
Image Captioning
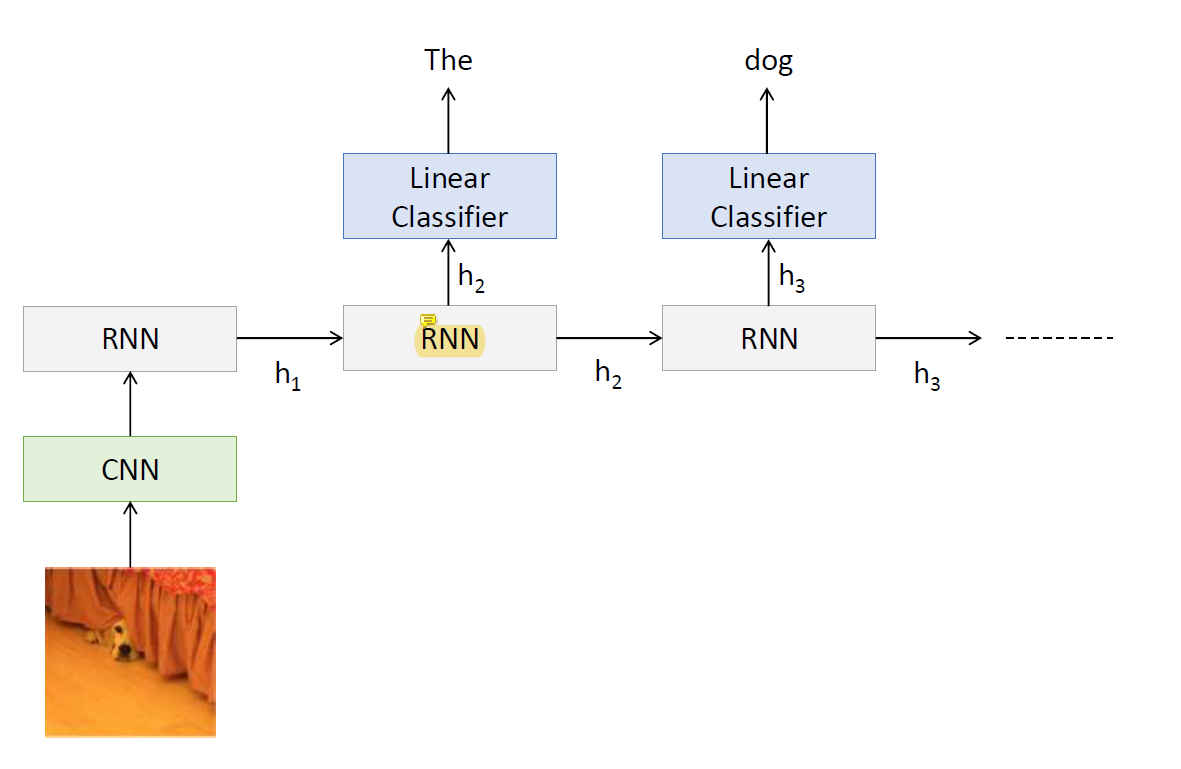
그림에서 먼저 CNN으로 visual information을 뽑고 input의 길이도 바뀔 수 있고 output의 길이도 바뀔 수 있는 시스템이기 때문에 RNN을 사용한다.
Recall: RNN for Captioning
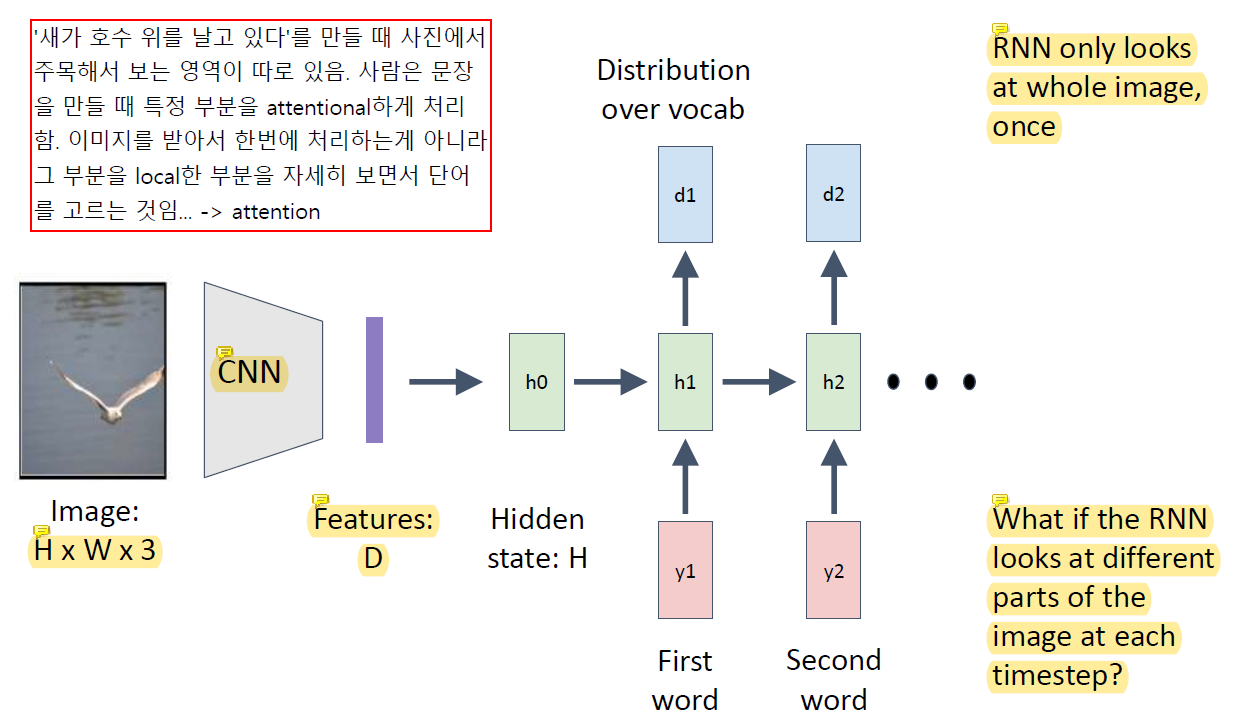
Image 하나와 그 image에 대해 사람이 작성한 sentence가 여러 개 있어서 model이 그 sentence와 유사한 결과를 내도록 learning한다.
이 image의 visual feature를 뽑아내기 위해 이미 새로 모델을 만들기도 하지만 이미 다 학습이 되어있는 CNN을 사용하는 경우가 많음.
주요한 feature를 vector로 뽑아내서 RNN의 input으로 줘서 RNN으로 새로운 모델을 만듦.
RNN은 그냥 그림 받아서 feature 바꾸고 끝이다.
더 잘할순 없을까?
사람은 이 문제를 어떻게 풀까? 사람은 그림 전체를 한번에 보는게 아니라 부분부분 보면서 그 영역과 관련된 word를 뽑아냄. 부분부분만 집중해서 보고 그 때 다른 부분은 잘 안봄. 전체 이미지가 엄청 큰데 내가 만드는 word와는 전혀 상관없는 정보들이 있을 수 있음.
고양이가 누워있는걸 설명해야하는데 고양이와 관련되어있지 않은 주변 물건들은 상관이 없다는거임. 그걸 배제하고 보자는 것임. 근데 그 정보가 언젠가는 필요할 때가 있음. sentence를 만들어야 하니까. 처음에는 이 정보가 필요없지만 중간에는 필요할 수도 있음.
야구 선수들이 나와있고 투수가 공을 던질 준비를 하고 있다. 주변에 관중들이 많이 있다. 근데 처음엔 관중이 중요한게 아니라 투수를 보면서 얘기를 해야하는거임. 그 뒤에 관중이 필요할 때 관중을 보고.
attention이 그런거임. 전체를 다 보는게 아니라 특정 부분을 집중적으로 보는 것. 사람이 하는 것처럼 attention을 하는 network design을 만들 순 없을까 이런거지.
Soft Attention for Captioning
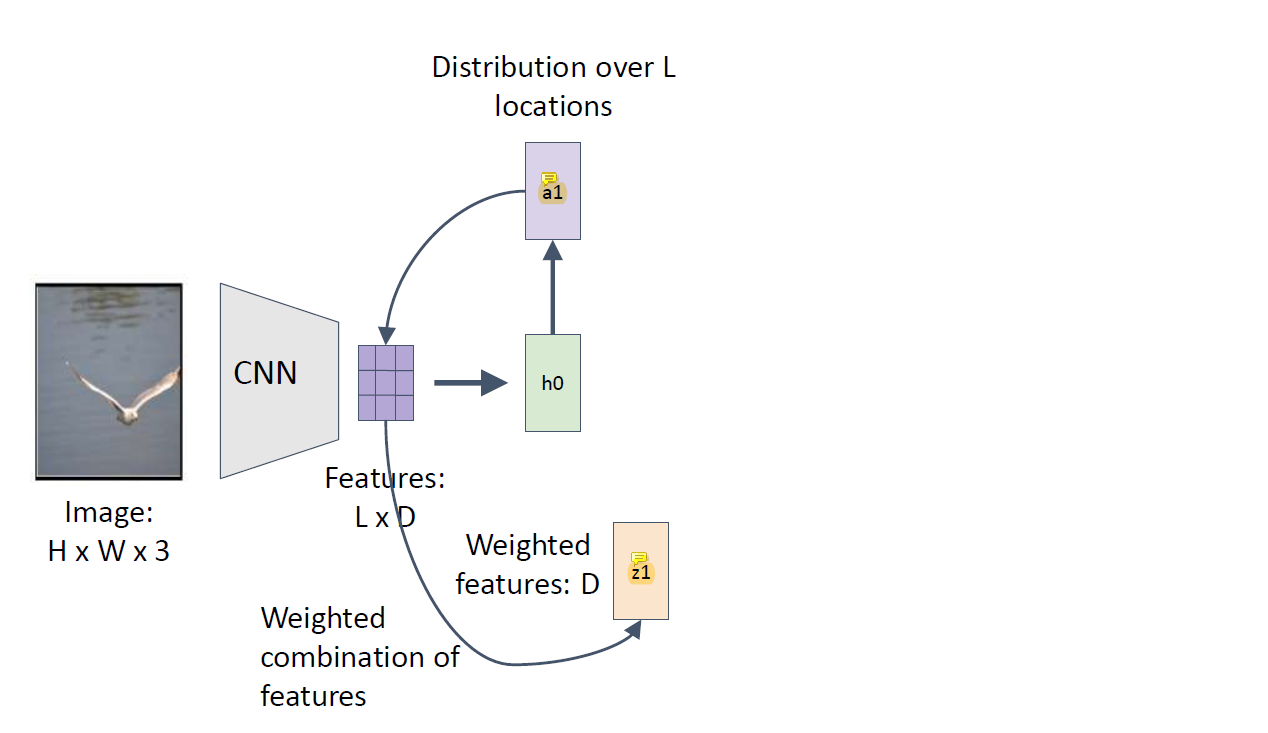
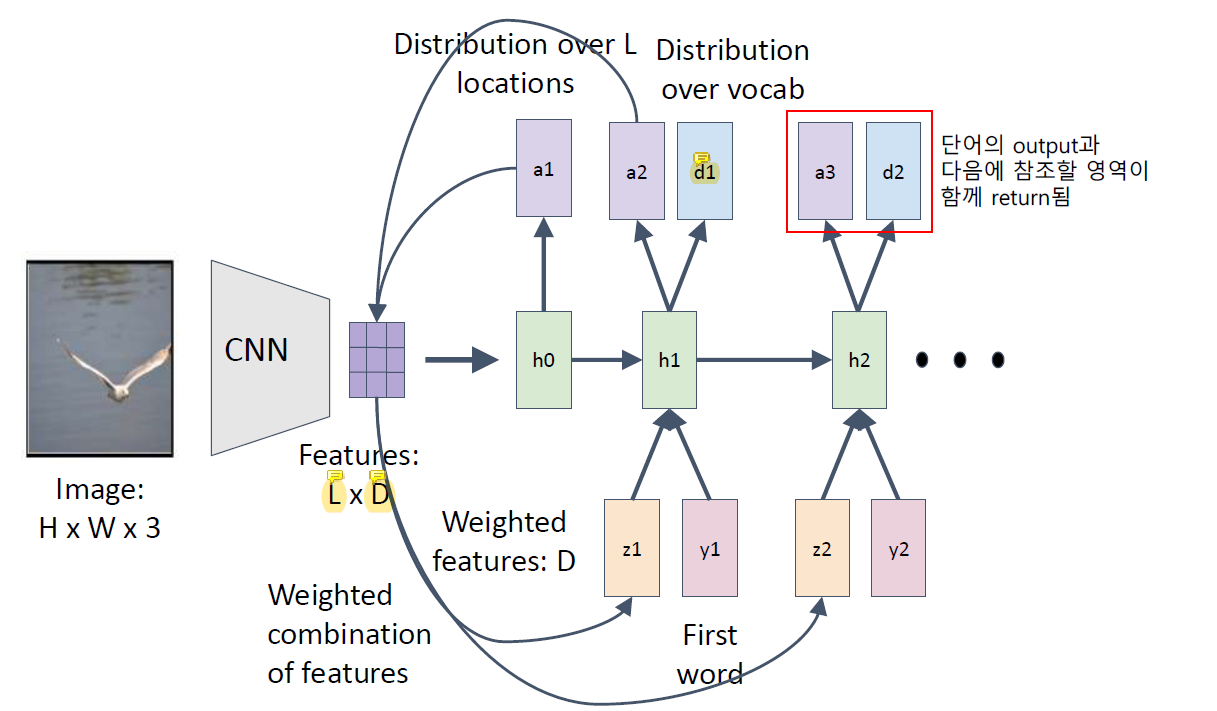
CNN이 전에서 벡터를 return했었는데 전략을 다르게.
Attention에서는 CNN으로 return하는게 vector가 아니라 LxD를 그대로 쓰는데 region을 나눠서 씀. 예전에는 쭉 펴서 벡터로 return 했었는데.
L은 나뉜 영역의 개수이고 D는 채널의 개수이다.
이제는 쭉 펴진 벡터가 아니라 9개의 region으로 나뉘어져있고 그 영역을 다 쓰는게 아니라 매번 그 중 몇 개만 쓰겠다는 것임.
첫 번째 단어를 만들기 위한 region 위치(h0)를 알려주고, 그 결과로 첫번째 단어(a1)와 그 다음에 어떤 위치를 보면서 단어를 만들지의 정보(z1)를 함께 return함.
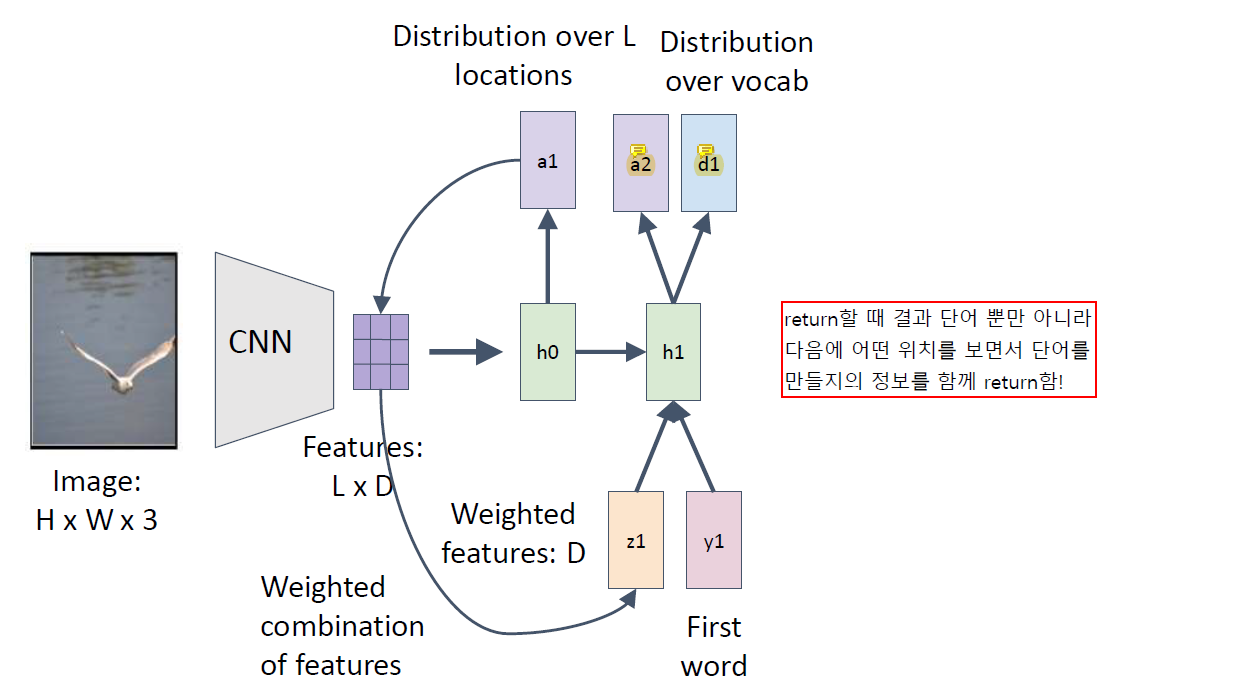
a2는 다음 단어를 만들기 위한 region 정보이고 d1이 결과로 나온 첫 번째 단어이다.
Attention에서는 return할 때 결과 단어와, 다음에 어떤 위치를 보면서 단어를 만들지의 정보를 함께 return한다.
Soft vs Hard Attention
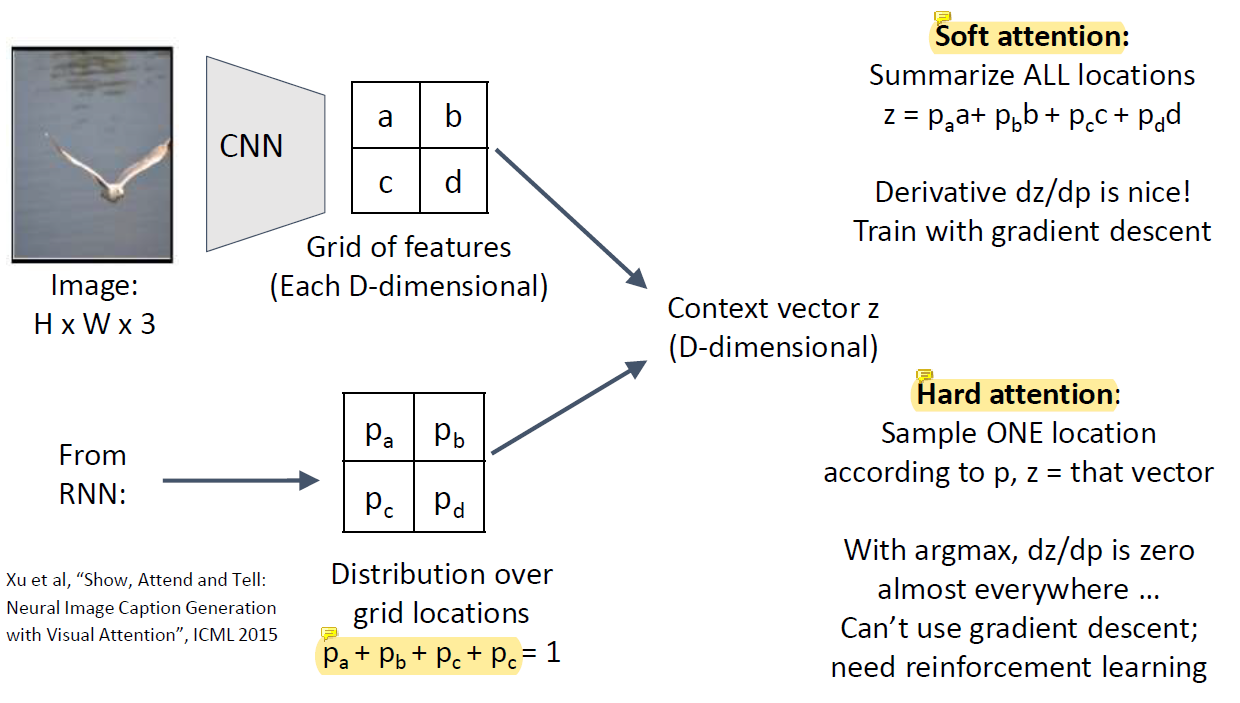
attention하기 싫으면 p의 값을 다 0.25로 만들면 됨.
d만 뽑고 싶다면 0 0 0 1 이런식으로 p값을 조정하는 것임.
이걸 soft하게 하는게 soft attention.
보통 자연스럽게 내버려두면 0, 1 이렇게 딱 떨어지게 값이 안나오고 0.3 이렇게 나올거아냐.
이걸 그냥 0 아니면 1로 만들어버리는게 hard attention임.
영역 중 확률 값이 제일 큰걸 1로 생각해버리는거임.
0.3 이 나온 값 중 최대면 그걸 1로 생각하겠다 이런거임.
Soft attention은 어떤 영역이 완전히 0이 되기가 힘들어서 상대적으로 덜 필요한 정보도 조금씩 섞여들어가는데 대신 계산이 쉬움.
Hard attention은 가장 큰 하나의 x만 취하는건데 이건 미분이 안됨.. 바람직한데 미분이 안돼서 쉽지않음.
미분이 안되는 애가 있는건 neural network의 중간이 끊어지는거임... backpropagation으로 학습이 불가능해서 다른 전략이 필요한데 그 중 하나가 argmax.
