algorithm
1.[Lv2][카카오 코딩테스트]오픈채팅방

문제 풀기아이디 정보는 dictionary에서 update하면 편함.출력 기록을 순서를 반영해서(list) 미리 만들어놓되, 닉네임이 아닌 아이디로 만들어 놓고 마지막에 최신 정보가 담긴 dictionary로부터 리스트에 있는 id정보를 닉네임정보로 바꿈.
2.[코딩테스트]Dynamic Programming
문제 풀기(https://www.welcomekakao.com/learn/courses/30/lessons/42895dynamic programming을 활용하는 문제입니다~!사용횟수가 1 일때, 사용횟수가 2 일 때 경우의 수들을 정리해 보는것이 첫번째 아이
3.[코딩테스트][Lv2] 2018 카카오 '프렌즈4블록' 문제 해설
문제 풀기list element의 용이한 삭제를 위해, 행과 열을 전치한 후 시작블록이 터져야 할 부분은 index를 set에 저장(중복 방지) 후 0으로 변경0 개수를 count한 후, 앞(위쪽)으로 재배치. '\_'로 변경 후 2번 과정 반복answer에 loop:
4.[코딩테스트][Lv1] 프로그래머스 '모의고사' 문제 해설 (stack,queue)
문제 링크두 list로부터 hashing을 이용하여 완주하지 못한 1명의 선수를 return하는 문제.{% gist crosstar1228/86ab2d292ea7dce38da70b41b506d781 %}단순히 completion 리스트를 확인하고 participatio
5.[코딩테스트][Lv1]프로그래머스 완주하지못한선수
문제 링크두 list로부터 hashing을 이용하여 완주하지 못한 1명의 선수를 return하는 문제.{% gist crosstar1228/86ab2d292ea7dce38da70b41b506d781 %}단순히 completion 리스트를 확인하고 participatio
6.[코딩테스트][Lv2]뉴스클러스터링(프로그래머스 카카오 기출)
문제 풀기중복집합에 대한 개념을 dictionary 개수와 key 교집합, 차집합, 합집합 그리고 min max로 해결하였다.
7.[알고리즘]Graph, BFS와 DFS
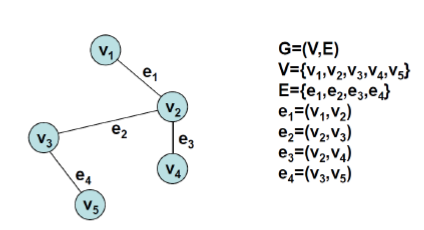
d
8.[자료구조]시간복잡도(Time Complexity)와 알고리즘, 자료구조
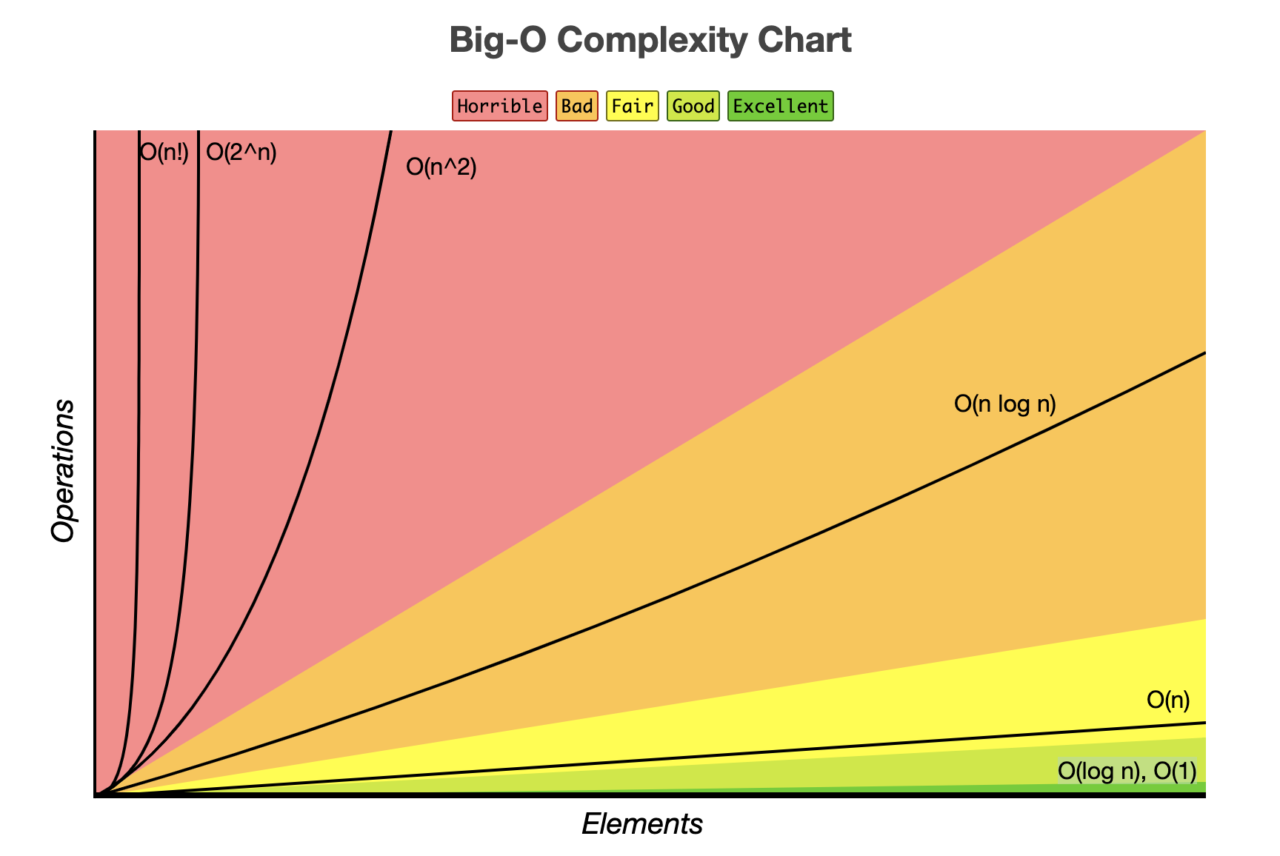
입력값에 따른 연산에 걸리는 시간을 변수에 따라 표기간단한 인덱싱시간복잡도가 linear하게 증가range 길이가 n개인 for문이 대표적업다운 게임을 생각BFS 알고리즘이 대표적이중 for문재귀함수가 대표적(피보나찌)하나의 루프를 사용하여 단일 요소 집합을 반복 하는
9.[코딩테스트]프로그래머스 - 거리두기(카카오 2021 blind recruitment)
문제 풀기나의 풀이1\. 5\*5 의 정해진 공간 안에서 L1 distance 구하기 : start 지점을 queue 에 append하고 bfs를 통해 각 지점에 대한 거리를 계산 2\. X(칸막이 지점) : queue에다 append하지 않으면 진행되지 않는 걸 활용
10.[알고리즘][Lv3]가장 먼 노드(python)(프로그래머스)
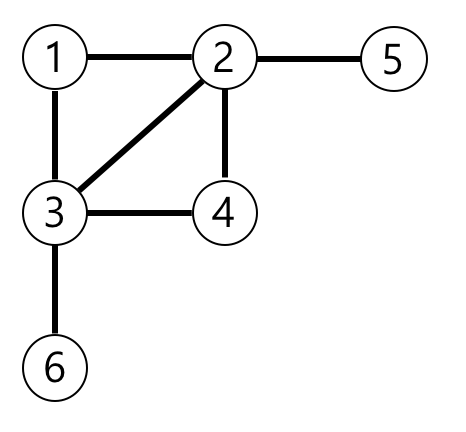
문제 풀기1번 노드로부터 최단경로 기준 가장 멀리 있는 노드의 개수를 구하는 문제.bfs로 탐색하는 queue 자료구조 활용연결 정보는 각 노드별 연결된 노드가 담긴 구조를 dictionary 형태로 저장(defaultdict활용)distance 에 거리별로 count
11.[알고리즘]Dynamic Programming
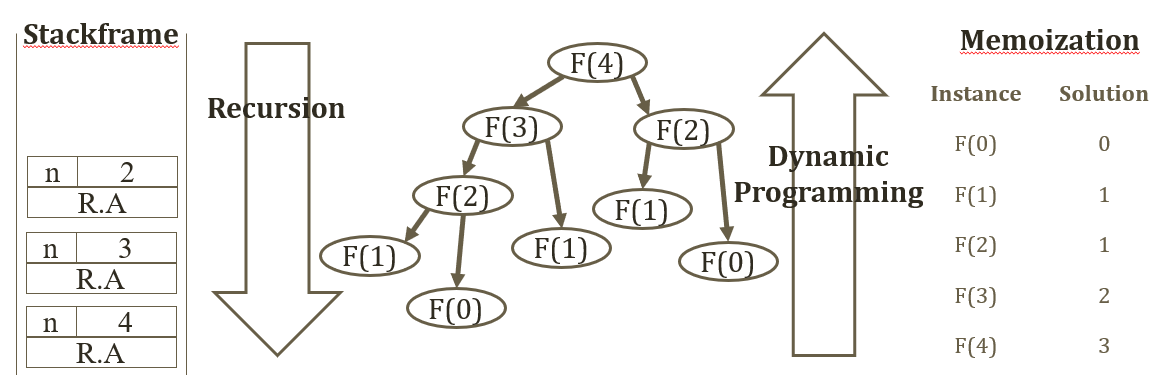
함수 호출이 너무 많다동일한 parameter를 갖는 함수 호출이 중복되어 비효율적정보를 미리 저장해두고 작은 문제부터 하나하나씩 해결해가면 어떨까?2를 8번 더하면 16이다. -> 2를 9번 더할 때는 다시 더하지 말고 2를 8번 더한 것에 2를 더하면 돼!https
12.[Lv2]프로그래머스 - 프린터(python) + any, all 활용하기
첫 순서 정보를 기억해야 하기 때문에 enumerate() 사용하여 인덱스정보 저장큐 를 굳이 안써도 코딩 가능. any를 쓰면 매우 간결한 코드로 변신함. 아래 두 코드를 비교해 보자.max 함수는 빈 리스트를 인자로 받을 경우 런타임 에러가 남. 이것을 방지하기 위
13.[자료구조]heap 익히기
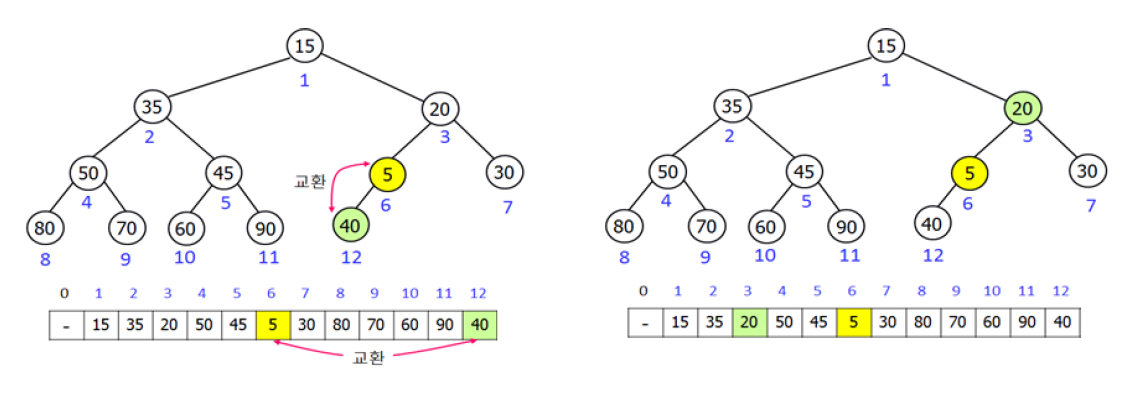
binary tree 를 가정최소힙 또는 최대힙이 있고, 아래 예시는 최소힙을 가정하고 든 예시시간복잡도가 log(n) 으로 우선순위 큐와 같은 자료구조보다 효율적인 알고리즘 구현 가능고려대학교 뇌영상분석연구실 교육자료 참고.image.pngimage.pngimage.
14.[Lv2][프로그래머스]가장큰수(Sorting)
문제 풀기51, 5, 57 이렇게 있으면 57, 5, 51 이렇게 배열해야 최대가 나옴. 다시 말해, 두자리 숫자라면 둘째 자리 수가 앞자리 수보다 작을때는 뒤로 가는게 낫고, 그게 아니라면 앞으로 와야함.위의 아이디어를 생각하지 않고 그냥 모든 경우의수를 고려하여 시
15.[알고리즘] NP-Hard (Time Complexity)
Deterministic Algorithm VS Non-Deterministic Algorithm 1) Deterministic Algorithm : input에 따라 결과가 정해진 알고리즘 ex) A-> B로 결정되어 있는 알고리즘 2) Non - determini
16.[자료구조]Array와 Time complexity(searching, insertion, deletion)
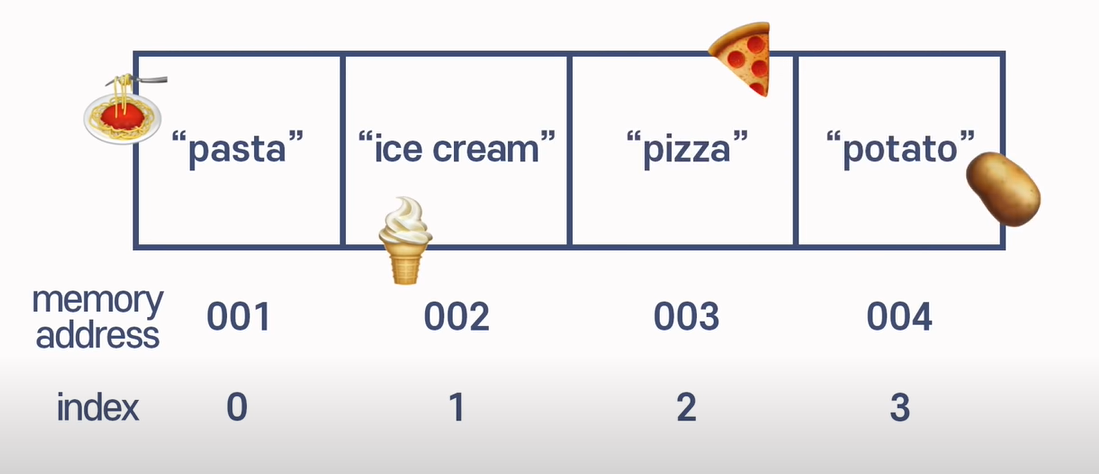
실제 소요 시간보다는 단계의 개념에 더 가깝다고 볼 수 있음단계가 적을 수록 효율적인 알고리즘컴퓨터에 미리 메모리 공간을 예약하여 어느 정도 길이가 될 것인지 설정해야 하는데, python이나 javascript와 같은 경우 그 과정을 IDE내에서 알아서 진행해 줌 메
17.[자료구조] sorting1 - bubble sort, selection sort, insertion sort (개념 및python 실습)
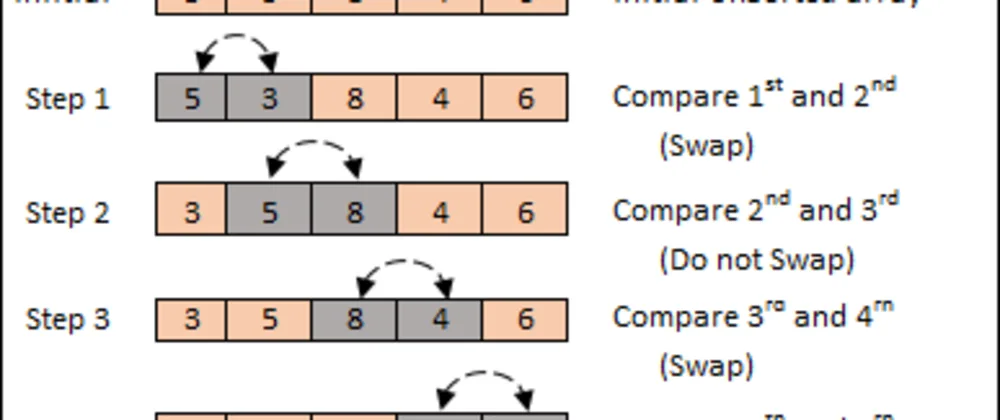
자주 이용되지는 않음이해하기 쉬움n, n+1 번째 index를 각각 비교하면서 설정https://dev.to/buurzx/buble-sort-4jkccycle 반복때마다 맨 뒤 값은 하나씩 정렬 완료됨최악의 경우 모든 item을 swap 해야함!$$O(n^2)
18.[자료구조]sorting2 - mergesort, quicksort, heapsort (개념 및 python 실습)
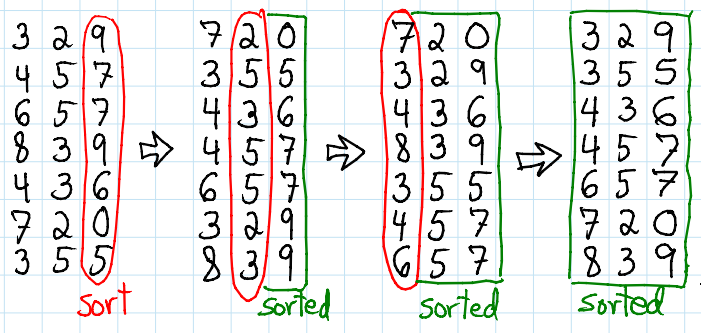
sorting 1 - bubble sort, selection sort, insertion sort저번 시간에는 시간복잡도가 최대 $$O(n^2)$$ 인 기본 정렬 알고리즘을 알아보았습니다. 조금 더 발전된 효율적인 sorting 알고리즘을 알아봅시다.https
19.[자료구조]sorting3 - counting, radix, topological(개념 및 python실습)
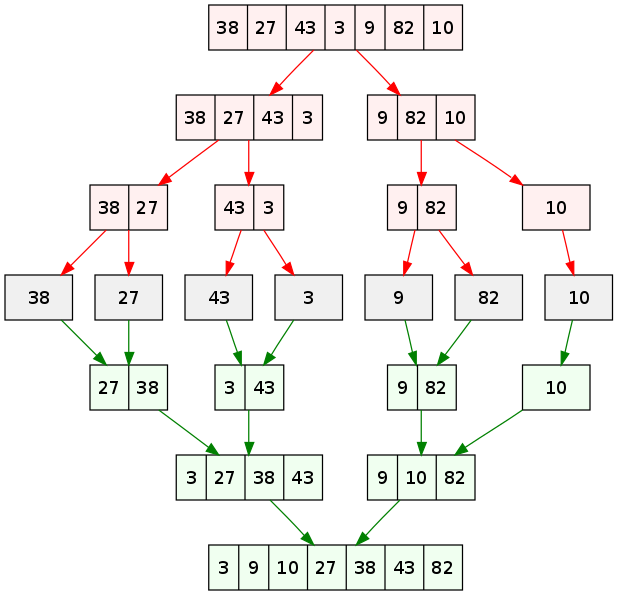
Sorting1 - bubble sort, selection sort, insertion sortsorting2 - mergesort, quicksort, heapsortsorting 마무리 시간입니다. 지금까지 배워온 정렬은 두 수의 대소를 비교하는 정렬이었습니다.
20.[알고리즘] 백준#2294. 동전 2 (dynamic programming)
최소이므로 조건에서 최대로 가질 수 있는 값으로 초기 dp 리스트 설정dp 리스트에 각 인덱스(k)에 대응되는 값은, k를 만들 수 있는 최소 개수를 의미예를 들어 12라는 수를 만들고 싶다면, dp12에 최소 동전개수가 매핑됨해당 동전을 뺐을 때 최소 가짓수 와 현재
21.[알고리즘] DFS와 백트래킹 backtracking(+ N queen, 부분수열의 합)
백트래킹이란? 해를 찾는 도중 해가 아니어서 막히면, 되돌아가서 다시 해를 찾아가는 기법 최적화 및 결정 문제의 해법이 됨 DFS 백트래킹의 일종이며, 재귀를 활용함 N*N Queen 문제 N*N의 체스판에 queen N개를 놓을 때, 서로 모두 공격 불가능한
22.프로그래머스 코딩테스트 - 정수 삼각형(Lv3)
문제 풀기계산 방법의 경로를 역추적하면 바로 위에서 오거나, 그 옆에서 오거나 두가지 경우임. 양 끝에 있는 건 예외처리 고고.
23.[코딩테스트]큰 수 만들기(stack)
문제 풀기모든 경우의 수를 확인해야 된다는 생각으로 접근하여 combination을 쓴 것이 비효율성을 낳았다.핵심은 앞쪽에서부터 확인해서 작은 숫자들을 없애 나가는 것이다. 다시말해, k개를 앞에서부터 없애 나가도(Greedy하게 풀어도) 알고리즘 구현에 무리가 없다
24.[코딩테스트]list 묶기(queue)
nested list 형태에서 max_group만큼 묶어서 list로(flatten) 반환하되, 묶은 list가 max_len를 초과할경우 초과하지 않을 때 까지 group을 줄여서 묶음.묶인 list는 다시 활용되지 않음. 다음으로 넘어감. que 자료구조 활용
25.[자료구조]hashing

https://en.wikipedia.org/wiki/Hash_functionkey 값들이 hash table의 각 값에 mapping 됨이러한 mapping은 hash function 에 의함hash table의 각 칸들을 hash bucket이라고 함htt
26.[코딩테스트]여행경로(DFS)
문제 풀기dfs를 stack으로 구현해야 쉽게 풀 수 있는 문제.방문한 경로를 기록해놓고 다시 방문 안하는게 아니라, pop()으로 없애주고 자연스럽게 모든 코스를 순회하도록 하는 것이 핵심defaultdict 활용해야 함.
27.[알고리즘]플로이드_워셜 알고리즘
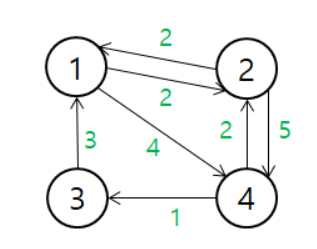
모든 정점 사이의 최단경로를 찾는 탐색 알고리즘시간복잡도 O(n^3)핵심은 해당 직접 방문하는 경로의 cost와, 다른 곳을 들렀다가 방문하는 cost 를 비교하여 더 작은 값을 선택해 나가는 것 https://it-garden.tistory.com/247
28.[프로그래머스][Lv2]전력망을_둘로_나누기(완전탐색) - python
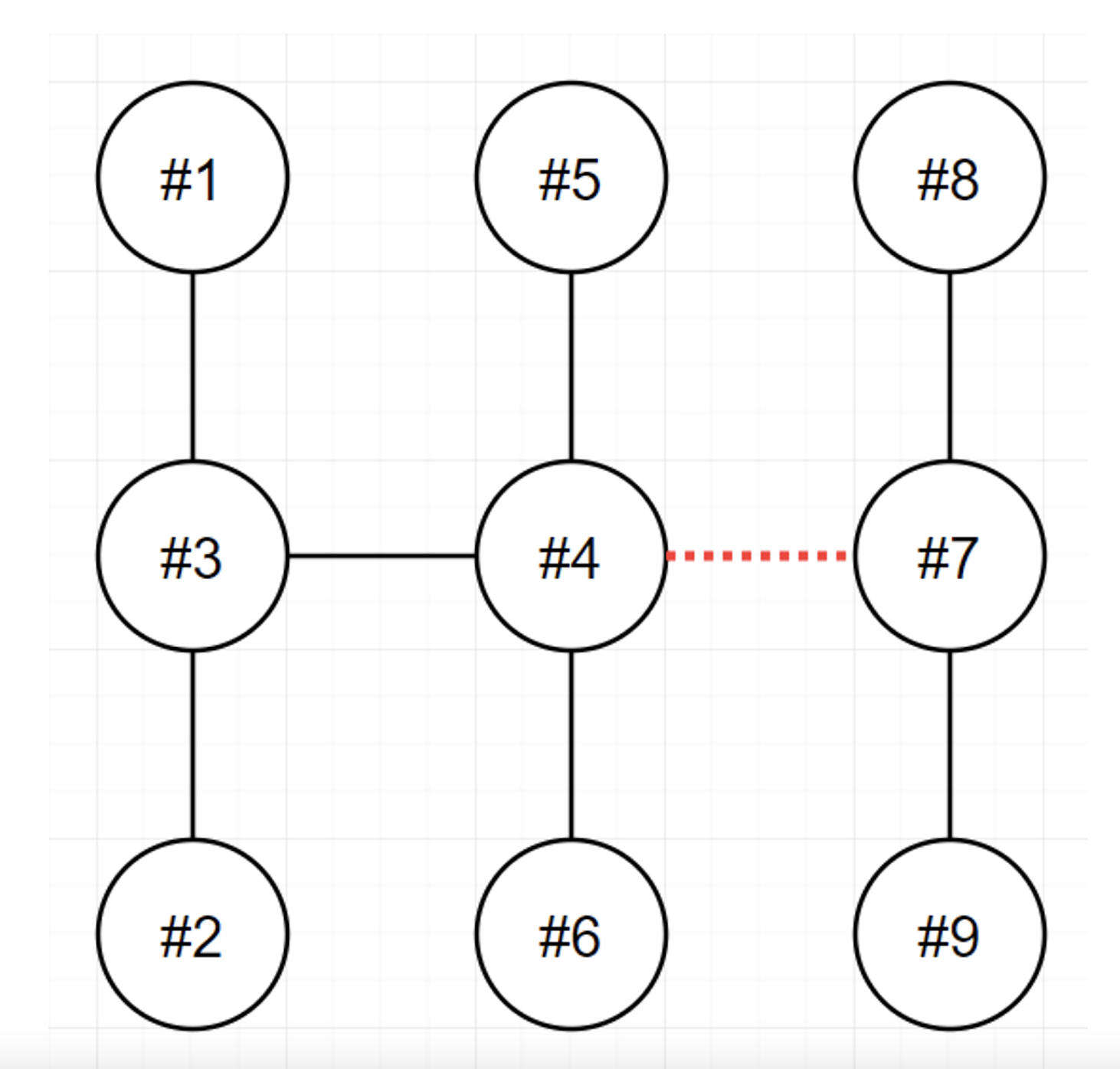
송전탑을 둘로(edge를) 쪼갰을때, 쪼개진 그 두 송전탑의 집합(트리구조)에서 노드수 차이값의 최소를 구하는 문제.7개의 노드에서 3,4 로 쪼개지는게 최소이므로 1이 정답.송전탑이 node고, 연결선이 edge인 트리구조를 생각했을 때, 이미 하나의 edge를 끊었
29.[알고리즘] binary search(이진탐색)
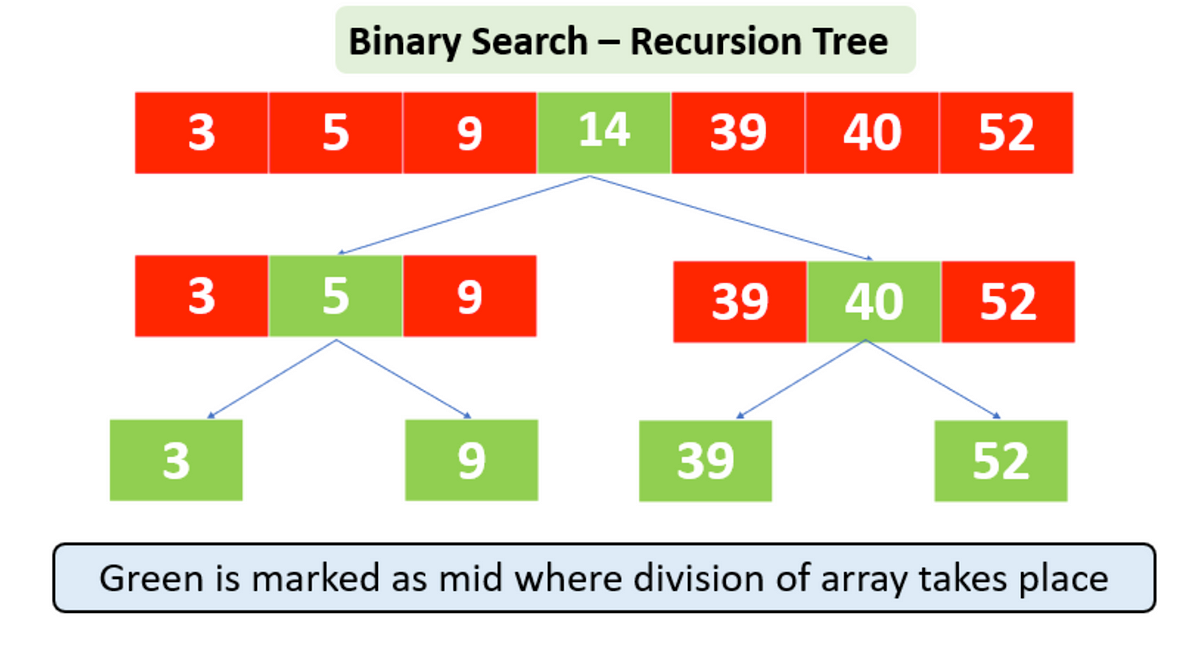
https://medium.com/@imanshu822/binary-search-and-its-powerful-applications-39ae7d7bca69정렬된 배열을 가정검색이 반복될 때마다 검색 범위가 절반으로 줄기 때문에 속도가 빠름Time Comple
30.[알고리즘] 153. Find Minimum in Rotated Sorted Array
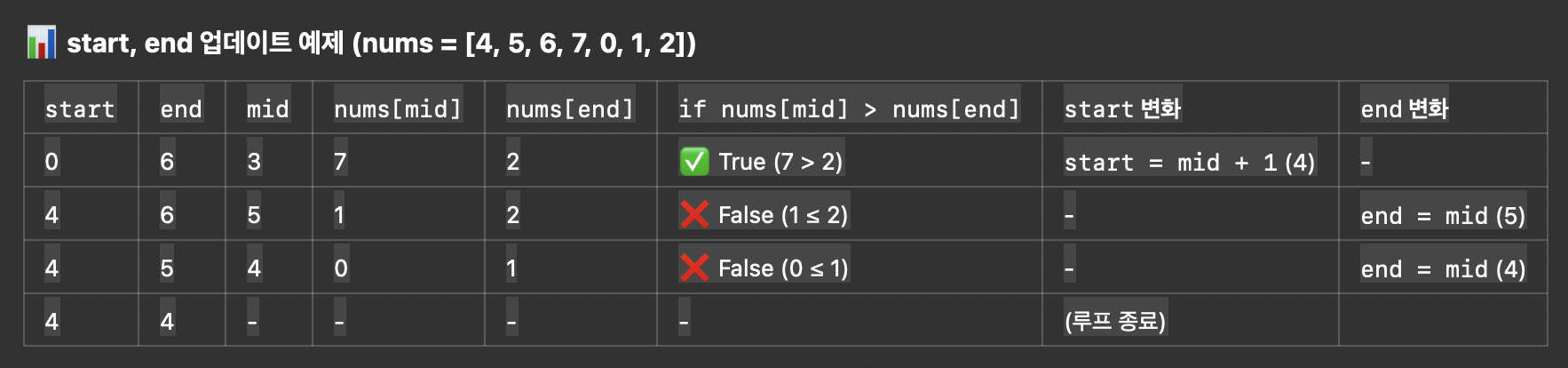
노션 링크이 문제는 이진탐색에서1\. start, end index를 0, len(arr)-1 로 할것인가, 0, len(arr)로 할것인가2\. while 문 조건을 start <= end 로 할것인가, start<end 로 할것인가3\. end 재할당시