wanted-NLP
1.[week1-1]NLP subtask : Word Embedding(Word2Vec, FastText) 과 Bert,Roberta
AI/머신러닝 엔지니어로서 커리어를 만들어나가고 싶고, 이에 취업준비를 하면서 modelling framework 사용 역량(pytorch 잘 모름)논문 base 구현그리고 실제 데이터를 활용한 모델 배포 경험을 쌓는 것 세가지가 저에게 있어 보완해야 하고, 해당 경
2022년 2월 21일
2.[week1-2][NLU]Question and Answering(질문과 답변) : SQuAD dataset과 SOTA Model(ANNA, Retrospective Reader)
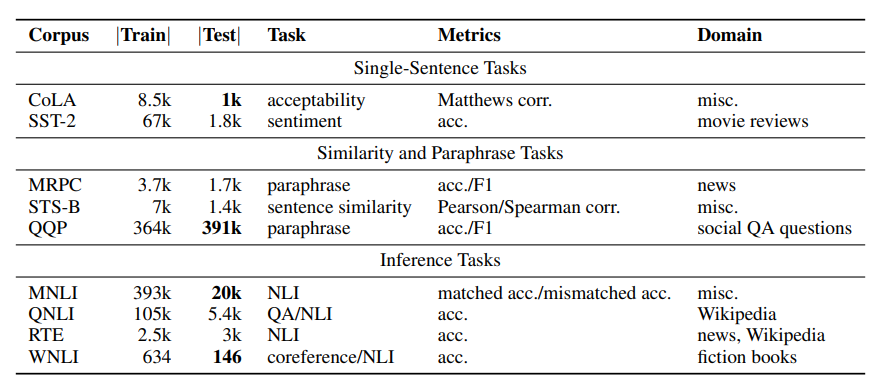
내가 풀어야 될 task와 benchmark dataset을 mapping하여 pipeline을 정의할 수 있다.NLU와 GLUE, SQuAD dataset에 대하여 이해해 본다.NLU Subtask중 Q&A task를 골라, 문제를 어떻게 정의하고 해결하는지 proc
2022년 2월 22일
3.[NLG] Text Summarization : Pegasus와 GLM 논문 요약 리뷰
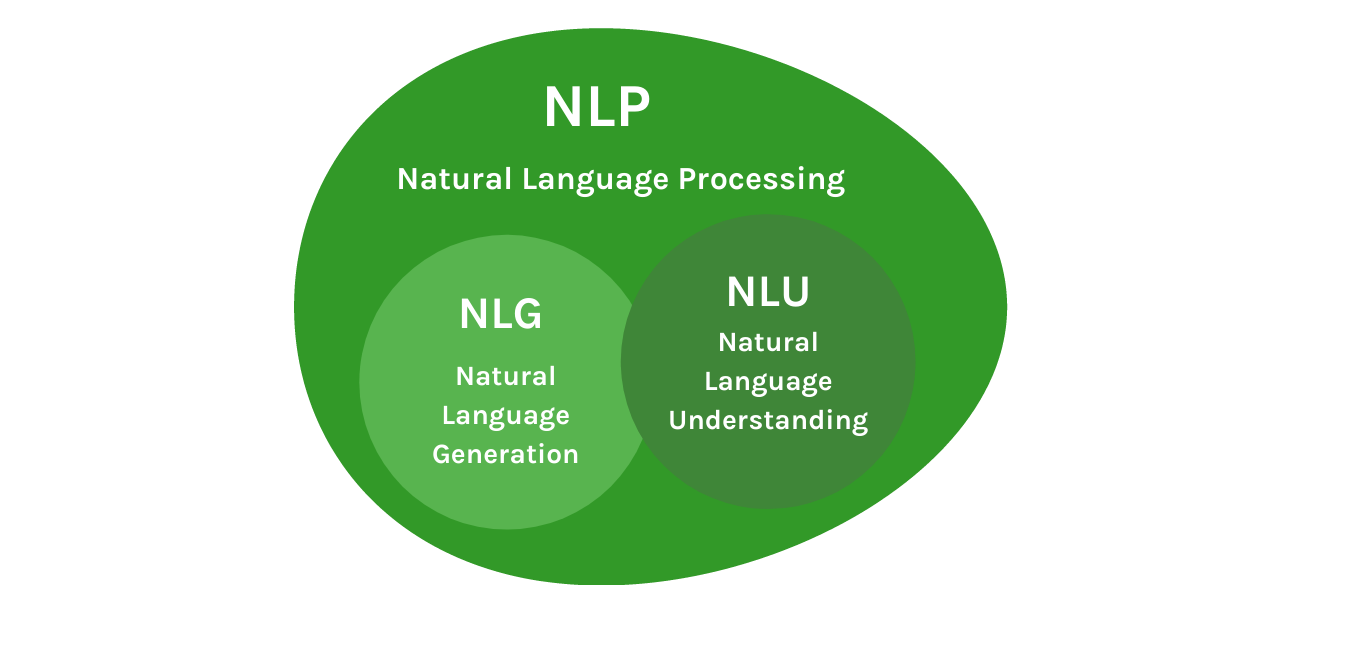
https://en.ax-semantics.com/natural-language-generation-explained/Natural Language Generation주어진 정보를 기반으로 축약(abbreviation), 보강, 재구성NLU에 비해 발전이 많이
2022년 2월 23일