1. 강의 수강 목적🤡
AI/머신러닝 엔지니어로서 커리어를 만들어나가고 싶고, 이에 취업준비를 하면서
- modelling framework 사용 역량(pytorch 잘 모름)
- 논문 base 구현
- 그리고 실제 데이터를 활용한 모델 배포 경험을 쌓는 것
세가지가 저에게 있어 보완해야 하고, 해당 경험이 매우 중요하다는 것을 여러 회사에 지원한 경험을 통해 인지하고 있기에 과정에 참여하게 되었습니다. 취업은 정말 거대한 하나의 고비이지만, 취업만을 위해서라기보다 실력을 쌓아나간다는 마인드로 과정을 잘 마치고 싶습니다!
오늘 공부해볼 것
- NLP 관련 두 가지의 큰 subtask를 통하여
- Word Embedding
- Roberta 모델
에 대한 이해도를 높여 봅시다.
1) Word Embedding
[https://corpling.hypotheses.org/495]
📌 task가 해결하고자 하는 문제?

[https://www.researchgate.net/figure/One-hot-vector-representation-and-embedding-representation-for-semantic-tags_fig2_331439739]
-
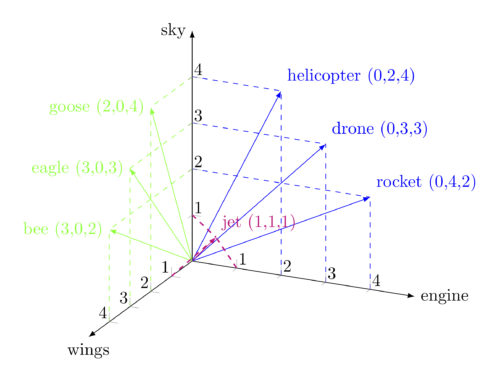
단어 간 유사도 보존을 위한 vector mapping 기법
-
벡터 간 거리 정보를 반영하고 있음
-
Onhe-hot Encoding으로 단어 매핑 시 발생하는 차원의 저주(Curse of Dimensionality)를 해결
-> Sentimental analysis, Text Generation, TTS 등 NLP 전반적인 모든 영역에 적용되는 개념
🧐마치 수학 연산을 하듯...
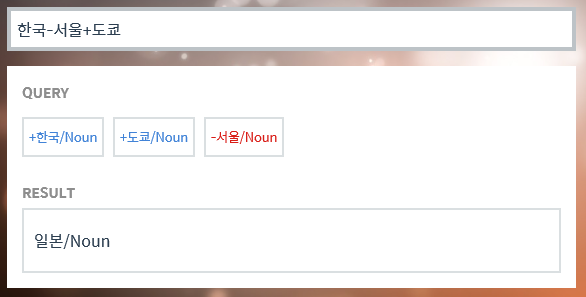
이렇게 결과를 얻을 수 있는 것은 유사도를 반영한 값을 가지고 있기 때문!
📌 데이터 소개
- real number가 포함된 vector 형태(일반적인 모델의 경우 200~500 차원)
- dense representation
- Dimension 값()을 hyperparameter로 정의한 후 각 단어를 학습시키며 Mapping함
- initialize 된 parameter()를 이용하여, 단어의 의미 및 단어 간 유사도를 잘 나타낼 수 있는 방향으로 학습
📌 라이브러리 소개
flair
- pytorch framework 활용한 NLP 라이브러리
- SOTA 모델을 다룰 수 있음
gensim
- python에서 Word2vec model를 불러올 수 있는 라이브러리
📌 Model 소개
1) Word2Vec
- 크게 skip-gram과 cBow 두 가지 기법이 있음
1)-a. CBow(Continuous Bang of words)
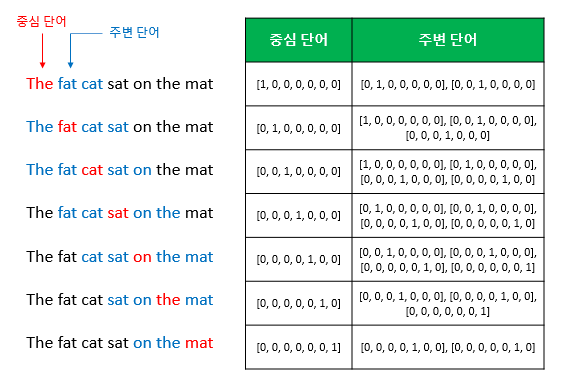
- 주변에 있는 단어들로 중간에 있는 단어를 예측하는 방법
- sliding window 기법으로 window size에 대한 hyperparameter 설정이 필요함
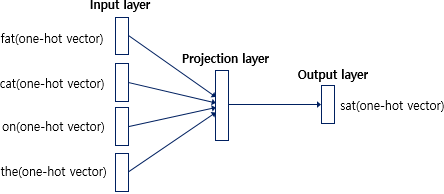
특징🤡
- input : 주변 단어들의 one-hot vector - output : 예측하고자 하는 단어의 one-hot vector - hidden layer가 하나이며, activation function이 존재하지 않는 것이 특징 - Projection layer : Lookup table 연산을 담당
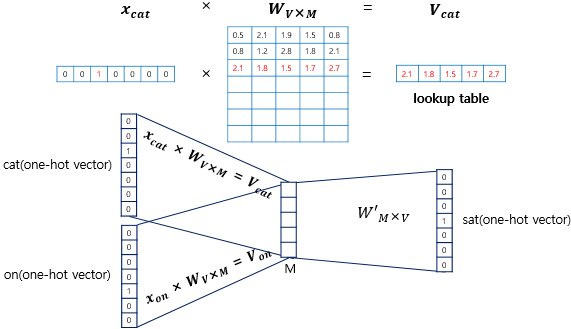
- One-hot vector의 차원 와, Embedding vector의 차원 , input layer의 가중치 와 projection layer의 가중치 에 대하여
1) one-hot vector와 값을 곱한 값은 해당 단어의 embedding vector가 됨
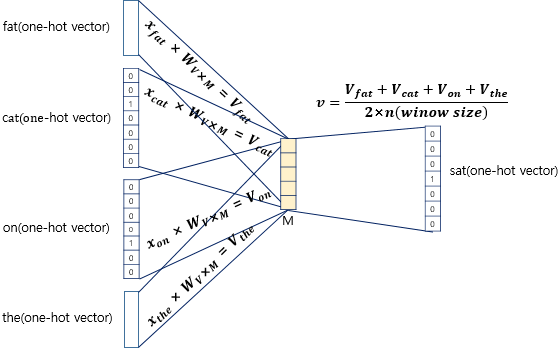
2) 이 각각의 embedding vector(주변 단어들)을 평균내어

3) 가중치 행렬 와 곱해지면 결과적으로 차원의 벡터가 나옴
4) Softmax function에 의해 Cross-entropy Loss로서 parameter를 update하게 됨
1)-b. Skip-gram
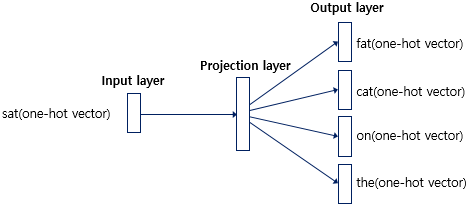
- 중심 단어로부터 주변 단어를 예측하는 방법
- CBoW와 과정이 유사하지만 projection layer에서 평균을 구하는 과정이 없음
- CBoW보다 성능이 좋다고 알려져 있음
2) LSA
- DTM 또는 TF-IDF 행렬 과 같이 각 문서에서의 단어 빈도수를 카운트한 행렬을 기반으로 학습하는 모델
- 차원을 축소(SVD) 하여 Latent Representation를 끌어내는 방법론
3) Glove
- LSA는 단어 의미 유추에서 좋지 않은 성능
- Word2Vec 은 유추 작업에서는 뛰어나지만 window를 설정하여 예측하므로 전체적인 통계 정보를 반영하지 못함
- 각각의 한계를 반영하여, 두 가지 방법론을 혼합하여 장점을 취한 형태!
main idea
- IDEA : 중심 단어 벡터와 주변 단어 벡터의 내적이 전체 코퍼스에서의 동시 등장 빈도의 로그값이 되도록 만드는 것
4)🧐 Fasttext(SOTA)
-
페이스북에서 개발한 Word2Vec 확장판
-
word2vec과 가장 큰 차이는, Word 의 하위 개념으로 여러 subword를 간주하여 학습
-
오타에 강건하고, 빠르고, 지도(supervision) 또는 별도의 전처리를 필요로 하지 않음
keyword
- subword, skip-gram, CBow, word representation, morphology, quantization
Reference
2) Sentimental Analysis
- positive, negative, neutral로 텍스트에 담겨진 감정을 분석
- ML-based, lexicon based 방법이 있으며 섞어서 쓰기 가능
📌 task가 해결하고자 하는 문제?
- 컨텐츠의 평가와 관련된 정성적 분석을 통해 핵심적인 feature로 활용할 수 있음(이후 추천 시스템 등 활용)
📌 데이터 소개
- SST, GLUE, IMDB 등이 있음
1) GLUE(General Language understanding Evaluation)
- 자연어 이해의 성능을 위한 dataset
왜 개발되었나?🤔
- transfer learning을 위한 모델 평가 방법론의 필요성 대두
- 강건성(Robustness) 및 범용성(versatility)를 전체적으로 평가
- 11개의 task로 비교적 일반화된 성능을 체크를 숫자로 체크할 수 있음!

- fine-tuning이후의 새모델을 이전 모델과 비교하여 훈련 및 평가할 수 있게 됨
Codes😉
GLUE 데이터셋 다운로드 받기
tensorflow tfds로 GLUE dataset 접근하기
2) IMDB dataset
- 영화 감상평에 대한 text를 포함하는 데이터셋
📌 SOTA Model 소개
1) BERT
- Transformer Model의 Encoding 구조를 따온 pre-trained model
- Masked Language Model(문장 내 관계), Next Sentense Prediction(문장 간 관계) 활용하여 Bidirectional하게 구축된 Language model
- fine-tuning에 특화된 모델이며, semi-supervised 모델로 별도의 training dataset이 필요 없음
2) RoBERTa
- Bert의 개선된 버젼
어떤 점이 개선되었나?
1. Static Masking -> Dynmaic Masking
- training data를 복제해서, epoch 별로 다르게 masking 하여 학습
2. 'NSP loss' deletion
- 제거 시 loss 향상
3. Training with Large batches
- mini batch size 증가 (256 -> 8K)
4. Text encoding
- Byte-pair Encoding으로 훨씬 더 많은 양의 데이터를 학습할 수 있게 됨
Reference

4개의 댓글


짧은 시간이었는데 정말 꼼꼼하게 정리를 해주셨네요!😲 word embedding은 nlp에서 핵심 task중 하나 같아요! 그중에 fasttext는 OOV문제를 해결 할 수 있다는 엄청난 장점이 있죠! 잘 봤습니다. :)
워드 임베딩이 상세해서 도움 많이 됐습니다