[https://en.ax-semantics.com/natural-language-generation-explained/]
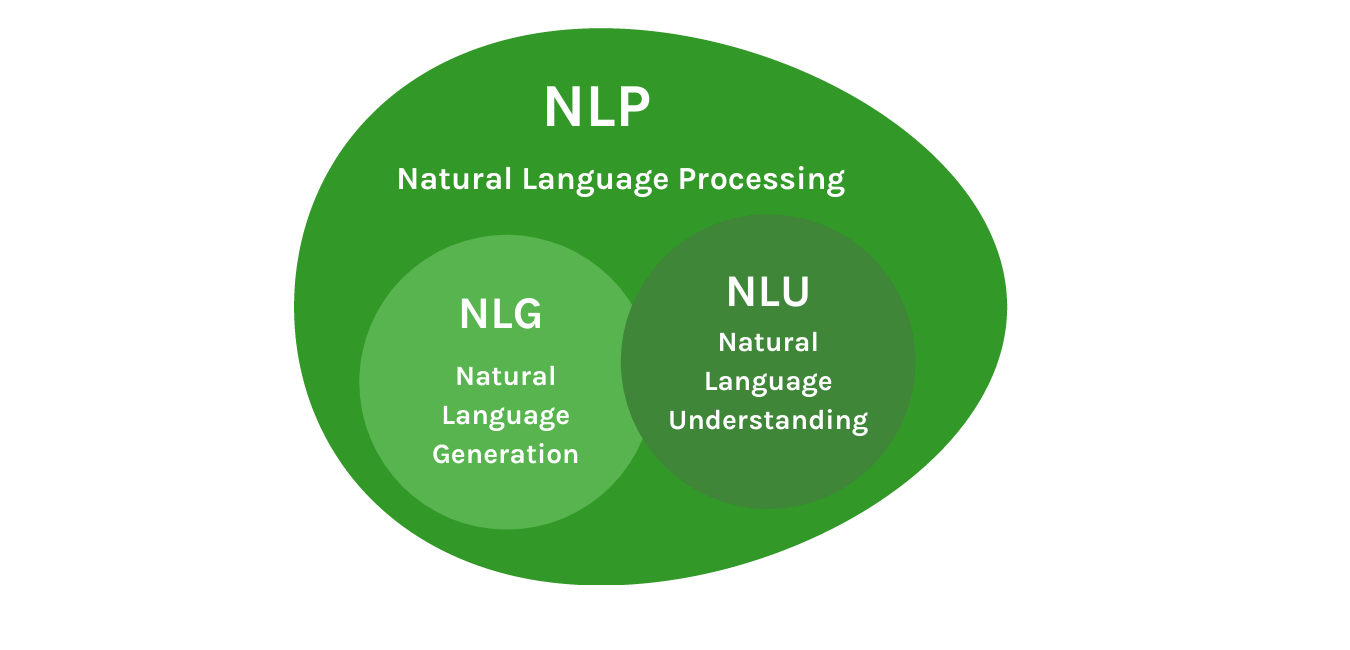
NLG
- Natural Language Generation
- 주어진 정보를 기반으로 축약(abbreviation), 보강, 재구성
- NLU에 비해 발전이 많이 되지 않았고, 2022년 현재 BenchMark dataset이 생기면서 연구가 활발히 진행되고 있음
1) Text abbreviation
a. summarization
-
abstractive, extractive summarization 으로 나누어짐
abstractive : 내용으로부터 주요 단어 추출 및 조합하여 요약, extractive보다 복잡한 task
extractive : 내용으로부터 주요 문장 추출 및 요약 -
뉴스 요약 등에 적용
b. Question generation
-
내용으로부터 질문(문제)을 생성
-
공부에 도움이 될 온라인 학습 도구 등에 적용
c. Distractor generation
-
오지선다에서 오답을 생성
-
데이터 증강(data augumentation) 에 적용
2) Text Expansion
a. Short text expansion
-
정보를 추가해서 데이터 길이 늘리기
-
짧은 제목을 내용을 늘이는 데 적용
b. Topic to essay generation
- input으로 topic들을 넣어주면, output으로 essay를 만들어 줌
3) Text Rewriting
- 기존 문서를 변형 및 재구성하여 정답 생성
a.Style transfer
- 문장을 긍정 <-> 부정, 사투리 적용 등등 문장 스타일로 변화시켜주는 task
- 데이터 증강, 말투 변화 등에 적용
b. Dialogue Generation
- 사전학습된 문장들을 기반으로 대화를 생성
- 챗봇에 적용
NLG Models
- Encoder Decoder
- RNN Seq2seq- Trnasformer
- Copy and pointing
- GAN
- Memory Network
- GNN, External Knowlendge(ERNIE,..)
NLG subtask중 Abstractive Text Summariation의 DATASET 및 SOTA 모델에 대해 알아봅시다.✒
📜Abstractive Text Summarization
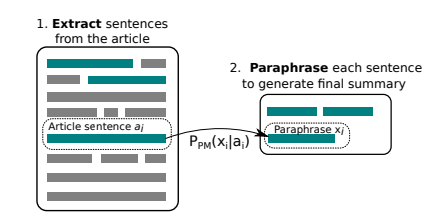
[Paper : Abstractive Document Summarization without Parallel Data]
📌 task가 해결하고자 하는 문제?
- 말 그대로 긴 문서 요약!
- 특히 단순히 문장을 추출하는 것보다, 내용을 한눈에 알아볼 수 있는 요약 task를 지향함
- 다시말해 paraphrasing하는 task를 수반함
- 산업군에서 뉴스기사와 같은 텍스트에 특히 많이 적용됨
📌 데이터 소개
1) CNN/Daily Mail[github]
- 미국의 뉴스사인 CNN과 Daily Mail 사이트로부터 생성된 abstractive Summary를 label로 담고 있는 데이터셋
- 문단(passage)과 그에 부합하는 요약본(Ground Truth summary) pair로 이루어져 있음
- 280,000개 이상의 training pair, 13,000개 이상의 validation pair, 11,000개 이상의 test pair
- 평균적으로 각 문단은 30개의 문장, 요약된 Summary는 3.72 문장으로 이루어져 있음
- 1.0.0 은 Reading Comprehension을 위한 dataset이고, 2.0.0 및 3.0.0 version이 요약을 위한 dataset
🤩구성 확인하기!
huggingface 공식문서를 참고하여 작성하였습니다.
{'id': '0054d6d30dbcad772e20b22771153a2a9cbeaf62',
'article': '(CNN) -- An American woman died aboard a cruise ship that docked at Rio de Janeiro on Tuesday, the same ship on which 86 passengers previously fell ill, according to the state-run Brazilian news agency, Agencia Brasil. The American tourist died aboard the MS Veendam, owned by cruise operator Holland America. Federal Police told Agencia Brasil that forensic doctors were investigating her death. The ship's doctors told police that the woman was elderly and suffered from diabetes and hypertension, according the agency. The other passengers came down with diarrhea prior to her death during an earlier part of the trip, the ship's doctors said. The Veendam left New York 36 days ago for a South America tour.'
'highlights': 'The elderly woman suffered from diabetes and hypertension, ship's doctors say .\nPreviously, 86 passengers had fallen ill on the ship, Agencia Brasil says .'}-
id, Article, Highlight(추론된 것이 아닌 실제 요약본) 로 이루어져 있음(string type)
📌 SOTA Model 소개
📌1)GLM-XXLarge(2021)
✏keyword
GLM(General Language Model),classification,unconditional generation,conditional generation,autoregressive blank infilling
- [모델 github Code 확인하기]
- Text summarization에 특화된 모델이 아니라, General하게 좋은 성능을 내는 모델이자 기법
a.concept
- 많은 pretrained SOTA model들은 각각의 NLP task에 특화된 모델들이 있지만, 모든 task에 좋은 성능을 내는 모델은 없음
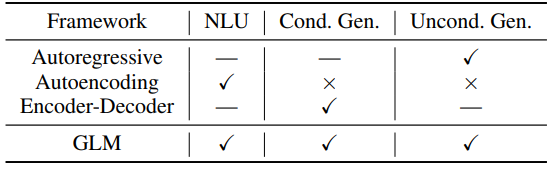
- GPT : autoregressive model(시계열, 생성에 특화)
- BERT : autoencoding(NLU에 특화)
- T5 : encoder-decoder model
- 본 논문에서 소개하는 framework인 GLM은
- classification, unconditional generation, conditional generation 모든 task에 좋은 성능을 보임
- pretrain-finetune 일관성(pretrained model과 finetuning 과정이 알맞게 이어저 있는 것)이 뛰어남
- 많은 downstream task에 이어지는 variable-length blank filling을 조절함.
b. Model Architecture
- BERT와 유사하게 transformer 구조를 사용함
c. autoregressive blank filling
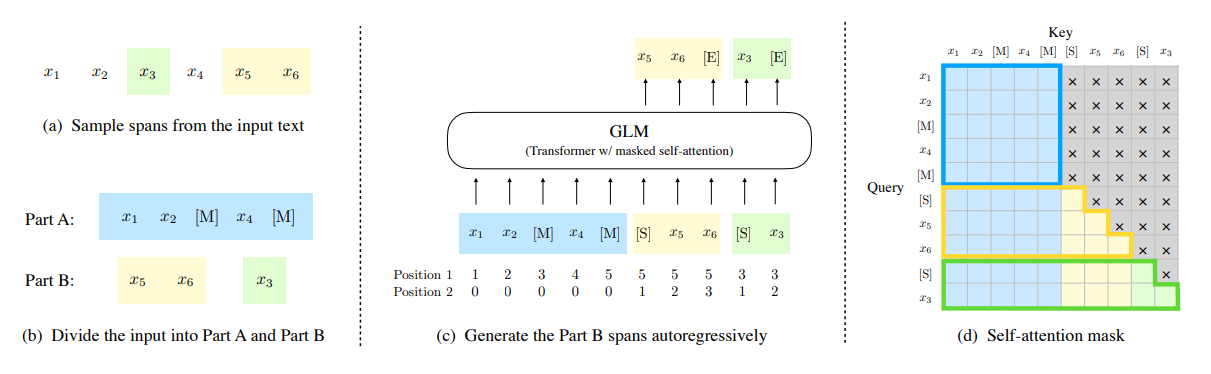
1) input을 Part A 와 B로 나눔
- input text :
- span 선택 : ,
- Part A : 선택된 span sample에 대해 masking
- Part B : 선택된 span을 shuffle
2) Autoregressive하게 Part B span을 생성
- start token 과 end token을 각각 input span의 prefix, output span의 suffix에 append
- Part B를 autoregressive하게 생성하도록 training 수행
- inter(span 간) , intra(span 안) 위치를 나타내도록 2D positioal encoding 수행
3) masking된 상태에서 self-attention 수행
- gray 영역이 masking된 곳
- Part A는 파란 테두리 영역의 attention 연산을 수행함
- Part B 의 각각의 Span(여기서는 두 Span)은 노랑, 초록 테두리의 attention 연산 수행함
d. fine tuning
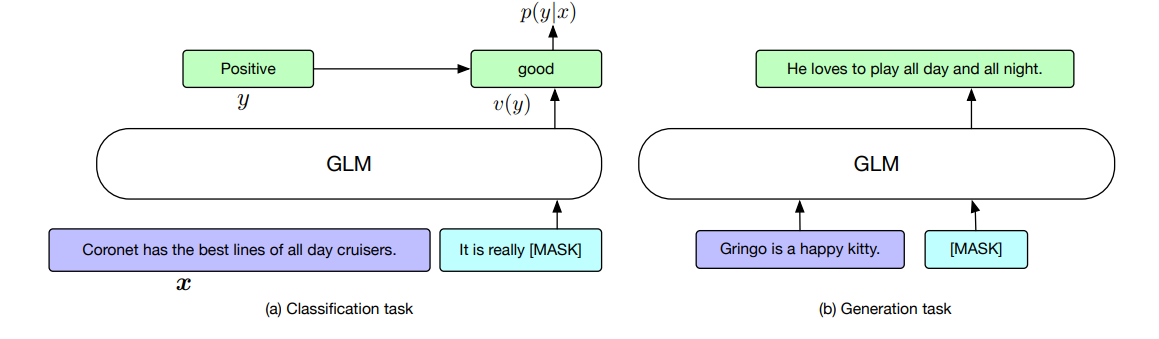
- 논문의 제목처럼 Classification도 masking을 통한 blank infilling을 통한 generation으로 수행하는 것을 알 수 있음
e. 성능
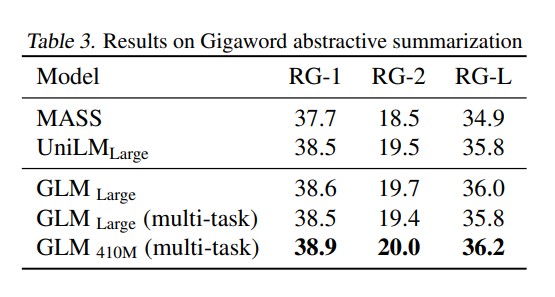
- GLM 모델에서 향상된 성능을 확인
- Dataset : GigaWord
- metric : testset에서 Rouge 1, Rounge 2, Rouge 3 의 F-1 Score로 선정
- optimizer : adamW
- lr : peak value
- 6% linear decay의 warmup 기법 사용
- 0.1의 rate 의 label smoothing 기법 사용
- 최대문서길이 192, 최소문서길이 32
- decoding 과정에서 Beam Search 이용
- validation set에 length penalty 값을 조정
Terminology
- warm-up 기법 : optimizer에서 lr 설정 시 초반에 매우 적은 값으로 간을 보고, 이후에 regular한 값으로 조정해나가는 process. attention 메커니즘이 이용되는 transformer 계열의 모델에서 흔히 이용됨.
- Rouge Score 란? : Recall-Oriented Understudy for Gisting Evaluation의 준말로 텍스트 요약 모델의 성능 평가 지표
- label smoothing : label의 noise를 제거하는 기법
- Beam Search
📌2) PEGASUS[2020][github]
✏keyword
GSG(Gap Sentence Generation),MLM(Masked Language Model),Rouge
- google에서 개발한, abstractive text summarization task를 위한 pre-trained 모델
- Transformer기반 encoder-decoder 모델
- self-supervised 모델
a. 특징
- 중요한 문장들이 input으로부터 masking되거나 제거됨
- 남은 문장들로부터 하나의 sequnce로 생성(extractive와 유사)
- 뉴스, 과학, 이메일, 특허, 법률 등 12종류의 다양한 domain에서 downstream task를 수행
- Rouge Score에서 SOTA의 성능을 보임
- resource가 많이 없어도 잘 작동
- 해당 논문에서는 좋은 성능을 내기 위해서는 downstream task의 목적에 맞는 pre-trained 모델을 사용하고 이를 fine- tuning 하라는 것을 강조
b. Model architecture
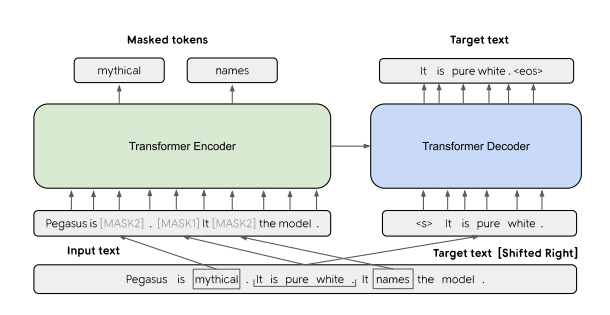
- GSG와 MLM이 동시에 사용되는 Transformer encoder-decoder 구조
- 3문장으로 이루어진 위의 예시에서는,
- 하나의 문장이 mask1으로 masking되고(encoder), target으로 이용됨(decoder로)
- 남은 2문장은 일부 token이 random하게 masking되어 encoding됨
GSG(gap sentence generation)
-
Pegasus 논문에서 모델 구조의 핵심 개념
-
모델은 input의 여러 문장중 핵심적인 의미를 담고 있다고 판단되는 중요한(principal) 한 문장을 선택하여 문장 전체를 masking 한다. 이 문장을 논문에서는 gap sentence라고 칭한다.
-
즉, 이 문장에 대한 masking 및 generation이 상기된 model architecture에서 진행되는 것이다.
그럼 중요한 문장을 어떻게 선택하나?🤔
-
이를 이용하기 위해 Random, Lead, Principal 이라는 3가지 전략을 이용한다.

[Pretraining 에 이용되는 C4 corpus dataset에서의 예시]
- Random(초록색) : m개의 문장을 랜덤하게 선택
- Lead(빨간색) : 첫 m개의 문장을 선택
- Principal(파란색) : Rouge f1 Score에 의해 중오도에 따른 top m개의 score를 계산즉, 각 색깔별로 해당된 문장들을 gap sentence로 인식하고 GSG 과정을 수행한다고 이해할 수 있다.
d. 성능
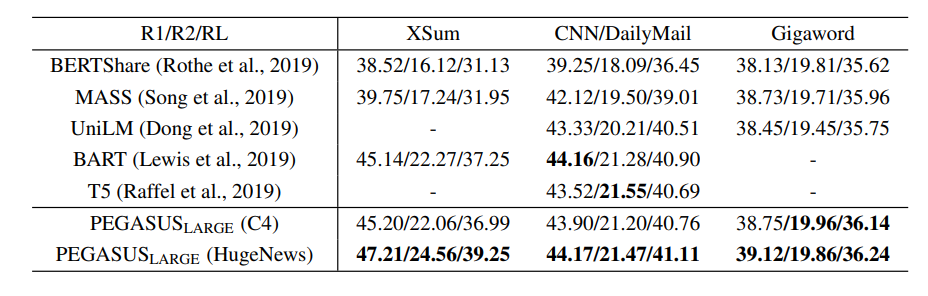
-
다른 이전의 SOTA 모델과 비교해보았을 때 , XSum, CNN/DailyMail, GigaWord 세 BenchMark에서 나아진 성능을 보임
-
metric : Rouge f-1 Score
-
hyperparameter
: L = 12, H = 768, F = 3072, A = 12, batch size = 256
: had L = 16, H = 1024, F =
4096, A = 16, batch size = 8192
- L: layer(Transformer block) 수
- H : hidden size
- F : Feed forward layer 크기
- A : self-attention의 크기 -
Transformer와 같이 sinosoidal positional encoding 이용
-
dropout rate 0,1, square root lr decay와 함께 Adafactor optimizer를 pre-training과 fine-tuning에 이용
-
beam search와 length-penalty 사용
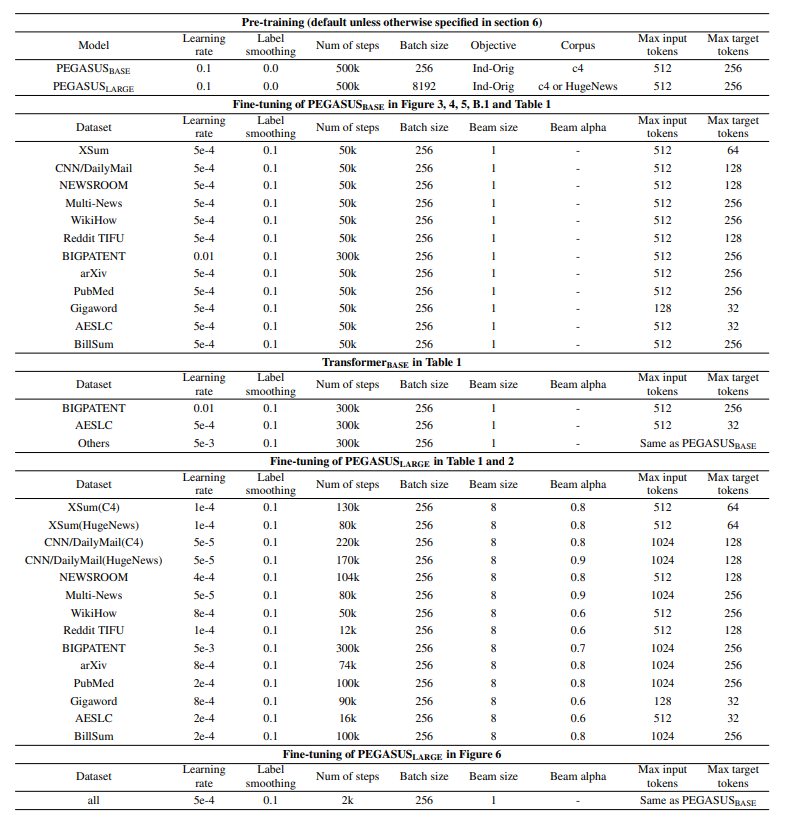
[논문 Appendix C에 기록된 실험 hyperparameter 값]
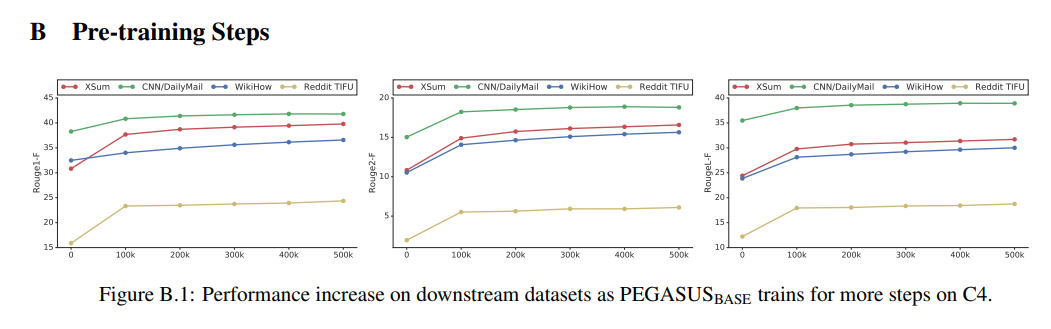
[의 pre-training 과정]
회고
- Pegasus가 모델도 복잡해보이지 않고 자료도 많아서 적용해볼만 한 모델인 것 같다.

본 콘텐츠는 "모두의 연구소에서 진행하는 "함께 콘텐츠를 제작하는 콘텐츠 크리에이터 모임" COCRE(코크리) 2기 회원으로 제작한 글입니다.
- 코크리란?

3개의 댓글

잘읽었습니다! 나중에 summarization task를 수행하게 되면 Pegasus 모델을 사용해보는 것도 나쁘지 않겠네요🤔 글 구성이 많은데 깔끔하게 잘 정리하신 것 같아요!

GLM이랑 Pegasus 모델 상세하게 알려주셔서 감사합니다!