AI & Game Programming
1.AI, Perceptron

Computer Vision in Game For Immersion(몰입감) • Eye Tracking for Enhanced Interaction (강력한 상호작용을 위한 아이트래킹) • Gesture Recognition for Intuitive Controls
2.AI Movement & Path Finding

캐릭터 = 현재 포지션(velocity) + 물리적 특성모든 움직임 알고리즘은 같은 기본형태를 띈다: own state, world state, geometric output보통 velocity에 대한 출력이 기본임Kinematic movement: 캐릭터가 어떻게 가
3.AI & Game Programming QUIZ for Mid-term

What is not covered in kinematic movement algorithms?PositionOrientationVelocityRotationAccelerationsWhat is the difference between the seek and arriv
4.CNN: Convolution Neural Network -1-
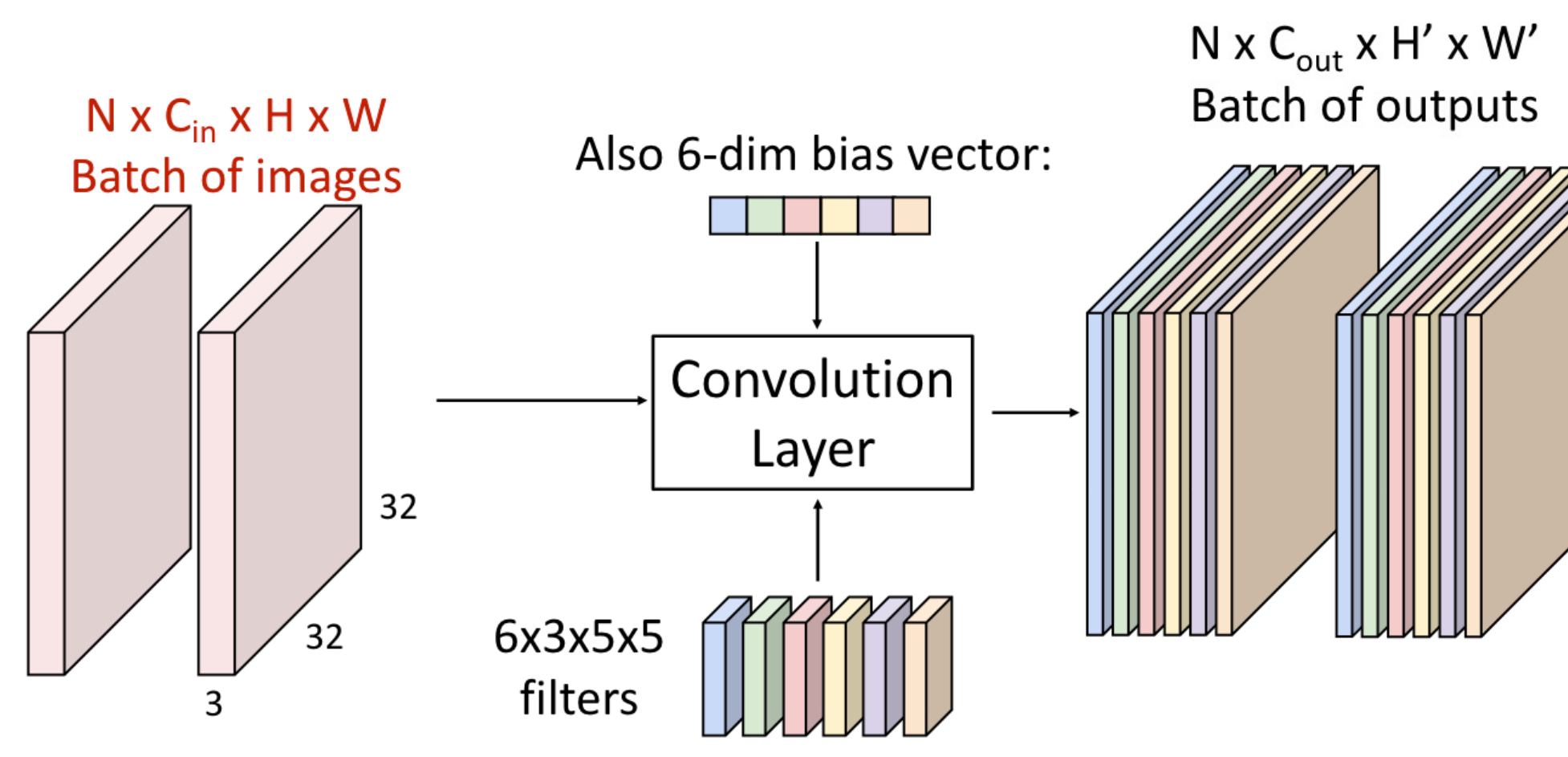
Kernel 크기 만큼 Input에 적용하여 모두 확인함계산 정리$W_2(H_2) = ({W_1(H_2)-F+2P})/S +1$$D2 = K$W: input의 너비H: input의 높이D1: input의 깊이(depth)k: 필터의 개수F: 필터 sizeP: paddi
5.Object Detection -1-
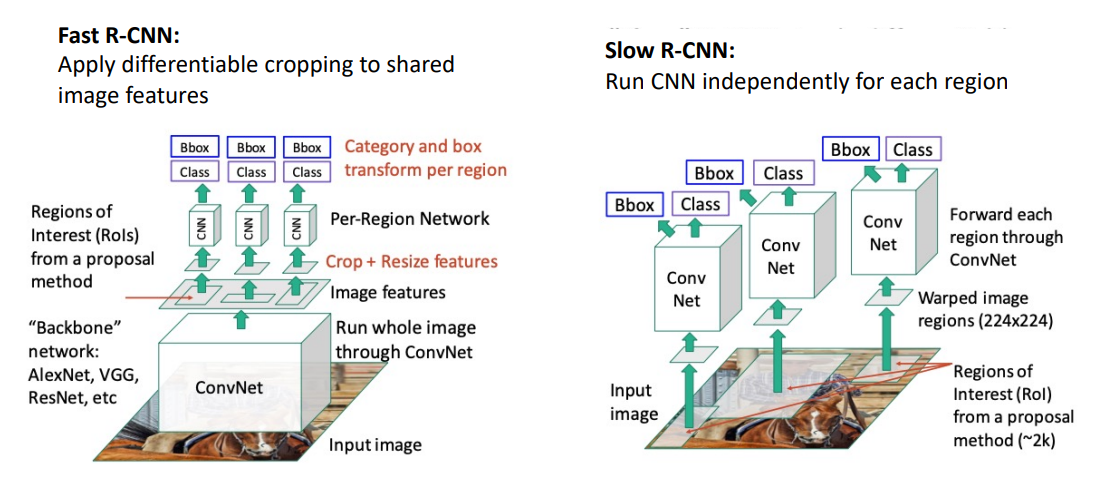
Object Detection Input: 하나의 RGB 이미지 Output: 탐지된 물체들 한 세트 각 object 예측: Category label Bounding box Challenge 다중 출력: 이미지 당 오브젝트의 다양한 수를 출력할 필요 출
6.PyTorch Framework

딥러닝 프레임워크의 초점새로운 아이디어의 빠른 프로토타입 가능자동적으로 gradient 계산GPU에서 효율적으로 실행됨근본적인 컨셉Tensor: numpy 배열처럼 GPU위에서 실행됨 = 자료형Autograd: Tensor의 계산 그래프를 패키징하고 자동으로 gradi
7.Object Detection -2-

Single-stage Detector > 한번에 Object Detection을 하게 하면 어떨까? RPN과 비슷함: 그러나, 물체의 여부로서 앵커를 분류하는 것보다 직접 물체 카테고리나 배경을 예측한다. 근데, 문제점: class 불균형 - 배경 앵커가 더 많으면
8.Video Classification

영상 분류는 영상에 나오는 행동을 분류함근데 영상은 너무 커서 일부만 쓴다.학습용으로는 짧게 잘라서 작은 fps로 모델에 적용함테스트용은 다른 클립을 사용Ref)https://velog.io/@onground/EECS-498-007-598-005-%EA%B0%