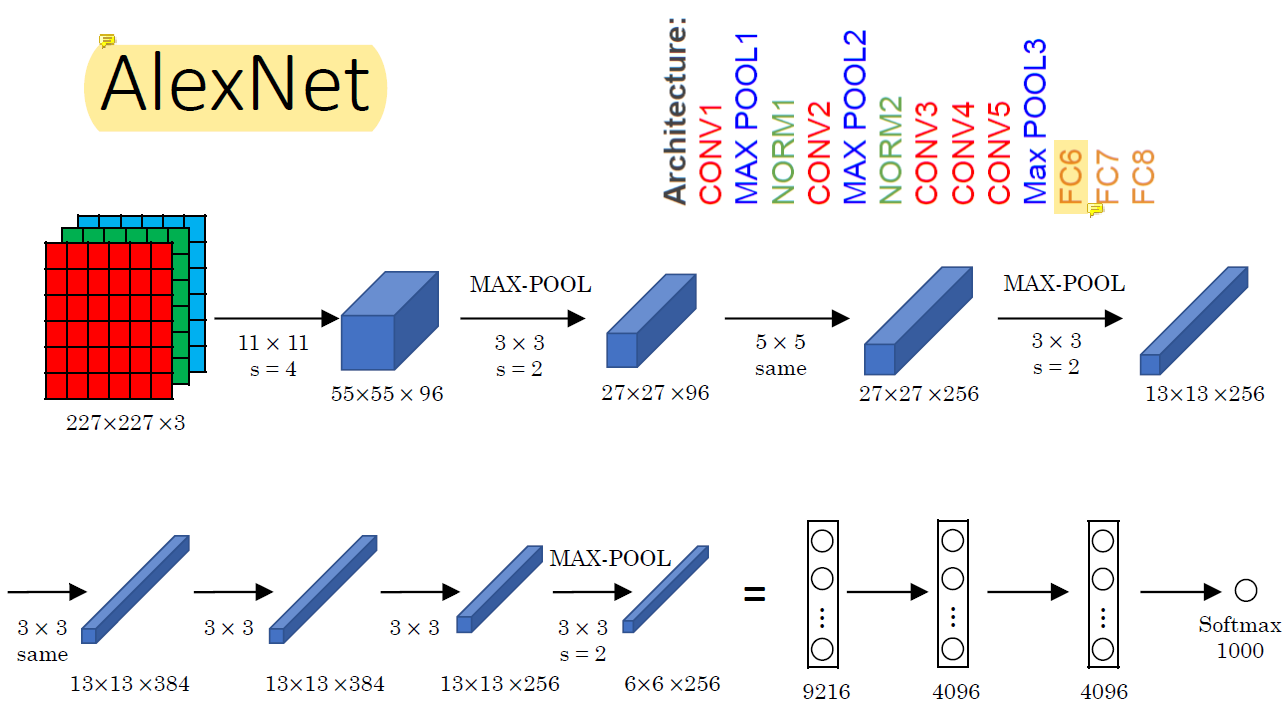 AlexNet은 총 8개의 layer 중 5개가 convolution layer이다.
AlexNet은 총 8개의 layer 중 5개가 convolution layer이다.
이전에 비해 뛰어난 성능 향상을 보였는데 여러가지 이유가 있겠지만 가장 큰 이유는 data set이 커졌기 때문이었다.
FC는 freely connected다.

AlexNet은 ReLU를 처음 사용했다.
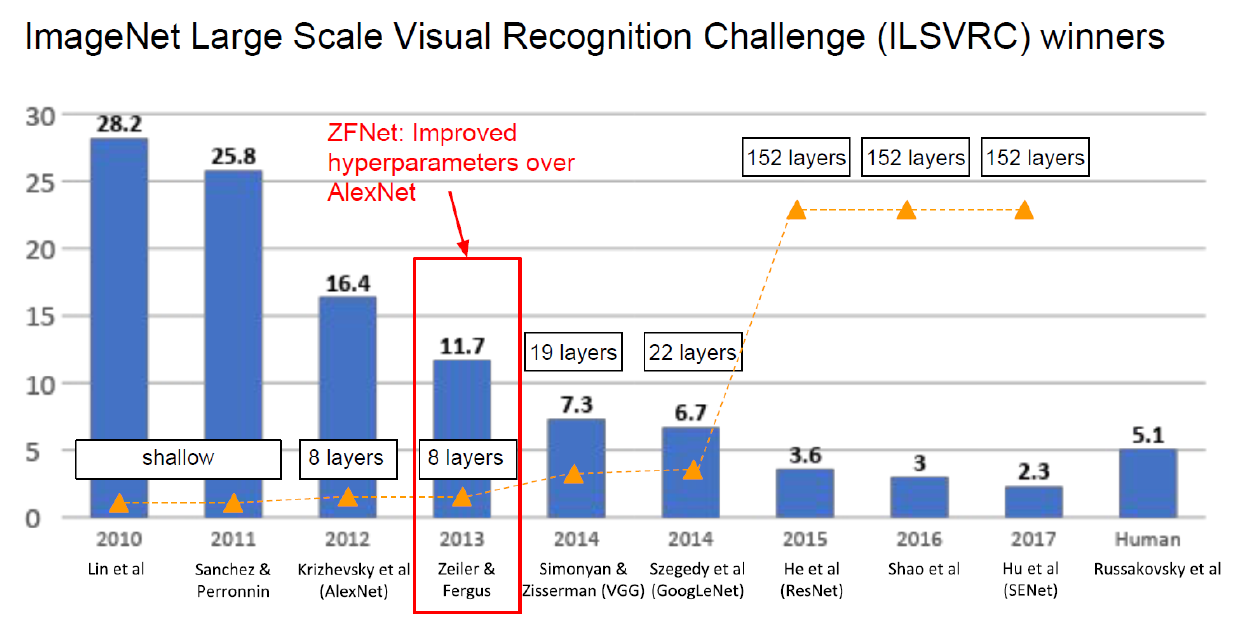
이전까지는 shallow neural network였다가 AlexNet이 등장하면서 8 layer로 많은 성능 향상을 이뤄냈다.
그 다음으로 나온 ZFNet은 AlexNet의 변형된 version인데, 많은 성능 향상을 얻었다.
ZFNet
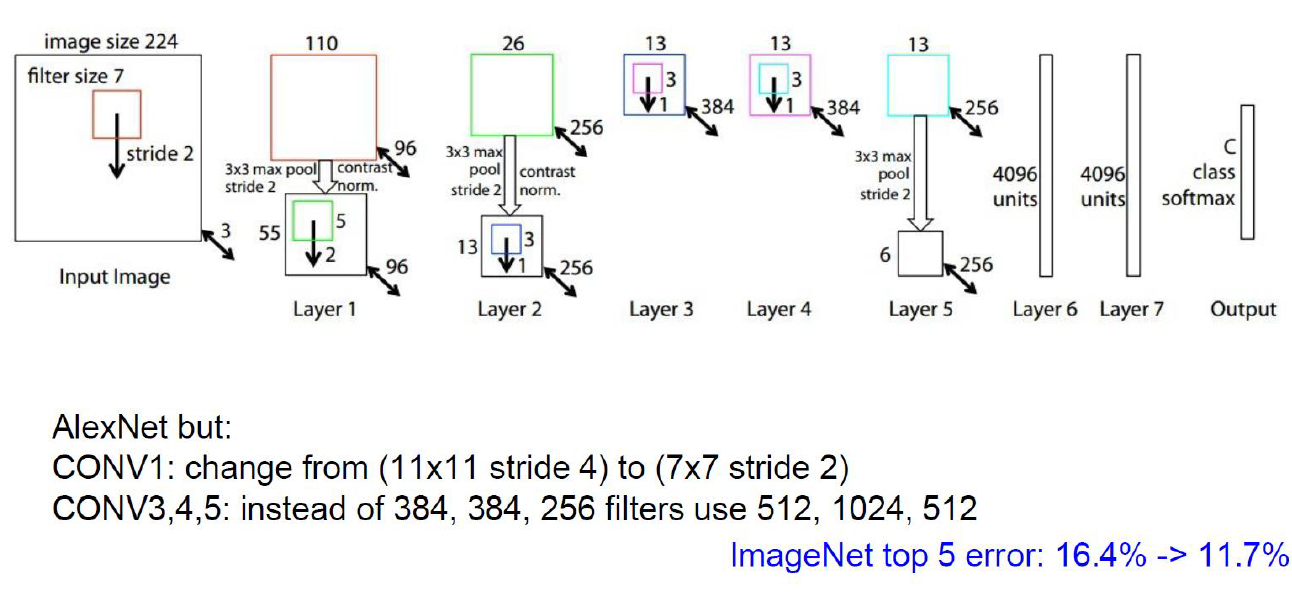 ZFNet은 AlexNet의 약간 변형된 버전이다.
ZFNet은 AlexNet의 약간 변형된 버전이다.
AlexNet을 조금 바꿨더니 성능이 좋아진 것이다.
예전에는 parameter같은 숫자 하나 바꿔보려면 시간이 오래 걸렸다.
그래서 이 당시에는 parameter 결정에도 많은 시간이 필요했기 때문에 이런 parameter를 정해서 error를 낮추는 것이 중요했다.
자신의 시간과 비용을 들여서 결과를 낸 것이기 때문에..
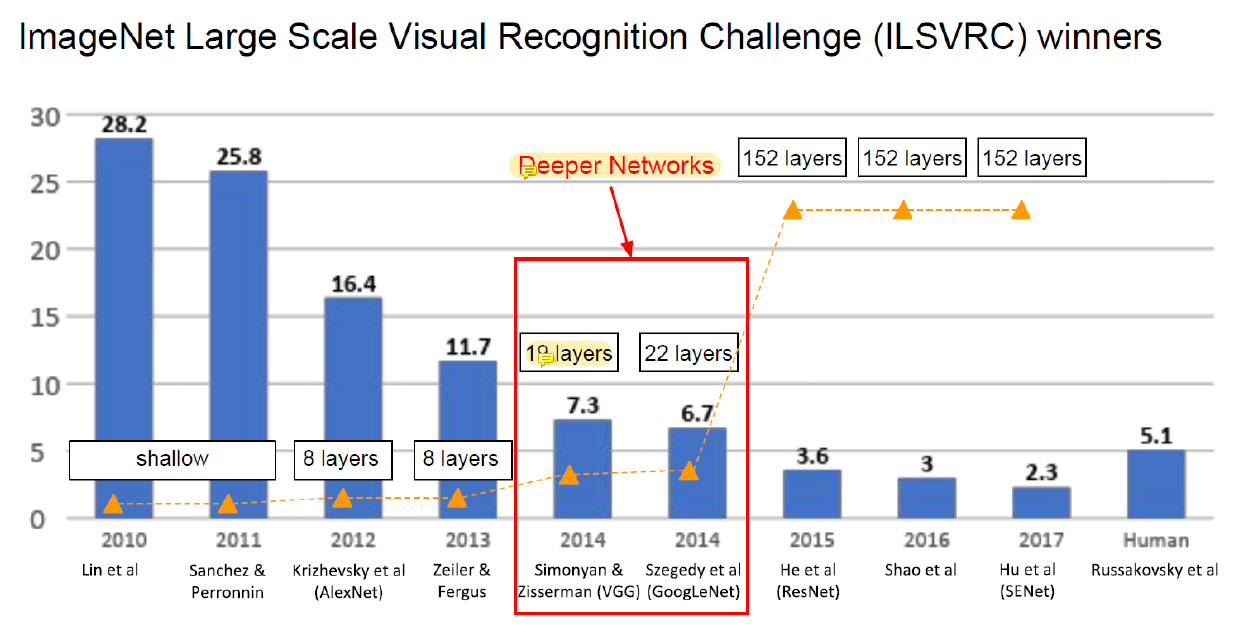
이 다음에 생긴 것이 VGG와 GoogLeNet인데 제일 유명하다.
그리고 이것들을 설계하는 데에 쓰였던 테크닉들이 아직도 쓰인다.
VGG를 보면 AlexNet 대비 layer가 2배는 많다.
이전의 기술로는 layer 10층을 넘기기 힘들었다.
Parameter가 늘어나고 network가 깊어지면 gradient 문제가 생겼기 때문이다.
VGG-16
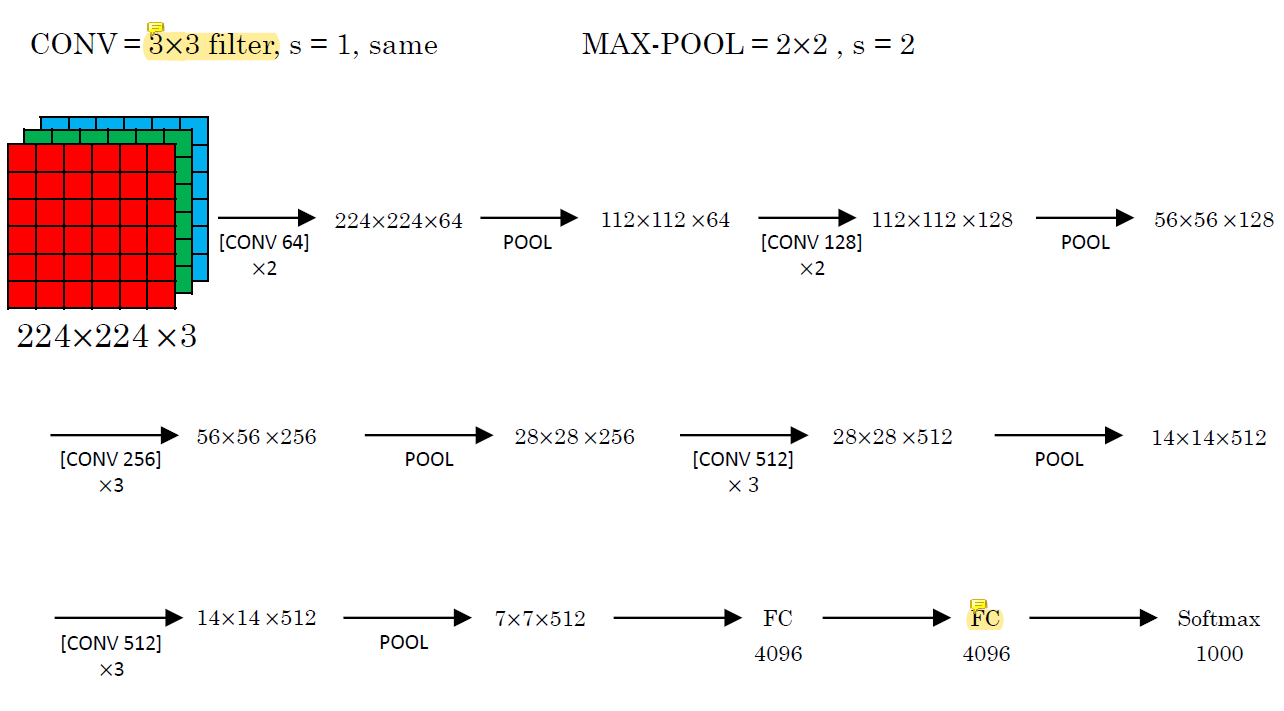 VGG에서는 convolution을 할 때 사용하는 filter의 크기가 이전의 network보다 작다.
VGG에서는 convolution을 할 때 사용하는 filter의 크기가 이전의 network보다 작다.
Filter의 크기를 줄였다는 것은 한 layer에서 variable의 개수를 줄였다는 것이다.
찾아야하는 factor의 수가 매우 줄어들고 훨씬 적은 수의 parameter가 한 layer에 들어있다.
한 layer에서 parameter의 개수를 줄이는 대신, layer의 개수를 늘리는 방식을 취했다!
Small filters, Deeper networks!
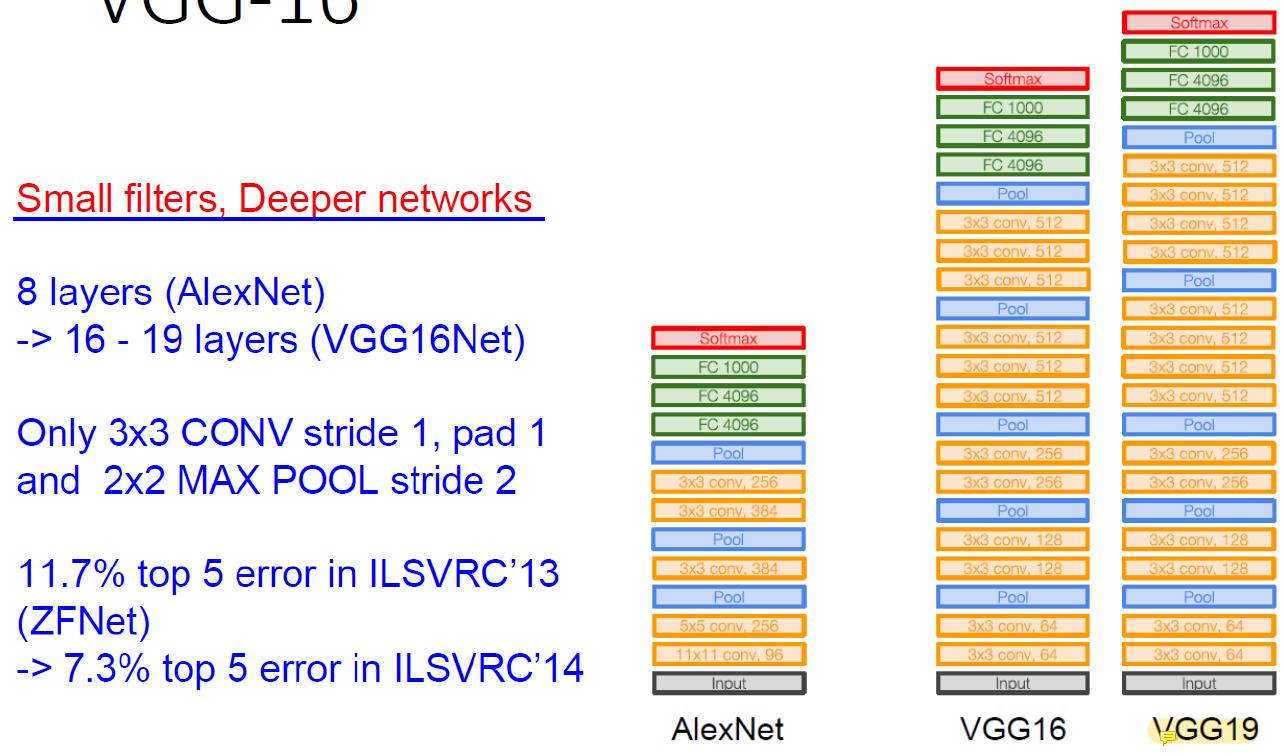 VGG-16보다 VGG-19의 성능이 더 좋다.
VGG-16보다 VGG-19의 성능이 더 좋다.
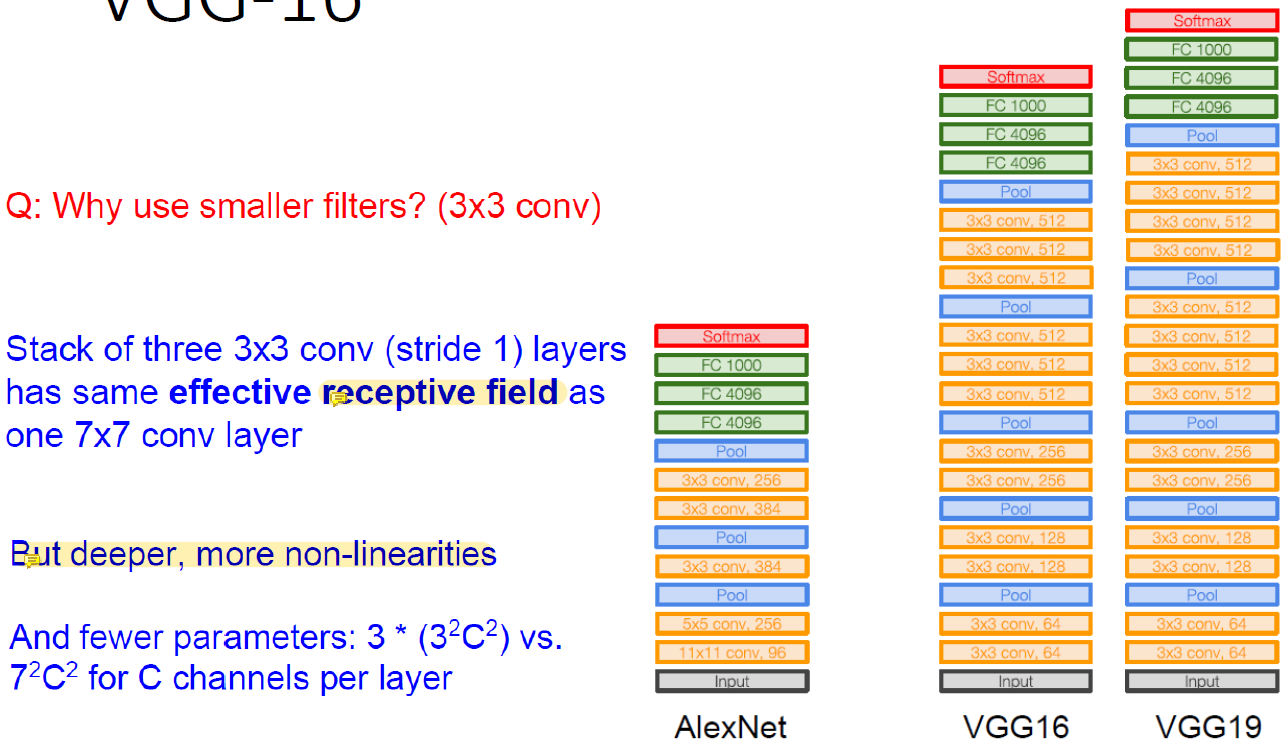
3x3 convolution layer를 3개 쌓은 것은 하나의 7x7 convolution layer만큼의 receptive field를 가지고 있다!
Receptive field는 크면 클 수록 좋다!
큰 filter는 receptive field가 엄청 큰데 3x3 filter는 이 값이 작다.
그런데 작은 filter도 layer를 깊게 쌒으면 어느정도 큰 값을 확보할 수 있다는 것이다.
근래에는 대부분의 neural network가 워낙 크기 때문에 이 값을 고려하지 않는다.
Filter의 크기가 작지만 layer가 깊기 때문에 더 많은 non-linearity를 줄 수 있다는 장점이 있다.
Layer 하나를 지날 때마다 non-linear function을 만나기 때문이다.
대신 각각의 layer 자체의 성능은 좋지 않다.
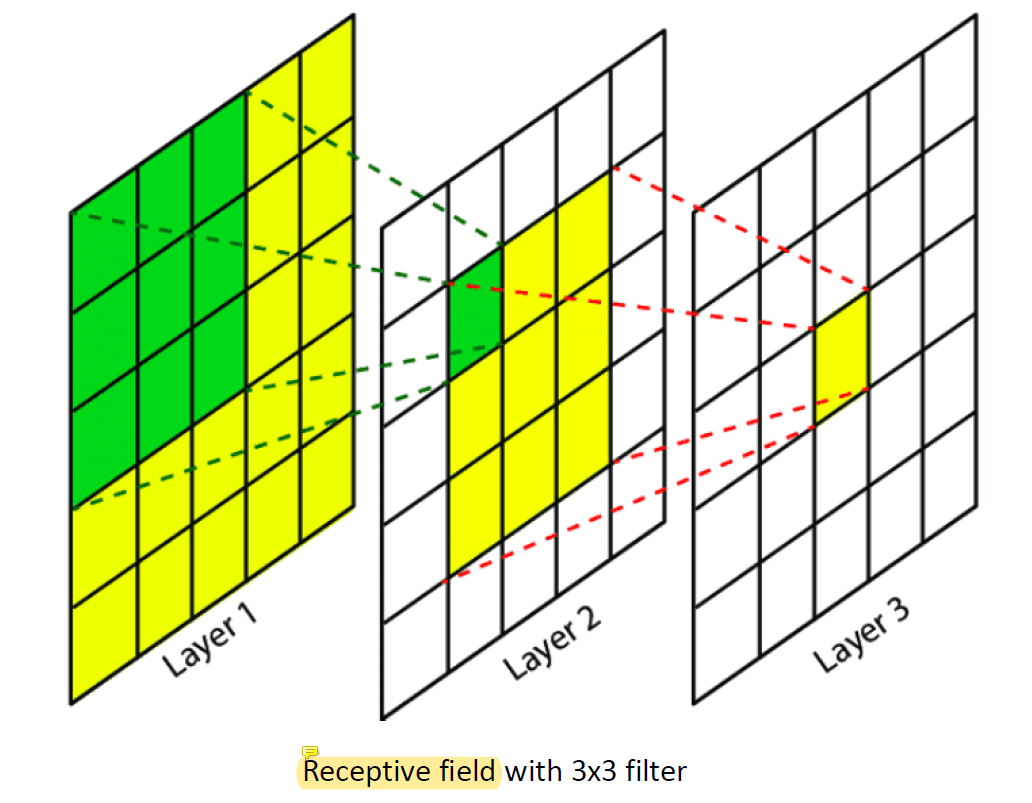
Receptive field는 마지막 layer의 한 값을 update하는 데에 얼마나 많은 값들이 영향을 미치는지를 나타낸 것이다.
Layer를 여러 개 쓰니까 멀리 떨어진 pixel 값도 사용을 할 수 있게 된 것이다.
Layer 3이 Layer 2만 썼다면 전체의 3x3밖에 사용을 못했을텐데 layer 하나를 더 쓰니까 Layer 1에서는 5x5를 다 쓰게 되었다!
크기가 큰 filter를 사용하면 더 많은 영역의 값을 사용하게 되기 때문에 receptive field의 값이 커진다.
단점은 한 layer에 필요한 parameter의 수가 많아져서 쓸 수 있는 layer의 수가 작아진다 (쓸 수 있는 parameter의 개수는 한정적이다).
Filter의 크기가 작아도 layer를 깊게 쓰면 멀리 있는 정보를 가져와 사용할 수 있다.
 VGG의 paramter 대부분은 후반부에 집중되어 있다.
VGG의 paramter 대부분은 후반부에 집중되어 있다.
GoogLeNet
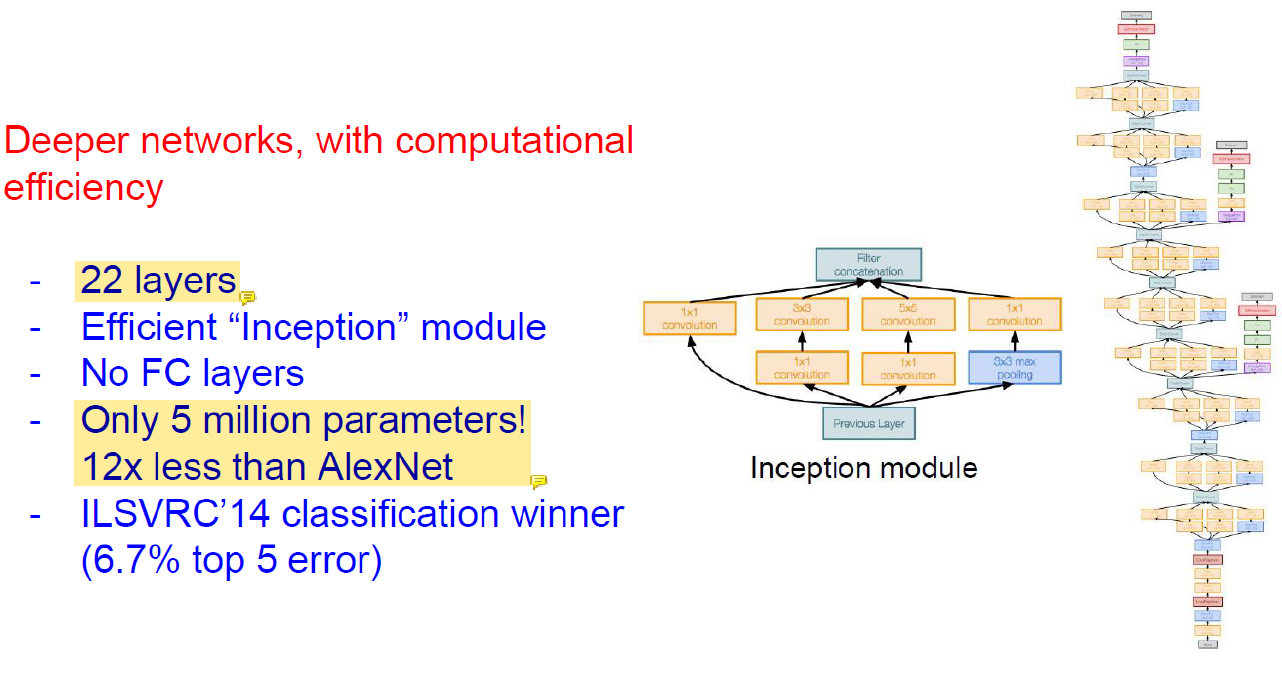 Computational 기술의 발달로 network가 깊어졌다.
Computational 기술의 발달로 network가 깊어졌다.
GoogLeNet은 20층을 최초로 넘어간 방법이다.
convolution을 많이 써서 parameter의 수는 엄청 적다.
적은 parameter로 좋은 performance를 낼 수 있던 이유는?
-> Inception module!
Good local network topology를 디자인해서 module을 쌓아서 사용했다.
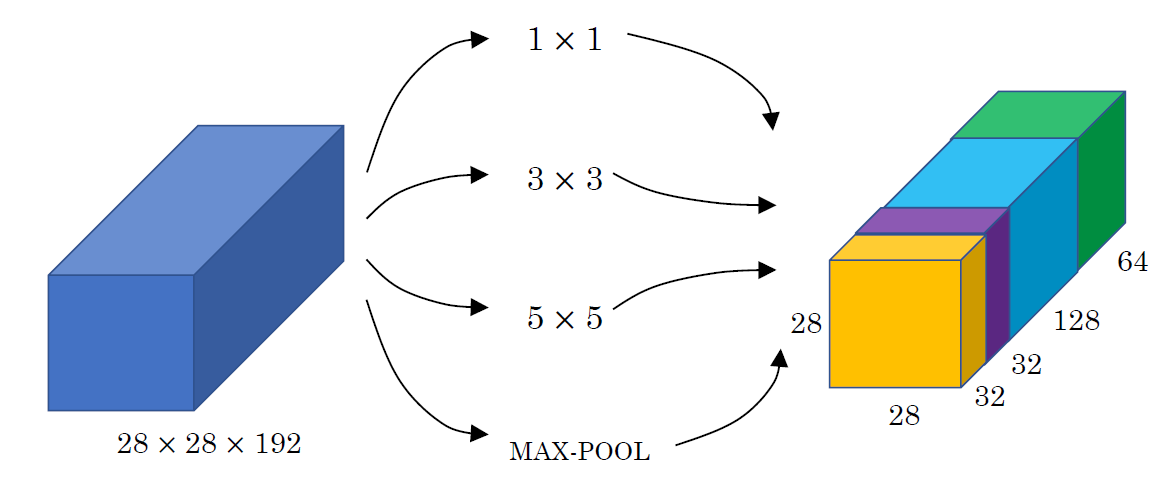
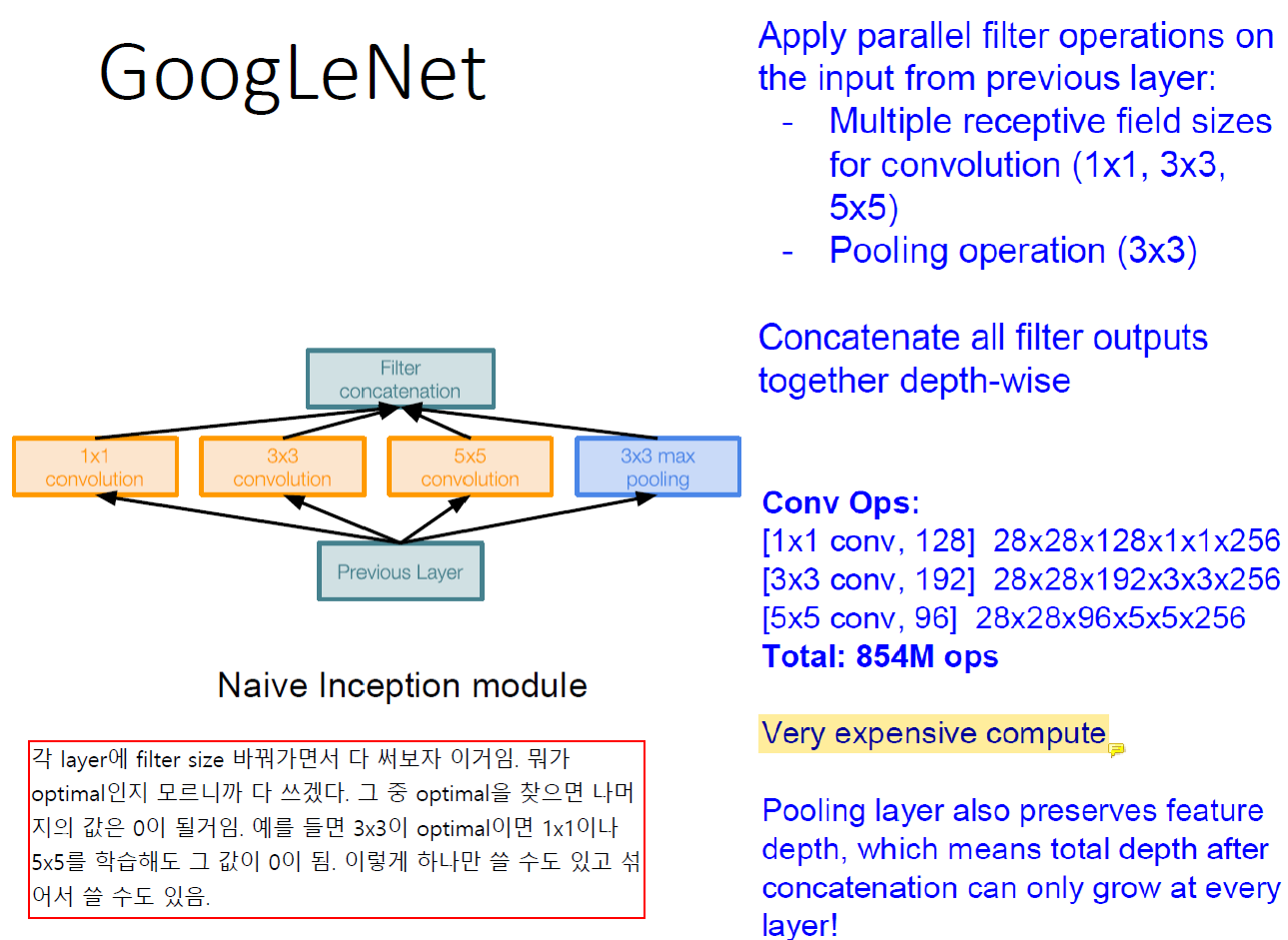 Naive inception module은 어떤 convolution filter size가 optimal인지 모르니까 다 써보는 것이다.
Naive inception module은 어떤 convolution filter size가 optimal인지 모르니까 다 써보는 것이다.
Optimal이 아니면 convolution의 결과는 0에 수렴할 것이다.
여러 filter size를 다 계산해야하기 때문에 계산이 매우 expensive하다.
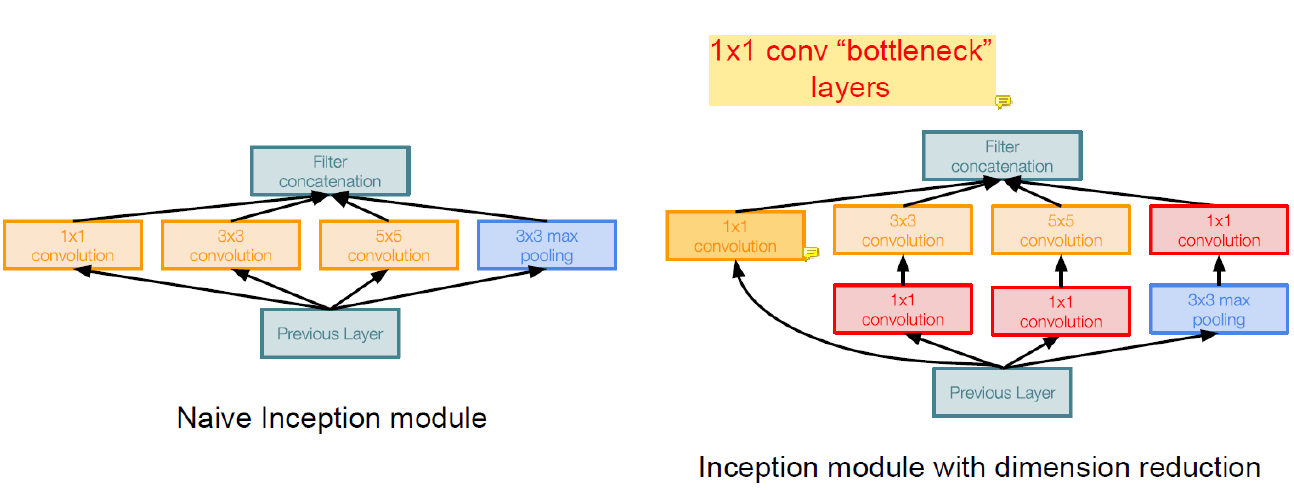
1x1 convolution bottleneck layer를 넣어 channel의 수를 줄인다 (빨간색 layer).
가장 왼쪽의 1x1 convolution layer은 channel size를 줄이려고 넣은게 아니라 1x1 filter가 중요한지 알아보기 위해서 넣은 것이기 때문에 bottleneck layer가 아니다.
What Does a 1x1 Convolution Do?
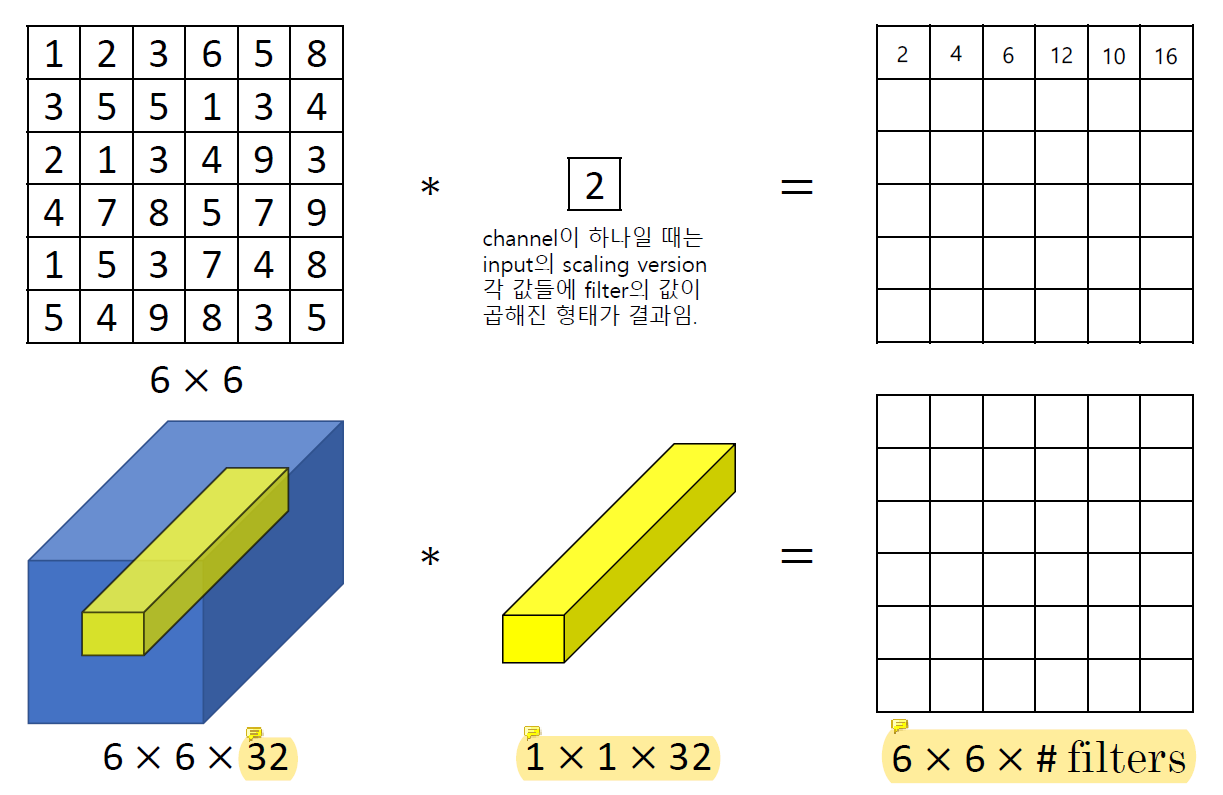
6x6x32에서 32는 filter의 개수이다.
1x1x32 filter에는 더할 때의 weight 값이 들어있다.
이 연산은 각 channel의 weighted sum을 하는데 그 weight값을 정해주지 않고 학습을 할 수 있다.
32 channel을 다 각각의 filter와 곱한 다음에 더해서 결과를 낸다.
맨 처음 channel만 중요하다면 filter가 1 0 0 0... 이렇게 학습 될 것이고 전부 중요하다면 filter가 1 1 1 1... 이렇게 학습될 것이다.
Weighted sum을 하는데 전략을 고민할 필요가 없고 알아서 중요한 것에 weight를 더 줄 수 있다.
이 특징을 통해 channel을 줄일 때 1x1 convolution을 사용할 수 있다.
Training을 통해 1x1 filter의 weight를 learning한다.
Using 1x1 Convolutions
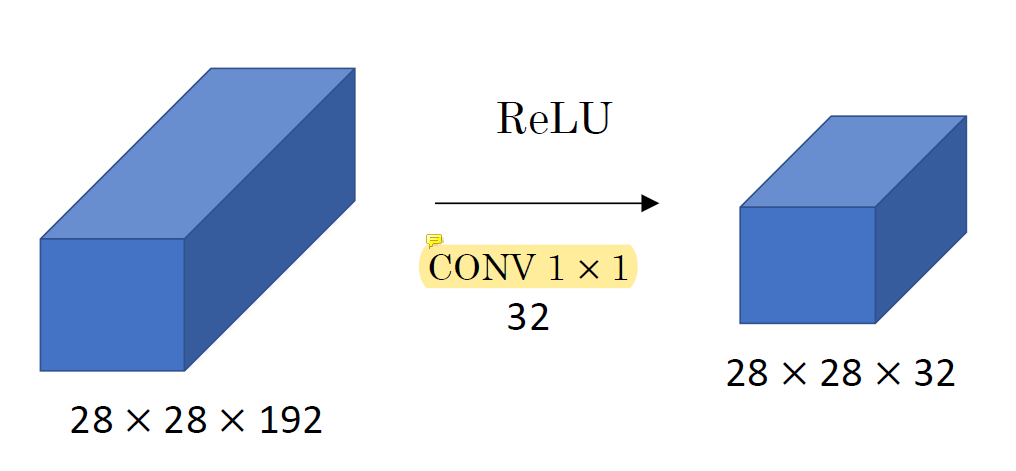
CONV 1 x 1이 각 channel중에 어떤 것이 안좋은지 골라준다.
Learning을 통해 알아서 중요한 channel만 남겨주는 것이다.
The Problem of Computational Cost
Using 1x1 Convolutions
Using 1x1 Convolution
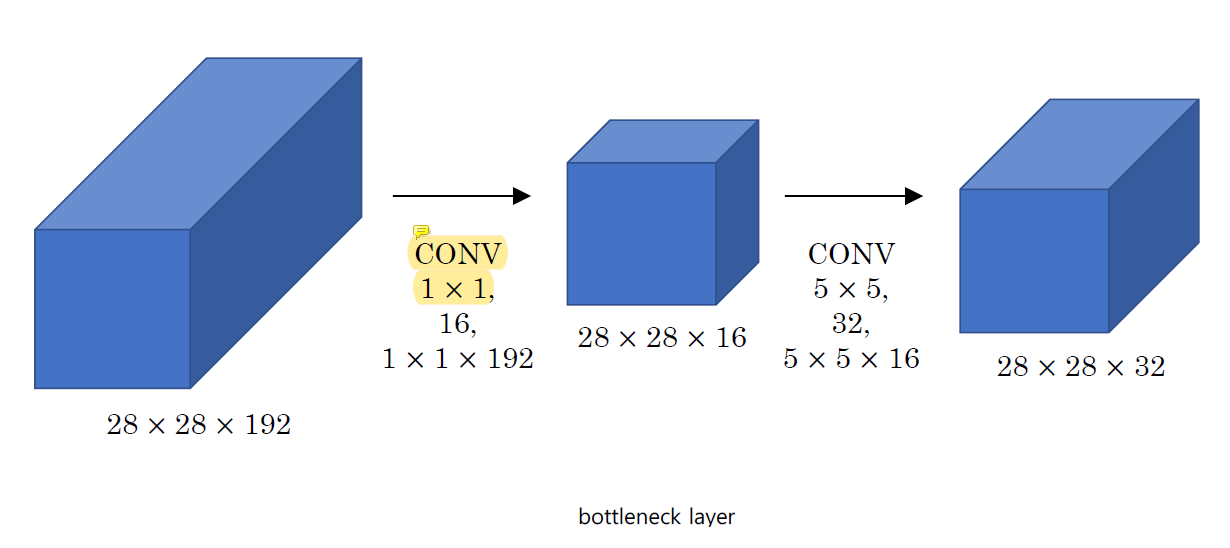 뒤에 비싼 계산을 할 때 채널을 줄이는 용도로 사용한다.
뒤에 비싼 계산을 할 때 채널을 줄이는 용도로 사용한다.
앞에서 엄청 큰 input으로 channel이 엄청 많은데 1x1 convolution으로 channel을 확 줄이고 비싼 5x5에 넣는다.
5x5 convolution으로 줄였던 channel을 좀 늘릴 수 있다.
28x28x16은 channel의 수를 줄여주는 bottleneck layer이다.
Inception Module
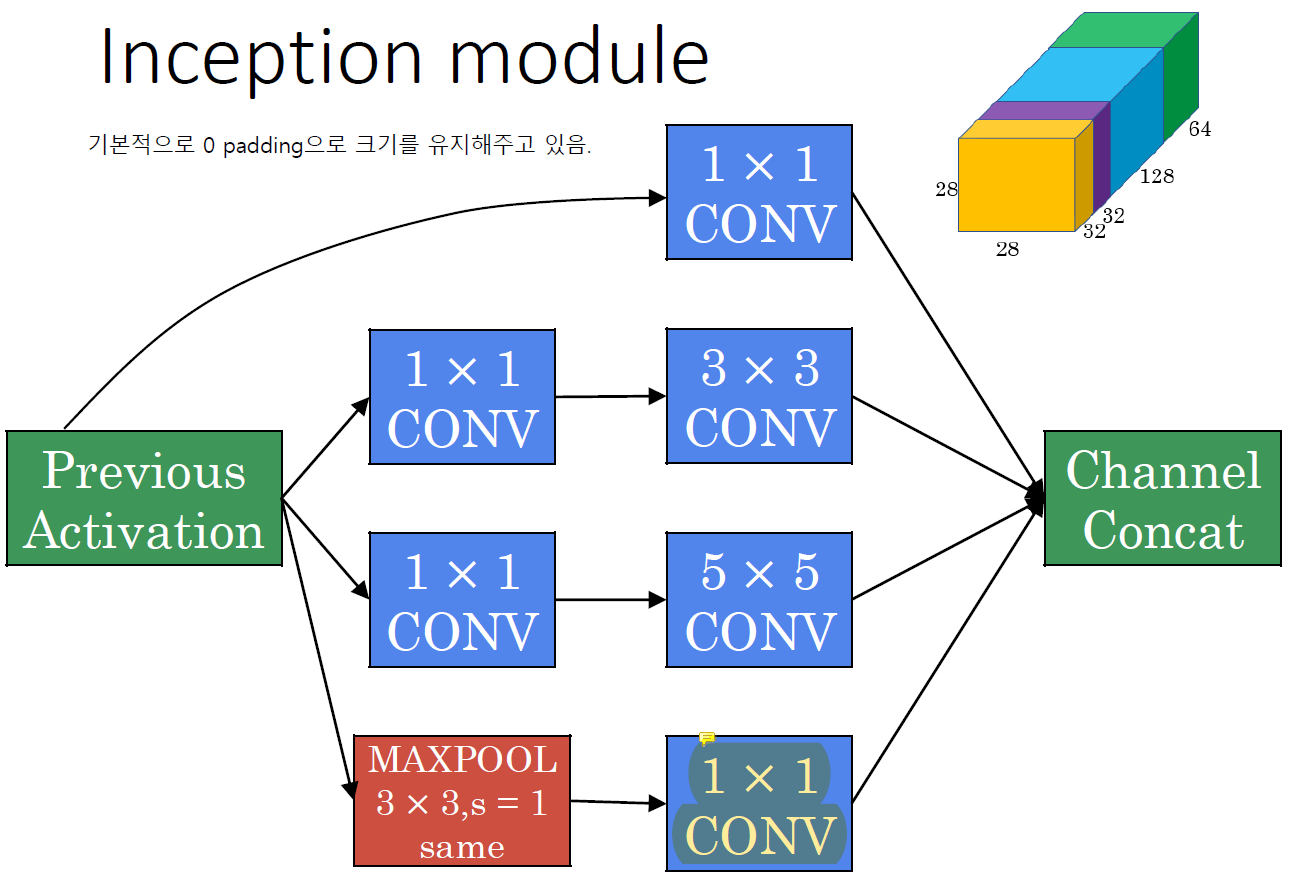 Maxpooling 다음의
Maxpooling 다음의 1x1 convolution은 채널 수를 줄이기 위한 것이다.
Maxpooling 자체는 엄청 simple해서 그 앞에 channel을 줄일 필요는 없다.
100 채널 maxpooling 하는건 순식간인데 그 100 채널을 뒷단에 그냥 보내는건 부담이라 보내기 전에 채널 수를 줄이는 것이다.
Stack Inception Network
 Inception을 말 그대로 쌓은 네트워크.
Inception을 말 그대로 쌓은 네트워크.
굉장히 적은 수의 parameter로도 좋은 성능을 낸다.
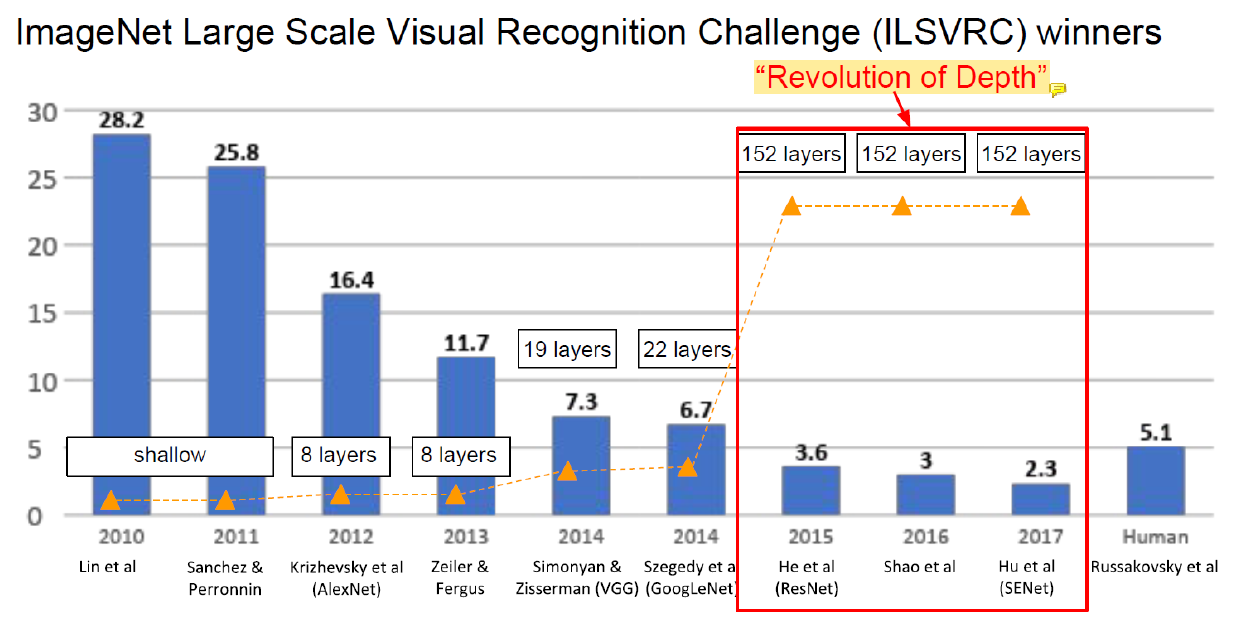 14년도까지는 AlexNet, VGG, GoogLeNet이 중요했다.
14년도까지는 AlexNet, VGG, GoogLeNet이 중요했다.
특히 VGG랑 GoogLeNet은 20층 근처 neural network까지 성공했고 그 이후엔 많은 깊은 network가 생겨났다.
그것을 가능하게 만든 기술이 ResNet에 사용된 기술이다.
ResNet
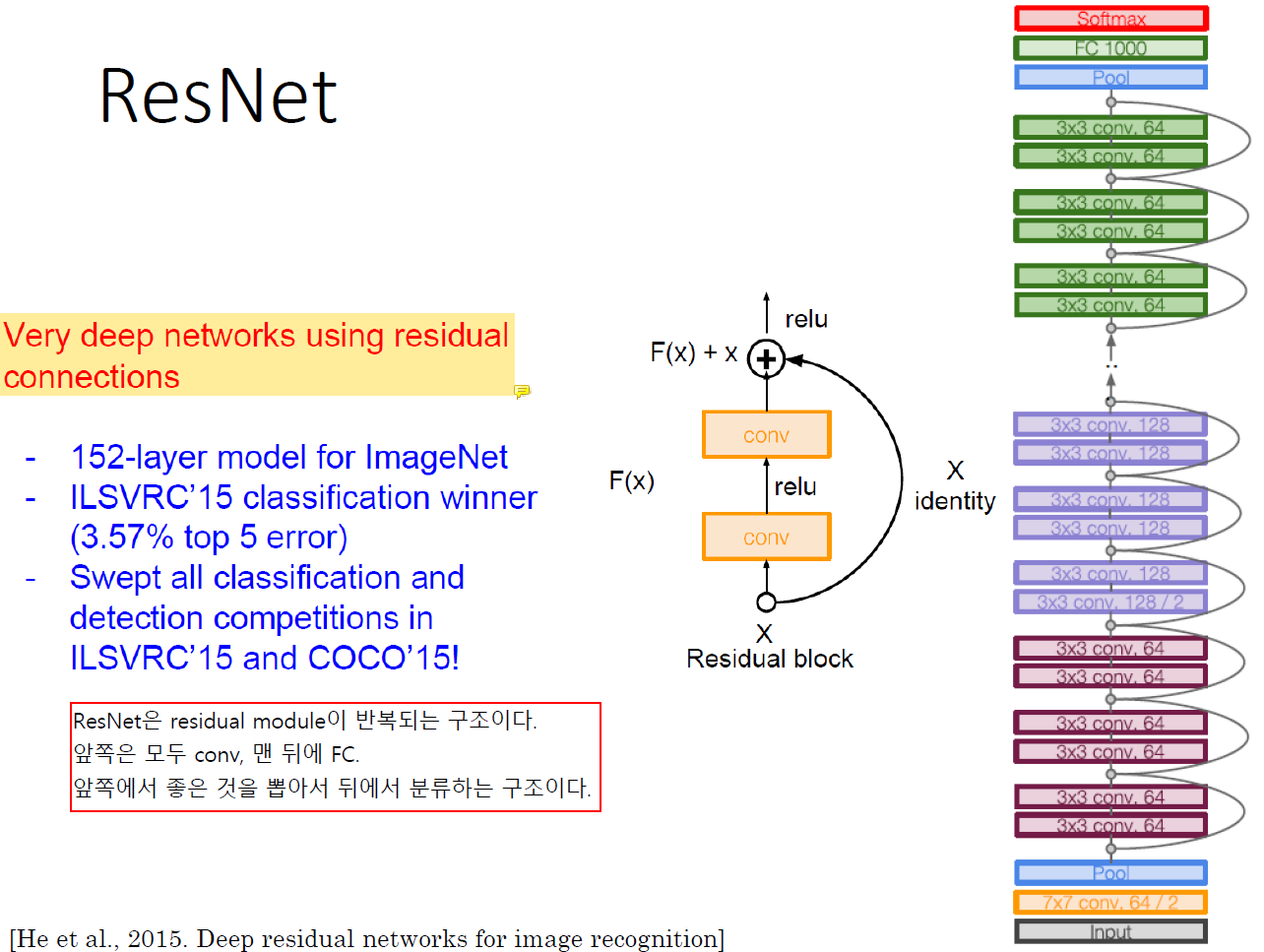 ResNet부터는 nerual network를 deep하게 쌓는 문제는 해결되었다.
ResNet부터는 nerual network를 deep하게 쌓는 문제는 해결되었다.
ResNet은 residual module이 반복되는 구조이다!
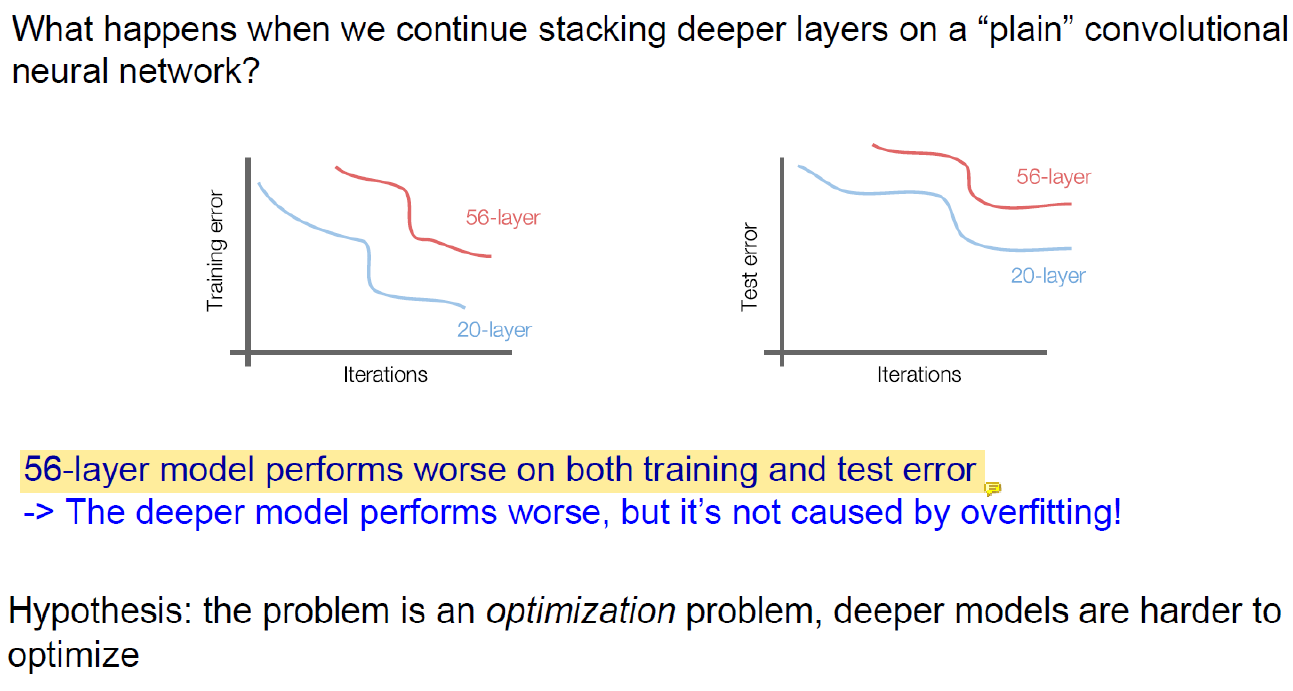 일반 convolutional neural network에서 layer를 깊게 쌓으면 더 분류를 잘 해야하는데 error가 더 많다.
일반 convolutional neural network에서 layer를 깊게 쌓으면 더 분류를 잘 해야하는데 error가 더 많다.
그래서 parameter가 늘어나서 overfitting 문제가 발생한 것이 아닐까 생각했는데 overfitting이면 train set은 엄청 잘 풀어야 하는데 train set도 잘 풀지 못해서 overfitting으로도 설명할 수 없는 현상이었다.
그래서 사람들은 optimization technique이 좋지 않아서 이런 결과가 나왔다고 주장하였다.
더 좋은 optimizer를 만들면 되긴 하지만 그건 검증도 많이 해야하고 어려운 작업이라 새로운 optimizer를 만들기보다 network architecture를 개선하는 쪽으로 생각을 하게 됐다.
그 결과로 나온 것이 residual block이다.
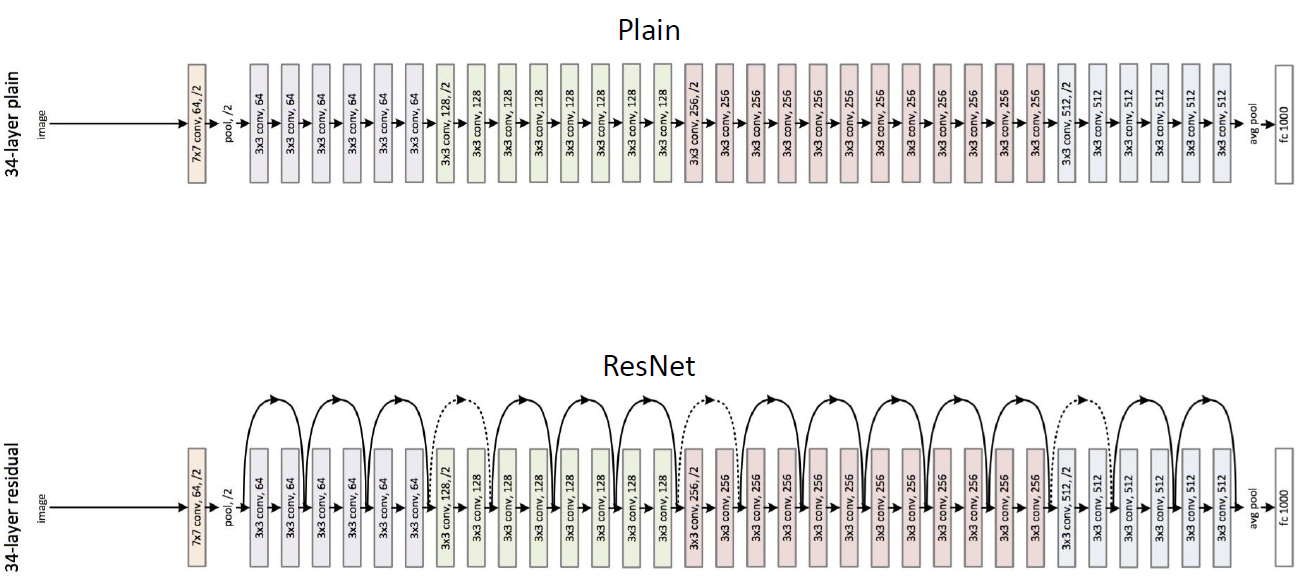
Residual Block
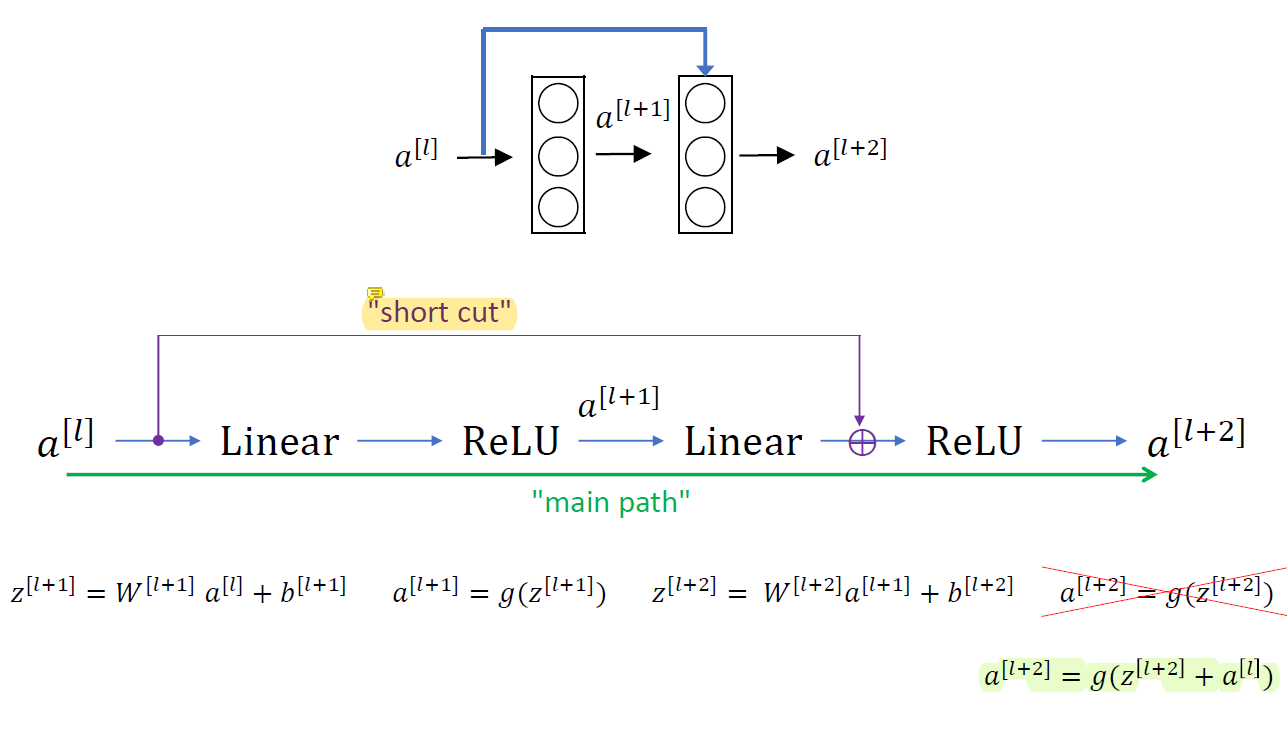 원래는 일반적인 2-layer network인데 앞 쪽의 linear 결과와 두 번째 linear 결과를 더해서 사용한다.
원래는 일반적인 2-layer network인데 앞 쪽의 linear 결과와 두 번째 linear 결과를 더해서 사용한다.
Shortcut을 더해서 second activation의 input을 수정한다.
선형변환결과와 앞 쪽의 정보를 더해서 사용한다.
Residual Network
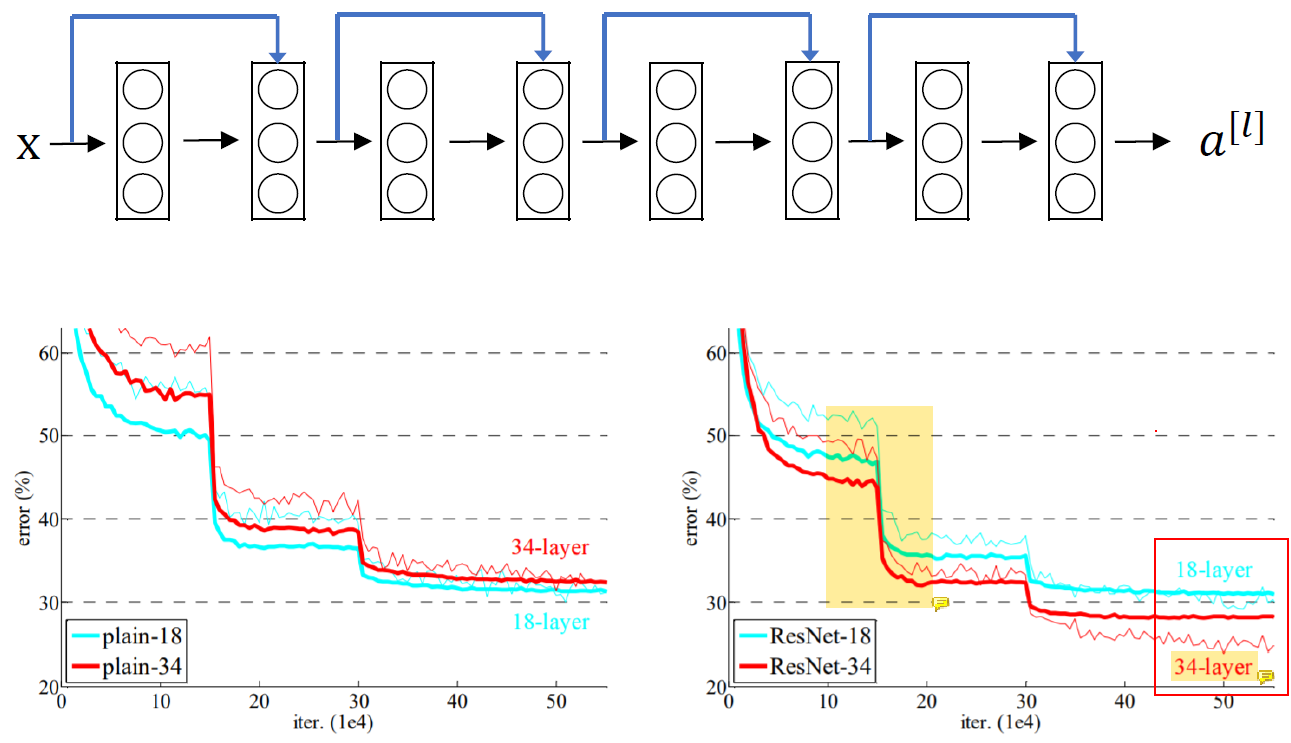 Shortcut을 사용하기만 했는데도 test set의 accuracy가 증가해서 깊은 neural network가 얕은 neural network보다 더 잘 동작하게 되었다.
Shortcut을 사용하기만 했는데도 test set의 accuracy가 증가해서 깊은 neural network가 얕은 neural network보다 더 잘 동작하게 되었다.
Error가 확 낮아지는 구간은 learning rate를 바꾼 것이다.
Learning을 하다가 성능이 더 이상 안좋아진다 싶으면 learning rate를 한 번씩 바꿔주면 error를 감소시킬 수 있다.
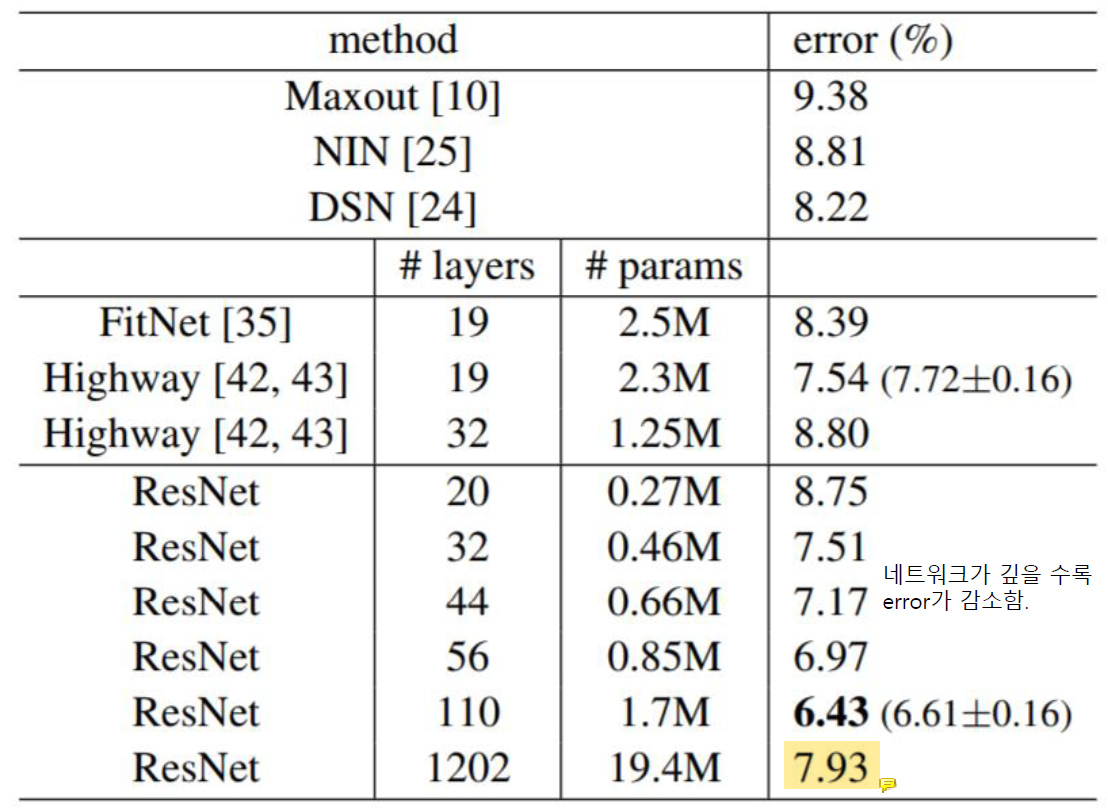 맨 마지막에 error가 살짝 높아진 정도는 overfitting으로 간주한다.
맨 마지막에 error가 살짝 높아진 정도는 overfitting으로 간주한다.

Why Do Residual Networks Work?
 엄청 큰 network에 residual block을 더 붙이는게 도움이 안될 수도 있다.
엄청 큰 network에 residual block을 더 붙이는게 도움이 안될 수도 있다.
만약 도움이 안된다면 convolution layer 2개가 있는데 각 filter들의 값이 전부 0으로 학습이 될 것이다.
그래서 원래 정보는 하나도 잃어버리지 않고 뒤로 가져오고 도움이 되지 않는건 사용하지 않는다.
Residual block은 필요가 없으면 알아서 0으로 학습되어 제거될 것이기 때문에 필요할지 필요하지 않을지 생각하지 않고 자유롭게 사용할 수 있다.
Residual block이 조금이라도 도움이 된다면 parameter가 0.1, 0.2와 같이 학습되면서 더 좋은 결과가 나올 수 있다.
Residual block의 아주 중요한 점은 쓸모가 없을 때도 기존의 정보를 살릴 수 있다는 것이다.
원 정보가 output에 그대로 흘러나온다.
Shortcut이 없었다면 CONV-ReLU-CONV-ReLU를 거쳤을 때 기존과 똑같아지는 identify function을 만드는게 굉장히 힘들다.
특히 ReLU때문에 값이 다 날아가기 때문에 쓸모없는 과정이더라도 원 정보를 보존하기가 굉장히 힘들다.
그런데 shortcut이 있으면 그것을 통해 residual block이 쓸모없을 때 원 정보를 보존하고 필요하면 더 좋은 결과를 낼 수 있는 특성을 가진다.
이러한 특성 때문에 residual block을 굉장히 깊게 붙일 수 있다.
Gradient와 관련해서도 좋은 점이 있다.
큰 network는 backpropagation을 하면서 gradient를 update할 때 계속 곱해져서 구해지니까 gradient가 엄청 크거나 작아지는 vanishing, exploding gardient 문제가 있다.
Gradient가 커서 생기는 문제는 clipping으로 비교적 쉽게 해결할 수 있는데 0으로 가는 gradient는 해결할 수 없다.
그런데 shortcut이 있다면 그냥 곱해져서 구해지는 root도 있지만 별로 곱해지지 않고 오는 강력한 gradient를 구할 수 있기 때문에 vanishing gradient 문제를 피할 수 있다.
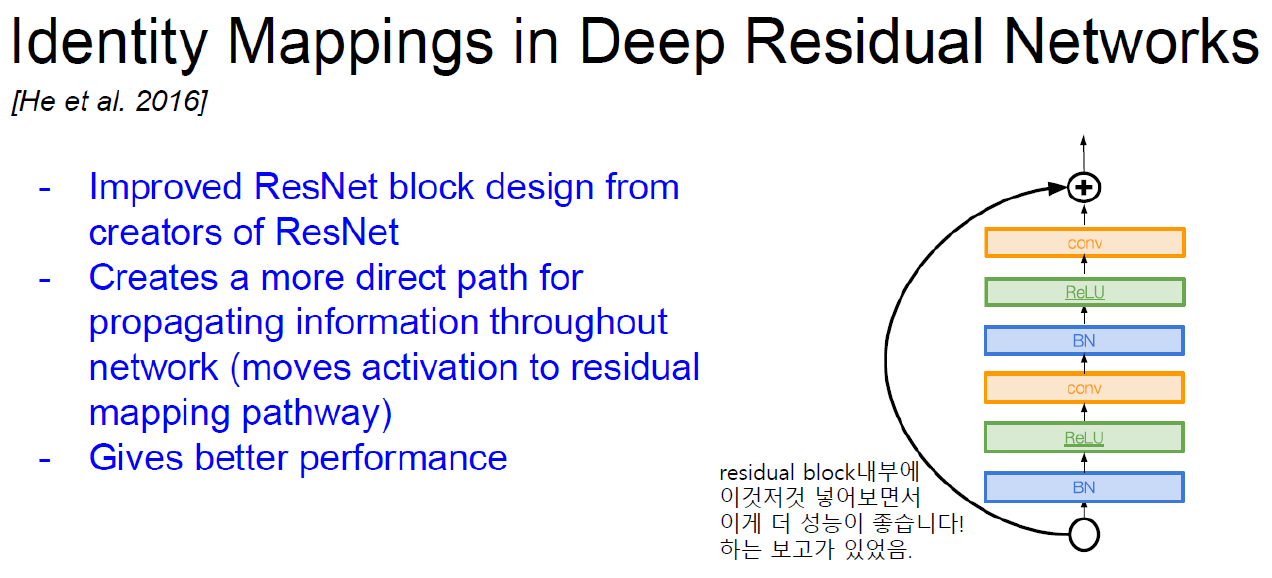
Improving ResNet
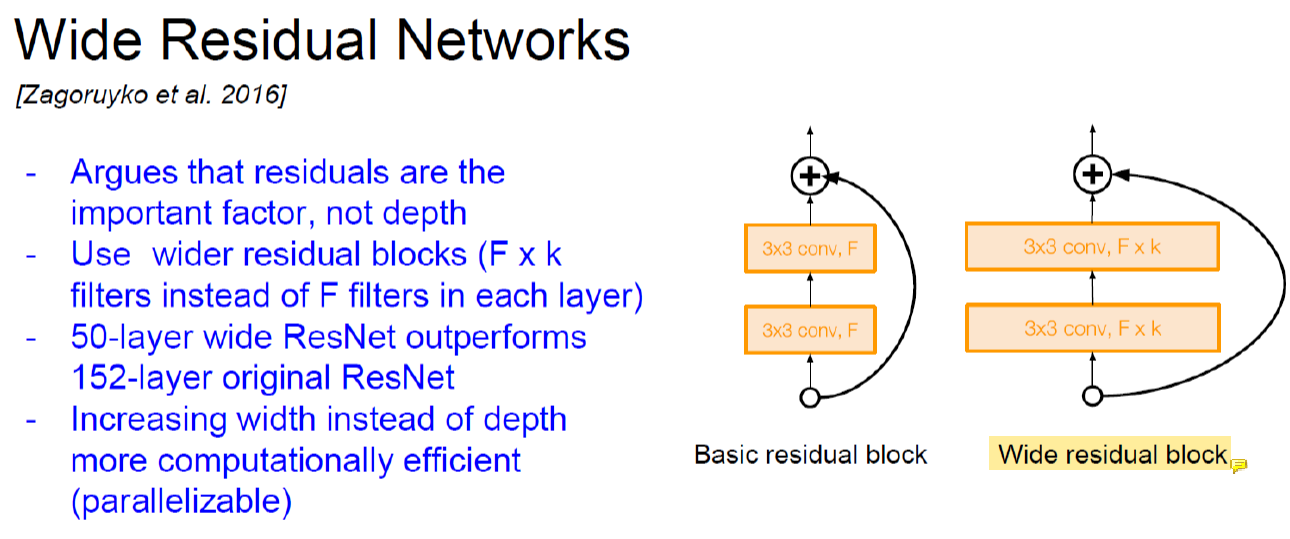
Channel 수가 늘어난 wide residual block이 더 성능이 좋다는 것을 알아냈다.
그런데 channel의 수가 늘어나면 parameter의 수가 늘어나니까 parameter 수를 줄이기 위해 depth를 줄였다.
그래서 무조건 deep하게 가는게 아니라 channel의 size를 늘린다.
Wide block이 들어간 50층짜리 network가 original block만 들어간 150층짜리 network보다 성능이 좋다는 것.
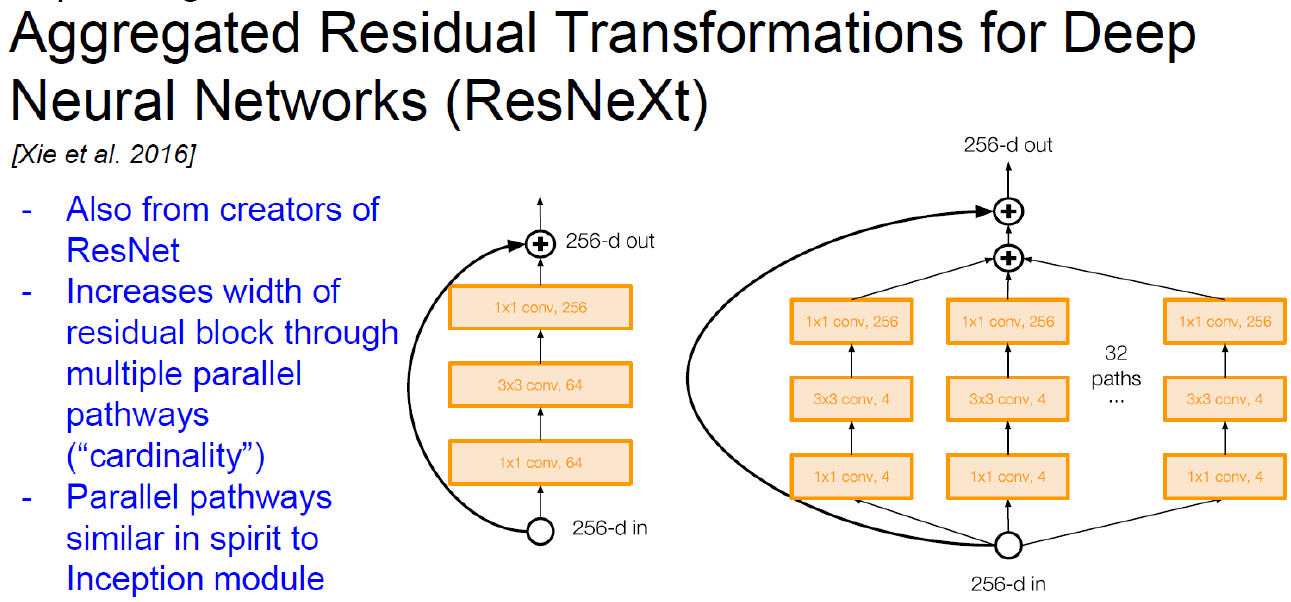
GoogLeNet과 ResNet을 합친 것이다.

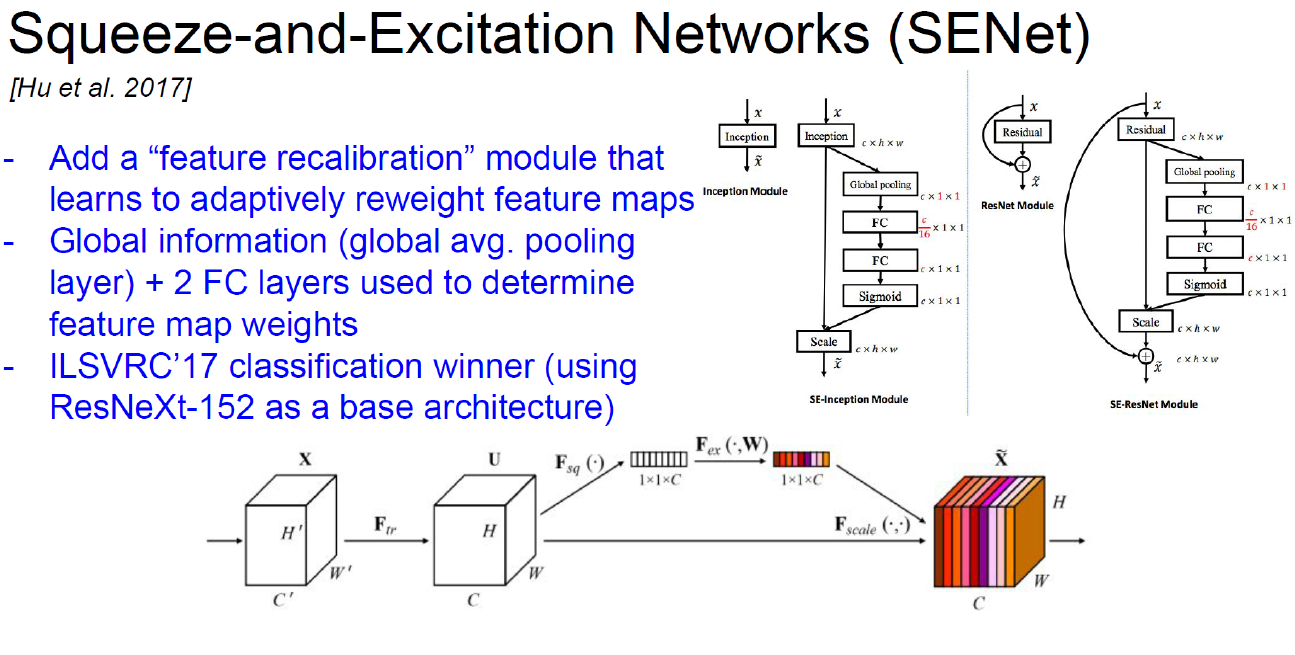
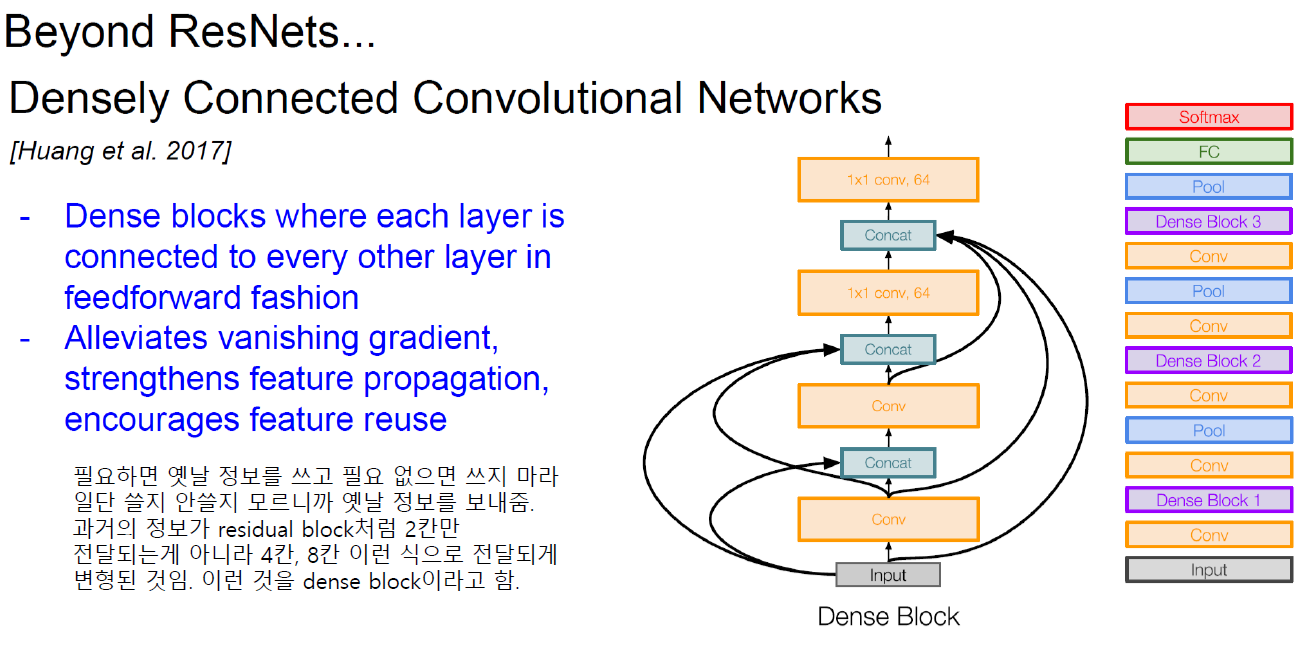
Practical Advices for Using ConvNets
Common Augmentation Method
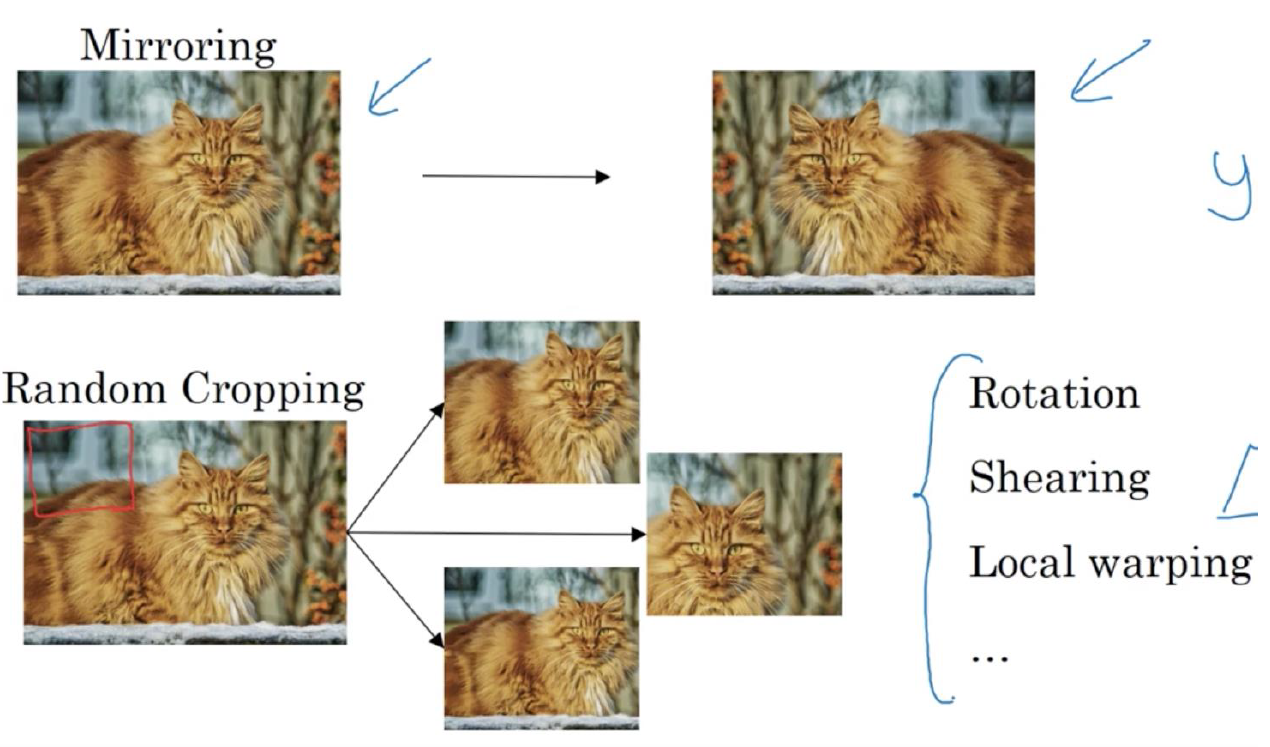
Dataset이 아무리 많아도 augmentation은 무조건 사용한다.
Dataset을 더 많이 가지고 있는 듯한 trick을 쓰는 것이다.
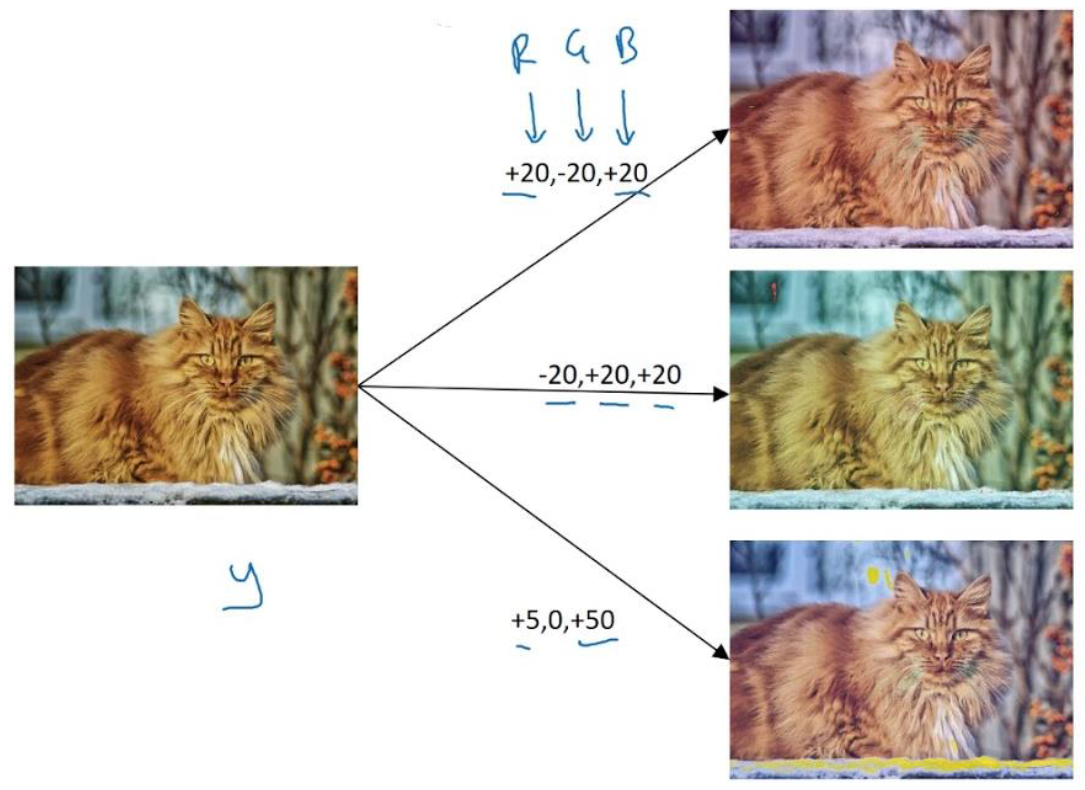
Noise를 더하거나 color를 바꾸거나 하는 방법을 쓸 수도 있다.
신중해야하는게 augmentation이 너무 과하면 안된다.
너무 과해서 고양이가 핑크색이 된다..? 그런 핑크색 고양이는 없는데 dataset으로 그런걸 만든다는건 잘못된 것이다.
실제 있을 법한 것들을 sample로 만들어야 한다.
Color Shifting
Implementing Distortions During Training
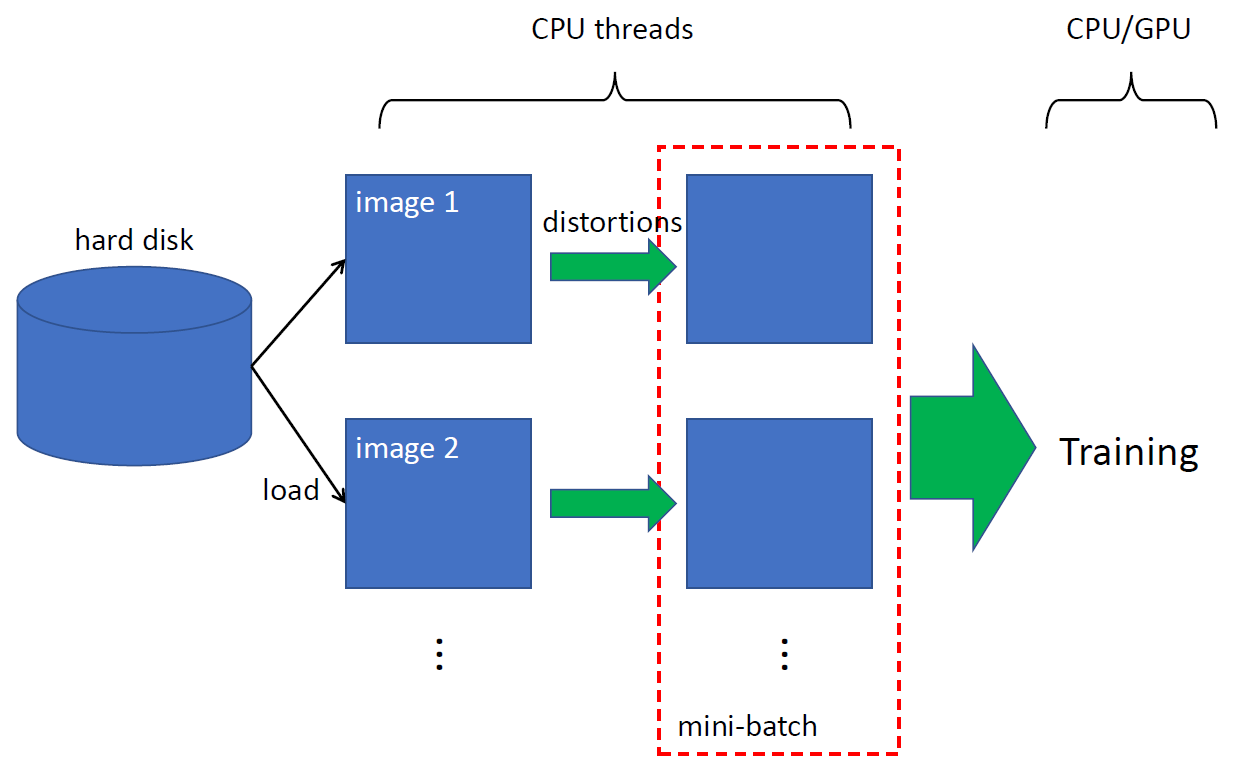
보통 augmentation에 시간이 많이 걸린다.
Batch를 하나를 만들어야 training할 수 있는데 그걸 만드는게 시간이 걸리기 때문에 일주일동안 training 해야 하는데 augmentation에 3일 쓰고 그러면 안되니까 보통은 이런쪽에서 시간을 잡아먹는것을 최소화하기 위해서 multi-threading을 한다.
CPU 여러개 써서 나눠서 image를 augmentation하는 것이다.
그리고 보통 backpropagation은 GPU에서 paralell하게 한다.
GPU가 backpropagation하는동안 CPU가 data sample만들고... 요즘엔 thread 몇개 쓸지만 알려주면 다 알아서 해준다고 한다.
Data VS. Hand Engineering
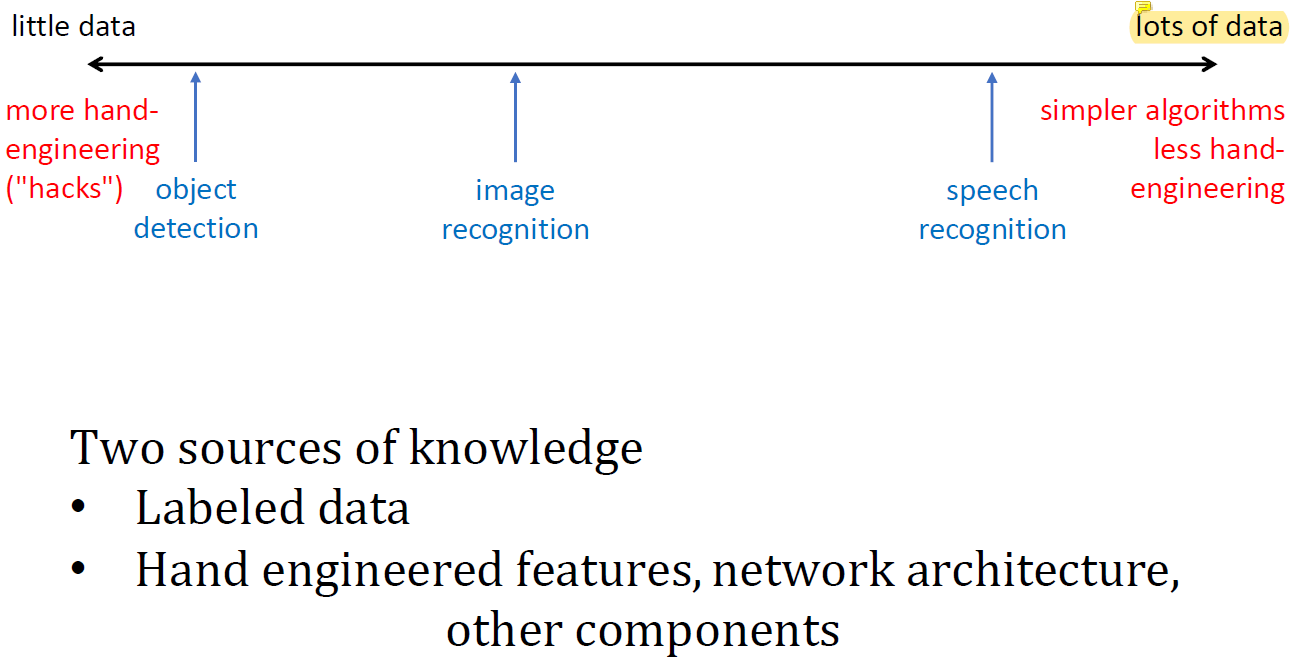
Dataset이 엄청 많으면 그냥 무조건 깊게 하면 어떤 문제든 다 잘 풀릴 수 있는데 application마다 필요한 data의 양이 달라진다.
엄청 쉬운 문제는 data가 별로 필요 없지만 엄청 어려운 문제는 굉장히 많은 data가 필요하다.
Object detection이나 image recognition은 비교적 어려운 문제라 이 문제를 잘 풀려면 많은 data가 필요한데 speech recognition은 비교적 적은 data로도 잘 풀리는 비교적 쉬운 문제이다.
그런데 어려운 문제는 dataset이 부족하니까 최대한 적은 parameter로 최대한 좋은 성능을 내야한다.
쓸 수 있는 parameter의 수에 한계가 있기 때문에 그 안에서 최고의 성능을 내야 하는 것.
근데 data의 수가 엄청 많으면 parameter를 몇 개 쓸지 어떤 방법을 쓸지 고려할 필요가 없다.
Tips For Doing Well On Benchmarks/Winning Competitions

Ensembling은 AlexNet에서 사용하고 있다.
이건 무조건 쓴다고 봐야한다.
다른 network를 100개 가져와서 100개 result의 평균값을 취한다던지 하는 것이다.
이렇게 여러 개의 result를 합쳐서 쓰는 것이 제일 simple한 version이다.
AlexNet의 경우 동일한 AlexNet인데 random seed를 다르게 줘서 training하니까 똑같은 data로 training해도 parameter가 좀 다르다.
그걸 mix해서 최종 결과를 낸다. 시간이 보통 오래 걸린다.
하지만 단기간에 주어진 자원으로 높은 성능을 내야한다면 ensembling을 반드시 써야한다.
거의 반드시 성능이 올라간다.
Multi-crop at test time은 single network를 사용하고 test set을 하나 주고 풀라고 할 때 그것을 여러가지 방법으로 바꾸는 것이다.
Image 하나 주면 그걸 돌리고 어쩌고 해서 각각으로 single network를 사용해서 나온 결과의 평균을 사용하는 것이다.
Use Open Source Code

