[week1-2][NLU]Question and Answering(질문과 답변) : SQuAD dataset과 SOTA Model(ANNA, Retrospective Reader)
wanted-NLP
목록 보기
2/3
Goal💪
- 내가 풀어야 될 task와 benchmark dataset을 mapping하여 pipeline을 정의할 수 있다.
- NLU와 GLUE, SQuAD dataset에 대하여 이해해 본다.
- NLU Subtask중 Q&A task를 골라, 문제를 어떻게 정의하고 해결하는지 process를 이해하여 본다.
NLU 2가지 : 언어를 이해한다는 것은🤔
- syntactic : 문법적으로 알맞은가?
- semantic : 의미를 아는가?
- Sentimental anaylsis
- similarity btw sentences
- understanding intention
- answering to the questions
GLUE & SQuAD Benchmark
1) GLUE(General Language Understanding Evaluation)[논문 읽기]
- 다양한 task 모여있는 dataset
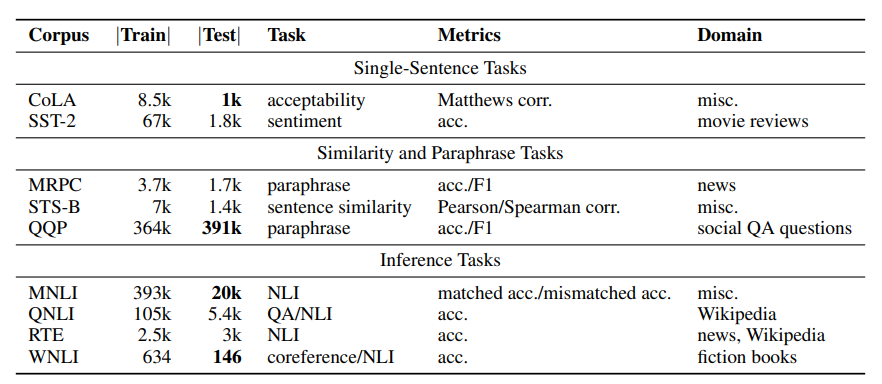
[문장 하나, pair, inference로 크게 분류되는 task]
- CoLA : 문법
- SST : 감성분석
- STS, MRPC, QQP :문장 유사성(regressive한 예측)
- MNLI, RTE : 추론(전제로부터 가설의 참,거짓 판별)
-> 법률 및 회계감사에 적용 - WNLI : 언급 대상 추론(it과 같은 대명사가 무엇을 가리키는지)
2) SQuAD(stanford question answering dataset)
- 질문으로부터 정답을 맞추는 Q&A dataset
- 위키피디아로부터 제작되었다는 특징이 있음
dataset
- SQuAD 1.1
- 500개이상의 article로부터 온 100,000개 이상의 Q&A pair
-> Reading Comprehension에 대한 성능 체크 - SQuAD 2.0
- SQuAD 1.1 의 dataset+ 50,000개 이상의 답변 불가능한 question
-> 답변이 어려우면 못하겠다고 말하는 성능까지 체크

[사이트에서 dataset 에서 분류된 article과, SOTA 모델 별로 학습 완료된 결과까지 어렵지 않게 확인할 수 있다.]
Question & Answering🎤
📌 task가 해결하고자 하는 문제?
- 검색 시스템 최적화(SEO)
- 챗봇 서비스[챗봇서비스 헬로우봇 해보기]
- 이외에 Reading Comprehension을 통해 문맥(context)을 파악하고, 질문에 대한 답을 내는 데에 도움이 되는 모든 task
📌 데이터 소개
import json
train_path = '/content/train-v1.1.json'
def print_json_tree(data, indent=""):
for key, value in data.items():
if type(value) == list: # list 형태의 item은 첫번째 item만 출력
print(f'{indent}- {key}: [{len(value)}]') # 여러개니까 길이 츨력
print_json_tree(value[0], indent + " ") #하위 항목을 indent 주고 재귀
else:
print(f'{indent}- {key}: {value}') # 여러개 아니면 그 값 출력
with open(train_path,'r') as f:
json_data = json.load(f)
print_json_tree(json_data)
>>>
## []는 데이터 개수
- data: [442] #442개의 article
- title: University_of_Notre_Dame
- paragraphs: [55] # article 아래 55개의 paragraph
- context: Architecturally, the school has a Catholic character. Atop the Main Building's gold dome is a golden statue of the Virgin Mary. Immediately in front of the Main Building and facing it, is a copper statue of Christ with arms upraised with the legend "Venite Ad Me Omnes". Next to the Main Building is the Basilica of the Sacred Heart. Immediately behind the basilica is the Grotto, a Marian place of prayer and reflection. It is a replica of the grotto at Lourdes, France where the Virgin Mary reputedly appeared to Saint Bernadette Soubirous in 1858. At the end of the main drive (and in a direct line that connects through 3 statues and the Gold Dome), is a simple, modern stone statue of Mary.
- qas: [5] # paragraph 별 5개의 질문
- answers: [1]
- answer_start: 515
- text: Saint Bernadette Soubirous
- question: To whom did the Virgin Mary allegedly appear in 1858 in Lourdes France?
- id: 5733be284776f41900661182
- version: 1.1
🤩구성 확인하기!
- 442 * 55 * 5 = 약 121,550개의 Q&A set 확인
- paragraph 별 context에
- 여러 개의 질문(question)과
- 그에 대한 답변(답변이 시작되는 곳(answer_start), 답변의 내용(text),
- 그리고 Q&A pair에 대응되는 id
로 이루어져 있음
-> answer를 target 으로 context 및 question을 학습하는 구조임을 유추해볼 수 있음
📌 SOTA Model 소개
📌1)ANNA(for SQuAD 1.1)[2021][논문 읽기]
- Approach of Noun-phrase based language representation with Neighbor aware Attention 의 약자로, pre-training approach의 새로운 기법
a. Attention 기법 활용(Transformer 변형)
- syntactic & contextual(semantic) 정보에 attention 매커니즘을 활용
- masking된 단어의 그룹(Noun phrase)을 학습 및 예측하도록 설계되어 있음
- 원래의 transformer의 encoder block으로부터 파생된, neighbor-aware self attention이라고 불리는 새로운 transformer encoding 매커니즘
- neighbor token을 더 중요하게 인식하여 attention score를 산출해 냄
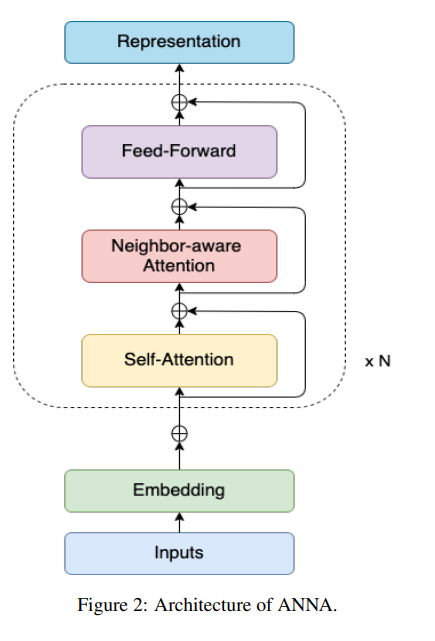
[transformer 각 layer에서, self-attention 과 FFN 사이에 Neighbor-aware attention을 추가해주는 구조]
b. Neighbor-aware self attention
- 기존 Transformer encoder block은 관련 없는 영역으로부터 온 Noise때문에 문맥을 파악하고 정답을 맞히는 데에 방해가 될 것이라는 판단으로부터 고안됨
- attention score 계산될 때, attention matrix의 diagonality(대각행렬)를 무시함으로서 동일한 토큰의 영향을 제거해 줌.
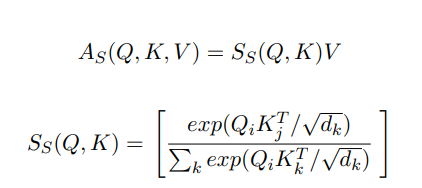
[standard transformer architecture의 attention layer]
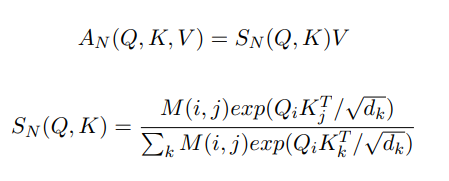
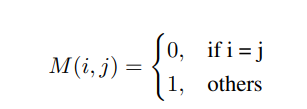
[neighborhood-aware attention layer와 Mask 함수 ]
- Mask 함수가 추가된 것이 핵심
- 는 position, 그에 따른 는 input token 간의 연산을 진행
- 일 경우 : 0으로 상호 동일한 token 간 영향 제거
- 일 경우 : 그대로 둠
c. MLM(Masked Language Model) task following BERT
- input token으로부터 random하게 15% masking 진행
- 15% 중에
- 80%는 [MASK] token으로 대체- 10%는 그대로 둠
- 10%는 random하게 token을 골라서 대체
- NSP(Next Sentense Prediction) 은 RoBERTa 논문에 의해 하지 않음
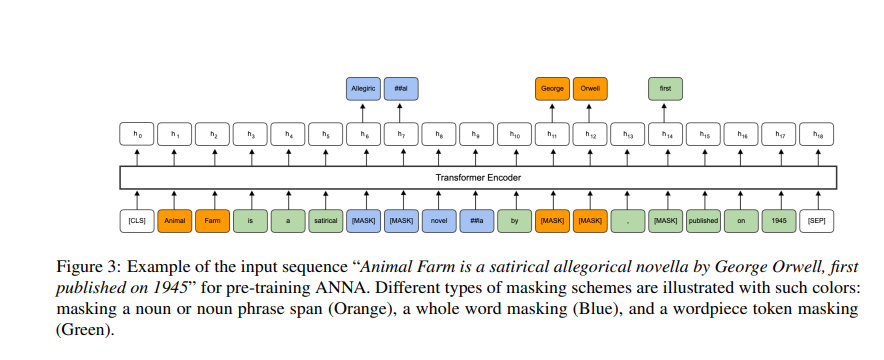
[ANNA 모델에서 여러 종류의 masking 과정. noun phrase(주황), 전체 단어 마스킹(파랑), wordpiece token(초록) 등 ]
d. 성능
- SQuAD 1.1 dataset에서 95.7% 의 F1 score, 90.6% 의 EM(Exact Match, 정답과 정확히 일치하는 정도) Score를 보여줌
- 이는 이전의 pre-trained Model인 RoBERTa, ElECTRA, XLNet 이 보여준 성능보다 뛰어남
📌2) Retrospective Reader(for SQuAD 2.0)[2020][논문 읽기]
- Machine reading Comprehension에 있어 찾는 답이 없다면 대답을 않는 task도 중요함
- 답을 찾는 것 뿐 아니라 쉽게 말해 모르면 모른다고 말하는 task도 수행할 수 있는 모델
- 이에 따라, encoder 뿐 아니라 verification module로 답을 낼 수 있는지 없는지 판단할 수 있는 verifier 필요함
a. Retro-Reader의 두 가지 task🧐
- reading과 verification의 기능이 구현된 모델
- 별도의 모델이라기보다는, 기존 모델에서 아래 기능을 추가한 개념으로 생각하면 됨
1) sketchy reading
- 스키밍을 통해 문단과 질문의 상호관련성을 판단(initial judgement)
- '정답이 있는지 찾는 과정'으로 생각해볼 수 있음
2) intensive reading
- 내용을 집중적으로 읽고, 정답을 낼 수 있는지 없는지 확인 후 최종 예측을 수행(final prediction)
- 정답이 있다고 판단하고 '정답을 내는 과정'으로 생각해볼 수 있음
b. 구조에서 학습과정 요약[참고자료]
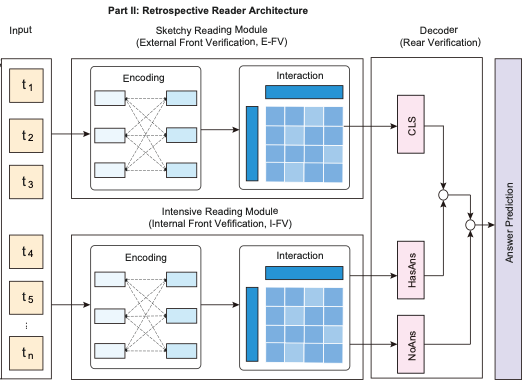
a. input
- token이 encoder에 input으로 들어감
- output :
b. Encoding
- encoder가 문장의 feature를 추출하고 BERT에서와 같이 input embedding(positional + segemnt + token)을 생성
output :
c. interaction
- input embedding이 interaction layer로 들어감. 이것은 multilayer bidirectional transformer에 해당하고, 문맥 표현을 추출함
- activation function으로 GELU(Gaussian Error Linear Unit)사용
- last-layer에 hidden state로 output 생성
output :
i. sketchy reading Module의 경우
- E-FV(External Front Verifier)로 CLS token을 FC layer에 통과시켜서 Classification 또는 regression score를 받게 됨. (Cross Entropy로 최적화)
ii. Intensive Reding Module의 경우
- Hidden state를 question에 대한 hidden state, Passage에 대한 hidden state로 나누어 매칭하는 매커니즘을 조사
- 정답 확신도 조사 -> 정답 후보들 생성 후 -> 마지막 에측 수행
(수식은 논문을 확인)
c. 성능
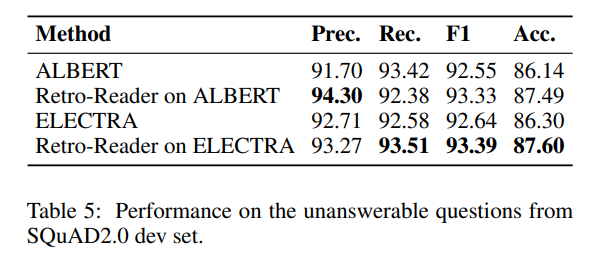
- ALBERT 및 ELECTRA에 해당 개념 적용
- Retro-reader 개념이 적용된 것이 전반적으로 더 나아진 성능을 보임

romantic ai developer


Question & Answering task와 현재 sota 모델에 대해서 알 수 있었어요! attention 메카니즘에 대한 정리도 잘 봤습니다 :)