1. 파운데이션 모델(foundation model) 이란?
-
파운데이션 모델은 인공지능 분야에서 최근 주목받고 있는 강력한 머신러닝 모델을 지칭하는 용어입니다.
-
이러한 모델은 대량의 데이터로 학습되어 다양한 작업에 활용될 수 있는 범용적인 능력을 보유한 것이 특징입니다.
-
파운데이션 모델의 핵심 특성과 장점
-
대규모 학습
- 파운데이션 모델은 대규모의 데이터셋을 사용하여 학습됩니다. 이를 통해 다양한 패턴과 정보를 포괄적으로 이해할 수 있도록 설계되어 있습니다. 이러한 학습 과정에서 모델은 언어, 이미지, 소리 등 다양한 형태의 데이터에서 복잡한 특성을 학습할 수 있습니다.
-
전이 학습 (Transfer Learning)
-
파운데이션 모델은 학습된 지식을 다양한 특정 작업에 쉽게 전이할 수 있습니다.
-
즉, 모델은 기초적인 대량의 데이터에 대한 학습 경험을 바탕으로 새로운 작업에서도 적은 데이터로도 높은 성능을 발휘할 수 있습니다.
-
이를 통해 특정 문제에 대한 맞춤형 모델을 구축하는 것이 용이해집니다.
-
-
-
다양한 응용
-
파운데이션 모델은 자연어 처리(NLP), 이미지 인식, 음성 인식 등 다양한 분야에 적용될 수 있습니다.
-
예를 들어, GPT-3와 같은 언어 모델은 텍스트 생성, 번역, 요약, 질문 답변 등 다양한 응용 프로그램에서 활용됩니다.
-
-
복잡한 문제 해결
- 이러한 모델은 인간 언어의 미묘한 차이, 문맥 이해, 상식적 추론 등과 같은 복잡한 문제도 다룰 수 있습니다.
-
규모와 효율성
-
최신 파운데이션 모델은 점점 더 커지고 있지만, 훈련과 추론에서도 효율성을 개선하는 연구가 진행되고 있습니다.
-
모델의 크기로 인해 발생하는 계산 비용과 자원 소모 문제를 해결하기 위한 방법들이 계속 개발되고 있습니다.
-
-
-
대표적인 예로는 OpenAI의 GPT 시리즈, Google의 BERT, Vision Transformer(ViT) 등이 있으며, 이러한 모델들은 자연어 처리뿐만 아니라 컴퓨터 비전 분야에서도 활발히 활용되고 있습니다.
-
파운데이션 모델은 연구 및 산업 분야에서 AI의 활용 가능성을 크게 확장시키며, 다양한 분야에서 혁신을 이끌고 있습니다.
- 그러나 이와 동시에 윤리적 문제나 책임 있는 AI 사용에 대한 고민도 함께 필요합니다.
1956년에 마일즈 데이비스 퀸텟(Miles Davis Quintet)은 프레스티지 레코드 사의 스튜디오에서 라이브 연주를 녹음하고 있었습니다.
엔지니어가 다음 곡의 제목을 묻자 데이비스는 “일단 연주를 해봐야 뭐가 될지 안다”고 쏘아붙였다고 하죠.
이 다작의 재즈 트럼펫 연주자 겸 작곡가가 그랬듯 오늘날의 연구자들도 엄청난 속도로 AI 모델들을 생성하며 새로운 아키텍처와 활용 사례를 탐구합니다. 자신은 새 분야의 개척에 집중하면서 범주화 작업은 다른 이들의 손에 맡기기도 하는데요.
- 100명이 넘는 스탠퍼드 연구자로 구성된 팀이 이 작업을 맡아 2021년 여름에 214페이지 분량의 논문을 발표했습니다.
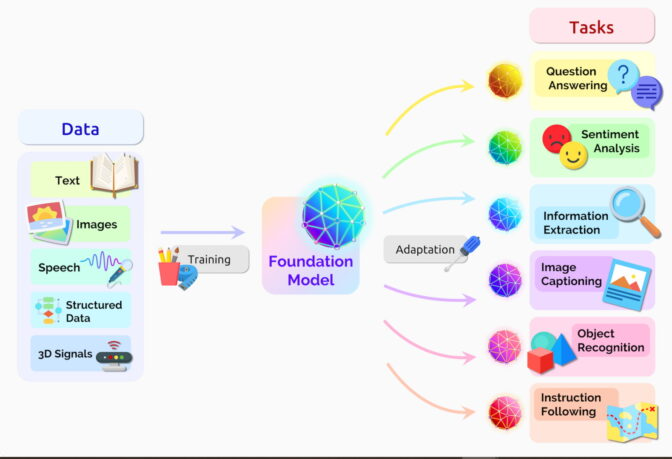
- 이 논문에서 연구자들은 트랜스포머(transformer) 모델과 대규모 언어 모델(LLM), 구축이 계속되고 있는 기타 신경망들이 일명 파운데이션 모델(foundation model)이라는 새롭고 중요한 범주를 구성한다고 분석했습니다.
-
논문에 따르면 파운데이션 모델은 산더미 같은 원시 데이터에서 대개 비지도 학습(unsupervised learning)을 통해 훈련된 AI 신경망으로, 광범위한 작업에 응용이 가능합니다.
- 연구자들은 “지난 몇 년 동안 발전을 거듭한 파운데이션 모델의 규모와 범위가 우리 상상력의 한계를 지속적으로 넓혀 왔다”고 평가했습니다.
-
파운데이션 모델을 정의하는 두 가지 개념
-
더 쉬운 데이터 수집
-
지평선만큼 광활한 가능성
-
노 레이블링, 무한한 가능성
-
파운데이션 모델은 일반적으로 레이블(label)이 없는 데이트세트로 학습하므로 대규모 컬렉션에서 각각의 항목을 수동으로 분류하는 데 드는 시간과 비용을 절약할 수 있습니다.
-
초기의 신경망은 구체적인 작업에 맞춰 협소하게 조정되어 있습니다.
- 약간의 미세 조정을 통해 텍스트 번역에서 의료 이미지 분석에 이르는 다양한 작업을 처리할 수 있게 됩니다.
-
파운데이션 모델 연구 센터의 웹사이트에 게시한 글에서 연구팀은 파운데이션 모델이 “인상적인 양상”을 보이며 규모별로 배포되고 있다고 전했습니다.
-
센터의 연구자들이 공개한 파운데이션 모델 관련 논문만 벌써 50개가 넘습니다.
-
센터의 책임을 맡고 있는 퍼시 리앙(Percy Liang)은 첫 파운데이션 모델 워크숍에서 “미래의 파운데이션 모델이 가진 가능성은 고사하고 기존의 파운데이션 모델이 가진 역량 중에서도 극히 일부만이 조명되고 있을 뿐”이라고 말했습니다.
-
AI의 출현과 균질화
-
출현(Emergence)은 파운데이션 모델의 여러 초기 기능처럼 아직 규명이 한창인 AI 기능들을 뜻합니다.
-
균질화(homogenization)은 AI 알고리즘과 모델 아키텍처의 혼합을 뜻합니다.
- 이는 파운데이션 모델의 형성에 도움이 된 하나의 트렌드이기도 합니다(아래 도식 참고).
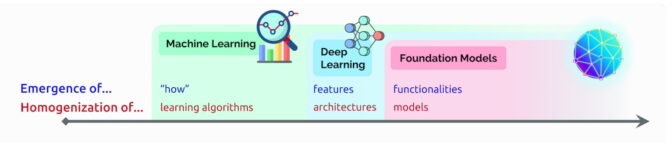
- 이는 파운데이션 모델의 형성에 도움이 된 하나의 트렌드이기도 합니다(아래 도식 참고).
-
스탠퍼드 팀이 파운데이션 모델을 정의하고 1년 뒤에 또다른 테크놀로지 전문가들이 생성형 AI(generative AI)라는 용어를 만들었습니다.
-
생성형 AI는 텍스트와 이미지, 음악, 소프트웨어로 사람들의 상상력을 캡처하는 트랜스포머 모델과 대규모 언어 모델 등의 신경망을 포괄적으로 일컫는 용어입니다.
-
벤처 기업인 세쿼이아 캐피탈(Sequoia Capital)의 경영진은 최근 AI 팟캐스트(AI Podcast)에 출연해 생성형 AI가 수조 달러 규모의 경제적 가치를 창출할 잠재력을 가졌다고 설명했습니다.
-
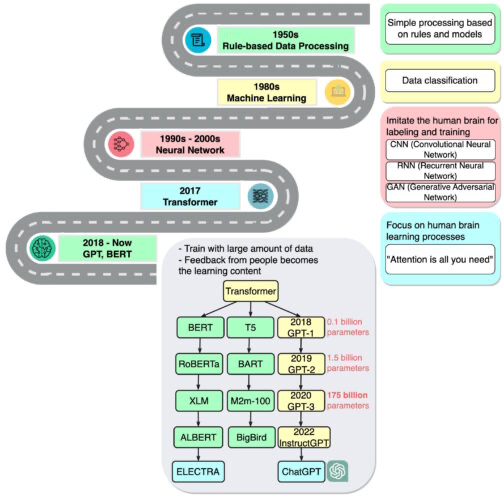
2. 파운데이션 모델의 역사
-
구글 브레인의 수석 연구원으로 2017년 트랜스포머 논문의 연구를 이끈 아시시 바스와니(Ashish Vaswani)는 지금 우리가 “신경망과 같은 간단한 기법이 새로운 가능성의 폭발로 이어지는 시대에 살고 있다”고 말합니다.
-
바스와니 팀의 연구는 BERT 등의 대규모 언어 모델에 영감을 주었고, AI 관련 논문의 표현을 빌리자면 ‘2018년을 자연어 처리의 분수령으로’ 만들었습니다.
-
구글이 BERT를 오픈 소스 소프트웨어로 출시했고, 이는 후속 제품군의 탄생으로 이어졌으며, 더 크고 강력한 언어 모델을 구축하기 위한 경쟁이 시작됐습니다.
-
다음으로 구글은 BERT 테크놀로지를 검색 엔진에 적용해 사용자가 간단한 문장의 형태로 질문할 수 있게 했죠.
-
-
2020년에 오픈AI(OpenAI)의 연구진은 또 하나의 기념비적인 트랜스포머 모델인 GPT-3를 발표했습니다. 이 모델은 곧장 시와 프로그램, 노래와 웹사이트 등의 구축에 활용되기 시작했습니다.
-
해당 연구진은 논문에서 “언어 모델은 다양하고 유익한 애플리케이션으로 사회에 기여한다”고 평가했습니다.
-
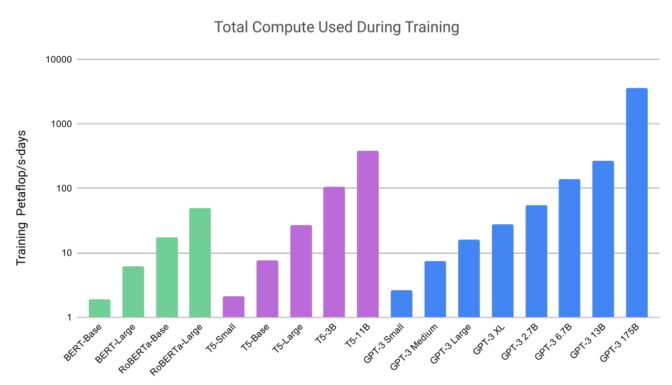
오픈AI의 연구는 또한 트랜스포머 모델들이 얼마나 크고 연산 집약적일 수 있는지 보여줬습니다.
- GPT-3는 1조 개에 가까운 단어를 포함한 데이터세트로 훈련되었고, 신경망의 성능과 복잡성을 측정하는 핵심 척도인 파라미터의 수가 무려 1,750개에 달합니다.
-
가장 최근의 ChatGPT는 NVIDIA GPU 1만 개로 훈련했으며, 두 달만에 1억 명 이상의 사용자를 확보하는 저력을 보여줬습니다. 이 모델의 출시는 관련 테크놀로지의 활용법을 많은 이들에게 선보였다는 점에서 ‘아이폰 모멘트(iPhone moment)’라고도 불립니다.
-
텍스트에서 이미지로
-
ChatGPT가 데뷔하던 즈음, 또다른 차원의 신경망인 확산 모델(diffusion model)이 큰 인기를 끌었습니다.
- 텍스트로 된 설명을 예술적인 이미지로 바꾸는 확산 모델은 놀라운 이미지들로 소셜 미디어에서 입소문을 타면서 일반 사용자와도 친숙해졌습니다.
-
확산 모델을 다룬 최초의 논문은 2015년에 조용히 발표됐습니다. 하지만 트랜스포머 모델들이 그랬듯 이 기법도 이내 열광적인 관심에 휩싸였죠.
-
옥스퍼드 대학에서 AI를 연구하는 제임스 손턴(James Thornton)에 따르면 작년 한 해에만 200개가 넘는 확산 모델 관련 연구가 발표됐습니다.
-
미드저니(Midjourney)의 데이비드 홀즈(David Holz) CEO는 트위터에 게시한 글에서 자사의 확산 모델 기반 텍스트 이미지 변환 서비스가 440만 명 이상의 사용자를 보유하고 있다고 밝혔습니다.
-
그는 한 인터뷰(로그인 필요)에서 이 서비스의 AI 추론에 1만 개 이상의 NVIDIA GPU가 활용된다고 말한 바 있습니다.
-
활발한 사용
-
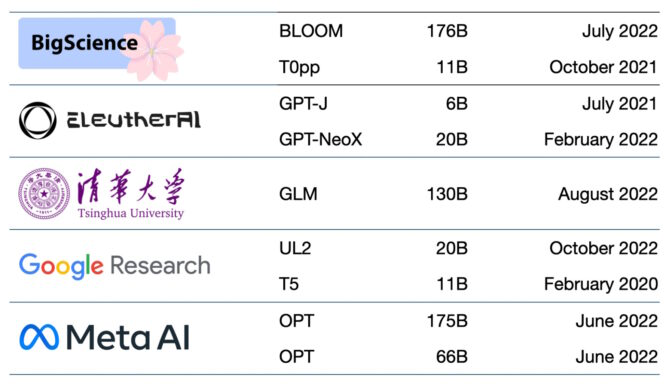
지금 사용이 가능한 파운데이션 모델은 수백 개에 달합니다. 한 논문에서 목록화하고 분류한 주요 트랜스포머 모델은 50개가 넘습니다(아래 표 참고).
-
스탠퍼드 연구팀은 30개의 파운데이션 모델을 벤치마킹하면서 관련 분야의 진화가 너무 빨라 새롭고 눈에 띄는 일부 모델은 검토하지 않겠다고 밝히기도 했습니다.
-
최첨단 스타트업을 육성하는 NVIDIA Inception 프로그램의 회원인 NLP 클라우드(NLP Cloud)는 항공사와 약국 등에 제공하는 상용 서비스에 25개의 언어 모델을 사용하고 있습니다.
- 전문가들은 더 많은 수의 파운데이션 모델들이 허깅 페이스(Hugging Face)의 모델 허브 같은 사이트에서 오픈 소스로 만들어질 것이라 내다보고 있습니다.
-
파운데이션 모델들 또한 규모와 복잡성이 증가하고 있습니다.
- 이를 극복하고자 많은 기업들은 새로운 모델을 아예 처음부터 구축하기보다 커스터마이징을 마친 사전 훈련 파운데이션 모델을 도입해 AI로의 여정을 가속하고 있습니다.