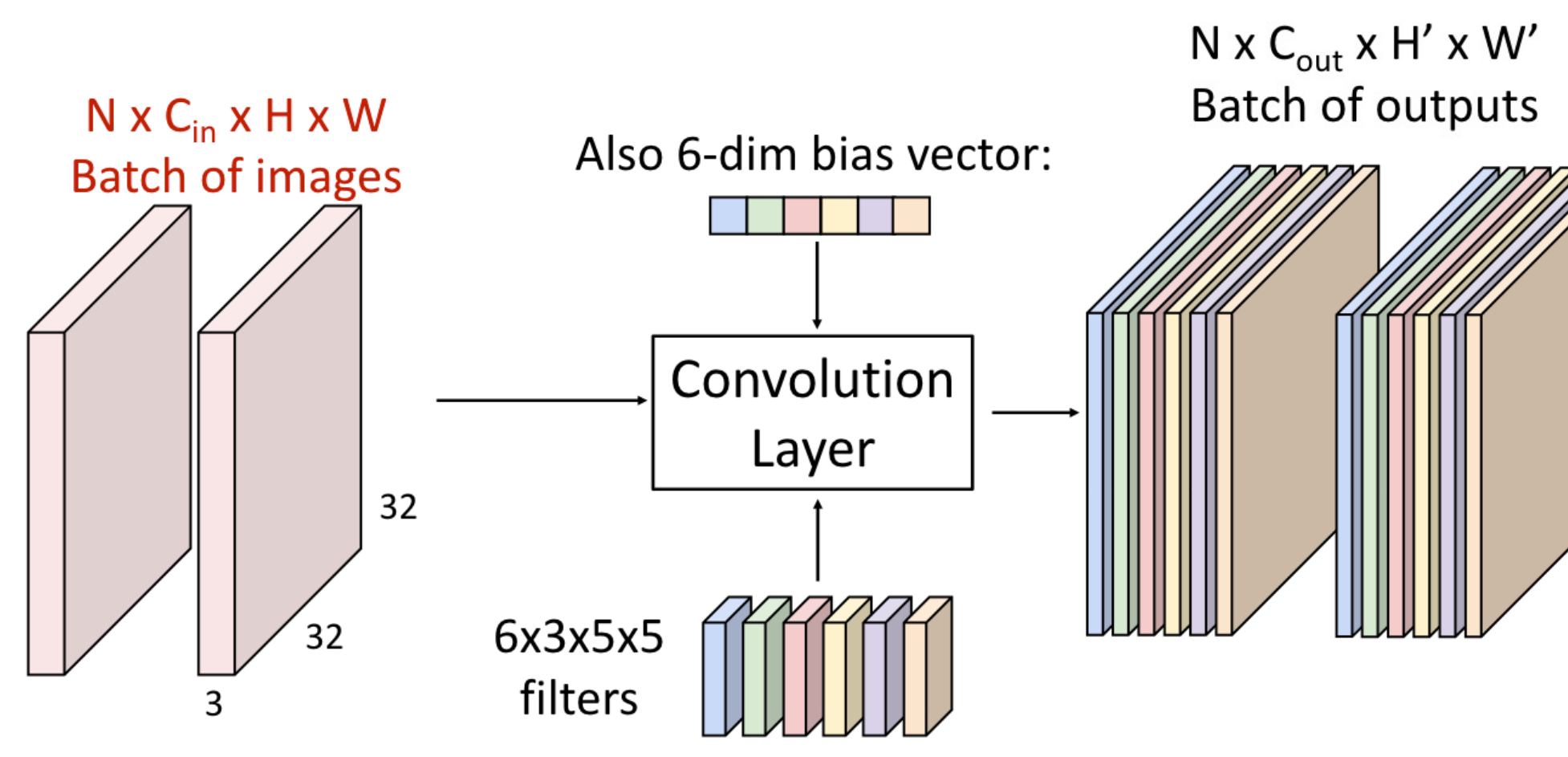
Convolution

- Kernel 크기 만큼 Input에 적용하여 모두 확인함
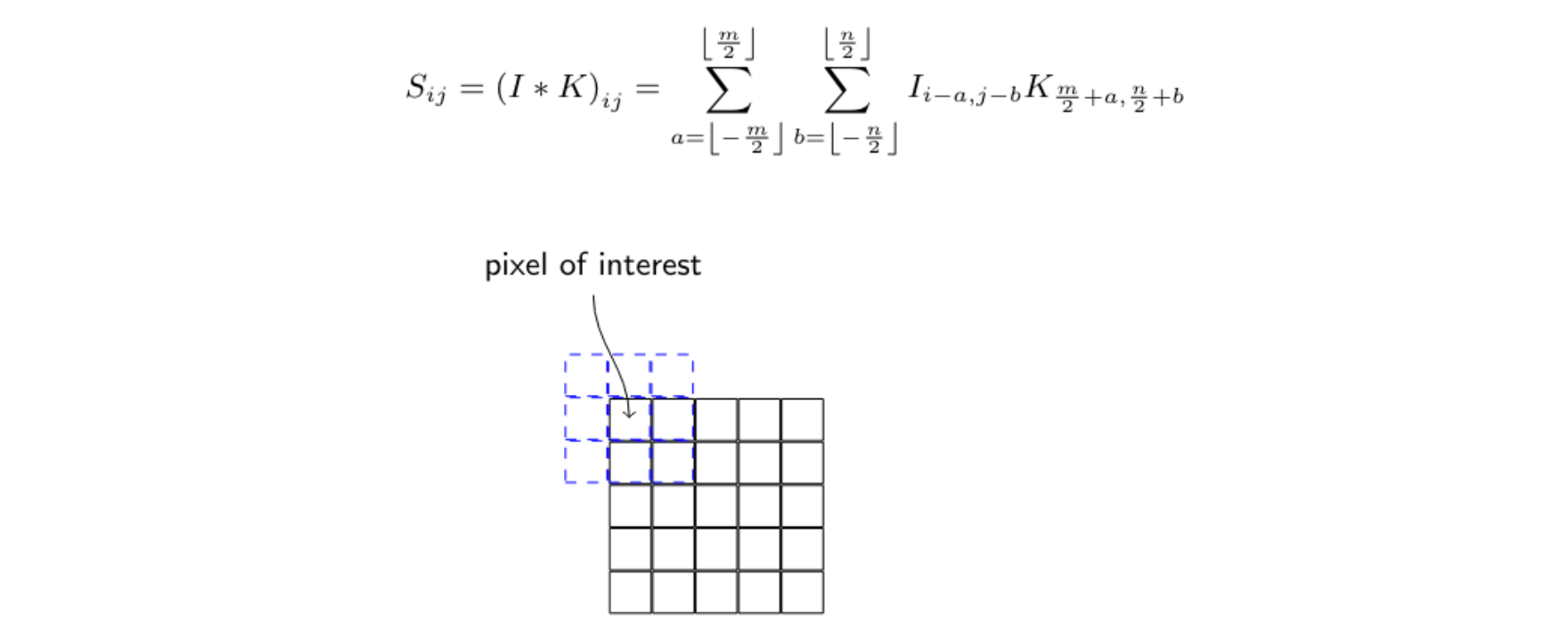
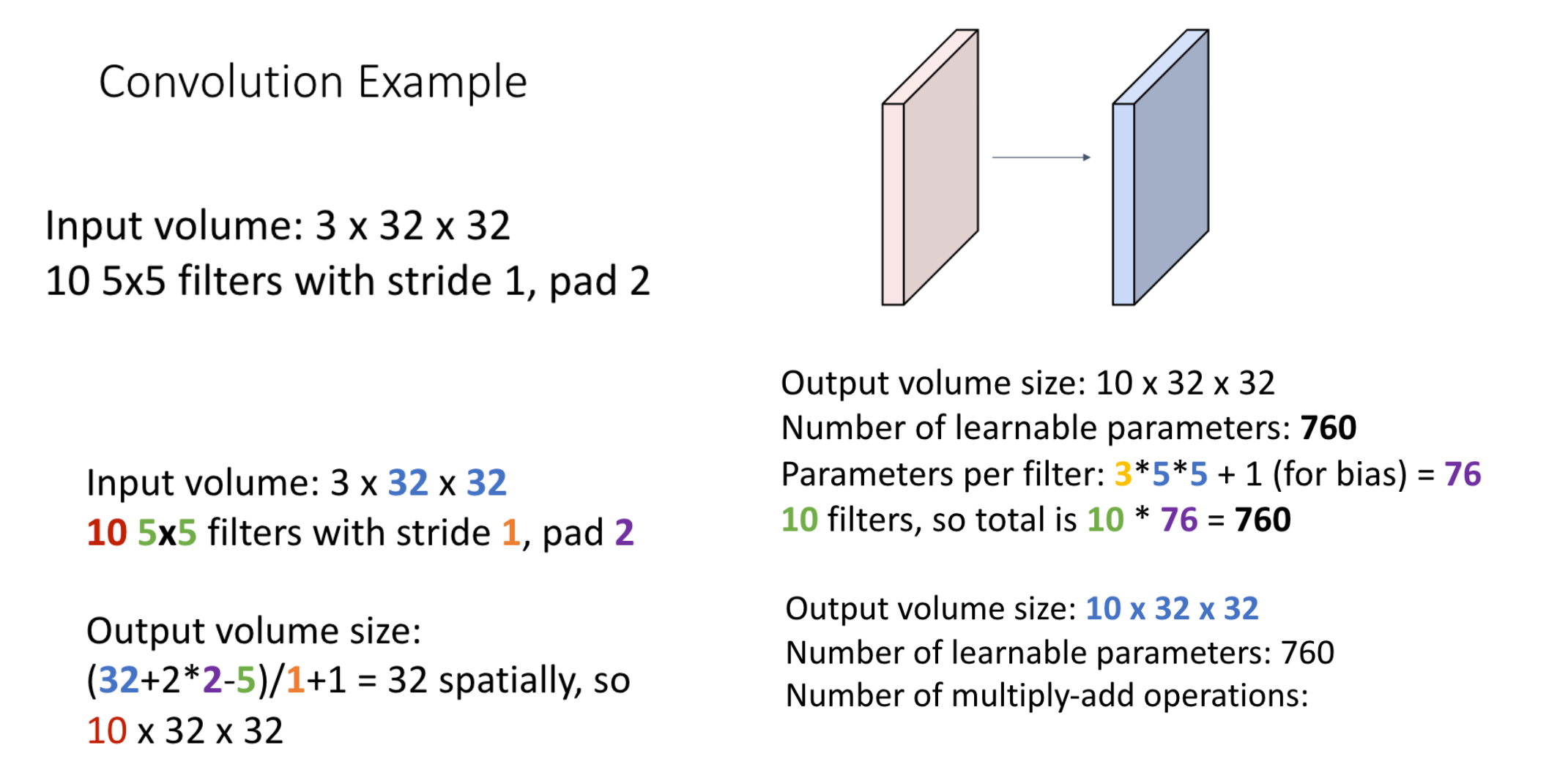
Convolution 적용 예
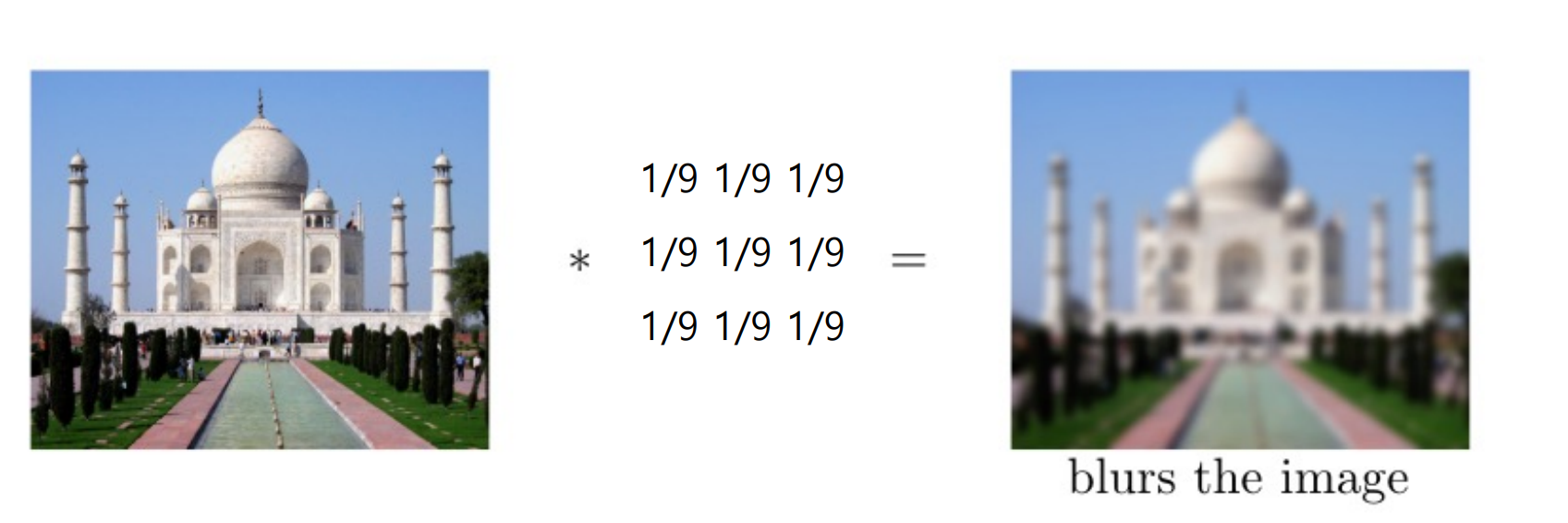
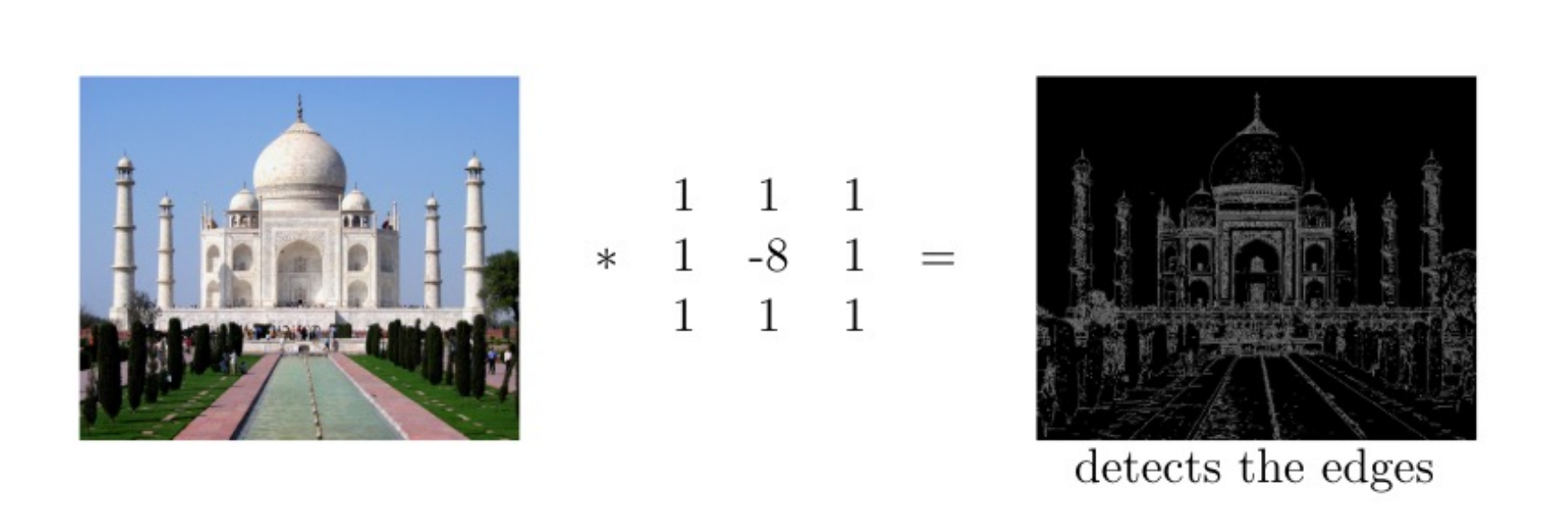
계산
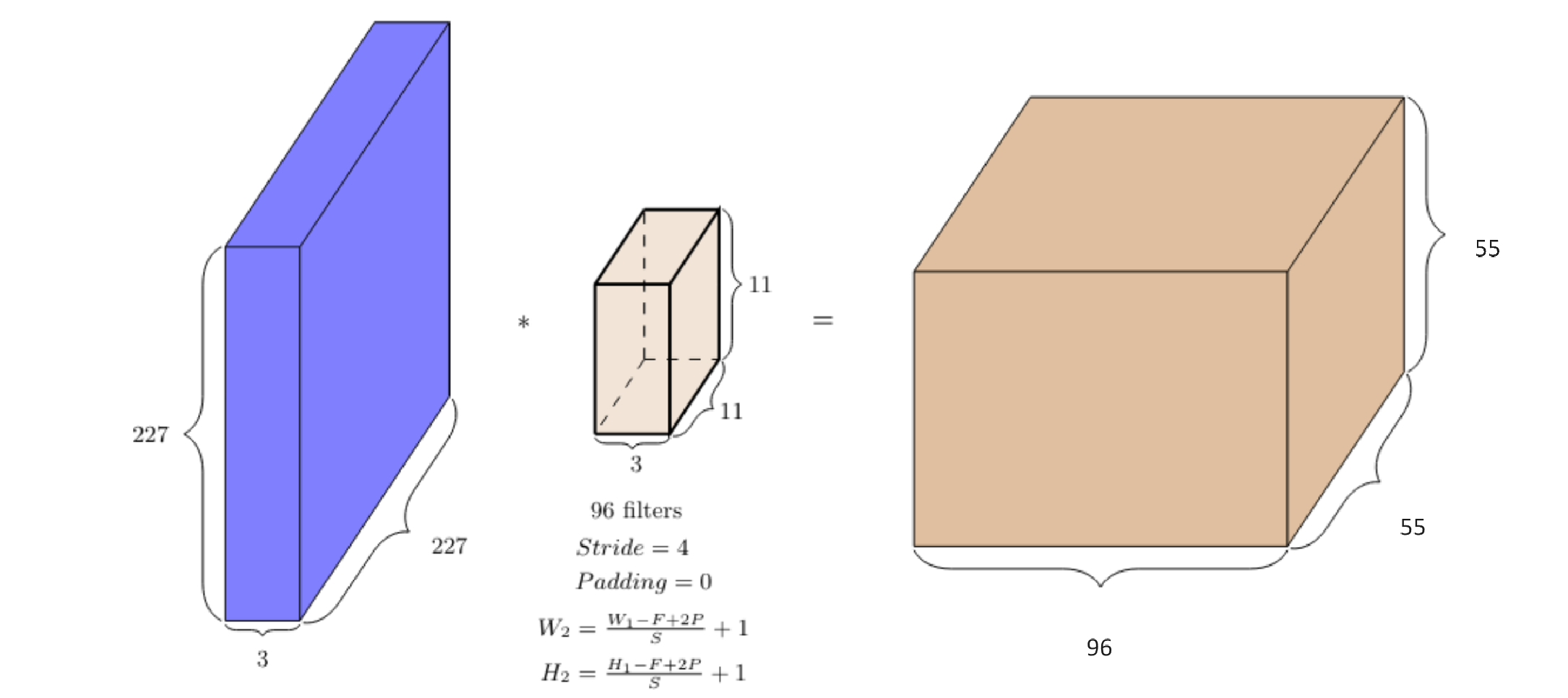
계산 정리
W: input의 너비
H: input의 높이
D1: input의 깊이(depth)
k: 필터의 개수
F: 필터 size
P: padding
S: Stride
Padding을 넣는 이유
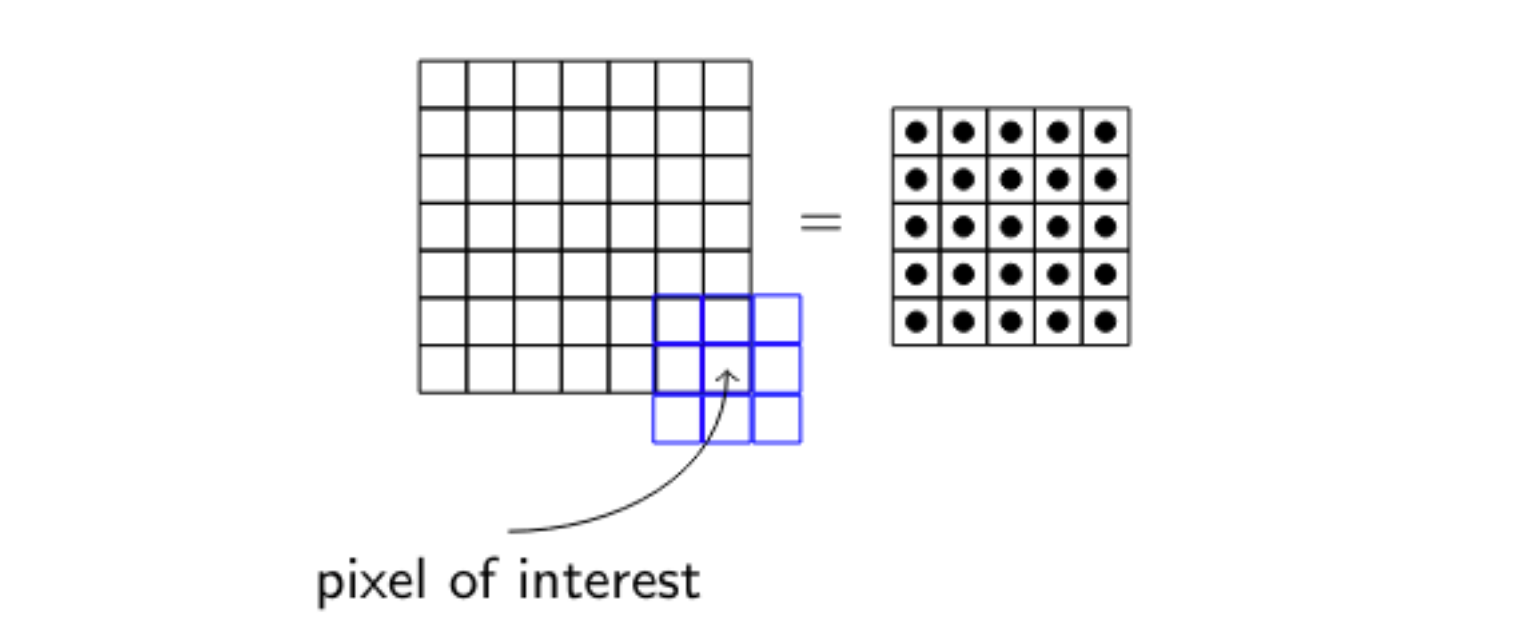
- 위의 사진처럼 커널이 입력 경계를 넘어가기 때문에 모서리에 배치할 수 없다.
- input보다 output의 공간이 작아지는 결과가 나온다
- 커널 사이즈가 커질 수록 더 많은 픽셀들을 입력할 수 없다
- 그래서 input과 output의 사이즈가 같아지길 원할 때 Padding을 사용한다
- 입력을 적절한 0개의 입력으로 채워서 이제 모서리에 커널을 적용할 수 있다
CNN
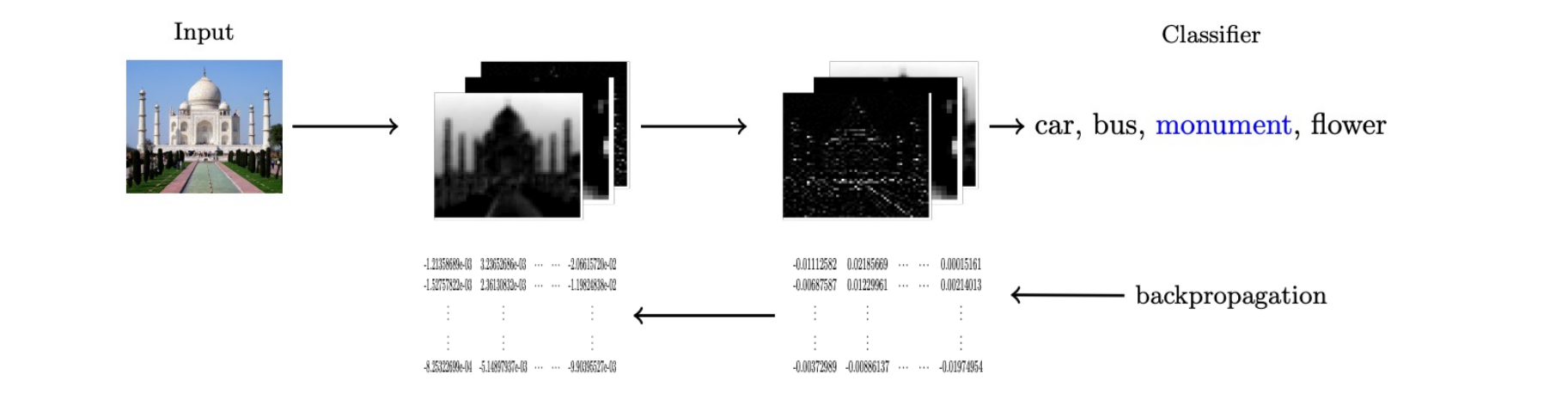
- 커널을 parameter로 단순히 다루고 분류기의 가중치에 추가하여 학습함(역전파를 이용)
feedforward neural network와의 차이점
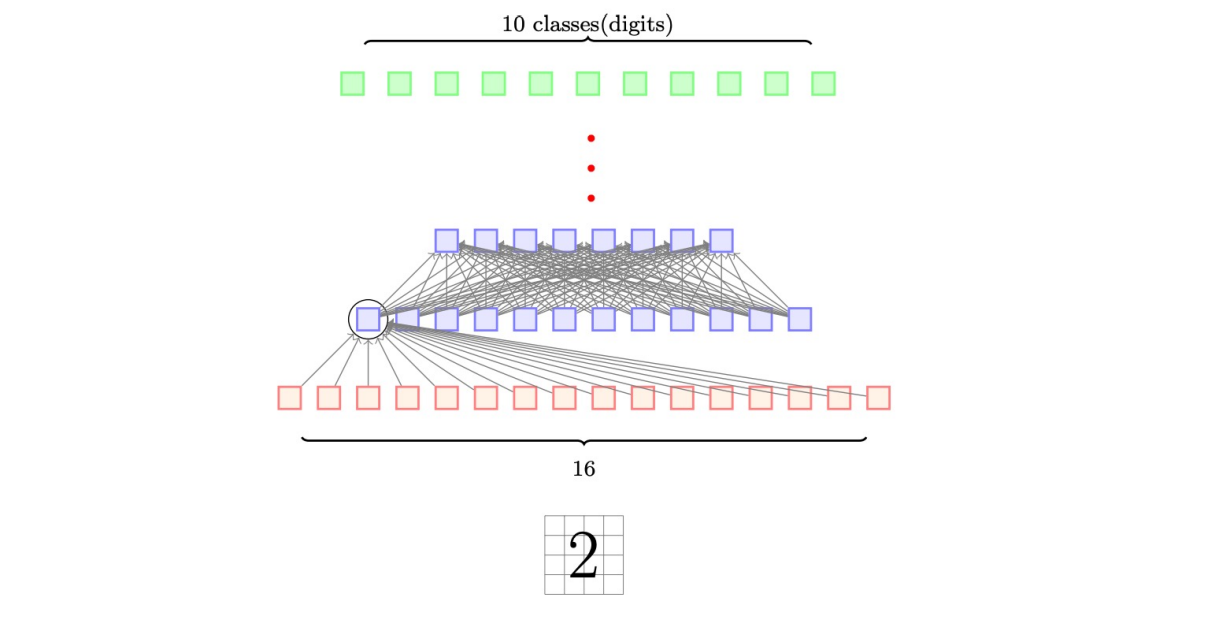
- 밀집된 많은 연결들이 있음
- 16개 모든 입력된 뉴런이 h11에 영향을 준다
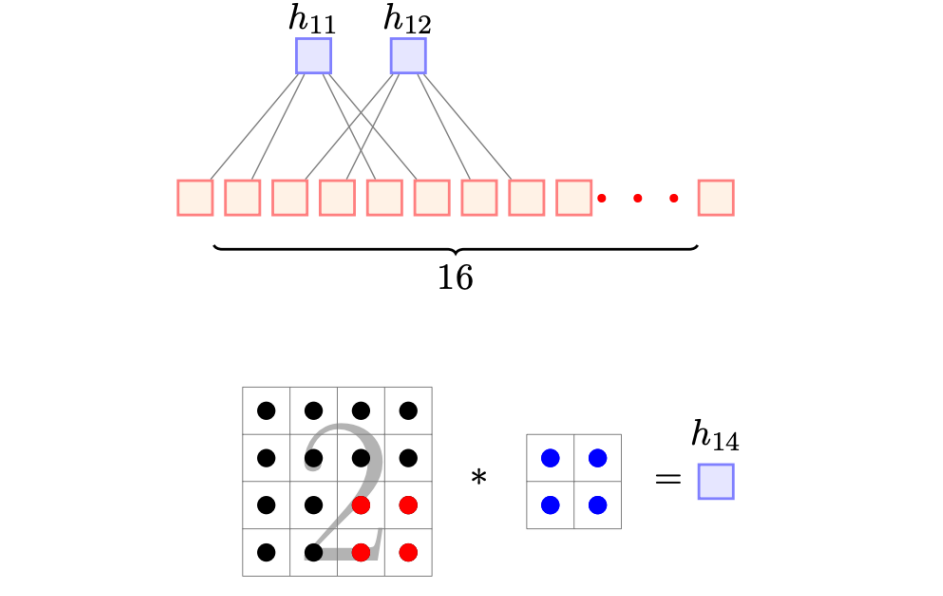
- 근데, CNN은 일부 뉴런들만 영향 h11에 영향을 준다
- 이미지 구조의 이점을 가져감
- 이웃하고 있는 픽셀들의 상호작용이 더 interesting 함.
- 이미지 구조의 이점을 가져감
- 이 희박한 연결(sparse connectivity)은 모델의 파라미터 수를 줄여줌
- 근데 이러면 픽셀의 정보를 잃는 것이 아닌가? 과연 좋은 건가?
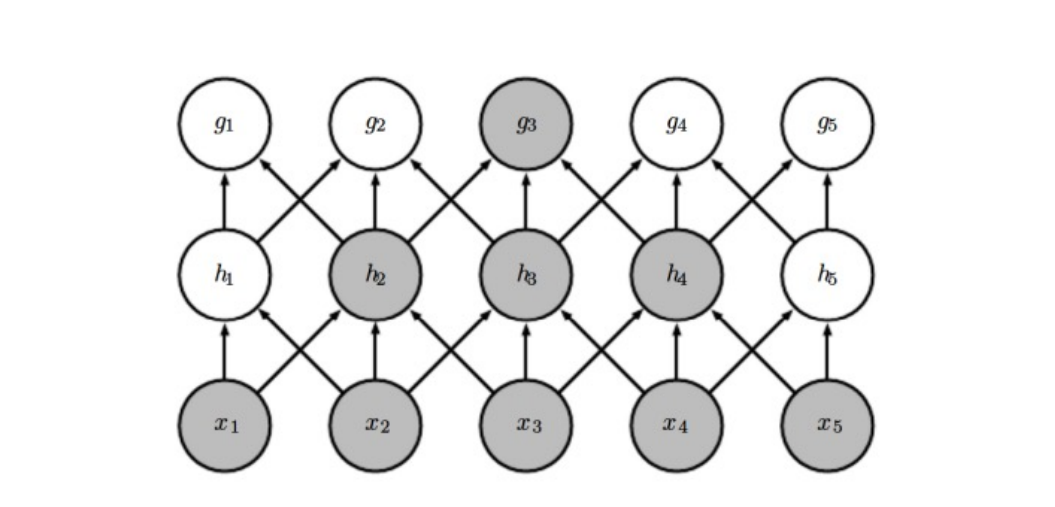
- 는 layer1 과 상호작용 하지 않음
- 그러나, 에 계산에 간접적으로 기여한다
weight sharing
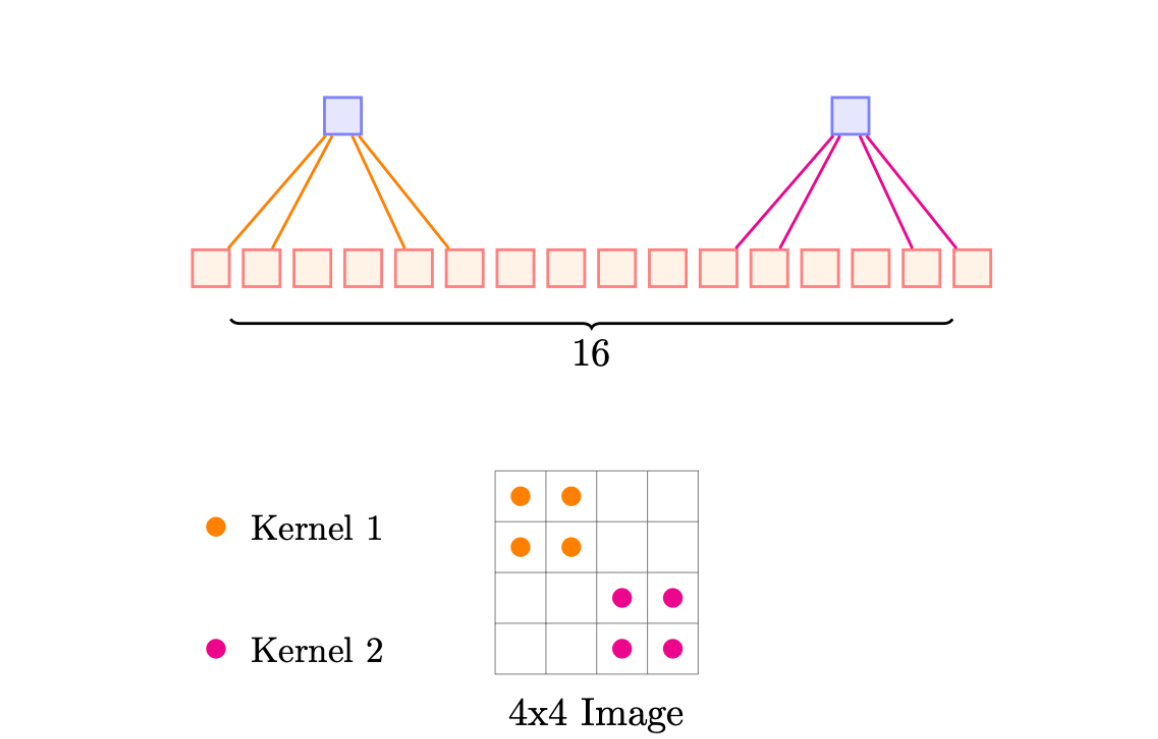
- 다른 부분의 다른 커널 가중치를 원할 때 사용
- 이미지의 모든 부분에 대해 같은 커널을 써야하지 않나?
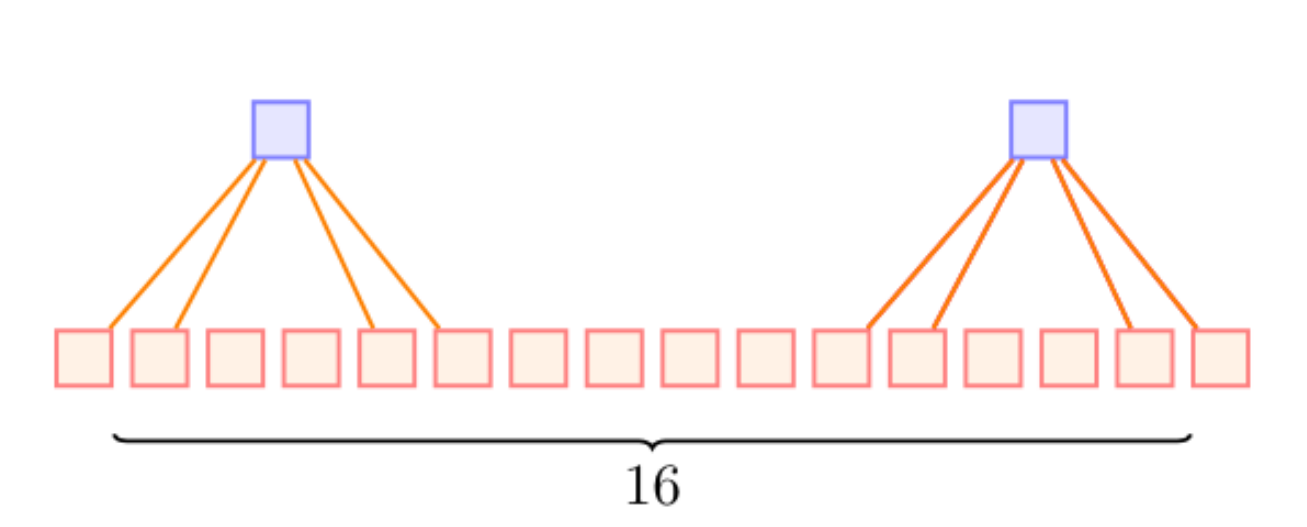
- 이미지의 모든 부분에 대해 같은 커널을 써야하지 않나?
- 이 방식이
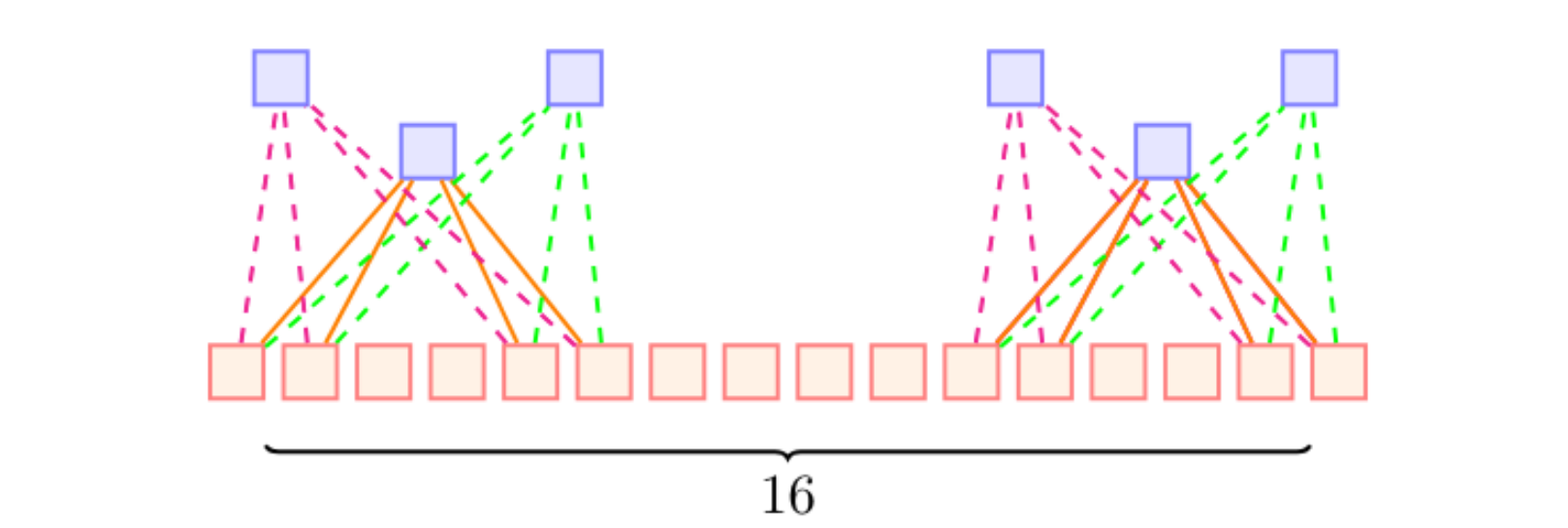
- 이미지의 모든 부분에서 커널들이 공유될 수 있다 = weight sharing
- 가중치 공유를 통해 파라미터 수를 감소할 수 있다
Pooling layer
pooling = downsampling?
네트워크의 파라미터 갯수나 연산량을 줄이기 위해 input에서 spatial 하게 downsampling을 진행해 사이즈를 줄이는 역할
-> 즉, feature map의 weight parameter를 줄이기 위함.
pooling: filter를 걸쳐서 input을 resizing함.
maxpool
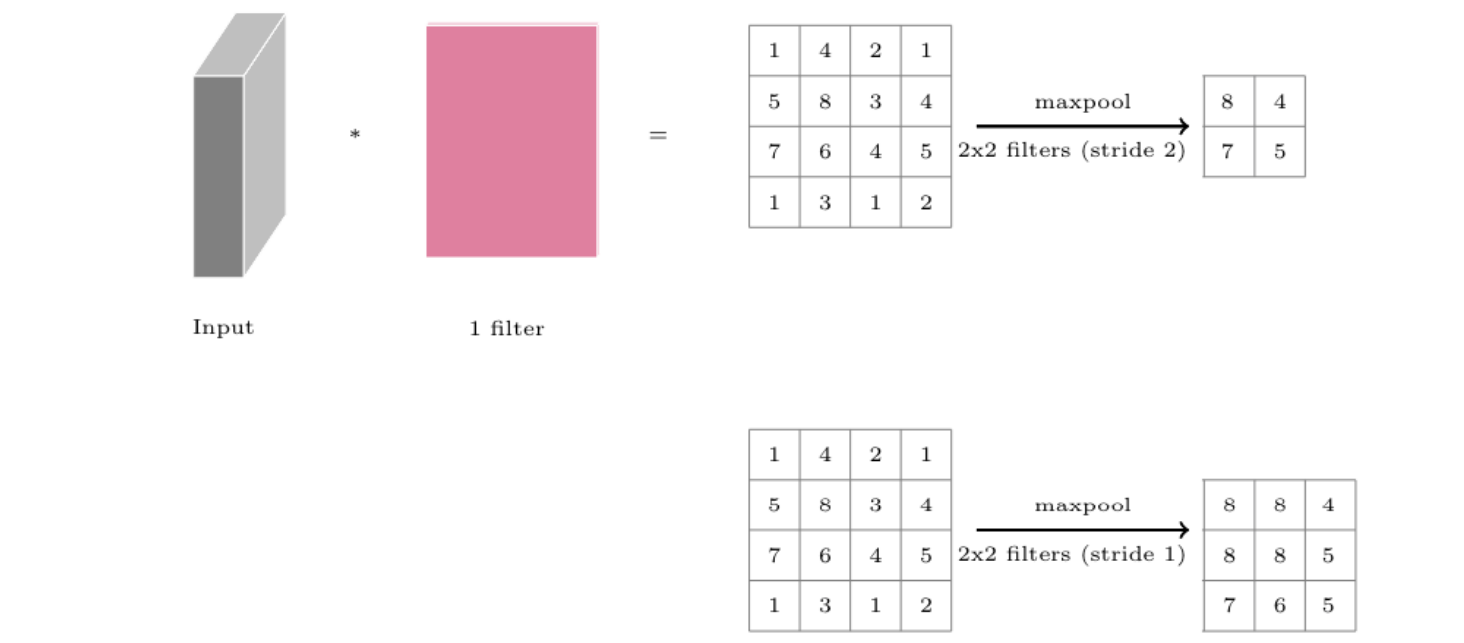
- maxpool은 average pool과 달리 최고 값만 가져옴
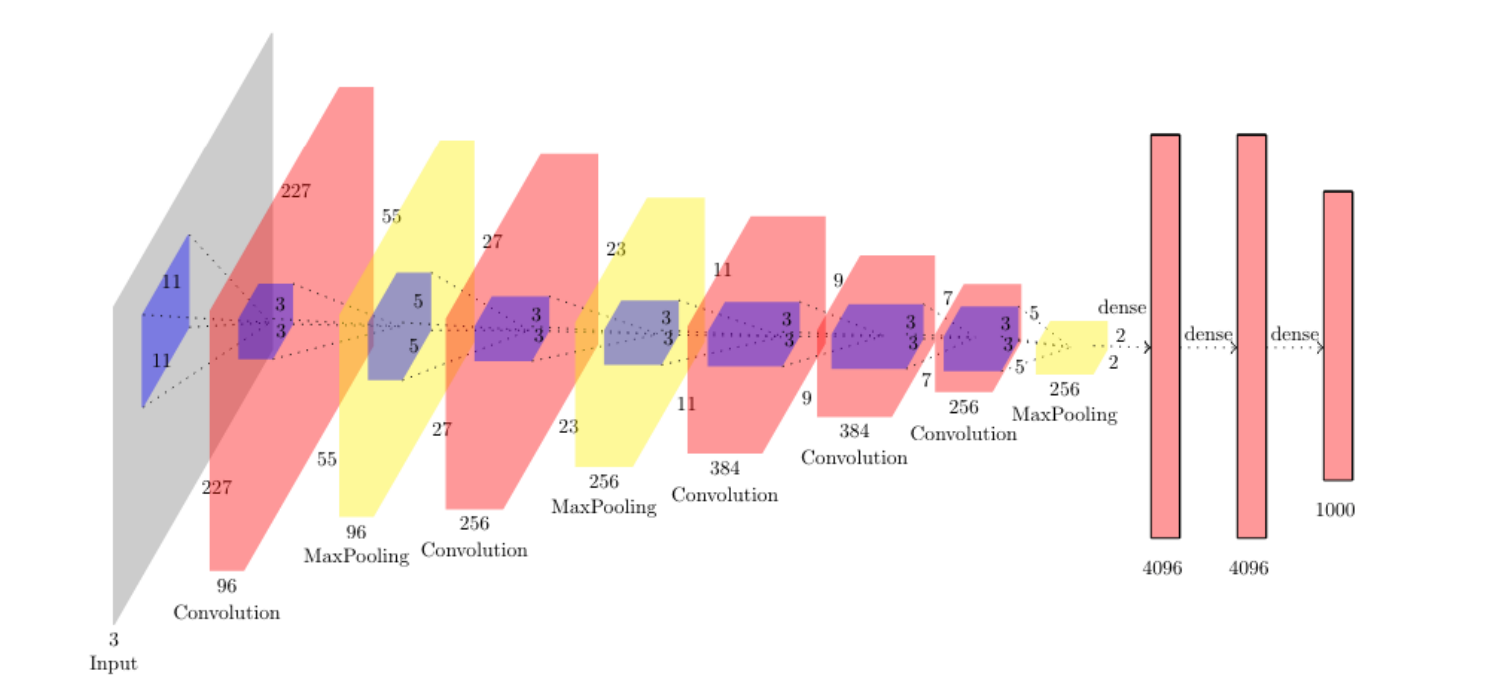
AlexNet
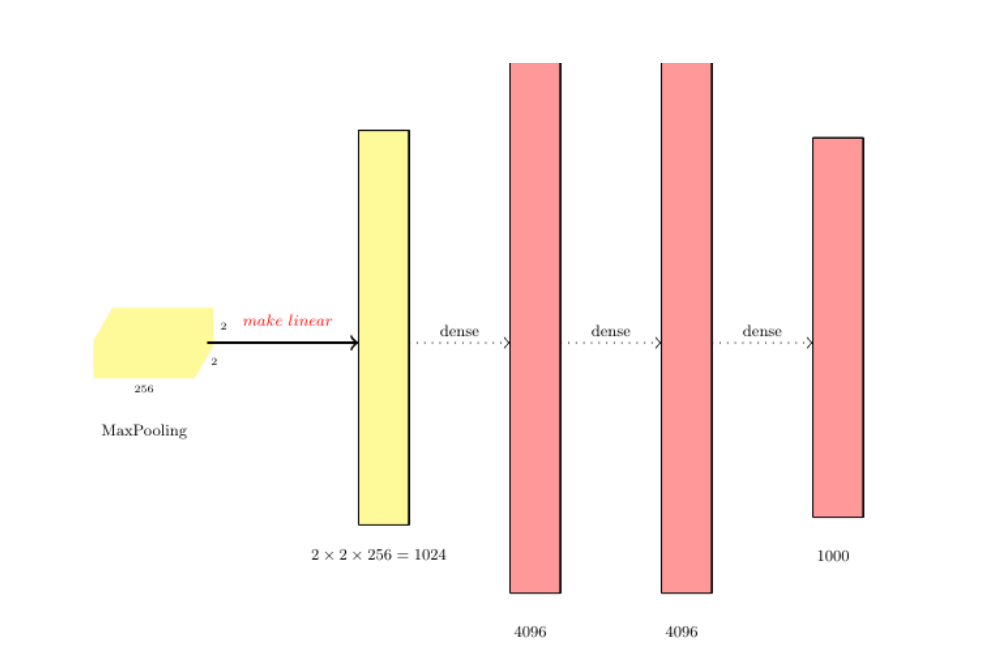
Fully connected layer(FC layer)
- 마지막 convolution layer나 maxpool layer를 확장하여 1차원 벡터로 만든다
- 이 일차원 벡터는 평범한 feedforward 뉴런 네트워크 안에서 처럼 다른 layer들과 밀접하게 연결된다
FC layer의 역할
- 2차원 배열 형태의 이미지를 1차원 배열로 평탄화
- 활성화 함수(Relu, Leaky Relu, Tanh,등)뉴런을 활성화
- 분류기(Softmax) 함수로 분류
AlexNet 계산 정리

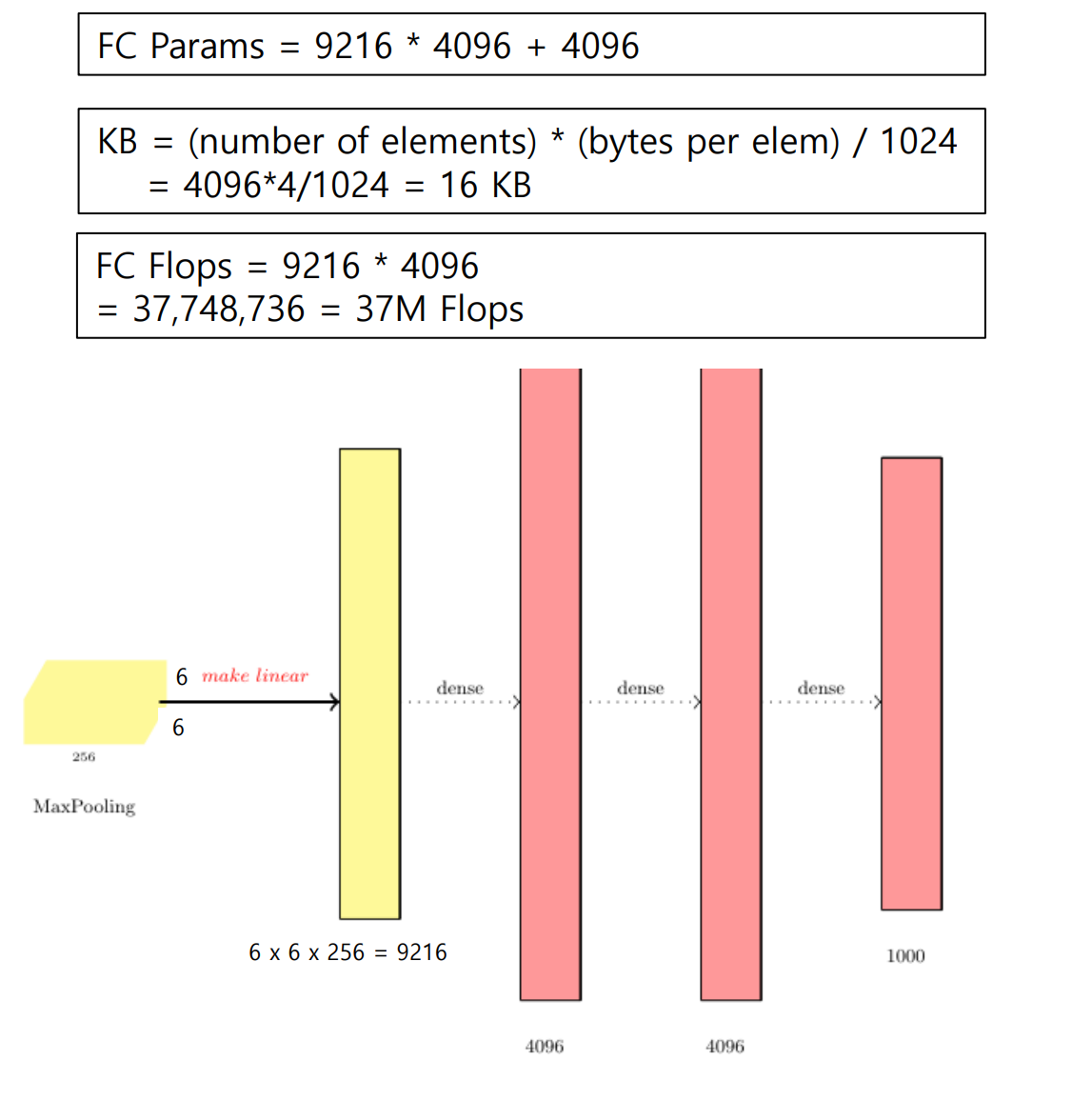
AlexNet 특징 정리
• 227 x 227 inputs
• 5 Convolutional layers
• Max pooling
• 3 fully-connected layers
• ReLU nonlinearities
- 높은 공간 해상도와 필터사이즈를 가짐
- 메모리 사용량 대부분은 Conv layer 초반에서 씀
- 거의 모든 파라미터들은 fc layer에 있음
- 대부분의 floating-point 계산들은 conv layer에서 발생한다

CNN Models
ZFNet
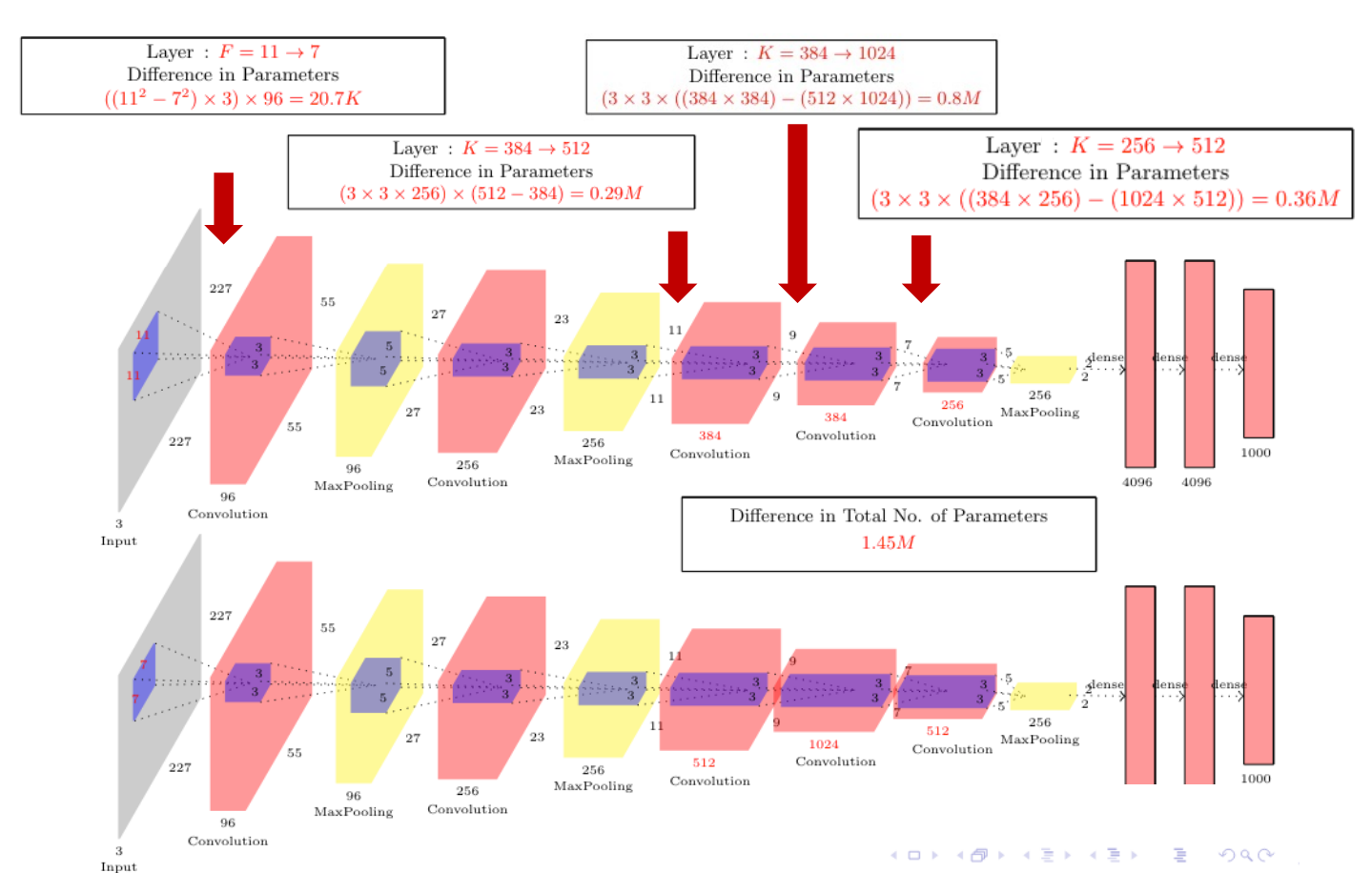
- ImageNet top 5 error: 16.4% -> 11.7%
- CONV1: change from (11x11 stride 4) to (7x7 stride 2)
- CONV3,4,5: instead of 384, 384, 256 filters use 512, 1024, 512
VGGNet
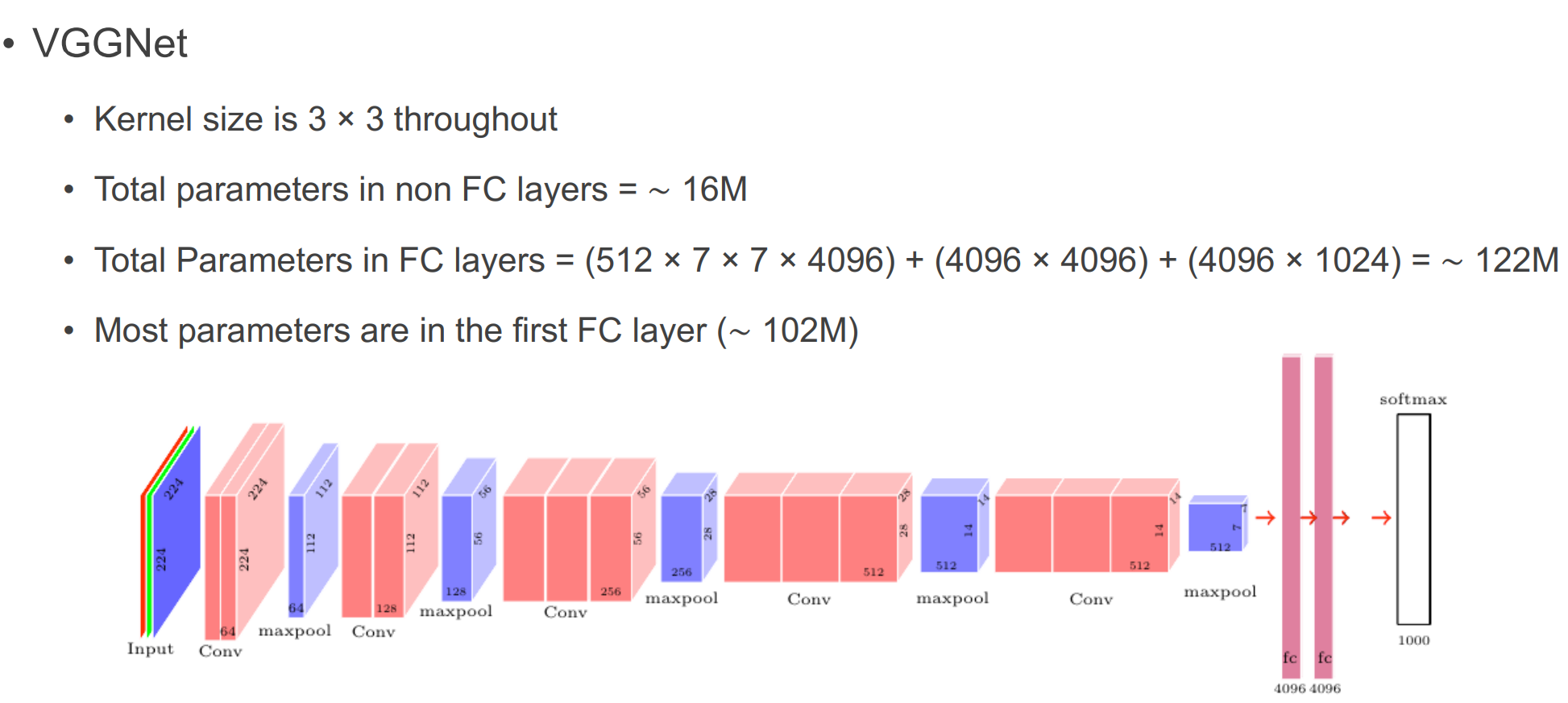
- VGG Design rules:
- All conv are 3x3 stride 1 pad 1
- All max pool are 2x2 stride 2
- After pool, double #channels

- 3x3 conv layer 2개는 같은 receptive field를 가지면서 parameter 수를 줄이고 더 적은 계산량을 가진다
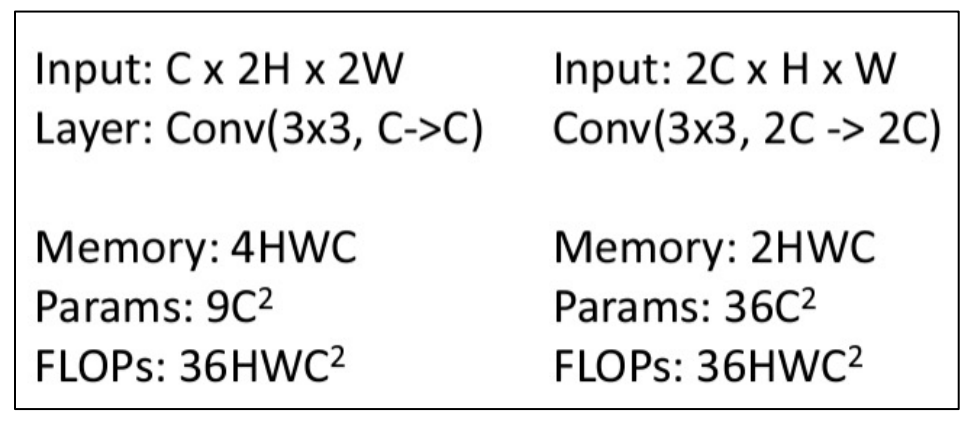
- 채널 수를 줄이고 W,H를 늘리면 메모리 사용량은 많지만 파라미터 수를 줄일 수 있음. 계산량은 동일함.
Convolutional layer
Conv layer는 Input의 feature를 추출하는 레이어다
Parameter 수 계산
Parmeter 수의 계산
: Conv layer의 가중치 개수
: Conv layer에서 사용되는 kernel size
: input image의 채널 수
: kernel 개수
- ppt에 나온 식으로 사용하면
:
filter는 무엇을 배울까?
- 첫 layer conv filter는 local image templates
- 방향을 잡은 가장자리, 반대되는 색을 학습함
Receptive Fields
- 출력 레이어의 뉴런 하나에 영향을 미치는 입력 뉴런들의 공간 크기
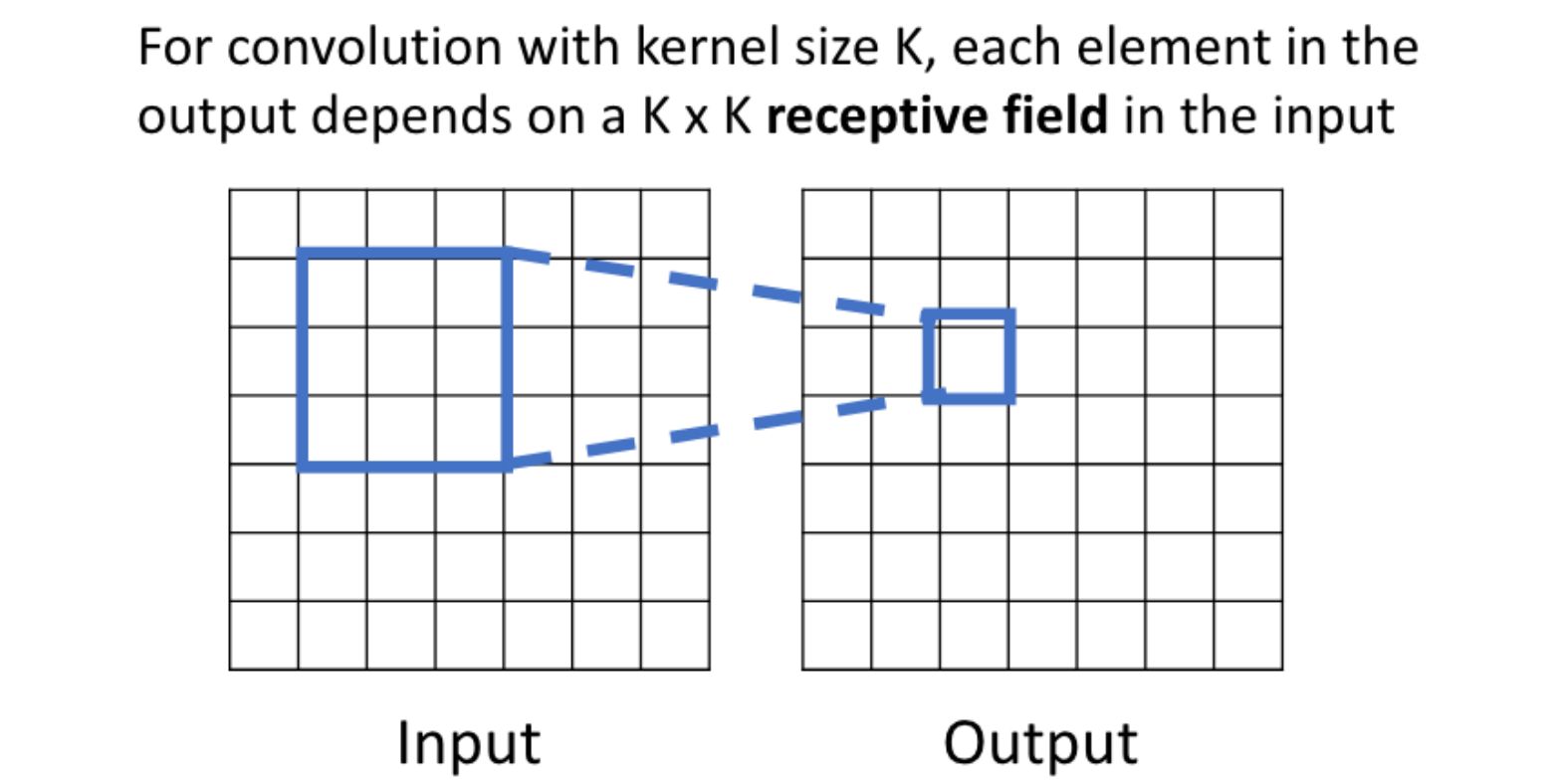
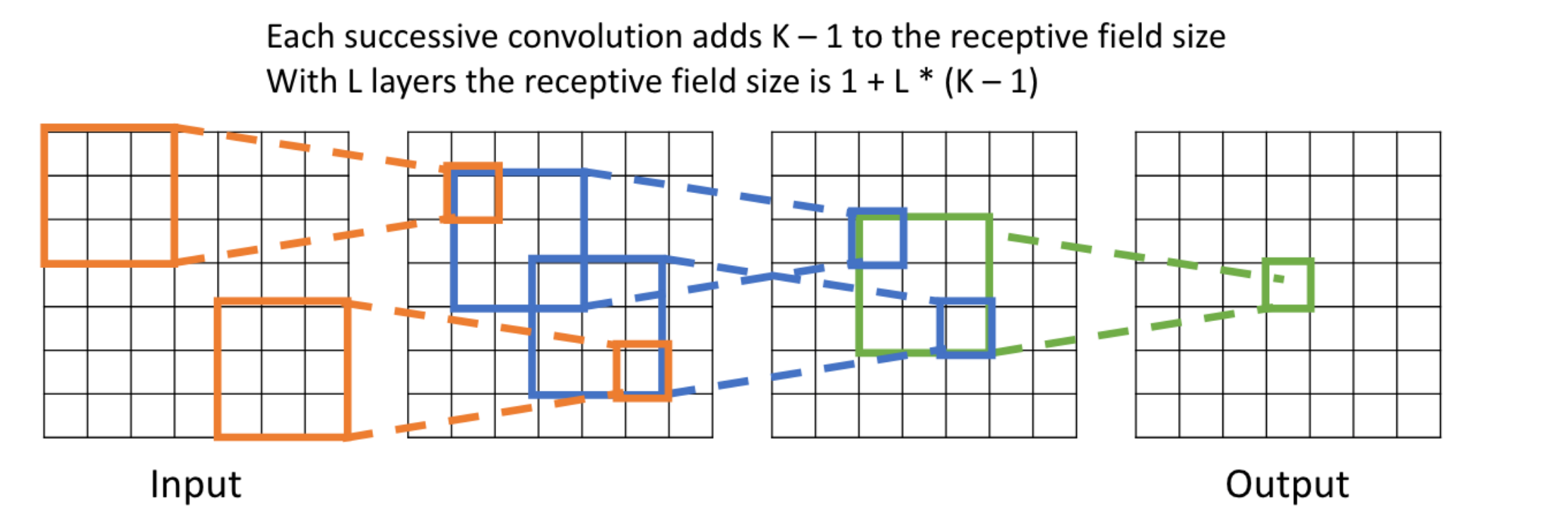
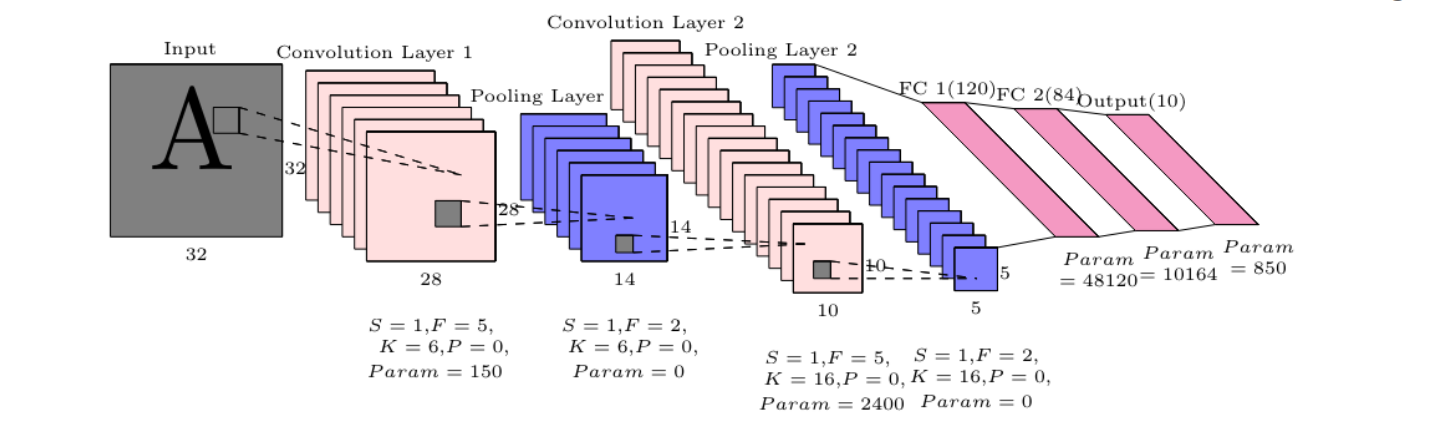
LeNet-5
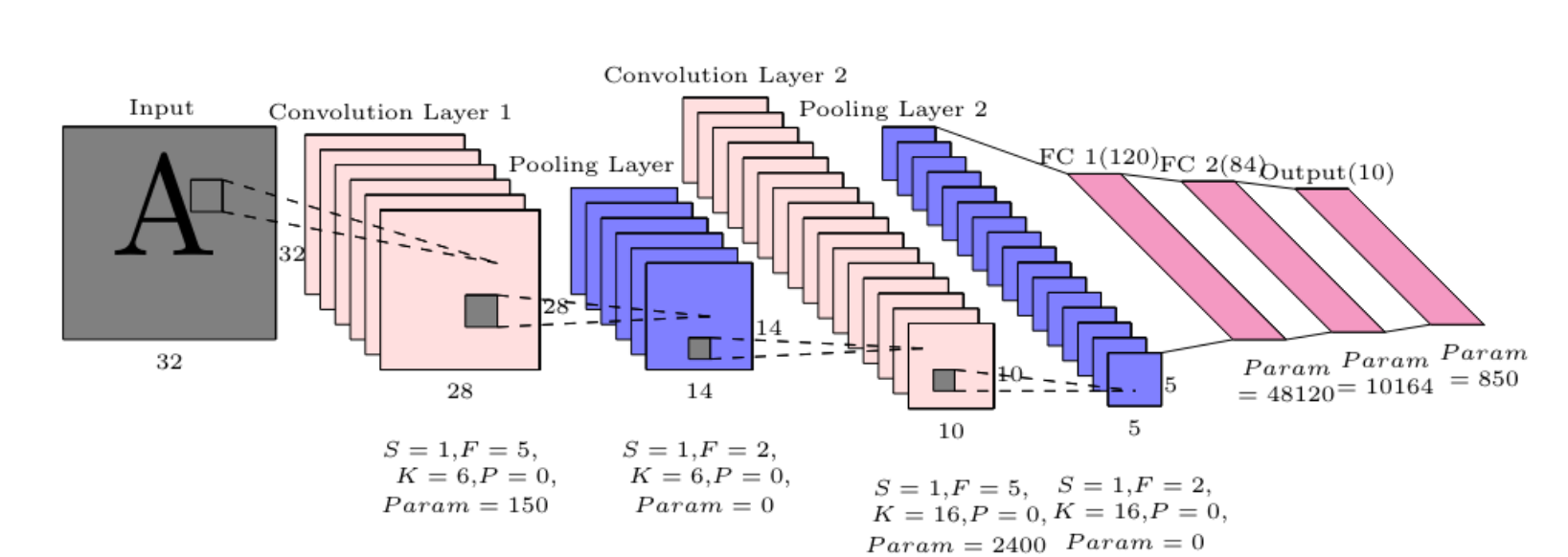
- LeNet-5 모델을 이용해 손으로 쓴 글씨를 인식할 수 있음
- Pooling, Convolution layer Stride -> 공간은 줄어든다
- 채널의 수는 증가함 -> 총 볼륨은 유지됨
- 근데 최근 모델들은 이러한 트렌드를 깨고 있음
1x1 convolution
- 채널 수를 조절하여 필요한 파라미터 수를 줄일 수 있다
GoogLeNet
- 효율성에 초점을 둔 모델: 파라미터 수, 메모리 사용량, 연산량 감소
굳이 Conv, Pooling, filter 중에 꼭 선택해야 할까?
-> 다 쓰면 안 될까? 해서 고안됨.
공격적인 줄기 구조
Inception Module
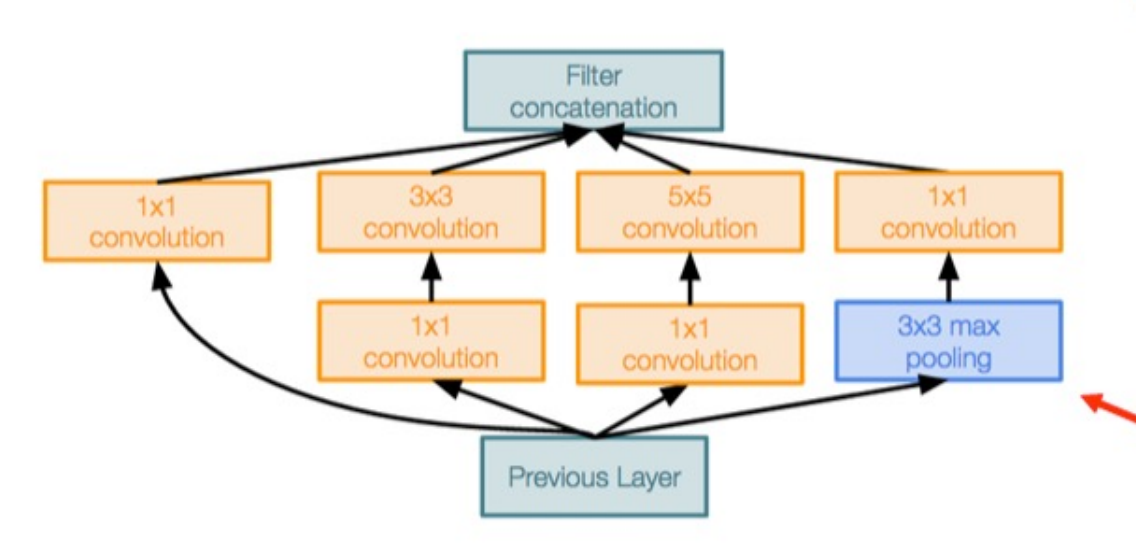
- 병렬 가지로 된 Local unit
- 1x1 "Bottlenetck" layer를 사용하여 conv 하기 전에 채널 수를 줄여 둔다.
Global Average Pooling
- 끝에 큰 FC layer가 없음
- 대신 글로벌 평균 풀링을 사용하여 공간 차원을 축소하고 한 개의 선형 레이어를 사용하여 클래스 점수를 생성합니다
Residual Network
- 심층 모델은 얕은 모델보다 성능이 떨어집니다
- 초기 추측: 딥 모델은 다른 모델보다 훨씬 크기 때문에 overfitting 된다.
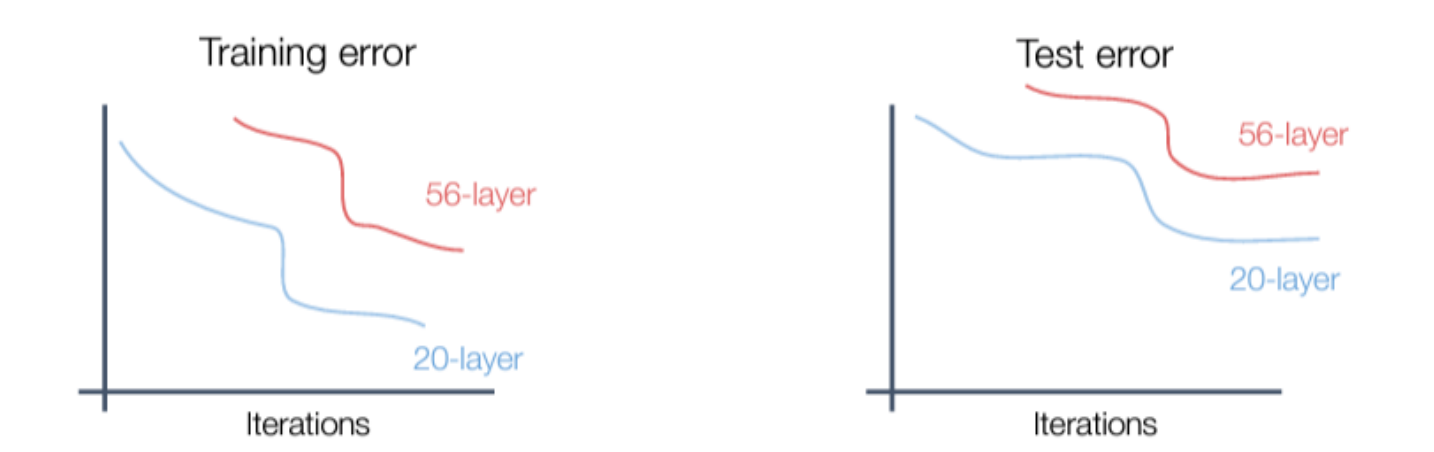
- 실제로 딥 모델은 training set의 shallow 모델보다 성능이 떨어지기 때문에 underfitting된 것 같습니다. 실제로도 그럼.
- 더 깊은 모델은 더 얕은 모델을 모방할 수 있습니다. 더 얕은 모델에서 레이어를 복사하고 추가 레이어를 identity로 설정
• 따라서 더 깊은 모델은 최소한 얕은 모델만큼의 성능을 발휘해야 합니다
• 가설: 이것은 최적화 문제이다. 더 깊은 모델은 최적화하기가 더 어렵고, 특히 얕은 모델을 모방하기 위해 항등 함수(identity function)를 배우지 않습니다
• 해결책: 네트워크를 변경하여 추가 계층으로 identity function을 쉽게 학습 가능
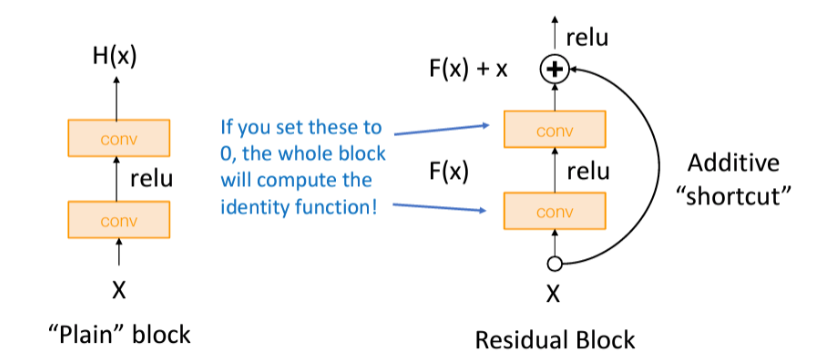
- residual network는 많은 residual block을 쌓은 것임.
- VGG와 같은 설계에서: 각 residual block은 2개의 3x3 conv 으로 구성
- 네트워크는 stage 안으로 나뉨: 각 스테이지의 첫 블럭은 해상도를 절반으로 줄이고(stride:2 conv) 채널 수를 2배로 늘린다.
downsample
- residual block을 적용하기 전에 GoogleNet처럼 aggressive stem을 사용하기 위해 input을 4배 downsample 합니다.
- GoogLeNet처럼, 큰 fully-connected-layer가 없다: 대신 global average pooling을 사용하고 끝에 단일 선형 layer를 사용함


- layer가 많아질 수록, 계산 비용이 줄어든다.
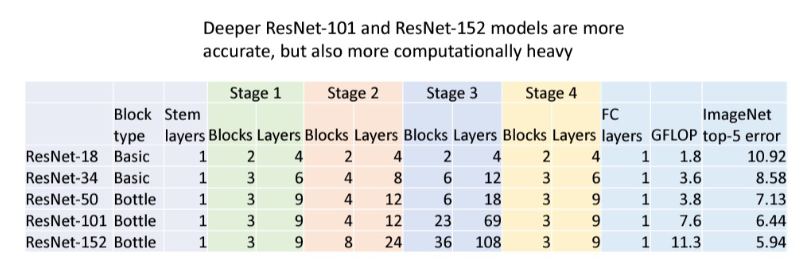
- ResNet-101, 152가 더 정확하지만 계산량도 많아짐.
- 매우 깊은 네트워크를 학습 가능
- 심층 네트워크는 얕은 네트워크보다 더 잘 함.
- 2015년 대회에서 수상함.
- 여전히 널리 쓰이는 중이다
복잡도 비교
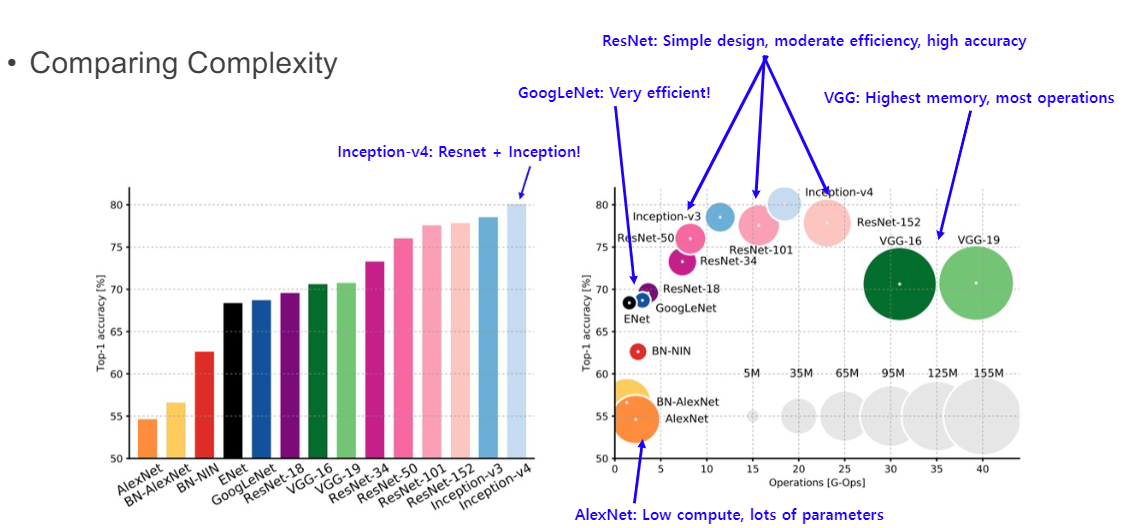
- GoogLeNet: 매우 효율적임
- ResNet: 간단한 디자인, 평범한 효율, 높은 정확성
- VGG: 높은 메로리, 많은 계산량
- AlexNet: 적은 계산량, 많은 파라미터
Choosing Hyperparameters
Grid Search
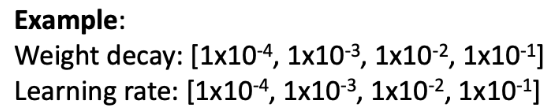
- 각 하이퍼파리미터의 값을 선택해야 함
- 하이퍼파라미터 grid 위에서 가능한 모든 선택들을 평가한다.
Random Search

- 각 하이퍼파라미터의 값 선택
- 여러 번의 다양한 시도
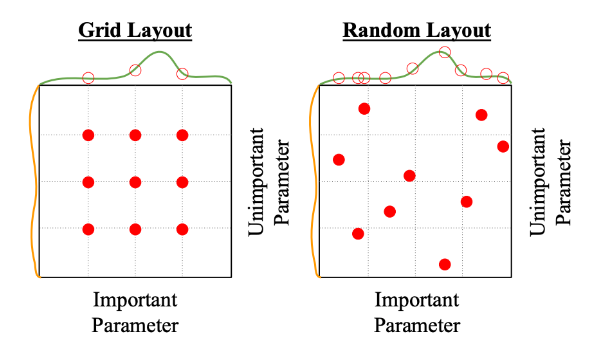
선택
- Step 1: 초기 loss 확인
- weight decay를 끄고, loss 초기 값 적정 검사 (ex. log(C) softmax)
- Step 2: 작은 샘플 overfit
- 100% 훈련 정확도를 위해 학습하는 데 학습 데이터의 작은 샘플을 씀
- 아키텍쳐, learning rate(학습 속도), 가중치 초기화를 파악함
- 정규화(regularization) 끔
- Loss 가 줄어들지 않는다면, LR이 너무 낮음, 나쁜 초기화
- Loss가 너무 많아지거나 NaN? -> LR이 너무 높음, 나쁜 초기화
- Step 3: loss를 줄일 수 있게 LR을 찾음
- 이전 단계에서 아키텍쳐를 사용하고 모든 학습 데이터를 사용하고 가중치 감쇠 작게 키고, 100회 반복 안에 의미 있게 loss가 떨어지는 LR을 찾는다.
- Good learning rates to try: 1e-1, 1e-2, 1e-3, 1e-4
- Step 4: Step 3에서 작동했던 것들 중심으로 LR과 weight decary 값을 고르고, ~1-5 epoch에 대해 몇 가지 모델을 학습한다.
- Good weight decay to try: 1e-4, 1e-5, 0
- Step 5: grid를 개선하고 학습을 오래한다
- Step 4에서 제일 좋은 모델을 고르고 LR 감쇠 없이 (~10-20 epochs)오랫 동안 학습한다.
- Step 6: learning curve 관찰

- 초기화를 이상하게 할 때, Loss 값이 평평해짐: 학습 속도 감소 시도, LR이 떨어질 때 Loss는 계속 떨어지고 있었는데 decay를 너무 일찍함(step decay)

- 정확도가 계속 높아지면 학습을 더 오래 해야됨
- 학습 정확도와 Val 값의 차이가 크다는 것은 overfitting 되었다는 뜻. regularization을 증가시키거나 더 많은 데이터를 사용한다.
- 학습 정확도와 Val 값의 차이가 너무 작거나 없으면 underfitting 되었다는 뜻: 학습을 더 오래하고 더 큰 모델을 사용하고 아마 더 높은 Learning Rate를 사용해야 함.
이후
Step 6까지 마쳤으면, Step 7은 5번으로 돌아가 반복하는 것.
Hyperparameter
- 네트워크 아키텍쳐
- Learning Rate, decay schedule, update type
- regularization(L2/Dropout strength)
- overfitting 방지 목적으로 regularization을 한다.
CNN을 학습하고 싶으면 많은 데이터를 사용해야 할까?
- "사실이 아니다"
Transfer Learning
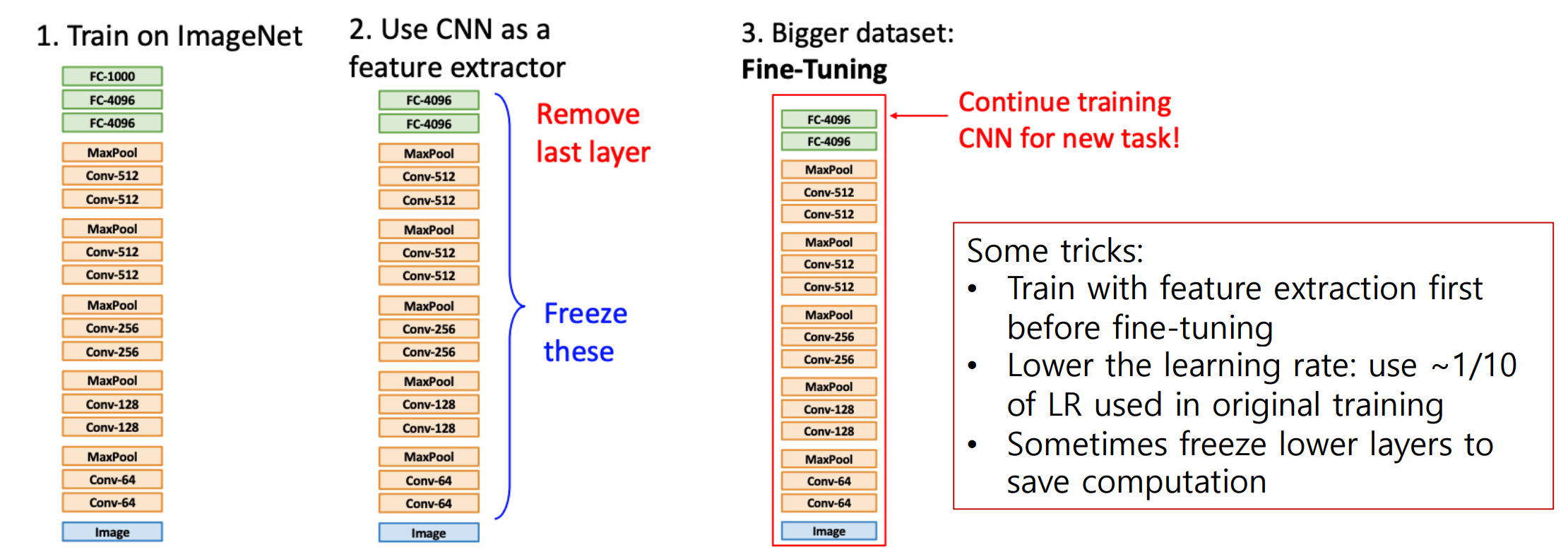
- 일부 트릭들:
- fine-tuning 이전에 특징 추출기를 가지고 먼저 학습
- LR 작게: 본래 학습에서 사용한 LR의 1/10 이하로 사용
- 계산을 절약하기 위해 가끔 아래 layer를 동결하는 경우가 있음.
- 전이 학습은 많은 downstream task들의 향상을 이끌어냈다.
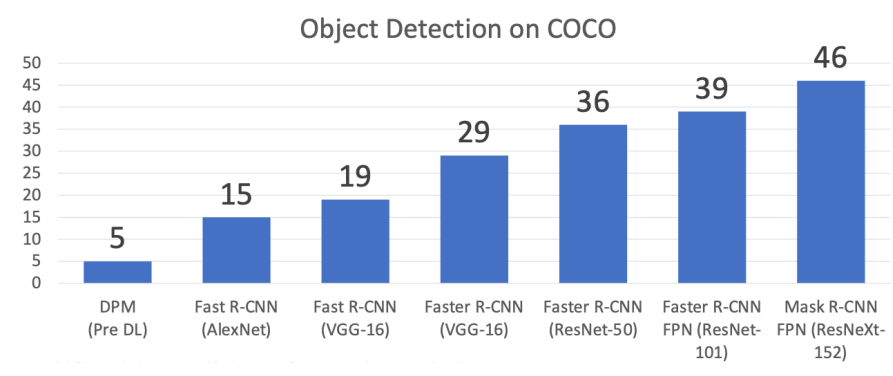
- 아키텍쳐는 중요함
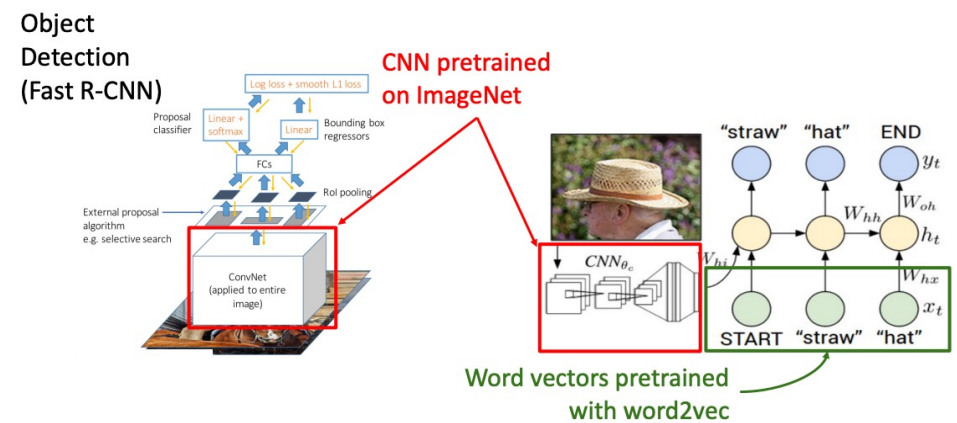
- ImageNet에서 CNN 학습
- Visual Genome에서 Object Detection을 위해 (1)번 Fine-Tune
- 많은 텍스트 위에 BERT 언어 모델 학습
- (2), (3)을 조합, 공동 이미지/언어 모델링 교육
- 이미지 캡션, 시각적 질문을 위한 (5) Fine-tuneD
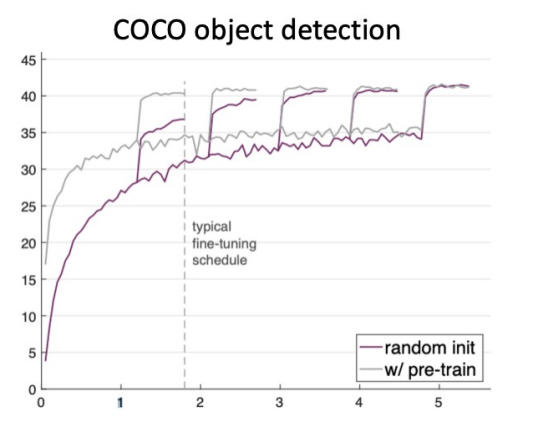
- ImageNet에서 사전 학습 뿐 아니라 처음부터 학습도 됨
- Pretraining + Finetuning은 데이터셋 크기가 매우 작을 때 처음부터 훈련을 능가한다(즉, 미리 훈련된 모델은 처음부터 시작하는 모델을 능가함)
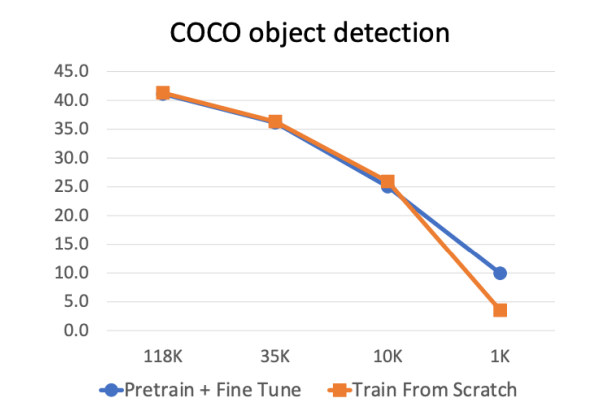
- 더 많은 데이터를 모으는 것은 pretraining보다 효과적이다.
- 미리 훈련+파인 튜닝은 데이터셋 크기가 매우 작을 때 처음부터 학습하는 모델을 능가함
- 더 많은 데이터를 모으는 것은 미리 훈련하는 것보다 효과적임
- Pretrain+finetune은 훈련을 빠르게 만들어주고, 매우 유용하다
- 처음부터 학습하는 것은 충분한 데이터를 가졌으면 잘 작동함.

공부 노트