IRL 이란?
-
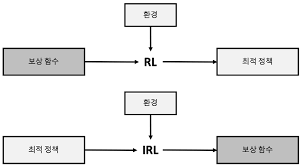
Inverse Reinforcement Learning (IRL, 역강화학습)은 강화학습(Reinforcement Learning)의 반대 방향으로 수행되는 학습 방식입니다.
-
일반적인 강화학습에서는 에이전트가 주어진 보상 함수에 따라 최적의 정책(행동 전략)을 학습합니다.
-
반면, 역강화학습은 행동 데이터를 기반으로 보상 함수를 추정하는 과정을 말합니다.
-
즉, IRL은 "사람이나 전문가의 행동을 관찰한 뒤, 그 사람이 따르고 있는 보상 함수를 역으로 학습"하거나 "해당 보상을 기준으로 최적의 행동을 유도"하는 과정입니다.
-
- IRL은 보상 설계를 자동화하거나 전문가의 행동 패턴을 학습하는 데 매우 유용하며, 특히 로봇, 자율주행, 의료, 게임 등 다양한 산업에서 중요한 역할을 합니다.
왜 IRL을 사용하는가?
-
보상 함수는 강화학습 모델의 성능을 결정짓는 핵심 요소입니다. 하지만 많은 상황에서 적절한 보상 함수를 직접 설계하기 어려운 경우가 있습니다.
-
예시
-
자율주행차에서 운전자의 의도를 이해하거나 따르는 행동.
-
로봇이 작업자의 자연스러운 행동을 학습해서 작업을 보조하도록 만드는 경우.
-
인간의 복잡하고 미묘한 행동 패턴(예: 사회적 규범)을 모델링할 때.
-
-
이런 상황에서 IRL은 다음과 같은 장점을 제공
-
직접 보상을 정의하지 않아도 전문가나 인간의 행동 데이터를 통해 보상 구조를 추론할 수 있음.
-
인간의 의도나 행동 패턴을 이해하고 재현하는 데 적합함.
-
IRL의 기본 아이디어
-
IRL의 주요 목표는 다음과 같습니다.
-
전문가의 행동을 관찰
-
원하는 행동이나 작업을 이미 잘 수행하는 전문가(사람 또는 시스템)의 데이터를 관찰합니다.
-
예: 뛰어난 운전자가 내리는 결정이나 행동(운전 경로, 속도 변화 등).
-
-
잠재적인 보상 함수 추정
-
전문가의 행동을 설명할 수 있는 보상 함수를 역으로 추정합니다.
-
이 보상 함수는 전문가가 특정 상황에서 행동하는 이유를 나타냅니다.
-
-
보상 함수를 이용해 최적 정책 학습
- 보상 함수가 추정되었으면, IRL 또는 강화학습을 활용해 최적의 행동 정책을 구축합니다.
-
"전문가가 왜 그렇게 행동했는지"를 나타내는 보상 구조를 바탕으로 최적의 행동 패턴을 배우는 것이 IRL의 핵심입니다.
IRL과 강화학습(RL)의 차이
| 항목 | 강화학습 (RL) | 역강화학습 (IRL) |
|---|---|---|
| 입력 | 보상 함수 | 행동 데이터 |
| 출력 | 최적 정책 | 보상 함수 |
| 핵심 목표 | 주어진 보상을 극대화하는 최적의 행동 학습 | 전문가의 행동을 설명하는 보상 학습 |
IRL의 알고리즘
- IRL을 구현하는 데는 여러 알고리즘이 존재합니다. 대표적인 방법은 다음과 같습니다.
-
MaxEnt IRL (Maximum Entropy IRL)
-
보상 함수를 추정할 때, 최대 엔트로피 원리를 사용해 행동의 불확실성을 모델링합니다.
-
전문가의 행동을 보상 기반으로 최대한 설명하면서도 불확실성을 유지합니다.
-
-
Apprenticeship Learning
- 전문가의 행동을 모방하기 위한 학습 방식으로, 라그랑주 승수를 활용하여 보상을 간접 학습합니다.
-
GAN-based IRL
-
Generative Adversarial Networks(GANs)를 이용해, 생성기와 판별기 사이의 경쟁 관계를 활용하여 IRL을 수행합니다.
-
이 방식은 특히 복잡한 행동 모델링에 적합합니다.
-
응용 분야
-
자율주행
- 사람의 운전 패턴을 학습하여, 안전하고 자연스러운 자율주행 행동을 설계.
-
로봇공학
- 전문가의 작업 행동을 학습해 로봇이 비슷한 작업을 수행할 수 있도록 최적화.
-
의료 분야
- 의사의 치료 패턴을 관찰하고, 최적의 치료 방식을 자동으로 학습하도록 설계.
-
게임 인공지능
- 사람처럼 행동하는 NPC(Non-Playable Characters)를 설계하거나, 플레이어의 행동 의도를 학습.
-
사회적 행동 모델링
- 군중의 행동, 사회적 규범, 의사결정을 이해하고 시뮬레이션.
한계
-
데이터의 질 의존
- 전문가의 행동 데이터가 부정확하거나 품질이 낮다면, 학습된 보상 함수 또한 잘못된 결과를 초래할 수 있습니다.
-
계산 비용
-
IRL은 강화학습보다 계산 비용이 훨씬 높고 복잡합니다.
-
보상 함수를 추정한 뒤 최적 정책을 학습하는 추가 단계가 필요하기 때문.
-
-
보상 함수의 다중성
- 여러 보상 함수가 같은 행동을 설명할 수 있는 경우가 많아, 보상 함수 추정의 정밀도가 떨어질 수 있음.
